一、背景
对于阿里巴巴的用户行为数据:有两个指标对广告CTR预测准确率有重大影响。
1、多样性(Diversity):一个用户可以对很多不同品类的东西感兴趣;
2、局部兴趣(Local activation):对于用户兴趣的多样性,只有一部分历史数据会影响到当次推荐的物品是否被点击,并非所有。
例子:
Diversity体现在年轻的母亲的历史记录中体现的兴趣十分广泛,涵盖羊毛衫、手提袋、耳环、童装、运动装等等。而爱好游泳的人同样兴趣广泛,历史记录涉及浴装、旅游手册、踏水板、马铃薯、冰激凌、坚果等等。
Local activation体现在,当我们给爱好游泳的人推荐goggle(护目镜)时,跟他之前是否购买过薯片、书籍、冰激凌的关系就不大了,而跟他游泳相关的历史记录如游泳帽的关系就比较密切。
目前的CTR预估的问题:
1、一般个人的当前兴趣是与最近的浏览内容有更强的关联,而不是全部的兴趣列表。
2、从用户浏览的内容多样性中获取用户真正兴趣。
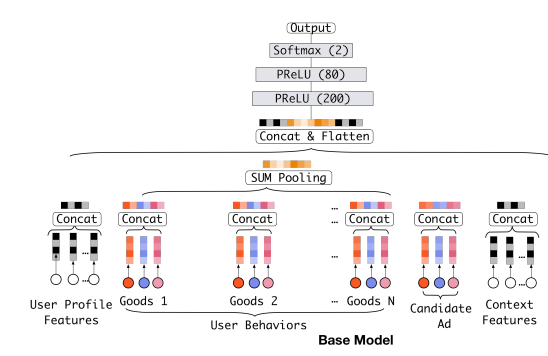
base模型:常见的MLP
1、对特征进行Embedding操作,得到一系列Embedding向量
2、将不同group的特征concate起来之后得到一个固定长度的向量
3、将此向量喂给后续的全连接网络,最后输出
二、DIN模型
1、特征处理
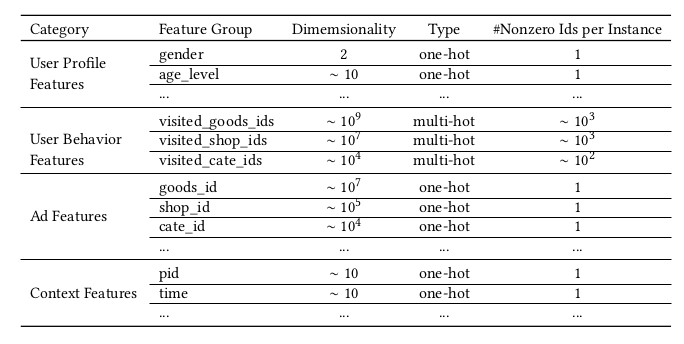
Learning piece-wise linear models from large scale data for ad click prediction多类别数据,如:[weekday=Friday, gender=Female, visited_cate_ids={Bag,Book}, ad_cate_id=Book], 这些特征通过encoding转为高维稀疏二值特征。
(1)ti ∈ R Ki 表示第 i 个类别的encoding vector,
Ki 表示类别 i 的维度,which means feature group i contains Ki unique ids. K=1表示one-hot,K>1表示multi-hot。
(2)ti[j] is 第j个元素of ti ,ti[j] ∈ {0, 1}.
(3)一个样本:x = [t1T , t2T , ...tMT] ,M表示类别的数量,即weekday,gender, visited_cate_ids , ad_cate_id四个 。
four groups of features are illustrated as:

全部特征类型如下:
2、Base模型(Embedding & MLP)
(1)Embedding layer:
![]() : 第 i 个类别的embedding。wi j∈ RD表示类别 i 多值中第 j 个值的embedding向量。
: 第 i 个类别的embedding。wi j∈ RD表示类别 i 多值中第 j 个值的embedding向量。

(2)Pooling layer and Concat layer:
![]()
(3)MLP
(4)loss

3、DIN
与Base模型结构相比主要差别:如何聚合多个用户行为Embedding向量?
- Base模型中直接对多个Embedding向量进行等权的sum-pooling
- DIN采取weighted-sum pooling,即Attention,让模型更加关注有用的信息。

(1)用户表示:采用Attention加权求和pooling
 --------------------- Local activation (attention unit)
--------------------- Local activation (attention unit)
其中,{e 1 , e 2 , ..., e H }是用户U的一系列行为embedding,VA表示广告A的embedding。且放宽了∑w i = 1的约束,这样更有利于体现不同用户行为特征之间的差异化程度。。
(2)本文还尝试用LSTM来建模用户历史行为数据,但没有任何改善。原因可能是:NLP中文本会受到语法约束,但是用户行为序列可能包含多个共同兴趣,这些兴趣快速的转换和突然的结束使得用户行为的序列数据变得杂乱。
可能的解决方案是设计特殊的结构来建模这样的序列数据,将此作为未来的研究。
三、训练技巧
用户和广告数量达数亿,大规模稀疏输入训练过程。两个解决技术:
1、Mini-batch Aware Regularization:解决在大规模稀疏场景下,采用SGD对引入L2正则的loss进行更新时计算开销过大的问题。
(1)提出背景:
没有加正则化会导致严重的过拟合行为(增加60万的细粒度good_id特征):如绿线。
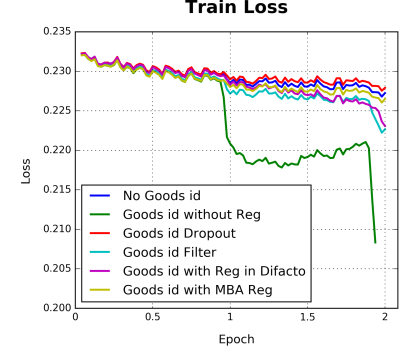

但是,当加l2正则化时,它需要针对每个mini-batch计算每个参数的L2范数,这会导致非常繁重的计算,参数扩展到数亿是不可接受的。
用户数据符合长尾定律long-tail law, 也就是说很多的feature id只出现了几次,而一小部分feature id出现很多次。这在训练过程中增加了很多噪声,并且加重了过拟合。对于这个问题一个简单的处理办法就是:直接去掉出现次数比较少的feature id。但是这样就人为的丢掉了一些信息,导致模型更加容易过拟合,同时阈值的设定作为一个新的超参数,也是需要大量的实验来选择的。
因此,阿里提出了自适应正则的做法,即:
1.针对feature id出现的频率,来自适应的调整他们正则化的强度;
2.对于出现频率高的,给与较小的正则化强度;
3.对于出现频率低的,给予较大的正则化强度。
该方法只对每一个mini-batch中参数不为0的进行梯度更新。
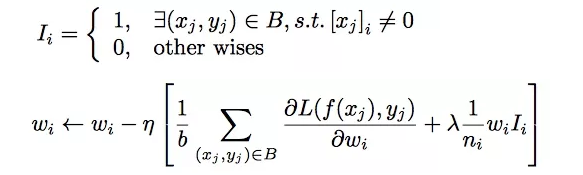
(2)推导过程:
mini-batch aware regularizer:
W ∈ R D×K表示:整个embedding dictionary的参数。D as the dimensionality of the embedding vector and K as the dimensionality of feature space.
Expand the l2 regularization on W:
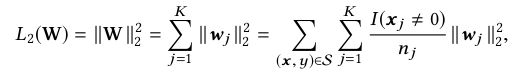 -----------------------(4)
-----------------------(4)
其中, I (xj 不等于 0) denotes if the instance x has the feature id j, and nj denotes the number of occurrence for feature id j in all samples.
(4)式可转为mini-batch形式(5):
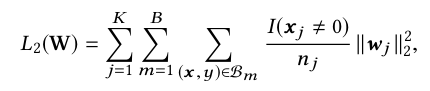 -----------------(5)
-----------------(5)
where B denotes the number of mini-batches。 Bm denotes the m-th mini-batch.
(5)式可近似为(6),令![]() 表示 if there is at least one instance having the feature id j in mini-batch B m .:
表示 if there is at least one instance having the feature id j in mini-batch B m .:
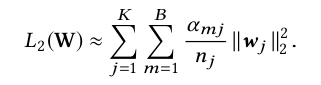 -----------------(6)
-----------------(6)
针对the m-th mini-batch,(梯度)the gradient w.r.t. the embedding weights of feature j is:
经过一系列推到之后得到近似的梯度计算公式如下所示:
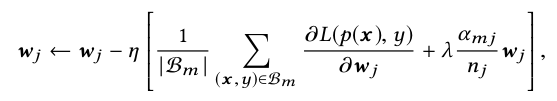
2、自适应激活函数Dice
Relu激活函数形式如下:(Relu激活函数在值大于0时原样输出,小于0时输出为0。这样的话导致了许多网络节点的更新缓慢。)

PReLU:及时值小于0,网络的参数也得以更新,加快了收敛速度。
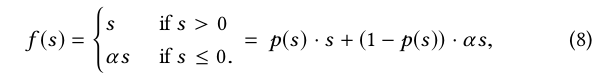
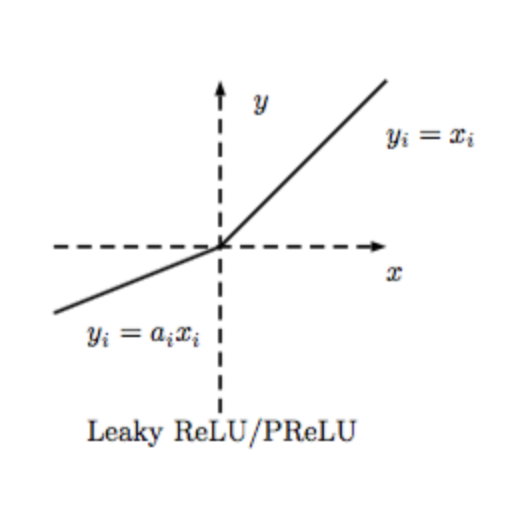
Dice: 尽管对Relu进行了修正得到了PRelu,但是仍然有一个问题,即我们认为分割点都是0,但实际上,分割点应该由数据决定,因此文中提出了Dice激活函数。
文章认为采用PRelu激活函数时,他的rectified point固定为0,这在每一层的输入分布发生变化时是不适用的,所以文章对该激活函数机型了改进,平滑了rectified point附近曲线的同时,激活函数会根据每层输入数据的分布来自适应调整rectified point的位置,具体形式如下 :
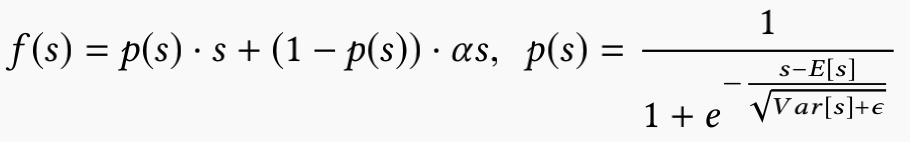
p(s)的计算主要分为两步:将si进行标准化和进行sigmoid变换。
另外,期望和方差使用每次训练的 mini batch data 直接计算,并类似于 Momentum 使用了 指数加权平均:
alpha 是一个超参数,推荐值为 0.99
函数曲线如下所示:

四、评价指标
评价标准是阿里自己提出的 GAUC。并且实践证明了 GAUC 相比于 AUC 更加稳定、可靠。
AUC 表示正样本得分比负样本得分高的概率。在 CTR 实际应用场景中,CTR 预测常被用于对每个用户候选广告的排序。但是不同用户之间存在差异:有些用户天生就是点击率高。以往的评价指标对样本不区分用户地进行 AUC 的计算。论文采用的 GAUC 实现了用户级别的 AUC 计算,在单个用户 AUC 的基础上,按照点击次数或展示次数进行加权平均,消除了用户偏差对模型的影响,更准确的描述了模型的表现效果:
其中权重 w 既可以是展示次数 (impression) 也可以是点击次数 (clicks)。n 是用户数量。
五、实现
DIN 在阿里内部的实现,使用了多个 GPU。并行化是基于 模型并行化、数据并行化。命名为 X-Deep Learning(XDL)。
由三部分组成:
-
Distributed Embedding Layer。模型并行化部分,Embedding Layer 的参数分布在多个 GPU 上,完成前向后向传播计算。
-
Local Backend。单独的模块,用来在处理网络的训练。使用了开源的 deep learning 框架,比如 tf,mxnet,theano 等。作为一个后端支撑,良好的接口封装方便集成或切换各个开源框架。
-
Communication Component。基础模块,用来帮助 embedding layer 和 backend 来实现并行化。使用 MPI 实现。
分为 模型并行化、数据并行化。
对于一个用户,一次 pageview 中假设展示了 200 个商品。那么每个商品就对应一条样本。但是,这 200 条样本中是有很多Common Feature的。所以 DIN 的实现中并没有把用户都展开,类似于下图:
对于很多静态的不变的特征,比如性别、年龄、昨天以前的行为等只计算一次、存储一次。之后利用索引与其他特征关联,大幅度的压缩了样本的存储,加快了模型的训练。最终实验仅用了 1/3 的资源,获得了 12 倍的加速。
下图展示了用户兴趣分布:颜色越暖表示用户兴趣越高,可以看到用户的兴趣分布有多个峰。
利用候选的广告,反向激活历史兴趣。不同的历史兴趣爱好对于当前候选广告的权重不同,做到了 local activation,如下图:
六、 总结
-
用户有多个兴趣爱好,访问了多个 good_id,shop_id。为了降低纬度并使得商品店铺间的算术运算有意义,我们先对其进行 Embedding 嵌入。那么我们如何对用户多种多样的兴趣建模那?使用 Pooling 对 Embedding Vector 求和或者求平均。同时这也解决了不同用户输入长度不同的问题,得到了一个固定长度的向量。这个向量就是用户表示,是用户兴趣的代表。
-
但是,直接求 sum 或 average 损失了很多信息。所以稍加改进,针对不同的 behavior id 赋予不同的权重,这个权重是由当前 behavior id 和候选广告共同决定的。这就是 Attention 机制,实现了 Local Activation。
-
DIN 使用 activation unit 来捕获 local activation 的特征,使用 weighted sum pooling 来捕获 diversity 结构。
-
在模型学习优化上,DIN 提出了 Dice 激活函数、自适应正则 ,显著的提升了模型性能与收敛速度。
七、代码
参考文献:(转载)
https://blog.csdn.net/livan1234/article/details/85159658
详细:https://juejin.im/post/6844903645008363527
盖坤团队视频解释:http://tech.sina.com.cn/roll/2017-07-11/doc-ifyhvyie0999628.shtml、https://www.leiphone.com/news/201707/t0AT4sIgyWS2QWVU.html