《30天自制操作系统》实现中文显示
《30天自制操作系统》最近一直再看,最近已经看到后面了,看到第28天,里面讲到可以实现对全角字符的支持,而原操作系统代码里面只是支持了日语显示,而中文版的这本书也只是讲了一个思路,具体的实现也是没有的。网上也好像没有人实现过这个吧,我是找不到。(由于书中每一章每一小节都有代码,我看书的时候就懒得去实际写代码,就简单看看。不过这次就可以写一下了,加深对这个系统的了解)反正没事做,就准备实现对这个系统的汉字全角支持。
一、了解HZK编码
在改造之前,我们先了解一下符合GB2312标准的中文点阵字库文件的HZK16。百度搜索HZK16第一个那个百度百科连接就是了。
HZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。其中一级汉字有3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为A1A1~FEFE。A1-A9为符号区,B0到F7为汉字区。每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。下面以汉字“我”为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。其中,每个区记录94个汉字,位号为该字在该区中的位置。
区码和区号,其实是一个东西
区码:区号(汉字的第一个字节)- 0xa0 (因为汉字编码是从0xa0区开始的,所以文件最前面就是从0xa0区开始,要算出相对区码)
位码:位号(汉字的第二个字节)- 0xa0
这样我们就可以得到汉字在HZK16中的绝对偏移位置:
offset=(94*(区码-1)+(位码-1))*32
注解: 1、区码减1是因为数组是以0为开始而区号位号是以1为开始的
2、(94*(区号-1)+位号-1)是一个汉字字模占用的字节数
3、最后乘以32是因为汉字库文应从该位置起的32字节信息记录该字的字模信息(前面提到一个汉字要有32个字节显示)
二、添加代码
首先查看一下c语言里面的中文编码是否真的跟书上讲的是否一样。我们先修改iroha/iroha.c这个文件,代码如下
 View Code
View Code运行的结果为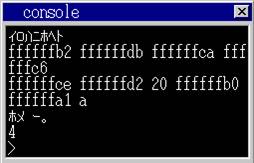
可以看出0xce 0xd2 0x20 0xb0 0xa1 0x0a 分别表示0x20是空格 0x0a是回车,看来我当前系统windows7下的作者默认编译器,编译的结构是符合EUC方式。我们就可以继续了。我们以harib26a这个进行改造。
首先我们下载一个HZK16的字库文件放到nihongo/HZK16.fnt,修改所有makefile文件harib26/Makefile和harib26/app_make.txt.更改这两个文件里面的nihongo.fnt为HZK16.fnt.
接着修改haribote/bootpack.c里面约109行处修改所载入库文件的大小,由于日文的nihongo.fnt比HZK16.fnt小所以要改大一点。至于多大,一般想法是右键属性查看HZK16的文件大小,不过我是写上
nihongo = (unsigned char *) memman_alloc_4k(memman, 0x5d5d*32);
因为0XFEFE-0XA1A1=0X5D5D.
往下三行,修改做载入字库文件的文件名
finfo = file_search("HZK16.fnt", (struct FILEINFO *) (ADR_DISKIMG + 0x002600), 224);
由于我们是增加汉字的支持所以我想定义task->langmode=3为汉字。我们在haribot/console.c约39行处加上一句task->langmode=3表示汉字。使每次都选择汉字。
接下来就是输出了,这次是在haribote/graphic.c约168行处增加下面一段代码
View Code增加一个可以查看效果的程序,我们以chklang/chklang.c这个小程序为例吧。
View Code 大概就修改这些了吧,根据书中这样修改,好像也不是很难嘛。好了我们make run一下。结果竟然是?????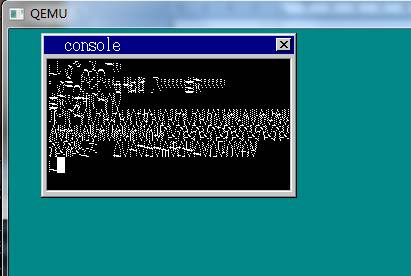
万恶的马赛克?????
三、再次了解HZK这个编码
果然还是功夫不到家。没有仔细的看代码。我们先了解一下字库,我下载了一个软件用于字库的生成和查看,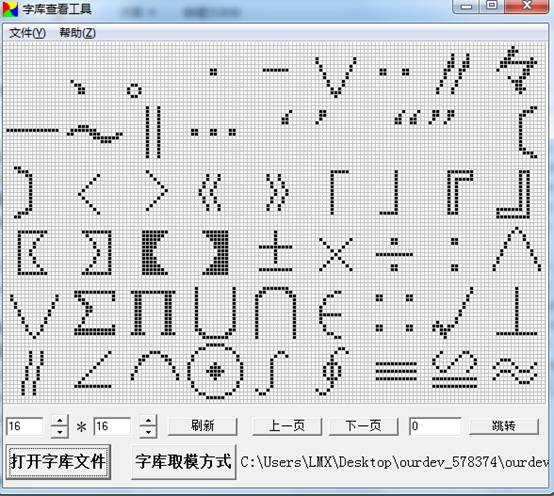
可以正常的显示,用这个软件打开系统自带的日文字库,是显示乱码的。我但是就在想我们系统显示乱码是不是编码方式不同还是因为压缩的原因,试着好多种办法。
这时想到了一个问题,自带的日文字库,好像是前半部分是半角,后半部分是全角。也就是做一个字库里面已经有了ASCII 256个半角在字库开头,而我们的HZK16,看上面我们也知道,HZK开头没有ascii的半角,直接就是全角的字符了。所以我们要修改haribote/graphic.c文件里面的task->langmode==3这里面的代码:
putfont8(vram, xsize, x, y, c, hankaku + *s * 16);//只要是半角就使用hankaku里面的字符
后果又是失败的,不过有了一点成功的迹象了。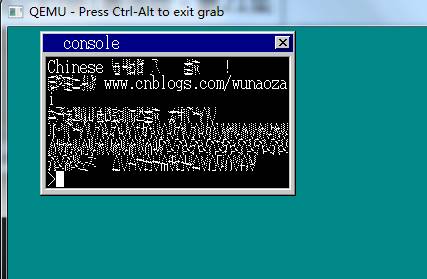
这次再改一下task->langmode==3,改font = nihongo + (k * 94 + t) * 32; 由于没有256个ascii所以这里也要该。再次make run。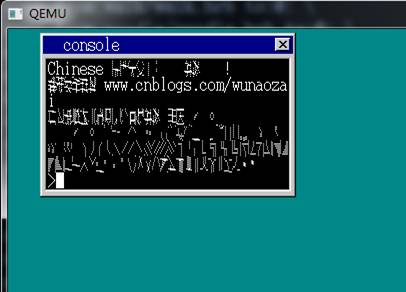
对了就是这个界面,昨天困扰我好久好久啊,由于上面的逗号和句号又可以显示,而其他的又显示不了。这是为什么呢?
四、书上是不是讲错,或是讲的不清楚
网上找了一个能显示HZK编码的C程序。
View Code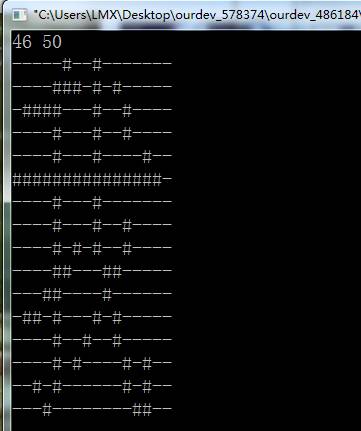
经过分析这个代码才知道,原来日文的编码是分左半部分和右半部分。而我们使用的HZK16是分上半部分和下半部分的。这一点坑了好久。
修改haribote/graphic.c
增加一个函数putfont32用于显示汉字(这个函数写的有点丑,能用就行了)
View Code修改putfonts8_asc函数里if (task->langmode == 3)语句块里这两句
putfont8(vram, xsize, x - 8, y, c, font ); putfont8(vram, xsize, x , y, c, font + 16);
为
putfont32(vram,xsize,x-8,y,c,font,font+16);
终于改完了,应该可以了,有点小激动了,赶快make run一下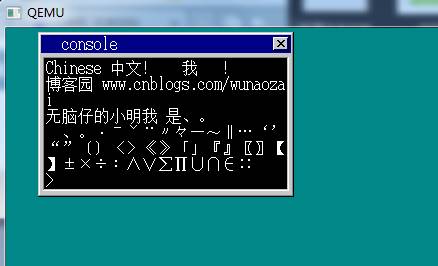
艾玛总算可以实现中文了。
参考资料
HZK编码 链接
所用到的工具和可以显示中文的代码:http://files.cnblogs.com/wunaozai/OS-in-30-days.zip
本文地址:http://www.cnblogs.com/wunaozai/p/3858473.html
利用yacc和lex制作一个小的计算器
买了本《自制编程语言》,这本书有点难,目前只是看前两章,估计后面的章节,最近一段时间是不会看了,真的是好难啊!!
由于本人是身处弱校,学校的课程没有编译原理这一门课,所以就想看这两章,了解一下编译原理,增加一下自己的软实力。免得被别人鄙视。
一、安装yacc和lex
我是在Windows下使用这两个软件的。所以使用bison代替yacc,用flex代替lex。两者的下载地址是http://sourceforge.net/projects/winflexbison/ 我的gcc环境是使用以前用过的mingw。我们吧解压后的flex和bison放到mingw的bin目录下。这一步就完成了。
二、编译代码
先编译代码,看一下结果,然后在分析。在这本书中提供的一个网址有书中代码下载。下载地址 http://avnpc.com/pages/devlang 下载后找到mycalc这个文件夹。然后执行下面进行编译
1 bison --yacc -dv mycalc.y -o y.tab.c 2 flex mycalc.l 3 gcc -o mycalc y.tab.c lex.yy.c
三、yacc/lex是什么
一般编程语言的语法处理,都会有以下的过程。
1.词法分析
将源代码分割成若干个记号的处理。
2.语法分析
即从记号构建分析树的处理。分析树也叫作语法树或抽象语法树。
3.语义分析
经过语法分析生成的分析树,并不包含数据类型等语义信息。因此在语义分析阶段,会检查程序中是否含有语法正确但是存在逻辑问题的错误。
4.生成代码
如果是C语言等生成机器码的编译器或Java这样生成字节码的编译器,在分析树构建完毕后会进入代码生成阶段。
例如有下面源代码

1 if(a==10)
2 {
3 printf("hoge
");
4 }
5 else
6 {
7 printf("piyo
");
8 }
执行词法分析后,将被分割为如下的记号(每一块就是一个记号)
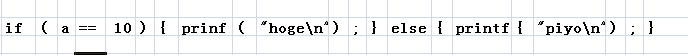
对此进行语法分析后构建的分析树,如下图所示
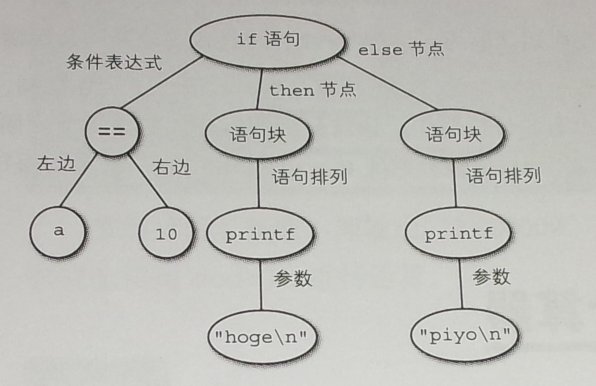
执行词法分析的程序称为词法分析器。lex的工作就是根据词法规则自动生成词法分析器。
执行语法分析的程序则称为解析器。yacc就是根据语法规则自动生成解析器的程序。
四、分析计算器代码
1.mycalc.l源代码
1 %{
2 #include <stdio.h>
3 #include "y.tab.h"
4
5 int
6 yywrap(void)
7 {
8 return 1;
9 }
10 %}
11 %%
12 "+" return ADD;
13 "-" return SUB;
14 "*" return MUL;
15 "/" return DIV;
16 "
" return CR;
17 ([1-9][0-9]*)|0|([0-9]+.[0-9]*) {
18 double temp;
19 sscanf(yytext, "%lf", &temp);
20 yylval.double_value = temp;
21 return DOUBLE_LITERAL;
22 }
23 [ ] ;
24 . {
25 fprintf(stderr, "lexical error.
");
26 exit(1);
27 }
28 %%
第一行到第十行是一个定义区块,lex中用 %{...}%定义,这里面代码将原样输出。
第11行到第28行是一个规则区块。语法大概就是前面一部分是使用正则表达式后面一部分是返回匹配到后这一部分是类型标记。大括号里面是动作。例如 ([1-9][0-9]*)|0|([0-9]+.[0-9]*)是匹配小数,然后对这个小数进行sscanf处理后返回一个DOUBLE_LITERAL类型。
2.mycalc.y 源代码
1 %{
2 #include <stdio.h>
3 #include <stdlib.h>
4 #define YYDEBUG 1
5 %}
6 %union {
7 int int_value;
8 double double_value;
9 }
10 %token <double_value> DOUBLE_LITERAL
11 %token ADD SUB MUL DIV CR
12 %type <double_value> expression term primary_expression
13 %%
14 line_list
15 : line
16 | line_list line
17 ;
18 line
19 : expression CR
20 {
21 printf(">>%lf
", $1);
22 }
23 expression
24 : term
25 | expression ADD term
26 {
27 $$ = $1 + $3;
28 }
29 | expression SUB term
30 {
31 $$ = $1 - $3;
32 }
33 ;
34 term
35 : primary_expression
36 | term MUL primary_expression
37 {
38 $$ = $1 * $3;
39 }
40 | term DIV primary_expression
41 {
42 $$ = $1 / $3;
43 }
44 ;
45 primary_expression
46 : DOUBLE_LITERAL
47 ;
48 %%
49 int
50 yyerror(char const *str)
51 {
52 extern char *yytext;
53 fprintf(stderr, "parser error near %s
", yytext);
54 return 0;
55 }
56
57 int main(void)
58 {
59 extern int yyparse(void);
60 extern FILE *yyin;
61
62 yyin = stdin;
63 if (yyparse()) {
64 fprintf(stderr, "Error ! Error ! Error !
");
65 exit(1);
66 }
67 }
上面第13行到第48行,语法规则简化为下面格式
A
: B C
| D
;
即A的定义是B与C的组合,或者为D。
上面的过程可以用一个游戏的方式解释。就是一个数字是定位为DOUBLE_LITERAL类型,通过第45行的规则可以将DOUBLE_LITERAL升级成primary_expression类型,然后通过34行规则可以升级为term类型。又term类型可以升级为expression类型。所以 “2+4” 符合的规则是数字2升级到expression类型,而当数字4升级到term类型时,此时的状态是 expression ADD term 通过第25行的规则可以得到两者的结合,得到一个term类型。(PS:这个时候让我想起了一个动漫,就是数码宝贝,类型可以进行进化,进化,超进化,究极进化,还可以合体进化。<笑>)上面一个专业的叫法是叫做归约。
由于归约情况比较复杂和不好讲,我就截书本上的原图进行讲解吧。



至于左结合或右结合是由写的词法分析器来决定的。例如给出的代码,为什么是右结合呢,是因为用到了递归,所以会首先和低级的类型进行结合,这就是为什么MUL,DIV是term类型,ADD,SUB是expression类型,就是处理优先级的问题。
对于C或Java有这样的一个问题
a+++++b;
我们可以分析为a++ + ++b 为什么编译器还会报错呢?是因为我们如果定义优先级的话,++优先级大于+。那么在代码中就是实现为尽量使++在一起,而不是+优先,如果是+优先的话,那么每次都不会结合为++。所以代码在词法分析器阶段代码就会被分割成a ++ ++ + b ;这样几段。从而错误的。由于词法分析器和解析器是各自独立的。又因为词法分析器先于语法分析器运行。
上面的过程就是这样进行语法分析的。上面的过程虽然简单,但是如果用代码实现就有点困难了。我们使用yacc生成的执行文件就是对上面模拟的执行代码,使用yacc自动生成的。如果我们要自制编程语言的话,那么这个过程就要自己写了。因为有很多细节问题。不过不多说了,我们先了解这个就行。生成后的代码文件是y.tab.c y.tab.h 。生成的代码有几十K呢,我们要了解这个过程还是比较难的。
五、用代码实现词法分析器
该代码在calc/llparser目录下
lexicalanalyzer.c
View Codetoken.h
View Code上面使用的方法是DFA(确定有限状态自动机)
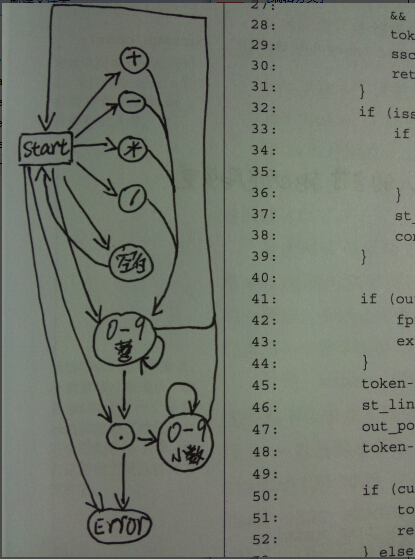
上面的图有些指向error的箭头没有标出,不过这个图就大概描述了这个过程。可以自己baidu一些状态机的知识。
有了这两章的基础就可以自己写个分析器了(作用:以后写应用程序时,要给程序一个配置文件时,可以自己写个脚本进行解析,方便用户书写配置文件。不过现在都使用xml语法了,都还有解析的库呢。都不知道学了以后还有没有机会用到实际中呢)。不过循环和判断就还不能实现。书中后面有讲到,不过看到后面一些内容就有一些力不从心了。感觉难难哒!
作者:无脑仔的小明
出处:http://www.cnblogs.com/wunaozai/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果文中有什么错误,欢迎指出。以免更多的人被误导。