C# 求精简用一行代码完成的多项判断 重复赋值
哈哈,说实话,个人看着这么长的三元操作也麻烦,但是我也只想到了这样三元判断句中执行方法体能够写到一行,追求的终极目的是,用一行实现这个过程,而且简单,由于篇幅,我就不截图我其实是放在一行上的
讨论的重点是怎么做的更极致,而不是这样搞规范不规范,求更有创意的写法。。。
。。 。。华丽丽的分割线。。 。。
var turecolor = colorJToken.OfType<JProperty>().Sum(d => (int)d.Value << "bgra".IndexOf(d.Name) * 8).ToString("X8");
如果是处理颜色,相信 Choo给出的写法想必是极好的,那么如果扩展成普通的用法呢?
。。 。。华丽丽的分割线。。 。。
刚说不实用,先不讨论是不是实用,也不管可读性,单纯的想把代码写在一行上,而且写的少,总结一下,主要内容在这,我想到的写到一行的方法是在三元判断句中执行方法体
bool b = 1 == 1 ? ((Func<bool>)(() => true)).Invoke() : ((Func<bool>)(() => false)).Invoke();
能不能继续精简这样一句话?
鬼柒 在评论中提出了直接纯赋值的写法,嗯,这个在不需要做额外判断的时候好了太多,那么现在的场景是,需要进行判断赋值的话,怎么样写呢?
( Name == "a" ? alph = (Byte)Value : Name == "r" ? red = (Byte)Value : Name == "g" ? green = (Byte)Value : Name == "b" ? blue = (Byte)Value).ToString(0);
。。 。。华丽丽的分割线。。 。。
其中 color仅仅为一个普通的JToken类型,需要精简的是,对于循环重复赋值上,能不能有更简单而且简洁的写法。。。
需求是,用一行完成,且必须有能够执行多判断的地方


Byte red = 0, green = 0, blue = 0, alph = 255; JToken colorJToken = CurrentVersion < ColorVersion ? color.FirstOrDefault() : color; if (colorJToken != null) { foreach (var item in colorJToken) { var colorJProperty = item as JProperty; if (colorJProperty != null && colorJProperty.Value != null) { //以下求精简 (colorJProperty.Name == "a" ? ((Func<bool>)(() => colorJProperty.Value is Byte && (alph = (Byte)colorJProperty.Value).Equals(alph))).Invoke() : (colorJProperty.Name == "r" ? ((Func<bool>)(() => (red = (Byte)colorJProperty.Value).Equals(red))).Invoke() : (colorJProperty.Name == "g" ? ((Func<bool>)(() => (green = (Byte)colorJProperty.Value).Equals(green))).Invoke() : (colorJProperty.Name == "b" ? ((Func<bool>)(() => (blue = (Byte)colorJProperty.Value).Equals(blue))).Invoke() : ((Func<bool>)(() => false)).Invoke())))).ToString(); } } }
1.高效的数据写入(put)
“锁分离” 技术
2.巧妙的数据移除(remove)

|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
void removeEntry(HashEntry entry, int hash) {
int c = count - 1; AtomicReferenceArray<HashEntry> tab = table; int index = hash & (tab.length() - 1); HashEntry first = tab.get(index); for (HashEntry e = first; e != null; e = e.next) { if (e == entry) { ++modCount; // 从链表1中删除元素entry,且返回链表2的头节点 HashEntry newFirst = removeEntryFromChain(first, entry); // 将链表2的新的头节点设置到segment的table中 tab.set(index, newFirst); count = c; // write-volatile,segment内的元素个数-1 return; } } } HashEntry removeEntryFromChain(HashEntry first, HashEntry entry) { HashEntry newFirst = entry.next; // 从链条1的头节点first开始迭代到需要删除的节点entry for (HashEntry e = first; e != entry; e = e.next) { // 拷贝e的属性,并作为链条2的临时头节点 newFirst = copyEntry(e, newFirst); } accessQueue.remove(entry); return newFirst; } HashEntry copyEntry(HashEntry original, HashEntry newNext) { // 属性拷贝 HashEntry newEntry = new HashEntry(original.getKey(), original.getHash(), newNext, original.value); copyAccessEntry(original, newEntry); return newEntry; } |
3.按需扩容机制(rehash)
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
void rehash() {
/** * .... 部分代码省略 */ for (int oldIndex = 0; oldIndex < oldCapacity; ++oldIndex) { HashEntry head = oldTable.get(oldIndex); if (head != null) { HashEntry next = head.next; int headIndex = head.getHash() & newMask; // next为空代表这个链表就只有一个元素,直接把这个元素设置到新数组中 if (next == null) { newTable.set(headIndex, head); } else { // 有多个元素时 HashEntry tail = head; int tailIndex = headIndex; // 从head开始,一直到链条末尾,找到最后一个下标与head下标不一致的元素 for (HashEntry e = next; e != null; e = e.next) { int newIndex = e.getHash() & newMask; if (newIndex != tailIndex) { // 这里的找到后没有退出循环,继续找下一个不一致的下标 tailIndex = newIndex; tail = e; } } // 找到的是最后一个不一致的,所以tail往后的都是一致的下标 newTable.set(tailIndex, tail); // 在这之前的元素下标有可能一样,也有可能不一样,所以把前面的元素重新复制一遍放到新数组中 for (HashEntry e = head; e != tail; e = e.next) { int newIndex = e.getHash() & newMask; HashEntry newNext = newTable.get(newIndex); HashEntry newFirst = copyEntry(e, newNext); if (newFirst != null) { newTable.set(newIndex, newFirst); } else { accessQueue.remove(e); newCount--; } } } } } table = newTable; this.count = newCount; } |
既然叫做缓存,则必定存在缓存过期的概念。为了提高性能,读写数据时需要自动延长缓存过期时间。又因为我们这里所讲的缓存有持久化操作,则要求数据写入DB之前缓存不能过期。
时间轴
删除指定元素的先进先出队列AccessQueue
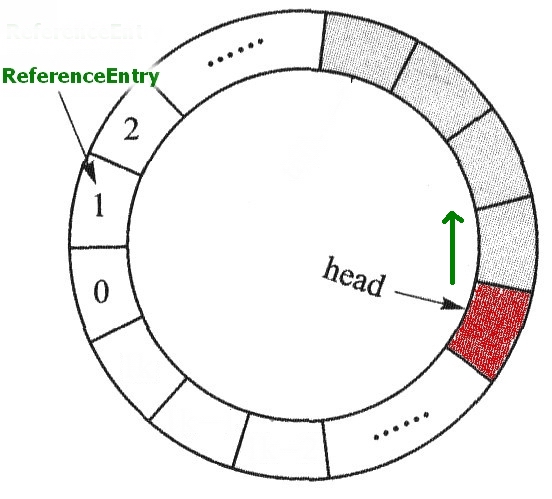
|
1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
static final class AccessQueue extends AbstractQueue<ReferenceEntry> {
// head代码省略 final ReferenceEntry head = XXX; // 其他部分代码省略 @Override public boolean offer(ReferenceEntry entry) { // 将上一个节点与下一个节点链接,也就是把entry从链表中移除 connectAccessOrder(entry.getPreviousInAccessQueue(), entry.getNextInAccessQueue()); // 添加到链表tail connectAccessOrder(head.getPreviousInAccessQueue(), entry); connectAccessOrder(entry, head); return true; } @Override public ReferenceEntry peek() { // 从head开始获取 ReferenceEntry next = head.getNextInAccessQueue(); return (next == head) ? null : next; } @Override public boolean remove(Object o) { ReferenceEntry e = (ReferenceEntry) o; ReferenceEntry previous = e.getPreviousInAccessQueue(); ReferenceEntry next = e.getNextInAccessQueue(); // 将上一个节点与下一个节点链接 connectAccessOrder(previous, next); // 方便GC回收 nullifyAccessOrder(e); return next != NullEntry.INSTANCE; } } // 将previous与next链接起来 static void connectAccessOrder(ReferenceEntry previous, ReferenceEntry next) { previous.setNextInAccessQueue(next); next.setPreviousInAccessQueue(previous); } // 将nulled的previousAccess和nextAccess都设为nullEntry,方便GC回收nulled static void nullifyAccessOrder(ReferenceEntry nulled) { ReferenceEntry nullEntry = nullEntry(); nulled.setNextInAccessQueue(nullEntry); nulled.setPreviousInAccessQueue(nullEntry); } |
何时进行过期移除?
|
1
2 3 4 5 6 7 |
void postReadCleanup() {
// 作为位操作的mask(DRAIN_THRESHOLD),必须是(2^n)-1,也就是1111的二进制格式 if ((readCount.incrementAndGet() & DRAIN_THRESHOLD) == 0) { // 代表每2^n执行一次 cleanUp(); } } |
|
1
2 3 4 5 6 7 8 9 10 11 |
void expireEntries(long now) {
drainRecencyQueue(); ReferenceEntry e; // 从头部获取,过期且已保存db则移除 while ((e = accessQueue.peek()) != null && map.isExpired(e, now)) { if (e.getValue().isAllPersist()) { removeEntry((HashEntry) e, e.getHash()); } } } |