队列积压问题的分析、解决
现象:
同事负责的项目转到我的头上,整理服务过程中发现了队列的积压问题。
为了搞清楚积压的严重程度, 对队列任务数每分钟进行一次采样,生成一个走势图, 队列积压情况一目了然,非常严重。
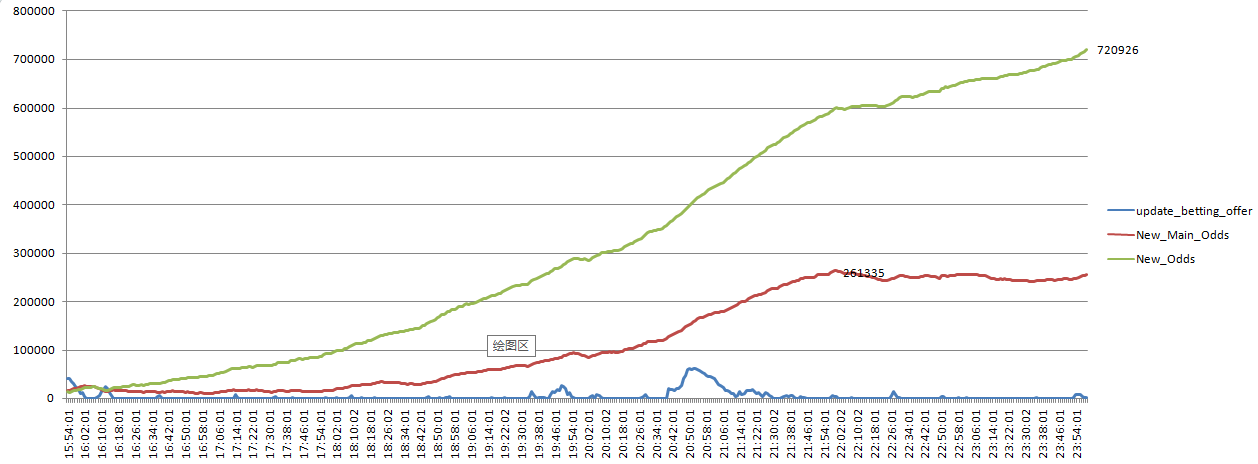
分析:
听了同事对系统的介绍,猜测是mongo性能影响了处理效率,于是针对mongo进行分析
1. 使用mongotop /usr/local/mongodb/bin/mongotop --host 127.0.0.1:10000
odds_easy.basic_odds表的操作一直排第一,写操作占大部分时间
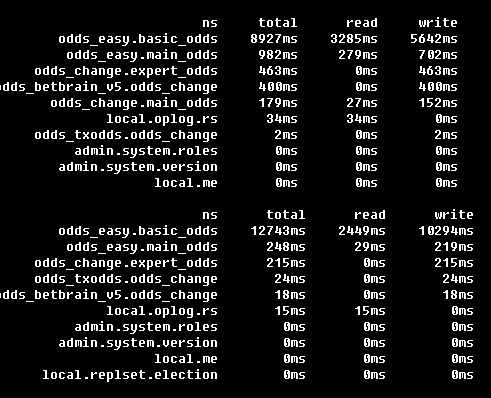
2. 看mongo shard日志
大量超过1s的操作,集中在odds_easy.basic_odds写操作, 看日志lock数量很多
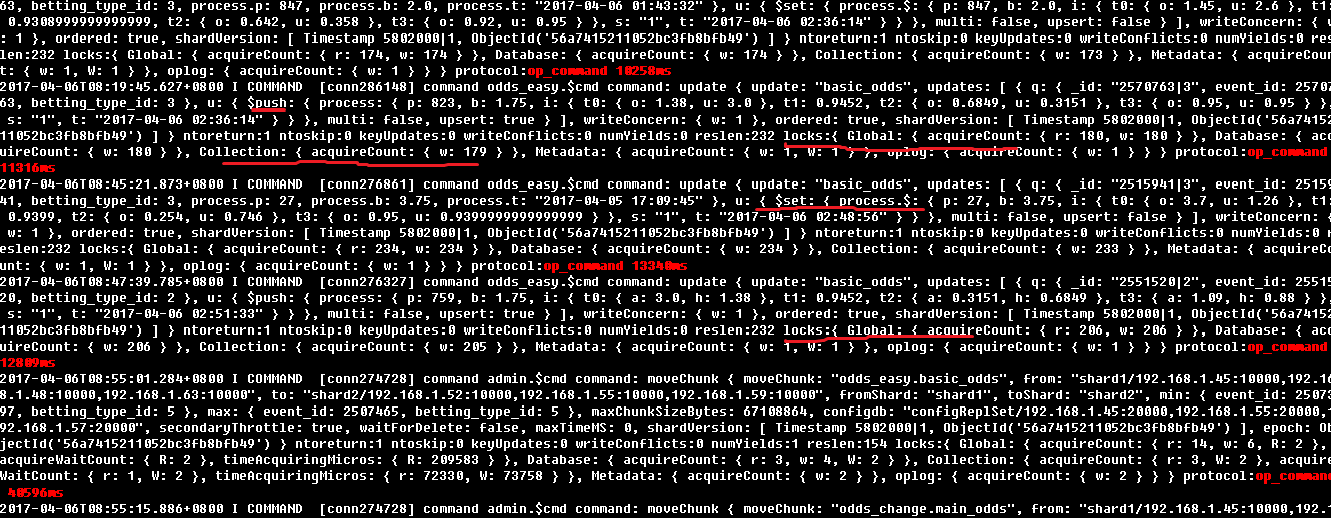
查询某一个文档的更新,在同一秒中居然有15个更新操作,这样的操作产生什么样的结果: 大量的写锁,并且影响读;而且还是最影响性能的数组的$push, $set操作
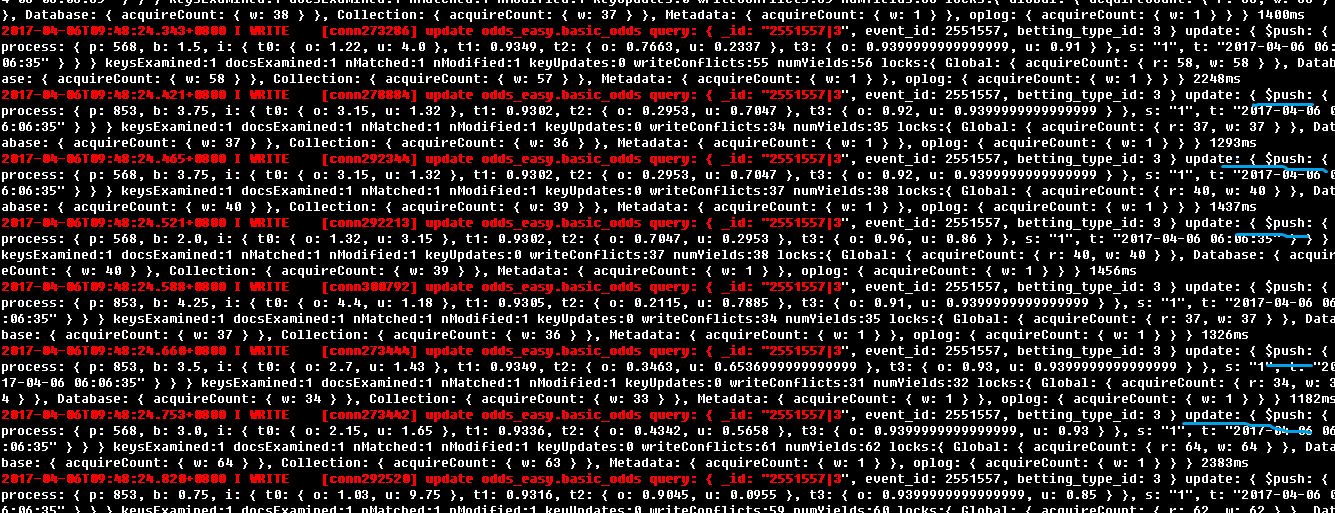
看看文档的结构,数组的数量之大,而且里面还是对象嵌套; 对这样一个文档不停的更新, 性能可想而知
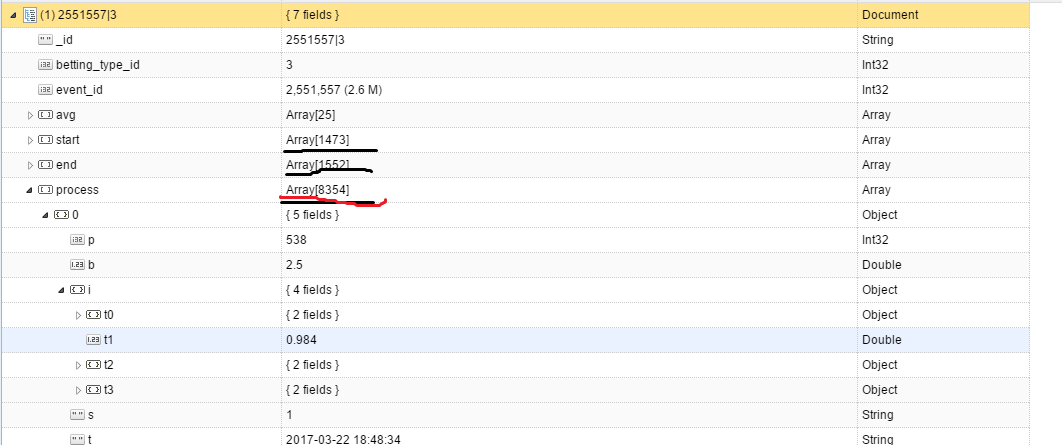
看看 db.serverStats()的lock情况
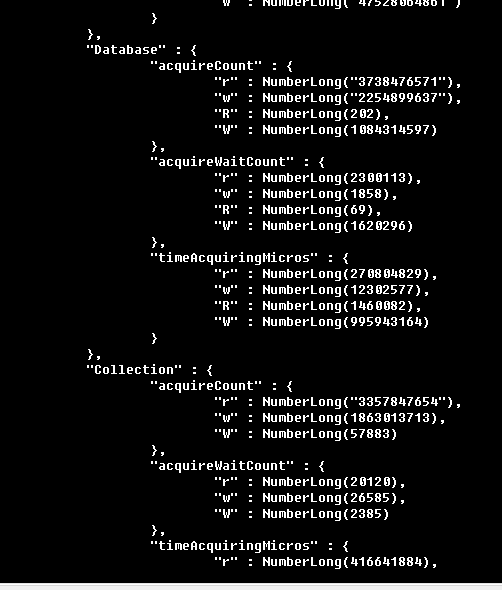
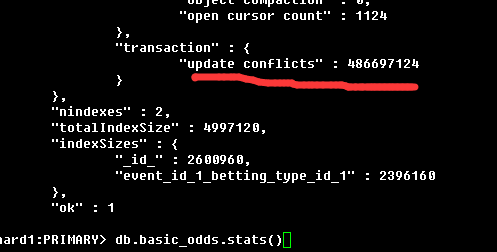
看看odds_easy的db.basic_odds.stats()情况,大量的更新冲突
3. 看看sharding情况
使用脚本,查看sharding情况,重定向到文件中查看。
sql='db.printShardingStatus({verbose:true})'
echo $sql|/usr/local/mongodb/bin/mongo --host 192.168.1.48:30000 admin --shell
basic_odds的sharding信息:
shard key: { "event_id" : 1, "betting_type_id" : 1 } event_id为mysql自增字段,betting_type_id为玩法id(意味着几个固定的值,区别度不大)
shard 分布情况, 从图里面可以看到mongo主要根据event_id这个自增字段的范围进行数据拆分, 意味着相邻比赛的数据大概率会被分配到同一个shard分区上(这就是为什么01机器上的日志大小远大于其他机器的原因吧,目前的数据都集中在shard1上)
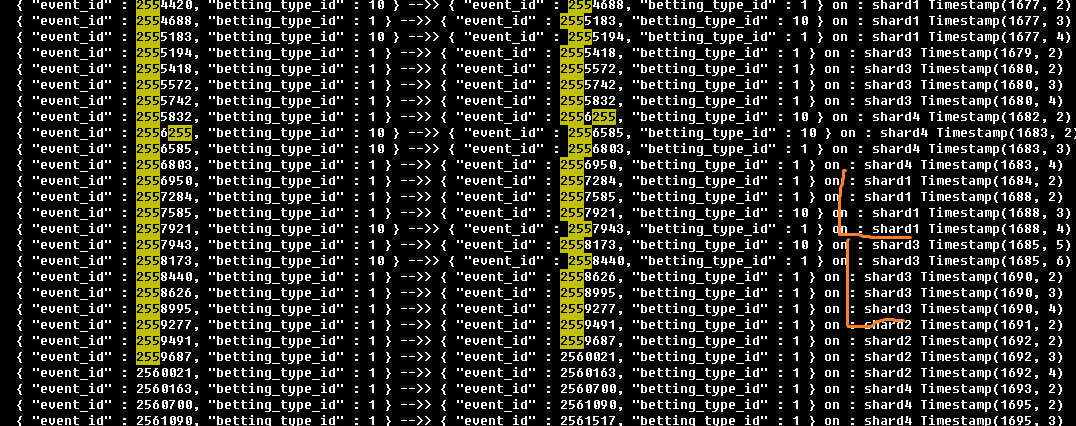
下图为数据库读写情况, 更新操作是查询操作的4倍。 对一个写多读少的数据库, 本该将写操作分布到不同的分区上,结果由于sharding key的错误选择造成了写热点,将写集中到了同一个分区,进一步加剧了写的阻塞

结论
- 文档结构不合理,数组过大、更新过于频繁,特别是对同一文档。 对数组频繁的更新操作是mongo最不推荐的,不仅影响本机的性能,还影响oplog的数据同步
- sharding key不合理造成了写热点, 在第一点不合理的基础上,更加剧了性能的急剧下降, 还会造成频繁的mongo数据迁移
(由于odds_easy.basic_odds的更新量大,目前问题在这个表上,但是其他表也有同样的问题)
【可以看到前期合理的架构设计是多么的重要】
解决思路
- 减少同一时刻对同一文档的更新操作,将一定时间内的多次更新改为一次更新。
- 将更新最频繁的process字段从文档中移出,写到新的表中。 在新表中,同一event_id,betting_type_id, 赔率公司的变化在同一条记录中
- 文档结构中加入时间字段,方便数据迁移,定期将历史数据进行迁移,进行冷热数据分离
- 修改sharding key为hash或者其他字段,将写操作分布到不同的分区上
解决方案
分两个阶段:
第一阶段 结构优化
- odds_easy库中basic_odds, main_odds不再存储最近10条的变化,去掉process字段。
- 数据直接 mongo push到odds_change中对应的记录rows字段中
- 单独提供接口,数据变化从odds_change中读取, 使用 mongo的$slice读出最近n条信息,然后程序排序截取即可
- odds_easy库和odds_change库中的表都使用 event_id 作 hash sharding key
- odds_easy, odds_change, odds_bet007, odds_betbrain_bb, odds_betbrain_v5, odds_txodds这些库中的记录都加入match_time字段。 新增的记录直接加入;历史的记录补全
第二阶段 冷热分离
目的
- 解决积压问题
- 提高访问速度
- 防止用户对大量历史的访问从而影响热数据的访问。(可以在配置中加入开关, 出现问题时关闭历史数据的访问)
系统中加入redis做热数据缓存, zookeeper/etcd作为配置服务中心以及热数据导入的流程控制中心