[Apache Kafka]Kafka设计
在开始开发producer和consumer之前,先从设计的角度看一看Kafka。
由于重度依赖JMS,且实现方式各异、对可伸缩架构的支持不够,LinkedIn开发了Kafka来实现对活动流数据和运营指标数据的监控,这些数据包括CPU、I/O使用数据、请求响应时间等。开发Kafka时主要目标是提供以下特性:
- 支持自定义实现的producer和consumer的API
- 以低开销的网络和存储实现消息持久化
- 支持百万级消息订阅和发布的高吞吐量
- 分布式和高可伸缩性架构以实现低延迟传输
- 在consumer失效时自动平衡多个consumer
- 服务器故障的容错保证
Kafka基本设计
Kafka既不是队列平台(消息由consumer pool中的某一个consumer接收),也不是发布订阅平台(消息被发布给每个consumer)。在一个基本的结构中,producer发布消息到Kafka的topic中(message queue的同义词)。topic也可以看做是消息类别。topic是由作为Kafka server的broker创建的。如果需要,broker也会存储消息。conmuser订阅(一个或多个)topic来获取消息。这里,broker和consumer之间分别使用ZooKeeper记录状态信息和消息的offset。如下图所示:
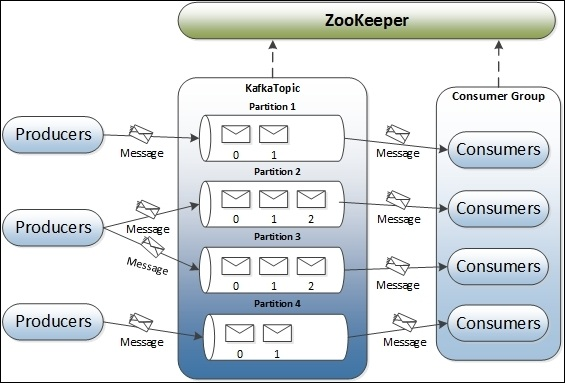
图中展示的是单节点单broker架构,一个topic有四个partition。图中包含了Kafka集群的五个组成部分:Zookeeper,broker,topic,producer,consumer。
在topic中,每个partition映射一个逻辑日志文件,由一系列大小相同的segment文件组成。每个分区是有序的且顺序不可改变的消息,当消息发布至一个partition时,broker将消息添加到最后一个segment文件中。segment文件在发布的消息达到配置的数量时或一段时间后会写入磁盘中。一旦segment文件写入磁盘,消息就可以被consumer获取到了。所有的消息partition被分配了一个唯一的序列号,称之为offset,用来识别partition内的每个消息。每个partition可配置为在多个服务器之间复制,实现容错保证。
每个partition在作为leader的服务器和有零个或多个作为follower的服务器上都是可用的。leader负责所有的读写请求,而follower从leader异步复制数据。Kafka动态维护一个in-sync replicas(ISR)集合,作为候选leader,并且始终将最新的ISR集合持久化到ZooKeeper中。如果当前leader失效了,某一个follower(ISR)会自动成为新的leader。在Kafka集群中,每个服务器扮演者两个角色,它既作为它的一些partition的leader,也是其它partition的follower。这样保证了集群中的负载均衡。
还有一个概念是consumer group。每个consumer看作一个进程,多个进程组织成群组就称为consumer group。
topic内的一个消息被consumer group内的某个进程(consumer)消费,如果需要,一个消息也可以被多个consumer消费,只要这些consumer在不同的group中。consumer始终从一个partition中顺序地消费消息,并且知道消息的offset。这意味着consumer消费了之前的所有消息。consumer向broker发起同步的pull请求,请求中包含待消费消息的offset。
Kafka中的broker是无状态的,这意味着消息的消费状态由consumer维护,broker并不记录消息的消费者。如果消息被broker删除(而broker不知道该消息是否已被消费),Kafka定义了time-based SLA(service level aggrement)作为消息保留策略。该策略中,消息在broker中停留的时间超过定义的SLA时长后会自动被删除。尽管与传统的消息系统相比,这样会允许consumer回退到之前的offset重新消费数据,但这是consumer违反了队列的约定。
来看一下Kafka提供的producer和consumer之间的消息传递方式:
- 消息不允许重新传递但可能丢失
- 消息可能重新传递但不会丢失
- 消息只传递一次
发布消息时,消息会被提交到日志中。如果producer在发布时出现网络故障,这时不能确定故障是在信息提交前还是提交后发生的。一旦提交成功,只要消息被复制到任意一个broker的partition中,消息将不会丢失。为了保证消息发布,需要配置producer提供的参数,如消息提交的确认时间和等待时间等。
从consumer视角来看,每个副本有着同样的日志,日志中是同样的offset信息。对于consumer,Kafka保证consumer在读取消息、处理消息、保存位置过程中至少被传递一次。如果consumer进程在保存位置之前崩溃了,该topic partition的另一个consumer进程将会接收到这小部分已经被处理的消息。
日志精简(log compaction)
日志精简是一种实现细粒度的消息保留,而不是粗粒度、基于时间保留的机制。它确保了topic partition内的每个消息key最后的值保持到该key有更新操作后才删除该记录。
在Kafka中,可以对每个topic设置如基于时间、基于大小、基于日志精简的保留策略。日志精简确保了:
- 始终维护消息的顺序
- 消息拥有顺序的offset,且offset不会改变
- consumer从offset 0开始读取,或者从日志的开始处开始读取,可以看出所有记录的写顺序的最终状态
日志精简由后台线程池处理,复制日志segment文件,删除在日志最前面出现的key对应的记录。
Kafka的一些重要的设计如下:
- Kafka的根本是消息缓存和基于文件系统的存储。数据会被立即写入OS kernel page。缓存和写入磁盘是可配置的。
- Kafka可在消息被消费后仍被保留,如果需要可以被consumer重新消费
- Kafka使用消息集分组管理消息,可减少网络开销
- 大部分消息系统将消息的消费状态信息记录在服务器层,而在Kafka中是由consumer层。这解决了两个问题:由于故障导致的消息丢失、同一个消息的多次传递。默认情况下,consumer将状态信息存储在ZooKeeper中,以可以使用其它的Online Transaction Processing(OLTP)系统。
- 在Kafka中,producer和consumer使用传统的推拉模式,producer将消息push到broker中,consumer从broker中pull消息。
- Kafka中的broker没有主从概念,所有的broker都看所peers。这意味着broker可以在任意时候添加或删除,因为broker的元数据维护在ZooKeeper中并共享给consumer。
- producer可以选择向broker发送数据是同步模式还是异步模式。
消息压缩(message compression)
考虑到网络带宽的瓶颈,Kafka提供了消息组压缩特性。Kafka通过递归消息集来支持高效压缩。高效压缩需要多个消息同时压缩,而不是对每个消息单独压缩。一批消息压缩在一起发送给broker。压缩消息集降低了网络的负载,但是解压缩也带来了一些额外的开销。消息集的解压缩是由broker处理消息offset时完成的。
每个消息可通过一个不可比较的、递增的逻辑offset访问,这个逻辑offset在每个分区内是唯一的。接收到压缩数据后,lead broker将消息集解压缩,为每个消息分配offset。offset分配完成后,leader再次将消息集压缩并写入磁盘。
在Kafka中,数据的压缩由producer完成,可使用GZIP或Snappy压缩协议。同时需要在producer端配置相关的参数:
- compression.codec:指定压缩格式,默认为none,可选的值还有gzip和snappy。
- compressed.topics:设置对指定的topic开启压缩,默认为null。当compression.codec不为none时,对指定的topic开启压缩;如果compressed.topics为null则对所有topic开启压缩。
消息集ByteBufferMessageSet可能既包含压缩数据也包含非压缩数据,为了区分开来,消息头中添加了压缩属性字节。在该字节中,最低位的两位表示压缩格式,如果都是0表示非压缩数据。
复制机制
在Kafka中,broker使用消息分区策略。消息如何分区由producer决定,broker会按照消息到达的顺序存储。每个topic的partition数量可在broker里配置。
尽管Kafka具有高可伸缩性,为了集群的更好的稳定性和高可用性,复制机制保证了即使broker故障消息也会被发布和消费。producer和consumer都是replication-aware的。如下图所示:

在复制机制中,每个消息partition有n个副本,可以支持n-1个故障。n个副本中有一个作为lead。ZooKeeper保存了lead副本和follow的in-sync replicas(ISR)。lead副本负责维护所有的follow的in-sync replicas(ISR)。
每个副本将消息存储到本地日志和offset,并定时同步到磁盘中。这样保证了消息要么被写到所有副本中,要么都没写。
Kafka支持以下复制模式:
- 同步复制:同步复制模式时,producer首先从ZooKeeper识别lead副本并发布消息。一旦消息被提交,它会被写到lead副本的日志中,所有的follower开始拉取消息;通过使用一个单独的通道,保证了消息的顺序。每个follow副本在将消息写入日志后会向lead副本发送反馈信息。复制完成后,lead副本向producer发送反馈信息。在consumer这一端,所有的消息从lead副本拉取。
- 异步复制:异步复制模式时,lead副本将消息写入日志后就向peoducer发送反馈信息,不等待follow副本的反馈。这样有个缺点,就是在broker故障时不能保证消息的传递。
如果任意的follower in-sync replicas故障了,leader会在配置的时间超时后将其从ISR列表中删掉。当故障的follower恢复了时,它首先将日志截断到最后的checkpoint(最后提交消息的offset),然后开始从checkpoint开始,从leader获取所有消息。当follower完全同步了leader时,leader将其加回到ISR列表中。
在将信息写入本地日志时或向producer发送反馈信息前,如果leader故障了,producer会将消息发送给新的leader。
新leader的选择跟所有的follower ISR注册它们自己到ZooKeeper的顺序有关。最先注册的将会成为新的leader,它的log end offset(LEO)成为最后提交消息的offset(也被称为high watermark(HW))。剩下的follower称为新的候选leader。每个副本向ZooKeeper注册一个监听器,在leader变化时会收到通知。当新的leader被选出,被通知的副本不再是leader时,它将日志截断到最后提交消息的offset,并开始赶上新的leader。新leader在配置的时间超时或者所有活跃的副本都同步完成了时,将当前ISR写入ZooKeeper,并开启自己的消息读取和写入。
更多关于Kafka复制的实现方式,见wiki.
参考资料