目录:
- apply
- memory_usage
- pivot_table
1、DataFrame概念
Series对应的是一维序列,而DataFrame对应的是二维表结构(表格型的数据结构)
DataFrame可以看成共享同一个索引index的Series集合。
2、DataFrame创建
DataFrame对象可以由列表、元祖、字典创建,然后通过DataFrame函数创建,如:name和pay为列索引,行索引用默认的0,1,2
由字典创建:

用列表创建:然后通过DataFrame创建,index作为行索引,columns作为列索引。

3、基本操作:


- 查看dataframe的行索引:dataframe.index
- 查看dataframe的列索引:dataframe.columns
- 查看dataframe的值:dataframe.values 【值的类型为numpy.narray】
- 通过dataframe['列名'] 来查看值 , 【值的类型为series】
- 查看dataframe单值索引:dataframe['列名']['行名'](注意先列后行)
用循环输出所有的值:
for i in dataframe.columns:
for j in dataframe.index:
print(dataframe[i][j])
- 查看dataframe的前n行:dataframe.head(n)
- 查看dataframe的后n行:dataframe.tail(n)
- 查看dataframe的数据描述:dataframe.describe【得到的结果为count、mean、std、min、25%、50%、75%、max】
- 查看dataframe的维度:dataframe.shape
- 查看dataframe的数据总个数:dataframe.size
- 查看dataframe的区域数据:dataframe.loc[行标签,[ 列标签 ] ] 函数 和 dataframe.iloc[ 行标签物理位置,[ 列标签物理位置 ] ]
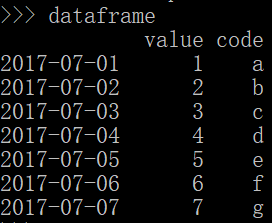
(参照以下这张图)
切片行索引:dataframe.loc['2017-07-03':'2017-07-06'],只输出从3号到6号的值。
dataframe.iloc[2:6]
进行列索引:dataframe.loc['2017-07-03':'2017-07-06',['value','code']]
dataframe.iloc[2:6,[0,1]]
- 查看dataframe的单个值:dataframe.at[行标签,列标签]
- 查看dataframe多个值:dataframe.ix[1:3,1:3]或者dataframe['a':'c','B':'D']即ix既可以通过属性来查看又可以通过行列数来查看。
- 修改dataframe的某个列名:dataframe.rename( columns={ '要修改的名称' : '改后的名称' },inspace=True)
- 提取dataframe的某一些特定行:isin
# 筛选p1列中值为'SD'和'HN'的行:df [ df.p1.isin ( ['SD','HN'] ) ]
- 不在里面:前面加一个~
# ~df [ df.p1.isin ( ['SD','HN'] ) ]
- pandas.DataFrame排除特定行:
#删除p1列中值为'SD'和'HN'的行
将p1转换为列表,再从列表中移除特定的行:
ex_list = list(df.p1) ex_list.remove('SD') ex_list.remove('HN') df[df.p1.isin(ex_list)]
(求均值)dataframe[ 行标签或者列标签 ].mean()
(求最大值)dataframe[ 行标签或者列标签 ].max()
(求和)sum ( dataframe [ 行标签或者列标签 ] )
(排序):按照行索引排序,按照值排序等:dataframe.sort_index、dataframe.sort_values(by='标签') 【还有一些参数,比如ascending=False逆序排序】
(分组):dataframe.groupby('标签') 【https://blog.csdn.net/youngbit007/article/details/54288603】
属性:as_index、axis、sort、
dataframe.groupby( ['标签1','标签2'] , as_index = False ),就是不将['标签1','标签2']作为index,默认是True。
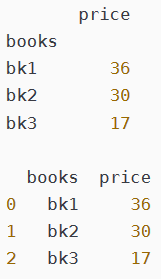
axis = 1
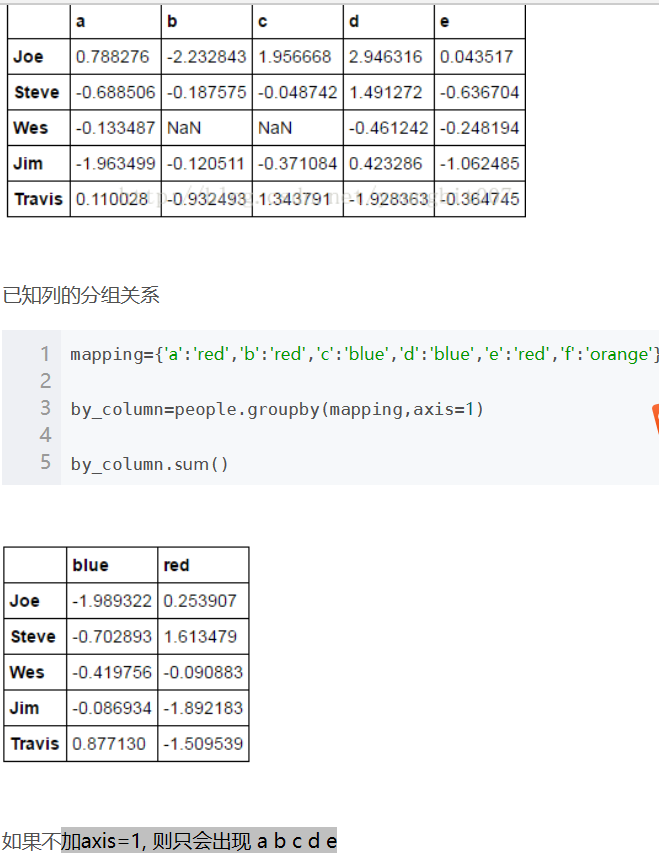
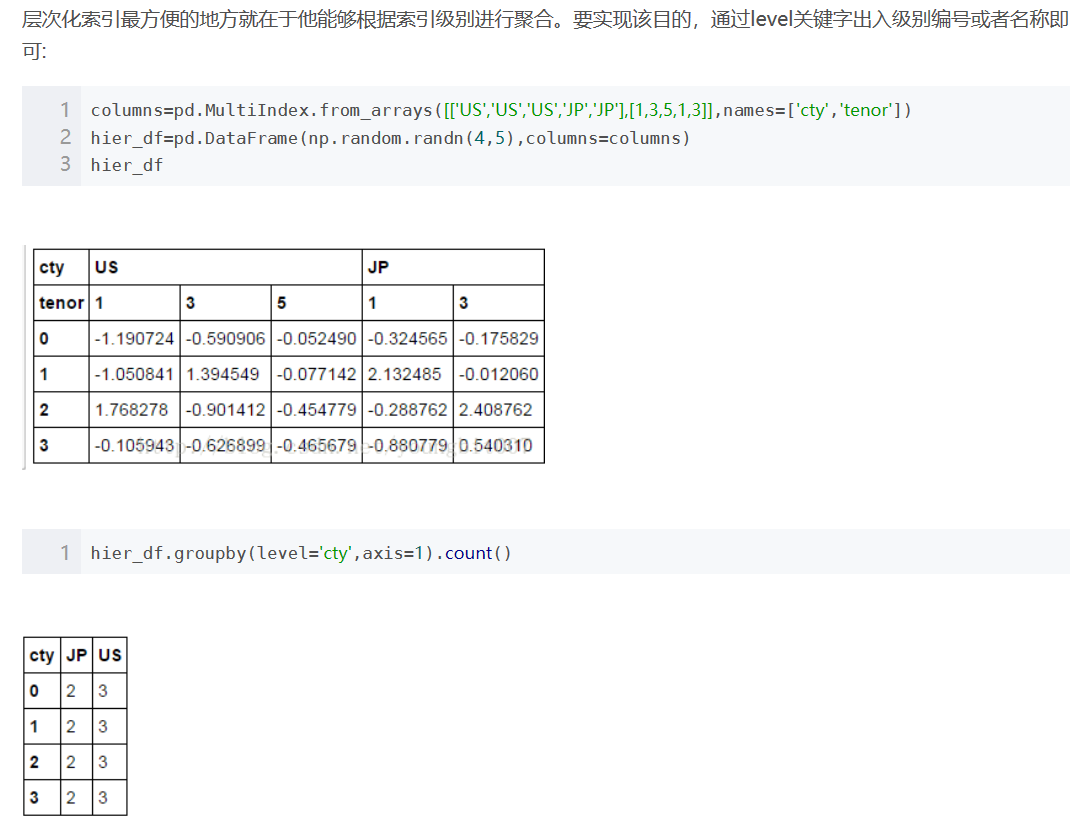
level:
函数:sum()、agg()、count()、mean()
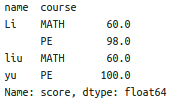
af.groupby(['name','course'])['score'].sum()#先将af按照name进行分组,再按照course进行分组,最后将score进行sum。

append是追加
concat是将多个相同的dataframe合并,不用考虑有没有相同的字段。
merge类似数据库中的join,需要有相同的字段来合并。
pd.merge(dataframe1,dataframe2,on='相同的标签' )【可以完成sql中很多连接的工作】
三个文件/甚至更多文件merge:
data5 = [account,cart,buy,order,success] df_merged5 = reduce(lambda left,right: pd.merge(left,right,on=['date']), data5).fillna('void')
https://www.cnblogs.com/guxh/p/9451532.html
(转置):dataframe.T
(去重):dataframe = dataframe.drop_duplicates():返回了一个移除重复值的dataframe。
dataframe = dataframe.drop_duplicates( [ 'A' ]) :希望对A这一列重复的值删除。
4、例子:
创建一个DataFrame:
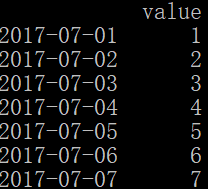
import numpy as np import pandas as pd dates=pd.date_range('2017-07-01',periods=7) col=['value'] data=[] for i in range(1,8): data.append(i) frame=pd.DataFrame(data,index=dates,columns=col) print(frame)
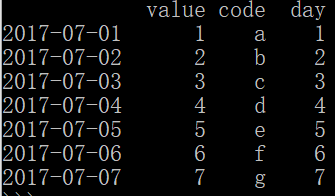
frame['code']=['a','b','c','d','e','f','g']
frame['day']=frame.index.day#将行索引的日期拆成一列加入到dataframe中
frame['day'].value_counts()
5、一些常用的函数
(1)删除缺失值:dropna(axis=0,subset=['Age','Sex']:意思是将属性Age或者Sex为空的列删除。
(2)数据透视表:df.pivot_table(index= ,value=,aggfunc=):index是按照该属性为基准,value是要作用的值,aggfunc是进行什么函数操作,如:
df.pivot_table(index="Pclass", values="Survived", aggfunc=np.mean):以Pclass为分组,对Survived进行均值操作。
(3)df.sort_values(属性名,ascending=False):对df将按属性升值来排序。
(4)apply函数:df.apply(自定义的函数名),想运用自定义的函数对df进行操作。
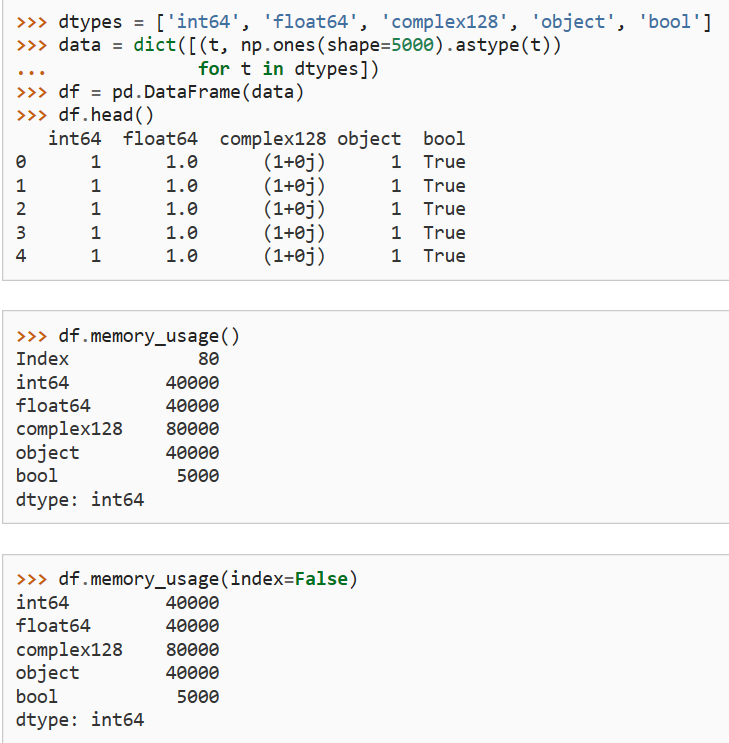
(5)memory_usage:返回每一列所占的内存大小。