python 的列表遍历删除
python的列表list可以用for循环进行遍历,实际开发中发现一个问题,就是遍历的时候删除会出错,例如
for i in range(len(l)):
if l[i] == 4:
del l[i]
print l
构建Python+Selenium2自动化测试环境<一>
很久没有了解自动化了,最近发现项目中沉淀了很多东西,回归测试效率很低,所以必须要考虑构建自动化来提供各个环节的小效率。由于忙于需求以及产品的流程规范,现在对于测试技术方面的研究也相对少了很多。不过不管做什么,做好最重要!自动化几年前研究过一套框架,由于各方面原因一直没有推广起来,也导致我的自动化发展之路还没出生就胎死腹中。现在搞自动化主要是出于团队建设考虑,一方面为了提供测试部门的工作效率,保障产品质量;另一方面,也是为了提升团队成员的测试技能,保证Team良性发展。不过不管如何,自动化是必须要搞,不然繁琐的回归测试是没有任何效率保证和质量保障的。
初步计划通过Python作为脚本语言,Selenium作为web端的测试工具,目前主要是基于web端来构建的。本节主要记录简单搭建Python+Selenium测试环境的过程,具体如下:
基础环境:windows 7 64bit
1、构建python开发环境,版本为当前最新版本python2.7.5
在python官方网站选择下载最新windows安装包:python-2.7.5.amd64.msi,注意这里选择64bit的。安装完之后,需要在系统的环境变量path中加入C:\Python27,然后可以在命令行,看到如下:

备注:以上表示,python安装成功,且path配置也ok!
2、SetupTools和pip工具安装,这两个工具都是属于python的第三方工具包软件,有点类似于linux下的安装包软件,不过pip比SetupTools功能更强大。
SetupTools官方解释:Download, build, install, upgrade, and uninstall Python packages -- easily!
在python的官方网站上可以找到SetupTools的下载,这里Windows只提供了32bit的下载,setuptools-0.6c11.win32-py2.7.exe,直接双击安装即可。
pip官方解释:A tool for installing and managing Python packages.
cmd进入命令行:easy_install pip 在线安装即可。
备注:此处需要注意的是,当安装SetupTools之后,就可以在python安装目录下看到Script目录,如下图所示:
这个目录生成之后,需要在系统环境变量的中加入 path:C:\Python27\Scripts,然后才可以在命令使用easy_install命令进行pip在线安装。
3、安装Selenium
这里因为需要将Python和Selenium进行组合,当然Selenium也提供了基于python的实现,所以就需要把Selenium的包安装到python库中去,以便于python开发时进行调用。
在cmd进入命令行:pip install selenium 执行之后,将自动化搜寻最新的selenium版本下载并安装,如下图所示:
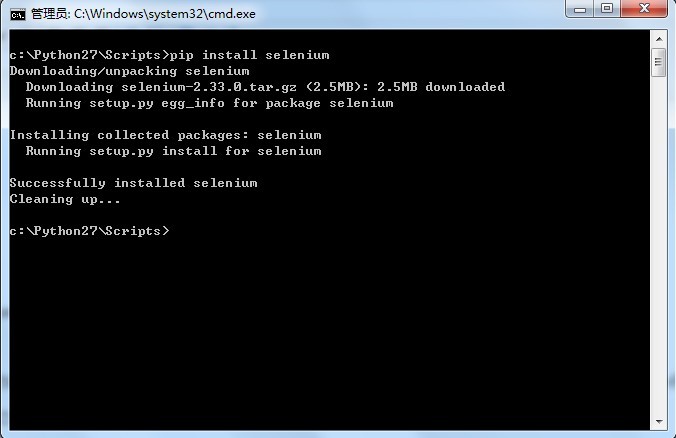
以上显示,则表明在线安装selenium成功!
4、Python+Selenium的Sample
这里可以直接在python的编辑中编写如下程序,并保存hello_selenium.py

1 from selenium import webdriver 2 3 driver = webdriver.Firefox() 4 driver.get("http://www.so.com") 5 assert "360搜索".decode('utf-8') in driver.title 6 7 print driver.title 8 9 driver.close()
在python编辑器里面操作F5运行即可,看看是否成功调用Firefox浏览器。。。
以上一个基础的Python+Selenium的自动化环境已经搭建完成。