自己写的数据交换工具——从Oracle到Elasticsearch
先说说需求的背景,由于业务数据都在Oracle数据库中,想要对它进行数据的分析会非常非常慢,用传统的数据仓库-->数据集市这种方式,集市层表会非常大,查询的时候如果再做一些group的操作,一个访问需要一分钟甚至更久才能响应。
为了解决这个问题,就想把业务库的数据迁移到Elasticsearch中,然后针对es再去做聚合查询。
问题来了,数据库中的数据量很大,如何导入到ES中呢?
Logstash JDBC
Logstash提供了一款JDBC的插件,可以在里面写sql语句,自动查询然后导入到ES中。这种方式比较简单,需要注意的就是需要用户自己下载jdbc的驱动jar包。
input {
jdbc {
jdbc_driver_library => "ojdbc14-10.2.0.3.0.jar"
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
jdbc_connection_string => "jdbc:oracle:thin:@localhost:1521:test"
jdbc_user => "test"
jdbc_password => "test123"
schedule => "* * * * *"
statement => "select * from TARGET_TABLE"
add_field => ["type","a"]
}
}
output{
elasticsearch {
hosts =>["10.10.1.205:9200"]
index => "product"
document_type => "%{type}"
}
}不过,它的性能实在是太差了!我导了一天,才导了两百多万的数据。
因此,就考虑自己来导。
自己的数据交换工具
思路:
- 1 采用JDBC的方式,通过分页读取数据库的全部数据。
- 2 数据库读取的数据存储成bulk形式的数据,关于bulk需要的文件格式,可以参考这里
- 3 利用bulk命令分批导入到es中
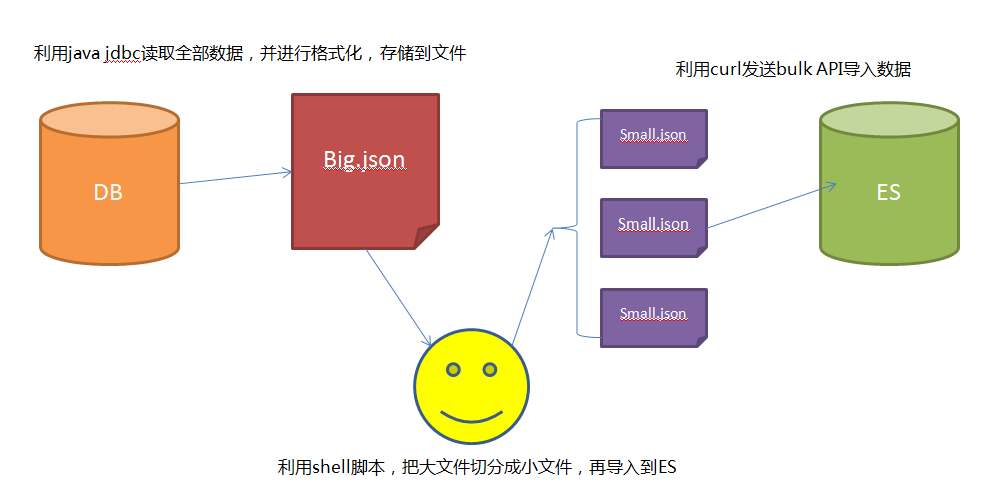
最后使用发现,自己写的导入程序,比Logstash jdbc快5-6倍~~~~~~ 嗨皮!!!!
遇到的问题
- 1 JDBC需要采用分页的方式读取全量数据
- 2 要模仿bulk文件进行存储
- 3 由于bulk文件过大,导致curl内存溢出
程序开源
下面的代码需要注意的就是
public class JDBCUtil {
private static Connection conn = null;
private static PreparedStatement sta=null;
static{
try {
Class.forName("oracle.jdbc.driver.OracleDriver");
conn = DriverManager.getConnection("jdbc:oracle:thin:@localhost:1521:test", "test", "test123");
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
System.out.println("Database connection established");
}
/**
* 把查到的数据格式化写入到文件
*
* @param list 需要存储的数据
* @param index 索引的名称
* @param type 类型的名称
* @param path 文件存储的路径
**/
public static void writeTable(List<Map> list,String index,String type,String path) throws SQLException, IOException {
System.out.println("开始写文件");
File file = new File(path);
int count = 0;
int size = list.size();
for(Map map : list){
FileUtils.write(file, "{ "index" : { "_index" : ""+index+"", "_type" : ""+type+"" } }
","UTF-8",true);
FileUtils.write(file, JSON.toJSONString(map)+"
","UTF-8",true);
// System.out.println("写入了" + ((count++)+1) + "[" + size + "]");
}
System.out.println("写入完成");
}
/**
* 读取数据
* @param sql
* @return
* @throws SQLException
*/
public static List<Map> readTable(String tablename,int start,int