【零基础学习iOS开发】【02-C语言】04-常量、变量
在我们使用计算机的过程中,会接触到各种各样的数据,有文档数据、图片数据、视频数据,还有聊QQ时产生的文字数据、用迅雷下载的文件数据等。这讲我们就来介绍C语言中数据的处理。
一、数据的存储
1.数据类型
首先来看看计算机是怎么存储数据的。总的来说,计算机中存储的数据可以分为两种:静态数据和动态数据。
1> 静态数据
概念:静态数据是指一些永久性的数据,一般存储在硬盘中。硬盘的存储空间一般都比较大,现在普通计算机的硬盘都有500G左右,因此硬盘中可以存放一些比较大的文件。
存储的时长:计算机关闭之后再开启,这些数据依旧还在,只要你不主动删掉或者硬盘没坏,这些数据永远都在。
哪些是静态数据:静态数据一般是以文件的形式存储在硬盘上,比如文档、照片、视频等。
2> 动态数据
概念:动态数据指在程序运行过程中,动态产生的临时数据,一般存储在内存中。内存的存储空间一般都比较小,现在普通计算机的内存只有4G左右,因此要谨慎使用内存,不要占用太多的内存空间。
存储的时长:计算机关闭之后,这些临时数据就会被清除。
哪些是动态数据:当运行某个程序(软件)时,整个程序就会被加载到内存中,在程序运行过程中,会产生各种各样的临时数据,这些临时数据都是存储在内存中的。当程序停止运行或者计算机被强制关闭时,这个程序产生的所有临时数据都会被清除。
你可能会问:既然硬盘的存储空间这么大,为何不把所有的应用程序加载到硬盘中去执行呢?有个主要原因是内存的访问速度比硬盘快N倍。
3> 动态数据和静态数据的转换
硬盘和内存是计算机使用最频繁的两个硬件,它们之间的数据经常要进行转换。
比如,硬盘上有个叫做“C语言.mp4”的视频文件,现在要使用暴风影音来播放

首先打开暴风影音软件,计算机会将暴风影音加载到内存中,紧接着计算机会读取硬盘中视频文件的内容到内存中。暴风影音会解析读取到的文件内容,以视频的形式呈现给用户看。这就完成了一个由静态数据到动态数据的转换。
再比如,你使用迅雷从网上下载一个叫做“C语言.mp4”的视频文件

首先打开迅雷软件,计算机会将迅雷加载到内存中,紧接着迅雷就会从互联网下载视频文件。大家都知道,这个下载过程肯定是要耗点时间的,主要受文件大小和下载速度的影响。每个时间段内下载获取的数据都是先放到内存中,然后再写入到硬盘中。所有数据下载完毕后,硬盘中就会有一个完整的视频文件。这就完成了动态数据到静态数据的转换。
2.存储形式
1> 二进制存储
在前面的文章中说过,计算机只能识别0和1。因此,前面所说的静态数据和动态数据,都是以0和1的形式存储的,这种存储方式称为“二进制存储”。有人可能觉得很诧异,只是0和1怎么可能表示这多的数据呢?没错,如果只是一位数字的话,只能表示2种数据:要么是0,要么是1。但是如果有多位数字的话,那情况就不一样了。如果有2位数字,那么就能表示4种数据:00、01、10、11;如果有3位数字呢,就能表示8种数据;以此类推,如果有n位数字,就能表示2的n次方种数据。可以发现,只要位数足够,0和1所能表示的数据是非常庞大的。
2> 比特位和字节
* 平时我们在计算机上看到的MP4、MP3、照片等文件,都是由0和1组合成的,只不过计算机解析了这些0和1,以图形界面的形式呈现在我们眼前。文件越大,所包含的0和1就越多,为了方便计算文件大小,对计量单位做了个规定:1个二进制位为1bit,也就是1个0或1就为1bit,bit的中文翻译是“比特位”;8个二进制位为1byte,也就是8个0或1就为1byte,1byte=8bit,byte的中文翻译是“字节”。平时我们所说的某个文件大小为64B,就是64字节的意思,内部包含了64x8个0和1。
* 还有一些需要了解的计量单位:
1 KB = 1024 B,1 MB = 1024 KB,1 GB = 1024 MB,1 TB = 1024 GB
* 在Mac上查看某个mp4文件的大小:
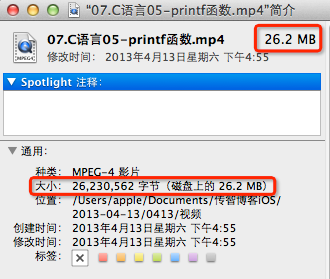
26.2 MB = 26.2 x 1024 KB = 26.2 x 1024 x 1024 B(字节)
二、数据类型
作为程序员,最关心的肯定是内存中的动态数据,因为我们写的程序就是运行在内存中的。程序在运行过程中,会产生各种各样的动态临时数据,为了方便数据的运算和操作,C语言对这些数据进行了分类,提供了丰富的数据类型。大致如下图所示:

* 在图中众多数据类型中,最常用的是4种基本数据类型:char、int、float、double,而最重要的是指针类型,指针使用得当的话,不仅可以节省代码量,还可以优化内存管理、提高性能。因此,指针是一个非常重要的概念,必须重视。如果你说C语言中除了指针,其他都学得挺好的,那你干脆说你没学过C语言。
* 这些丰富的数据在C语言中可以用常量或者变量来表示。接下来就介绍一下常量和变量的使用。
三、常量
1.什么是常量
"量"表示数据。常量,则表示一些固定的数据,也就是不能改变的数据。
2.常量的类型
在C语言中,常量大致可以分为以下类型:
1> 整型常量(int)
其实就是int类型的数据,包括了所有的整数,比如6、27、109、256、-10、0、-289等
2> 浮点型常量(float\double)
浮点型常量分为double和float两种数据类型
- double:双精度浮点型,其实就是小数。比如5.43、-2.3、0.0等,注意,0.0也算是个小数。
- float:单精度浮点型,也是小数,比double的精确程度低,也就是说所能表示的小数位数比较少。为了跟double区分开来,float型数据都是以f结尾的,比如5.43f、-2.3f、0.0f。需要注意的是,绝对不能有10f这样格式的,编译器会直接报错,只有小数才允许加上f。
3> 字符常量(char)
- 将一个数字(0~9)、英文字母(a~z、A~Z)或者 其他符号(+、-、!、?等)用单引号括起来,这样构成的就是字符常量。比如'6'、'a'、'F'、'+'、'$'等。
- 注意:单引号只能括住1个字符,而且不能是中文字符,下面的写法是错误的:'abc'、'123456'、'男'
4> 字符串常量
- 将一个或者多个字符用双引号("")括起来,这样构成的就是字符串常量。比如"6"、"男"、"哇哈哈"、"abcd"、"my_car4",其实printf("Hello World");语句中的"Hello World"就是字符串常量。
- 那究竟6、'6'、"6"在用法上有什么区别呢?这个先不作讨论,以后会介绍。
三、变量
1.什么是变量
常量表示的数据是不可以改的,而用变量表示的数据是可以经常修改的。比如游戏中主角的生命值就可以用一个变量来表示,主角受到伤害后,生命值就会减少,主角接受治疗后,生命值就会增多,在游戏过程中,主角的生命值一直都在改变,因此主角的生命值应该用一个变量来表示。总结一句话:当一个数据的值需要经常改变或者不确定时,就应该用变量来表示。
2.变量的定义
任何变量在使用之前,必须先进行定义。定义变量的目的是:在内存中分配一块存储空间给变量,方便以后存储数据。如果定义了多个变量,就会为这多个变量分别分配不同的存储空间。
1> 变量类型
* 计算机的内存是有限的,现在普通计算机的内存有4G,那么定义一个变量的时候分配多少存储空间给这个变量呢?是4G全部给它么?这很显然不可能,如果把4G的存储空间全部给了这个变量,那就意味着不能再分配空间给其他变量,而且系统也会瘫痪,因为内存不够用了,无法再运行其他程序。因此,我们在定义变量的时候,需要指明变量类型,系统会根据变量类型来分配相应的存储空间。不同数据类型所占用的存储空间是不一样的,如果是字符型(char)变量,就分配1个字节的存储空间;如果是整型(int)变量,就分配4个字节的存储空间。
* 变量类型的还一个作用是用来约束变量所存放数据的类型。一旦给变量指明了类型,那么这个变量就只能存储这种类型的数据,比如整型(int)变量只能存储整型数据,不能存储浮点型数据。
2> 变量名
在程序运行过程,肯定会定义大量的变量,每个变量都有自己的存储空间。那怎么区分这些变量呢?怎么找到变量对应的存储空间呢?为了区分这些变量,定义变量的时候应该为每个变量指定一个变量名,变量名也是标识符的一种。当我们要修改变量的数据时,系统会根据变量名找到变量对应的存储空间,将存储空间里面的数据改掉。
3> 定义
总结可得,定义变量需要2个条件:变量类型、变量名。定义变量的格式为:变量类型 变量名;

1 int main() 2 { 3 int i; 4 5 char c; 6 7 return 0; 8 }
由于C程序的入口是main函数,因此暂时把定义变量的代码都写在了main函数中。在第3行定义了一个名字为i的整型变量,说明i只能存储整型数据;在第5行定义了一个名字为c的字符型变量,说明c只能存储字符型数据。第3、5、7行的代码都称为“语句”,每条语句后面都有个分号;。
于是,系统就会在内存中分别为变量i、c分配一定的存储空间,如下图所示,i和c各占用一块存储空间。至于究竟占用多少字节的存储空间呢,暂时不用去研究,后面会介绍。

如果是同一种类型的变量,可以连续定义,变量名之间用逗号,隔开。格式为:变量类型 变量名1, 变量名2, 变量名3, ... ;
1 int main() 2 { 3 int a, c; 4 5 return 0; 6 }
第3行代码的意思是定义了2个int类型的变量,变量名分别为a、c
3.变量的使用
1> 先定义,再初始化
前面已经定义了两个变量,但是这两个变量并没有存储任何值,我们需要给变量进行第一次赋值,也叫做“初始化”。
变量赋值的格式是:变量名 = 值;
这个等号"="是一个赋值运算符,将右边的值赋值给左边的变量,也就是将右边的值存储到左边变量的存储空间中。
1 int main() 2 { 3 int i; 4 i = 10; 5 6 char c; 7 c = 'A'; 8 9 return 0; 10 }
在第4行给变量i赋值一个整型常量10,在第7行给变量c赋值一个字符型常量'A'。像第4、7行这样的赋值操作,称为“赋值运算”。
内存中大致如下图所示,整数10存储在i的存储空间中,字母A存储在c的存储空间中。
(其实我这个图并不是很准确,因为内存中的所有数据都是以0和1的形式存储的,比如10,它会存储成1010;字母A,它会存储成1000001。这里为了达到直观的效果,就没有写成二进制形式)

2> 定义的同时初始化
上面的代码也可以写成下面这样,在定义变量的同时进行初始化:变量类型 变量名 = 值;
1 int main() 2 { 3 int i = 10; 4 5 float f = 10.9f; 6 7 double d = 9.8; 8 return 0; 9 }
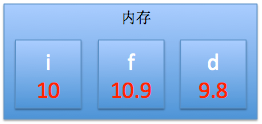
3> 可以不断修改
既然i是个变量,说明它的值可以不断地改变,看下面的代码
1 int main() 2 { 3 int i = 10; 4 5 i = 89; 6 7 char c = 'A'; 8 9 return 0; 10 }
在第3行定义了变量i,并且初始值为10。紧接着在第5行把i的值改为89,这个89会覆盖以前存储的10,内存中大致如下图所示

4> const关键字
刚才提到,默认情况下,变量的值是可以不断改变的。不过,有时候我们会希望变量的值只在定义的时候初始化一次,以后都不能再改变,这个时候我们就可以使用const关键字来修饰变量。
1 int main() 2 { 3 const int i = 10; 4 5 i = 11; 6 7 return 0; 8 }
注意第3行,在int的前面加了个const关键字。表示变量i的值只会初始化一次,也就是说i的值永远都是一开始的10,以后都不能再改了。所以编译器会报第5行代码的错误,不允许再次修改i的值。
4.变量的使用注意
1> 不能重复定义同一个变量
下面的代码是错误的
1 int main() 2 { 3 int i = 10; 4 5 int i = 89; 6 return 0; 7 }
编译器会报第5行的错,错误的原因很简单,第3行和第5行都是定义变量i,因此在内存中会是这样

内存中会出现两块存储空间,而且名字都叫i,那如果我想取出变量i的值,那你说计算机取10好还是取89好呢?因此,这种做法肯定是不可以的。
2> 可以将一个变量的值赋值给另外一个变量
1 int main() 2 { 3 int i = 10; 4 5 int a = i; 6 7 return 0; 8 }
在第3行定义了变量i且初始值为10;接着在第5行定义了变量a,并且将变量i的值赋值给了a。在内存中大致如下图所示:

变量i和变量a存储的值都是10
3> 变量的作用范围(作用域)是从定义变量的那一行代码开始
下面的代码是错误的
1 int main() 2 { 3 int a = i; 4 5 int i = 10; 6 7 int b = i; 8 9 return 0; 10 }
编译器会报第3行的错误,错误原因是:标识符i找不到。我们是在第5行定义了变量i,因此变量i从第5行开始才有效,在前面的第3行是无效的。
一个BUG的发现过程
首先是项目代码:statAd是我的功能模块API,他的功能定义是累加某个广告在某个投放位置的pv和uv(存到一个全局数组LIST里)
详细说明:pv的概念大家很清楚就是浏览广告的人次,uv的概念则是某个时间段内,浏览过的人数(非人次,一人浏览多次算多个PV但只算一个UV);输入其实是已经经过初步计算的数据,它标识了一个人在某个页面浏览过某过个广告的次数,但是一个广告可以投放到多个页面,所以一个人可以在不同页面浏览相同的广告,这在输入数据里就会被当做多笔输入;下面是这个API的输入输出定义
- 输入:userid(用户身份),adid(广告标示),adflag(广告投放位置),pv(该人已在此广告位置浏览了几次,其实多半是刷新)
- 输出:累加输入的广告标示在某广告位置的PV,UV
function statAd(userid, adflag, adid, pv, __ARGVEND__, v, newpv, newuv) { item = adid" "adflag if(item in LIST) { split(LIST[item],v," ") v[1] += pv if(!(item" "userid in ITEM_USERS)) { v[2] += 1 } LIST[item] = v[1]" "v[2] } else { newpv = 1 newuv = 1 LIST[item] = newpv" "newuv ITEM_USERS[item" "userid] } } { userid = $1 adflag = $2 adid = $3 pv = $4 statAd(userid,adflag,adid,pv) }
awk的程序还是比较像javascript的,语法上应该不需要太多说明,需要说明的一定是$1,$2这样的符号,其实这是调用该程序的输入,可以理解为命令行调用时在shell里写入的参数。写好之后觉得很高兴,代码看起来很整洁,很清晰,觉得没有什么问题,就放上线了(是的,我们没有测试)但是呢,觉得自己应该对自己的代码负责,还是应该看看有没有问题
于是造了一个玩具assert函数(awk里没有这样的库函数)
function assert(testConditon, message,__ARGVEND__) { if(! testConditon) { print message exit -1 } }
之后构造测试用例,调用功能模块的API,并将它的输入和预想的结果相比较,这是测试的基本思路,应该不用多说
@include lib/assert.awk @include statapi.awk { x[1] a[1,"userid"] = 100 a[1,"adflag"] = "XX_YY_ZZ_11" a[1,"adid"] = 200 a[1,"pv"] = 12 x[2] a[2,"userid"] = 200 a[2,"adflag"] = "XX_YY_ZZ_11" a[2,"adid"] = 200 a[2,"pv"] = 14 for(i in x) { statAd(a[i,"userid"],a[i,"adflag"],a[i,"adid"],a[i,"pv"]) } for(i in LIST) { print i" "LIST[i] } assert("200 XX_YY_ZZ_11" in LIST,"assertion faild:erro1") assert(LIST["200 XX_YY_ZZ_11"] == "26 2","assertion faild:error2") }
assert函数在assert.awk中,statAd函数在statapi.awk中,测试用例的代码首先把他们include进来,之后开始构造测试数据,一共造了两笔广告浏览记录,表示的是两个用户在同一个地方浏览了相同的广告(多次),应该说是最最最基本的测试用例了,我预想的结果是pv26,uv2,那么输出结果就是"26 2"(这是程序特殊的保存数据的方式造成的,测试应该适应程序的表达方式)但是结果,没有通过!提示assertion faild:error2
因为之前我心里已经认定程序是没有问题的,所以这次这个测试也只是锦上添花的验证性程序(就是想证明自己是对的)没想到程序一下子就告诉我,我挂了,心里的郁闷就别提了,稀里哗啦,开始在功能模块上追加日志:
function statAd(userid, adflag, adid, pv, __ARGVEND__, v, newpv, newuv) { item = adid" "adflag print "debug 1 : "item if(item in LIST) { print"debug 2 : "item" in LIST" split(LIST[item],v," ") v[1] += pv if(!(item" "userid in ITEM_USERS)) { v[2] += 1 } LIST[item] = v[1]" "v[2] print"debug 2.1 : "item" is "LIST[item] } else { print"debug 3 : "item" not in LIST" newpv = 1 newuv = 1 LIST[item] = newpv" "newuv ITEM_USERS[item" "userid] print"debug 3.1 : "item" is "LIST[item] } }
再次执行,输出是
debug 1 : 200 XX_YY_ZZ_11 debug 3 : 200 XX_YY_ZZ_11 not in LIST debug 3.1 : 200 XX_YY_ZZ_11 is 1 1 debug 1 : 200 XX_YY_ZZ_11 debug 2 : 200 XX_YY_ZZ_11 in LIST debug 2.1 : 200 XX_YY_ZZ_11 is 15 2 200 XX_YY_ZZ_11 15 2 assertion faild:error2
一下子发现问题,输出的debug3.1说pv,uv都是1,但是,这里的数据是经过初步统计的,我输入的也不是1,再看代码,原来我就写死了pv,uv都是1,修改代码
function statAd(userid, adflag, adid, pv, __ARGVEND__, v, newpv, newuv) { item = adid" "adflag print "debug 1 : "item if(item in LIST) { print"debug 2 : "item" in LIST" split(LIST[item],v," ") v[1] += pv if(!(item" "userid in ITEM_USERS)) { v[2] += 1 } LIST[item] = v[1]" "v[2] print"debug 2.1 : "item" is "LIST[item] } else { print"debug 3 : "item" not in LIST" newpv = pv #造成bug的地方,修改之 newuv = 1 LIST[item] = newpv" "newuv ITEM_USERS[item" "userid] print"debug 3.1 : "item" is "LIST[item] } }
再运行,输出:
debug 1 : 200 XX_YY_ZZ_11 debug 3 : 200 XX_YY_ZZ_11 not in LIST debug 3.1 : 200 XX_YY_ZZ_11 is 12 1 debug 1 : 200 XX_YY_ZZ_11 debug 2 : 200 XX_YY_ZZ_11 in LIST debug 2.1 : 200 XX_YY_ZZ_11 is 26 2 200 XX_YY_ZZ_11 26 2
好了,这次通过测试用例了,那程序是不是就没有问题了呢,(好吧,我感觉是)但是这个测试用例证明的只是“在不同用户访问同一个位置同一个广告的”情况下是没有问题的。其他情况还是需要进行测试,才能说是没有问题的,我这种资质的人只能通过这样的办法给自己树立信心,我不知道牛人们是不是应该很少犯我犯的错误呢?如果他们能很少犯错,到底是天生呢还是后天锻炼,如果是后天锻炼是通过什么办法锻炼出来的呢,求解
还有,awk看样子很需要log4awk这样的库啊!!!
不幸的,我通过review又发现一个bug(这次倒不是通过测试用例发现)该bug的现象时某些时候同一个用户,对于同一个位置的广告多次访问,他的UV会多累加,这个BUG出现的前提是:1。广告以及他的某个位置已被记录(之后再提及的时候不再强调这个广告和广告的位置都是和这个被记录的广告是相同的了) 2。访问这个广告的用户非让这个广告被记录的用户 3.这个用户会多次访问这个广告(理论上初步统计的程序会把同一个用户对广告A在位置Y上的多次访问捏成一条记录,但是如果出现这情况,程序是不是应该也能容错呢?)
function statAd(userid, adflag, adid, pv, __ARGVEND__, v, newpv, newuv) { item = adid" "adflag print "debug 1 : "item if(item in LIST) { print"debug 2 : "item" in LIST" split(LIST[item],v," ") v[1] += pv if(!(item" "userid in ITEM_USERS)) { v[2] += 1 ITEM_USERS[item" "userid] #其他用户访问已记录的广告,这次访问需要被记录 } LIST[item] = v[1]" "v[2] print"debug 2.1 : "item" is "LIST[item] } else { print"debug 3 : "item" not in LIST" newpv = pv newuv = 1 LIST[item] = newpv" "newuv ITEM_USERS[item" "userid] pdflag -