SQL索引学习-聚集索引
这篇接着我们的索引学习系列,这次主要来分享一些有关聚集索引的问题。上一篇SQL索引学习-索引结构主要是从一些基础概念上给大家分享了我的理解,没有实例,有朋友就提到了聚集索引的问题,这里列出来一下:

- 其实,我想知道的就是对于一个大数据量的表,我应该用哪种索引,各有什么优缺点。如果能带一两个实例,就更perfect了。
- 看过很多这样文章,但具体还是不知道如何设计表和优化,比如:聚集和非聚集, 唯一与主键, 设计表事该如何取舍。应该有示例说明,这更容易理解,只是概念即使理解了也不容易消化。
上面两位朋友的问题有一个共同特点,就是希望有示例,因为这样容易让他们更加容易理解。但从我的角度来讲,有示例只能给你提供一个参考而已,够不成是否容易消化的关键因素,最好的办法是,通过自己的理解,自己有能力去做相应的实验,这样效果才是最好的,你也会发现更多的问题,每个项目都有自己的特点,所以性能优化这块也是需要因地制宜的。
聚集索引的存储结构

聚集索引的特点
- 索引的数据以及实际物理数据存储于同一张表中,这与非聚集索引不相同
- 物理数据或者叫关键字出现在叶子结点的双向链表中
- 非叶子结点不可能出现物理数据或者叫关键字
- 非叶子结点相当于叶子结点的索引
B+树的结构
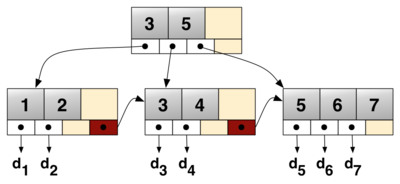
- 1,2,3,4,5,6,7为Key
- d1,d2,d3,d4,d5,d6,d7分别是数据
- 红色框是链接下一节点的指针
它的结构完全符合聚集索引的存储结构,所以我们说聚集索引的存储结构为B+树。
聚集索引的重要性
聚集索引的选择是数据库设计的基石,不好的聚集索引设计不光是增加查询的执行时间,而且是一个瀑布性的影响:
- 增加硬盘空间,和选择的数据列的大小有直接关系
- 效率低下的IO,也许会产生更多的数据页,或者发生随机性的数据页切换等
- 索引碎片的增加
- ......
如何选择表的聚集索引
一般可以优先参考如下因素:
- 列数据宽度要小或者叫窄列,比如int就只有4字节,这个宽度越小越好,因为可以在同样的空间中存储更多的索引数据
- 唯一性,虽然聚集索引并没强制要求列字段是唯一的,但在系统内部会在具备有重复值的列上增加一个标识位来区分,实际内部还是唯一的,所以尽量选择重复值很少最好是没有重复值的列,因为SQL Sever要额外的去维护这些标识
- 静态的,不易更改的列,很少发生变更最好是从不修改这列的值,因为它也许会引起数据的移动
- 递增性的,用来避免索引碎片,这样SQL Server每次在插入数据的时候都会将新记录追加在最新一条记录的后面,不会因此影响之前插入的数据顺序。
窄列
创建如下表,为了测试只包含两个字段,一个在类型为Int的Id上创建聚集索引,一个在类型为uniqueindentifier的Code上创建聚集索引,且为唯一聚集索引。
CREATE TABLE dbo.NarrowStudent ( Id INT IDENTITY(1, 1) , -- unique Code UNIQUEIDENTIFIER -- unique ) ; CREATE UNIQUE CLUSTERED INDEX PK_NarrowStudent_IdON NarrowStudent(Id)CREATE TABLE dbo.Student ( Id INT IDENTITY(1, 1) , -- unique Code UNIQUEIDENTIFIER -- unique ) ; CREATE UNIQUE CLUSTERED INDEX PK_Student_CodeON Student(Code) |
再分别插入一条数据:
INSERT INTO dbo.NarrowStudent ( Code )VALUES ( NEWID() -- Code - uniqueidentifier ) INSERT INTO dbo.Student ( Code )VALUES ( NEWID() -- Code - uniqueidentifier ) |
看下行大小:
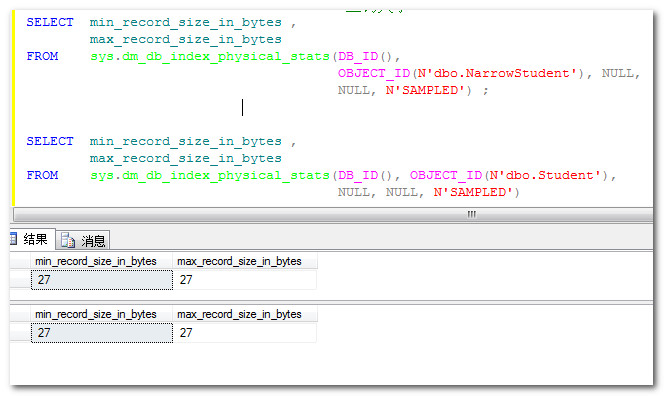
注意为什么宽度为27而不是20呢(Id类型为int,占用4字节,Code为Guid占用16字节),这是SQL Sever内部为了维护可空值或者是可变长值而预留7位空间。
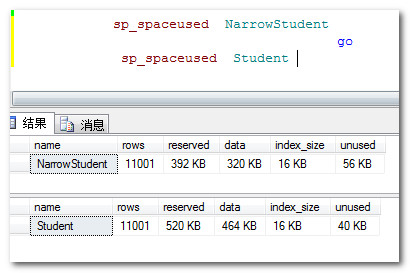
我们再多插入些数据来做对比,插入的脚本就贴了,然后我们看下两表所占用的空间对比:采用了int做为主键的表数据占用为320K,选用Guid为主键的表占用为464K,明显较int要费磁盘空间。
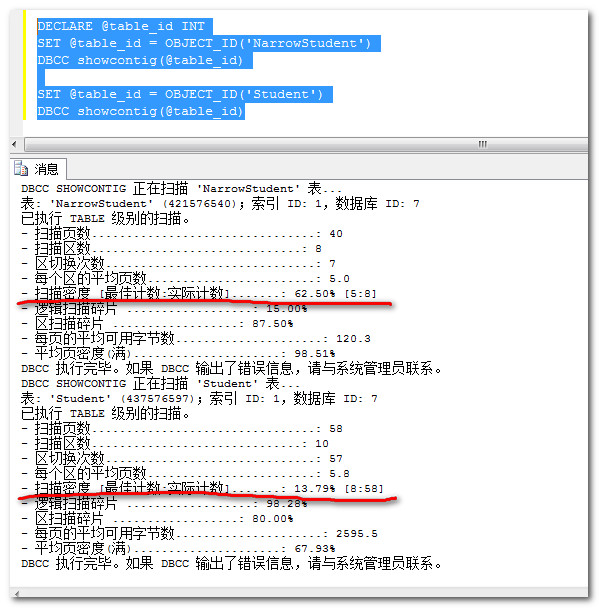
索引健康情况
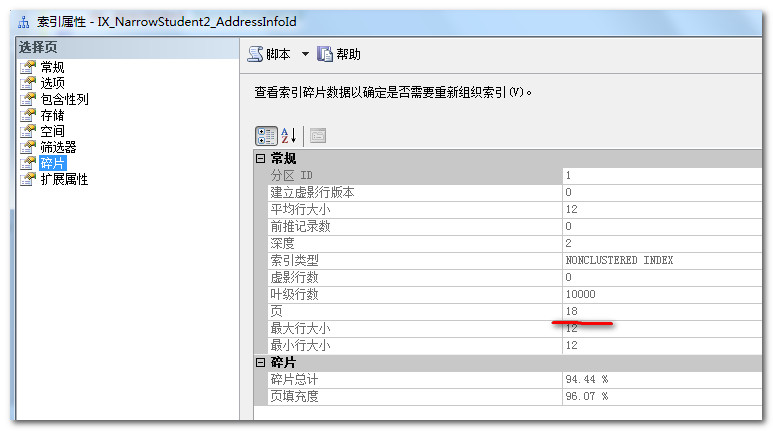
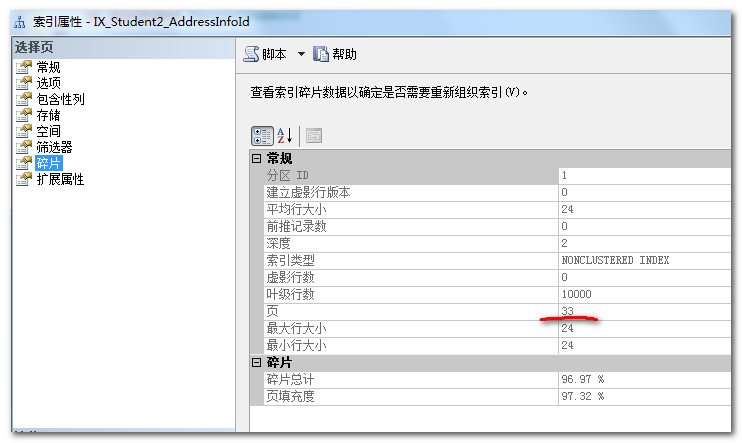
下图中红线部分有一个非常重要的参数:扫描密度,明显可以看出在连续对表进行数据插入后,int自增性为主键的索引密度比Guid为主键的索引密度要大的多。这说明前者产生的索引碎片更低。
聚集索引对非聚集索引的影响
两者最大的区别在于聚集索引的叶级存储了数据本身,但非聚集索引叶结点不存在数据记录,只是一个指向聚集索引的指针,这就意味着在非聚集索引的所有级别中都包含了聚集索引的指针,聚集索引的大小会直接影响非聚集索引的大小。
为上面两个表,增加一个AddressInfo的字段,且创建非聚集索引,这里为了测试的有效性,不要使用如下语句添加列之后做测试,因为后期表结构的变更会引起比较明显的数据分页情况,建议创建新表来测试,下面对比在两个表中,字段类型以及值者相同以及表数据条数一样的情况下非聚集索引的大小情况,结论是在其它条件都相同的情况下,谁的主键大谁占用的索引空间就更大。
主键为int的非聚集索引
主键为Guid的非聚集索引
唯一性
上面提到过聚集索引可以选择具有重复值的列,但在内部会维护一个类型为uniqueifier的字段,长度为4字节,同时还会需要维护可变长列,同样会占用4字节,所以SQL Server会使每行的大小增加8字节,数据类似如下表格:
| Id | First Name | uniqueifier |
| 1 | Tom | NULL |
| 2 | Tom | 1 |
| 3 | Andy | Null |
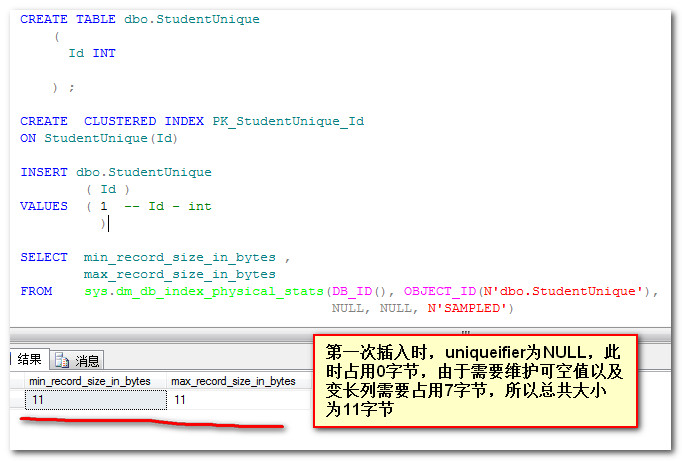
关键字第一次出现时,uniqueifier赋值为NULL,当第二次出现时,就开始计数累加。赋值为NULL时占用0字节,可从如一图得到结果:
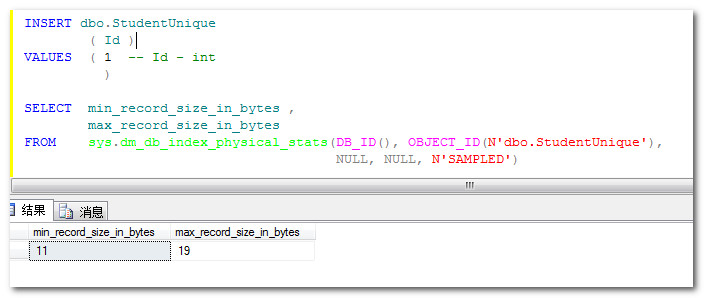
再插入一条重复数据之后再查看行大小,由11字节变成19字节了,这多出来的8字节,就是当uniqueifier值不等于空之后的结果。
这里列一个场景:如果选择一个时间字段做为主键的话,此时瞬间批量插入多条数据,那么时间在某一批数据中都是相同的,这时就需要频繁维护uniqueifier。重复的数据越多,后续索引的命中就会越困难,同时由于行大小变大会降低磁盘空间的应用,从而降低IO性能。
这篇内容比较长,先讲其中的窄列以及唯一性这两原则吧,这只是从性能角度来区分,没有涉及具体业务,所以并不是说一定要按此标准来选择聚集索引,后面再分析其它的几条规则。
SQLSERVER新建表的时候页面分配情况是怎样的?
SQLSERVER新建表的时候页面分配情况是怎样的?
再次感谢sqlskill网站和转载sqlskill网站文章并翻译的人,因为您们的转载和翻译让小弟又学习到新的东西o(∩_∩)o
文章中用到的工具:查看SQLSERVER内部数据页面的小插件Internals Viewer
参考文章:http://www.cnblogs.com/wcyao/archive/2011/06/28/2092270.html
在往下看之前,请看一下混合区和统一区的解释,如果不明白的话,大家可以百度一下“SQLSERVER混合区 统一区”
统一区:由单个对象所有。区中的所有8页只能由一个对象使用
混合区:最多可由8个对象共享。区中8页的每页可由不同对象所有。但是一页总是只能属于一个对象
先建立四张表,堆表、聚集索引表、非聚集索引表、聚集索引和非聚集索引表
这些表的特点:一行记录刚好占用一页
我们要先建立一张,分析完毕drop掉表,然后再建立另一张,这样可以看得更加清楚
新建数据库
 View Code
View Code建立测试表
1 CREATE TABLE heaptable(c1 INT IDENTITY(1,1), c2 VARCHAR (5000)) 2 GO
插入测试数据
View Code查询数据
1 SELECT * FROM heaptable ORDER BY [c1] ASC

建立DBCCResult表
View Code查看DBCC IND的结果
View Code
除了IAM页,表中有20个数据页
查看IAM页的情况,IAM页面号为80
View Code
根据参考文章,SQLSERVER在新建表的时候,会先在混合区分配页面,当表中的数据超过8个页面的时候,会寻找数据库中的统一区,
并且在统一区分配页面,在混合区分配的页面一般靠近数据库的开头的空间,在统一区分配的页面一般靠近数据库的结尾的空间
并且,在混合区分配的页面是分散的,在统一区分配的页面是连续的
参考文章地址:http://www.cnblogs.com/wcyao/archive/2011/06/28/2092270.html
通过DBCC PAGE命令看到IAM页面中间部分,中间部分记录了,表中哪些数据页在混合区,哪些数据页在统一区

SQLSERVER先在混合区分配了77、89、109、114、120、174、45、78这些页面
然后在176到191页面区间中分配统一区的页面,IAM页并没有记录统一区中的页面具体在哪一页,
只是指出统一区分配的页面在176到191页面区间中
我们借助SSMS的插件Internals Viewer从宏观的角度去观察页面分配情况

绿色的小方格代表heaptable表在数据库中占用情况
可以看到前8个页面是分散的,而且都在混合区,从第9个页面开始连续,并且都在统一区
大家将鼠标放上去绿色小方格上就可以看到页面号
详细可以参考:查看SQLSERVER内部数据页面的小插件Internals Viewer
在混合区里的页面分别是:174、120、114、109、89、78、77、45

我们点击PFS按钮,看一下那分散的8个页面是否在混合区

页面45

页面77

页面78

页面89

页面109

页面114

页面120

页面174

再对比一下IAM页面中记录的混合区里的页面
刚才我们在Internals Viewer里看到混合区里的页面分别是:174、120、114、109、89、78、77、45
在混合区分配的页面一般靠近数据库的开头的空间,在统一区分配的页面一般靠近数据库的结尾的空间

并且,在混合区分配的页面是分散的,在统一区分配的页面是连续的

在176到191页面区间中分配统一区的页面,IAM页并没有记录统一区中的页面具体在哪一页,
只是指出统一区分配的页面在176到191页面区间中


不在混合区

这里刚好表在统一区分配的最后一页在IAM分配中统一区区间的最后一页是一样的,都是页面191,如果表比较大,
不可能是一样的
我们drop掉heaptable表,建立clusteredtable表
View Code建立索引
View Code插入测试数据
View Code查询数据
View Code
查看DBCC IND的结果
View Code
除了IAM页,表中有20个数据页和一个聚集索引页面
查看IAM页的情况,IAM页面号为120
View Code View Code
从上图看到,在混合区的页面分别是:45、77、80、89、109、115、114、174

clusteredtable表和heaptable表的情况一样,这里就不一一详述了
我们drop掉clusteredtable表,建立nonclusteredtable表
View Code建立索引
View Code插入测试数据
View Code查询数据
View Code 
查看DBCC IND的结果
View Code
除了IAM页,表中有20个数据页和一个非聚集索引页面
查看IAM页的情况,IAM页面号为89和77

从上图可以看出89这个IAM页面是维系着非聚集索引的,77这个页面是维系着堆中的数据页面的
如果大家想深入了解IAM页面,为什么非聚集索引会有一个IAM页面维系?其实聚集索引也有的
View Code非聚集索引分配在混合区里,并且在80这个页面
更多详细的请看:http://www.cnblogs.com/wcyao/archive/2011/06/28/2092270.html
我们查看77这个页面,因为数据分布都记录在77这个IAM页面
View Code View Code ,
,
从上图看到,在混合区的页面分别是:45、47、78、90、109、115、114、120、174

nonclusteredtable表和heaptable表的情况一样,这里就不一一详述了
这里要说一下
如果表中有索引,不管聚集索引还是非聚集索引,索引页超出8个,那么前8个页面都在混合区中分配
实际上索引页面的分配规则跟数据页面的分配规则是一样的
为了验证这个,我们向非聚集索引表nonclusteredtable插入更多数据,以求让非聚集索引页面超过8个
View Code
现在nonclusteredtable表有10019条记录
我们看一下IAM页
View Code
只有两个IAM页面,其中IAM页面109维系着非聚集索引页面
我们看一下非聚集索引页面
View Code非聚集索引页面有20页
我们看一下IAM109页面
View Code View Code
在混合区的非聚集索引页面有:47、79、89、93、115、118、175、121
我们使用Internals Viewer看一下非聚集索引页面分配情况


我们关注黄色的小方格,黄色的小方格代表非聚集索引页面
我们使用滚动条往下拉


因为表中的数据页面太多,点击PFS按钮,电脑就会死机,我们使用另外一种方法,查看非聚集索引页面是否在混合区/统一区

我们将鼠标放上去黄色的小方格上,看一下在混合区中的非聚集索引页的页面号

通过这种方法,在混合区中的非聚集索引页面号分别为:47、79、89、93、115、118、121、175
刚才在IAM页里看到:在混合区的非聚集索引页面有:47、79、89、93、115、118、175、121
我们使用DBCC PAGE命令,就可以看到非聚集索引页面是否在混合区
View Code View Code
可以看到页面47是分配在混合区
我们看一下统一区中的情况

非聚集索引页面3944是在统一区的
DBCC PAGE命令
View Code View Code
非聚集索引页面3944在统一区分配
为了节省篇幅,在混合区中的其他页面和在统一区中的其他页面这里就不一一测试了,使用DBCC PAGE命令就可以了
通过上面实验就可以证明:索引页面的分配规则跟数据页面的分配规则是一样的
我们drop掉nonclusteredtable表,并收缩数据库,然后建立clusteredandnonclusteredtable表
View Code建立索引
View Code插入测试数据
View Code查询数据
View Code
查看DBCC IND的结果
View Code
除了IAM页,表中有20个数据页和一个非聚集索引页面、一个聚集索引页面
查看IAM页的情况,IAM页面110记录了非聚集索引页面的情况
我们查看IAM页面78的情况
View Code View Code
从上图看到,在混合区的页面分别是:47、79、93、115、118、120、121、174

clusteredandnonclusteredtable表和clusteredtable表的情况差不多,这里就不一一详述了
那么表中的数据页少于8个是怎样的?
先drop掉clusteredandnonclusteredtable表,再收缩数据库,然后重新建立heaptable表
View Code插入测试数据
View Code查询数据
View Code

只有3个数据页面在混合区
再次说明了SQLSERVER先在混合区分配页面,再在统一区分配页面
那么,SQLSERVER是否在数据库没有空间的时候,等待数据库空间增长,然后增长好之后再在统一区分配页面呢?
我们先drop掉ALLOCATIONDB数据库,然后重新建立ALLOCATIONDB数据库,并设置初始大小为3MB,每次增长1MB
View Code重新建立heaptable表
View Code插入数据
View Code看一下页面情况


再插入数据
View Code


总结
说了这麽多终于到总结了
为什麽SQLSERVER会有这种机制,先在混合区分配页面,再在统一区分配页面??
个人觉得和IAM页总是在混合区分配一样,为了节省空间,当一个表不足8页的时候,就不用在统一区分配空间
如果一开始就在统一区分配空间,比如一张表有3页,那么SQLSERVER还需要新建5个同属于同一张表的空白页面,这样就浪费空间了
中秋节假期还在家里研究SQLSERVER,也许没有女朋友就是这样,研究SQLSERVER也是一种寄托吧。。。。。。
如有不对的地方,欢迎大家拍砖o(∩_∩)o
--------------------------------
补充
IAM页面和数据页面怎麽查看在混合区还是在统一区 ,下面页面14515是一个IAM页面
View Code View Code
下面14518是一个数据页面
View Code View Code
