SQL语句调优 - 索引上的数据检索方法
如果一张表上没有聚集索引,数据将会随机的顺序存放在表里。以dbo.SalesOrderDetail_TEST为例子。它的上面没有聚集索引,只有一个在SalesOrderID上的非聚集索引。所以表格的每一行记录,不会按照任何顺序,而是随意地存放在Hash里。这个时候如果用户想要找所有单价大于200的销售详细记录,要运行的语句会是:
SET STATISTICS PROFILE ON SELECT SalesOrderDetailID , Unitprice FROM SalesOrderDetail_test WHERE UnitPrice > 200
由于表在UnitPrice上没有索引,所以SQL SERVER不得不对这个表从头到尾扫描一遍,把所有UnitPrice的值大于200的记录一个一个挑出来。

从执行计划里可以清楚地看出来SQL SERVER 这里做了一个表扫描(下图),后面会详细介绍如何得到和分析执行计划

如果这个表上有聚集索引,事情会怎么样呢?还是刚才那张表做例子,先给它的值是唯一的字段 Unitprice上建立一个聚集索引。这样所有的数据都会按照聚集索引的顺序存储。
CREATE CLUSTERED INDEX SalesOrderDetail_TEST_CL ON dbo.SalesOrderDetail_test (SalesOrderDetailID)
可惜的是,查询条件Unitprice上没有索引,所以SQL SERVER还是要把所有记录都扫描一遍。如下图

与之前不同的是,执行计划里的表扫描变成了聚集索引扫描。因为在有聚集索引的表上,数据是直接存放在索引的最底层的,所以要扫描整个表格的数据,就是把整个聚集索引扫描一遍。在这里,聚集索引扫描就相当于一个表扫描。所要用的时间和资源与表扫描没有什么差别。并不是说这里有了”Index”这个字样,就说明执行计划比表扫描的有多大进步。当然反过来讲,如果看到”Table Scan”的字样,就说明这个表格上没有聚集索引。
现在在 UnitPrice 上面建一个非聚集索引,看看情况会有什么变化
CREATE NONCLUSTERED INDEX SalesOrderDetail_TEST_NCL_Price ON dbo.SalesOrderDetail_test (UnitPrice)
再次查询
SET STATISTICS PROFILE ON SELECT SalesOrderDetailID , Unitprice FROM SalesOrderDetail_test WHERE UnitPrice > 200
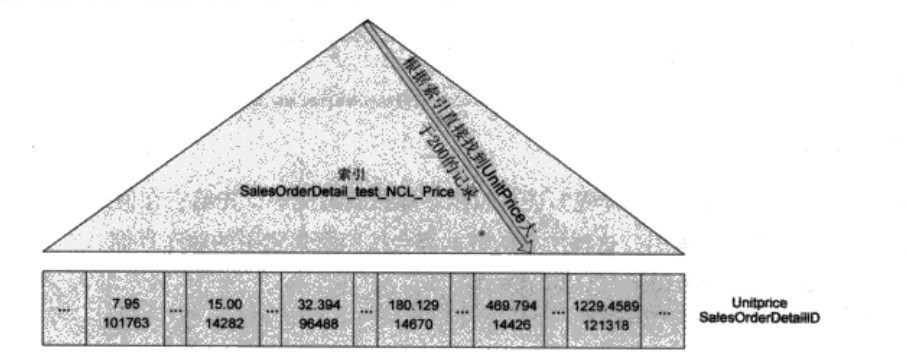

在非聚集索引里,会为每条记录存储一份非聚集索引索引键的值和一份聚集索引索引键的值(在没有聚集索引的表格里,是RID值)。所以在这里,每条记录都会有一份 SalesOrderDetailID和UnitPrice记录,按照UnitPrice的顺序存放。再查询,就会看到这次的SQL SERVER不是扫描整个表,会根据新建的索引直接找到符合的记录的值。
但是光用UnitPrice建立在上的索引不能告诉我们其它字段的值。如果在刚才那个查询里再增加几个字段返回,SQL SERVER 就要先在非聚集索引上找到所有UnitPrice大于200的记录,然后再根据SalesOrderDetailID的值找到存储在聚集索引上的详细数据。这个过程可以称为 “Bookmark Loopup”
SET STATISTICS PROFILE ON SELECT SalesOrderId,SalesOrderDetailID , Unitprice FROM SalesOrderDetail_test with(index = SalesOrderDetail_TEST_NCL_Price) WHERE UnitPrice > 200
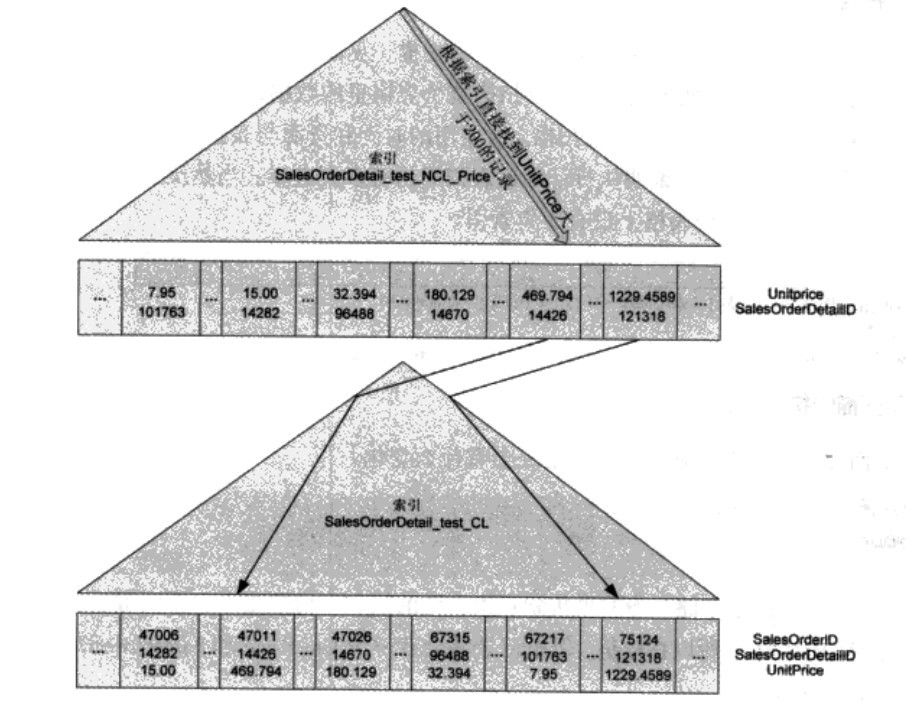
在SQL SERVER 2005以后,Bookmark Loopup 的动作用一个嵌套循环来完成。所以在执行计划里,可以看到SQL SERVR是先SEEK了非聚集索引,然后再用Clustered Index Seek 把需要的行找出来。这里的嵌套循环其实就是 Bookmark Loopup 如下图。

注:Bookmark Loopup就是聚集索引
在SQL SERVER里根据数据找寻目标的不同和方法不同。有下面几种情况。
|
结构 |
Scan |
Seek |
|
堆(没有聚集索引的表) |
Tablescan |
无 |
|
聚集索引 |
Clustered Index Scan |
Clustered Index Seek |
|
非聚集索引 |
Index Scan |
Index Seek |
如果在执行计划里看到这些动作,就应该能够知道SQL SERVER正在对哪种对象在做什么样的操作。表扫描表明正在处理的表没有聚集索引,SQL SERVER正在扫描整张表。聚集索引扫描表明SQL SERVER正在扫描一张有聚集索引的表,但是也会是整表扫描。Index Scan表明SQL SERVER正在扫描一个非聚集索引。由于非聚集索引上一般只会有一小部分字段,所以这些虽然也是扫描,但是代价会比整表扫描要小很多。Clustered Index Seek 和Index Seek会比Scan 说明SQL SERVER正在利用索引结果检索目标数据。如果结果集只占表格总数据量的一小部分,Seek 会比Scan便宜很多,索引就起到了提高性能的作用。
了解这些是为以后读懂执行计划做基础。水平有限,暂时为这些吧。大家可以多多交流。
下一次会写统计信息的东西,可能会稍多一些。上述一语句均为上一次发博客的脚本为例。