Linux操作系统学习_用户态与内核态之切换过程
因为操作系统的很多操作会消耗系统的物理资源,例如创建一个新进程时,要做很多底层的细致工作,如分配物理内存,从父进程拷贝相关信息,拷贝设置页目录、页表等,这些操作显然不能随便让任何程序都可以做,于是就产生了特权级别的概念,与系统相关的一些特别关键性的操作必须由高级别的程序来完成,这样可以做到集中管理,减少有限资源的访问和使用冲突。Intel的X86架构的CPU提供了0到3四个特权级,而在我们Linux操作系统中则主要采用了0和3两个特权级,也就是我们通常所说的内核态和用户态。
运行于用户态的进程可以执行的操作和访问的资源都受到极大的限制,而运行于内核态的进程则可以执行任何操作并且在资源的使用上也没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程。本文主要要介绍的就是这个过程。
这里再明确一个概念,每个进程都有一个4G大小的虚拟地址空间,在这个4G大小的虚拟地址空间中,前0~3G为用户空间,每个进程的用户空间之间是相互独立的,互不相干。而3G~4G为内核空间,因为每个进程都可以从用户态切换到内核态,因此,内核空间对于所有进程来说,可以说是共享的,不过这么说有些不太严谨,应该说内核空间中大部分区域对于所有的进程来说都是共享的,这不共享的小部分区域是存储所有进程内核栈的区域,为什么这么说,因为每个进程都存在一个内核栈,而各个进程的内核栈之间一定是不共享的。关于内核空间的详细描述,参见
了解了上面所说的这些之后,相信对于内核态和用户态的概念已经有了一定的了解,下面正式开始进入由用户态向内核态切换的过程。
首先需要了解,什么情况下会发生从用户态向内核态切换。这里细分为3种情况。
1、发生系统调用时
这是处于用户态的进程主动请求切换到内核态的一种方式。用户态的进程通过系统调用申请使用操作系统提供的系统调用服务例程来处理任务。而系统调用的机制,其核心仍是使用了操作系统为用户特别开发的一个中断机制来实现的,即软中断。
2、产生异常时
当CPU执行运行在用户态下的程序时,发生了某些事先不可知的异常,这时会触发由当前运行的进程切换到处理此异常的内核相关的程序中,也就是转到了内核态,如缺页异常。
3、外设产生中断时
当外围设备完成用户请求的操作后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序,如果先前执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了由用户态到内核态的切换。比如硬盘读写操作的完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
可以看到上述三种由用户态切换到内核态的情况中,只有系统调用是进程主动请求发生切换的,中断和异常都是被动的。
由于系统调用、中断和异常由用户态切换到内核态的机制大同小异,所以这里仅就系统调用的切换过程进行具体说明。
如果一个用户程序需要调用底层的系统接口,如fork等诸如libc里面的系统调用函数,就牵涉到用户态与内核态的切换问题,因为系统调用处理程序都是运行在内核态下。
在系统调用时由于用户态和内核态是运行于两个独立的栈上面,即分别为内核栈和用户栈,因此,不能仅简单的传递函数指针,因为对于内核态堆栈在用户态下是不可见的,所以对于系统调用函数的处理程序对于用户态是不可见的;同时,因为内核栈和用户栈是相互独立的,所以在参数传递的过程中不能使用普通的压栈出栈的方式来进行参数传递。
每一个系统调用函数在内核当中都存在对应的句柄处理函数,一般以sys_开头,这些句柄处理函数作为一个系统调用表形式存在:linux-3.9.4/arch/x86/syscalls/syscall_32.tbl
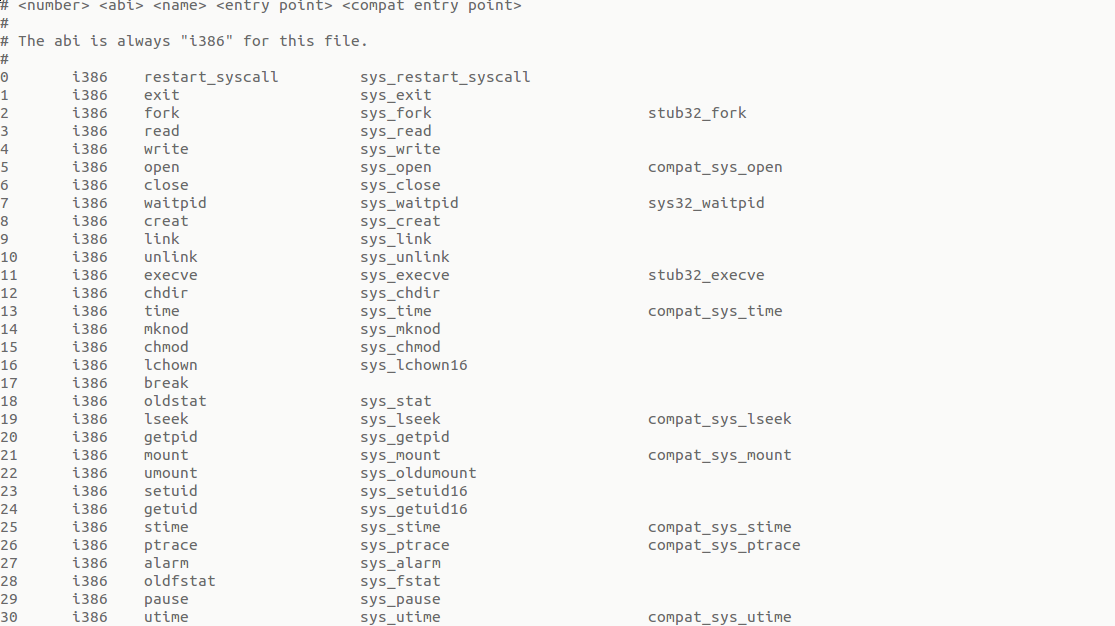
PS:在3.9.4内核中系统调用初始为350个,系统调用的最大个数是动态变化的,即不用如2.6内核中,在添加系统调用时需先查看MAX是否满足,若不满足则需要进行修改。在3.9.4内核中则不需要这个过程,现在编译出的内核其syscall_MAX为351,若添加一个系统调用,则编译出内核之后,该值为352。
每一个系统调用的函数对应着内核里的一个具体实现,每一个系统函数都有一个相应的数字对应,即系统调用号,这个数字事实上是系统调用函数指针的偏移。
当我们运行一个系统调用时,运行时库通过查找这个表来决定对应的函数代码,即系统调用号,然后存入到寄存器中,通常为eax寄存器,然后当切换到到内核态后,内核根据系统调用号来查找到对应的系统调用处理例程的函数名,从而找到对应的代码入口地址。系统调用切换过程如图所示:

因为在前面已经说过,内核栈和用户栈分别处于内核空间和用户空间两个不同的空间中,因此,这两个栈是相互独立的,所以参数传递不能只是简单的压栈出栈,因此,Linux内核中主要是才用寄存器的方式来完成这个任务。
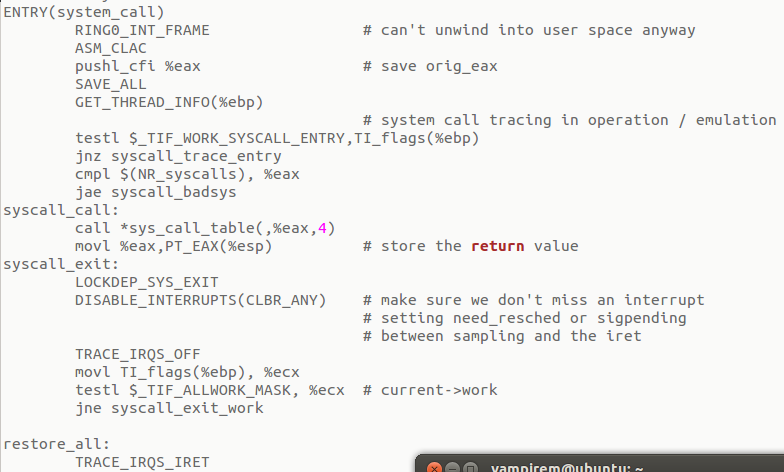
可以看到,在发生系统调用时,先是RING0_INT_FRAME,

可以看到这个过程是对esp和eip进行处理,使其指向内核栈。然后把寄存器eax中的系统调用号入栈,然后SAVE_ALL,
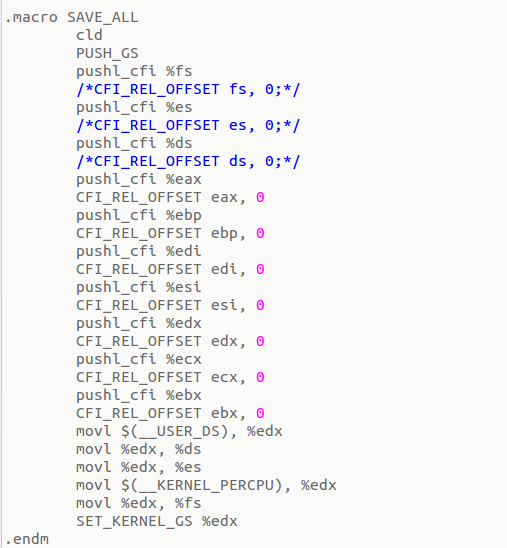
而SAVE_ALL中首先是各个寄存器的入栈操作,即将传递的参数压到内核栈中。到此,完成了由用户态向内核态的切换过程。由于这次时间有限,没有细致的由源码角度去研究这个具体的过程,过段时间有空了,好好研究一下,再进行修改补充。
欢迎大家提出问题,进行交流指导~