1、摘要:
提出了一种新的深度强化学习框架的新闻推荐。由于新闻特征和用户喜好的动态特性,在线个性化新闻推荐是一个极具挑战性的问题。
虽然已经提出了一些在线推荐模型来解决新闻推荐的动态特性,但是这些方法主要存在三个问题:①只尝试模拟当前的奖励(eg:点击率)②很少考虑使用除了点击 / 不点击标签之外的用户反馈来帮助改进推荐。③ 这些方法往往会向用户推荐类似消息,这可能会导致用户感到厌烦。
基于深度强化学习的推荐框架,该框架可以模拟未来的奖励(点击率)
2、引言:
新闻推荐三个问题:
(1)新闻推荐的动态变化是难以处理的。
(2)用户的兴趣可能随着时间的变化而变化。
(3)创新
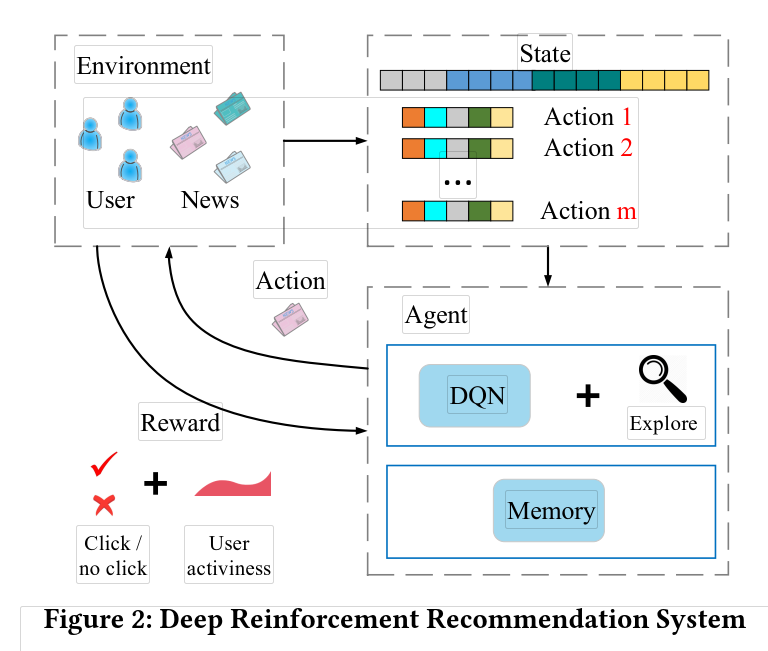
强化学习:假定一个智能体(agent),在一个未知的环境中(当前状态state),采取了一个行动(action),然后收获了一个回报(reward),并进入了下一个状态。最终目的是求解一个策略让agent的回报最大化。
因此,本文提出了基于深度强化学习的推荐系统框架来解决上述提到的三个问题:
(1)首先,使用DQN网络来有效建模新闻推荐的动态变化属性,DQN可以将短期回报和长期回报进行有效的模拟。
(2)将用户活跃度作为一种新的反馈信息。
(3)使用Dueling Bandit Gradient Descent 方法来进行有效的探索。
算法的框架如下图所示:
3、问题描述:
当一个用户 u 在时间 t 向推荐系统 G 发送一个新闻请求,系统会利用一个给定的新闻候选集 I 给用户推荐一个 top-k 列表给用户。
4、模型方法:
4.1 整体架构图:
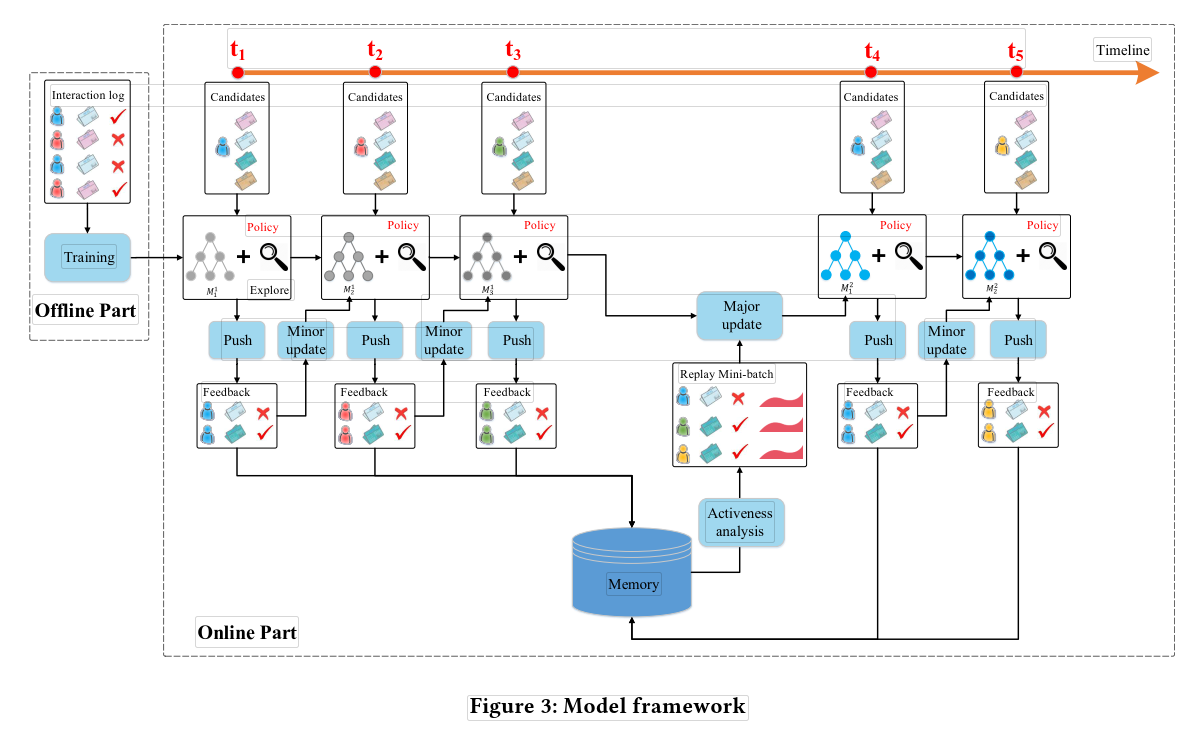
几个关键环节:
push:在每一个时刻,用户发送请求时,agent根据当前的state产生k篇新闻推荐给用户。
Feedback:通过用户对推荐新闻的点击行为得到反馈结果。
minor update:在每个时间点过后,根据用户的信息(state)和推荐的新闻(action)以及得到的反馈(reward),更新参数。
major update:在一段时间后,根据DQN的经验池中存放的历史经验,对模型参数进行更新。