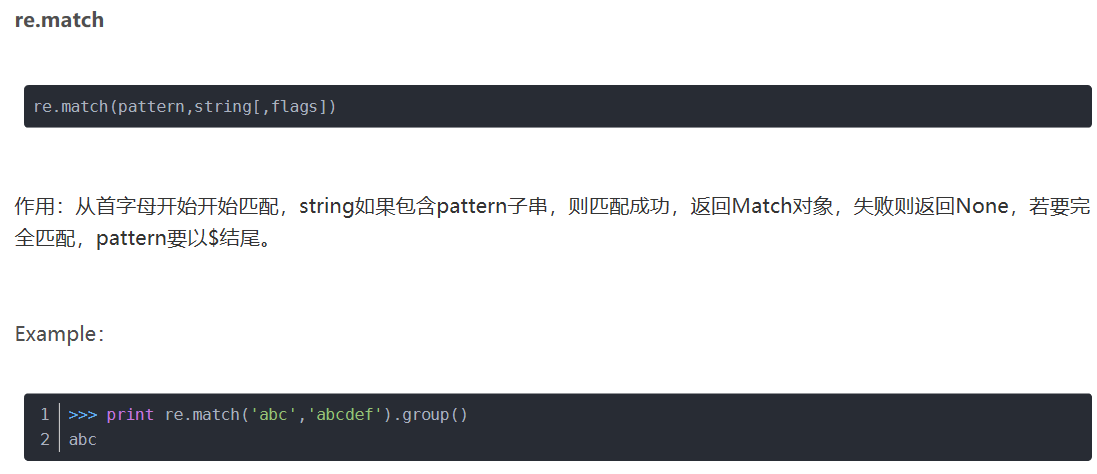
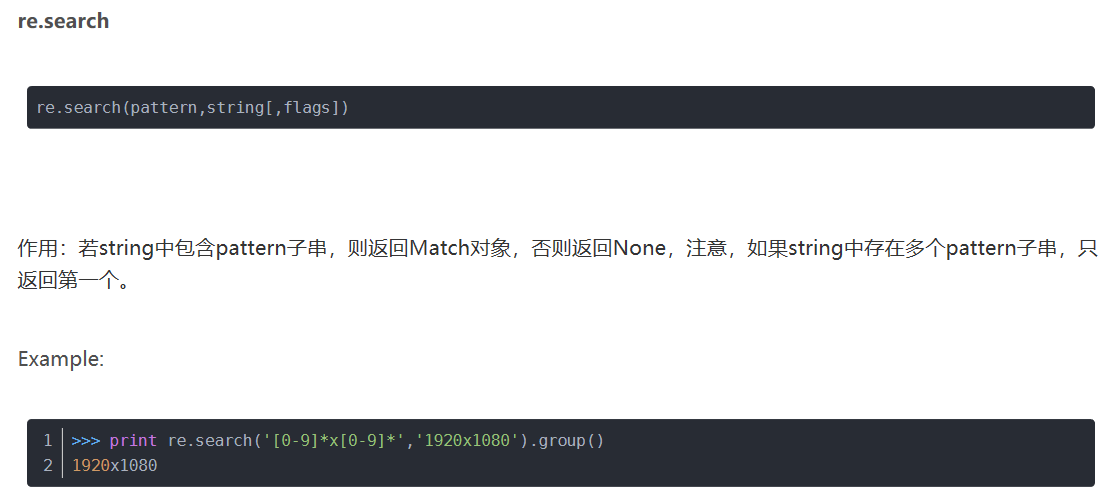
1、语法:
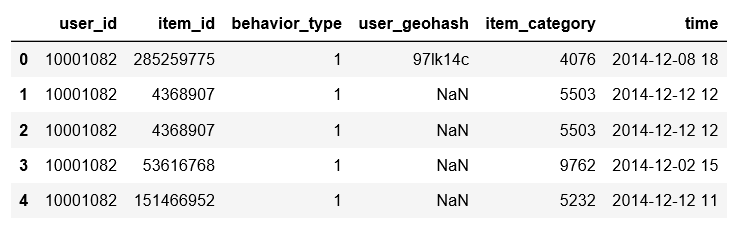
2、题目1:数据类型:
如果要选择 time 为2014-12-18那天的数据:采用正则化来处理
代码:
import re regex = re.compile(r'^2014-12-18+ /d+$') def datefun(data): if re.match(regex,data['time']): date,time = data['time'].split(' ') return date else: return None data['time'] = data.apply(datefun,axis = 1) data = data[(data['time'] == '2014-12-18')]
3、合法字母或数字,只要是大小写字母和数字就合法
import re ss = 'abc13AD' if re.search('^[0-9a-zA-Z]+$',ss): return True
4、pandas dataframe/series 正则表达式使用 str.match str.contains str.extract
(series)topquery_data['sentence'] 满足 开头为字母,然后为: ,接着是任何字符,接着还是:,最后为任何字符,如:
sport::程菲 体操
social:ssocial_车祸违驾:闯红灯 女司机 广州
health::野草 农民
选出之后按冒号切分,将最后的值付给原来的topquery_data['sentence'] ,即
程菲 体操
闯红灯 女司机 广州
野草 农民
取代原来的值
def split_function(string):
return string.split(':')[-1]
pattern = '^[a-zA-Z]+:+[a-zA-Z:]+[]*+:[sS]*' topquery_data['sentence'].loc[topquery_data['sentence'].str.contains(pattern)] = topquery_data[topquery_data['sentence'].str.contains(pattern)]['sentence'].apply(split_function)