原型模式——谈 Prototype 无小事
原型模式不仅是一种设计模式,它还是一种编程范式(programming paradigm),是 JavaScript 面向对象系统实现的根基。
在原型模式下,当我们想要创建一个对象时,会先找到一个对象作为原型,然后通过克隆原型的方式来创建出一个与原型一样(共享一套数据/方法)的对象。在 JavaScript 里,Object.create 方法就是原型模式的天然实现——准确地说,只要我们还在借助 Prototype 来实现对象的创建和原型的继承,那么我们就是在应用原型模式。
有的设计模式资料中会强调,原型模式就是拷贝出一个新对象,认为在 JavaScript 类里实现了深拷贝方法才算是应用了原型模式。这是非常典型的对 JAVA/C++ 设计模式的生搬硬套,更是对 JavaScript 原型模式的一种误解。事实上,在 JAVA 中,确实存在原型模式相关的克隆接口规范。但在 JavaScript 中,我们使用原型模式,并不是为了得到一个副本,而是为了得到与构造函数(类)相对应的类型的实例、实现数据/方法的共享。克隆是实现这个目的的方法,但克隆本身并不是我们的目的。
一、以类为中心的语言和以原型为中心的语言
1、Java 中的类
JavaScript 没有除了 Prototype 以外应用原型模式的选择 —— 毕竟原型模式是 JavaScript 这门语言面向对象系统的根本。但在其它语言,比如 JAVA 中,类才是它面向对象系统的根本。所以说在 JAVA 中,我们可以选择不使用原型模式 —— 这样一来,所有的实例都必须要从类中来,当我们希望创建两个一模一样的实例时,就只能这样做(假设实例从 Dog 类中来,必传参数为姓名、性别、年龄和品种):
Dog dog = new Dog('旺财', 'male', 3, '柴犬')
Dog dog_copy = new Dog('旺财', 'male', 3, '柴犬')
这里我们不得不把一模一样的参数传两遍,非常麻烦。而原型模式允许我们通过调用克隆方法的方式达到同样的目的,比较方便,所以 Java 专门针对原型模式设计了一套接口和方法,在必要的场景下会通过原型方法来应用原型模式。当然,在更多的情况下,Java 仍以“实例化类”这种方式来创建对象。
2、JavaScript 中的“类”
虽然说 ES6 支持类,但 ES6 的类其实是原型继承的语法糖,类语法不会为 JavaScript 引入新的面向对象的继承模型。
当我们尝试用 class 去定义一个 Dog 类时:
class Dog {
constructor(name, age) {
this.name = name
this.age = age
}
eat() {
console.log('肉骨头真好吃')
}
}
其实完全等价于写了这么一个构造函数:
function Dog(name, age) {
this.name = name
this.age = age
}
Dog.prototype.eat = function () {
console.log('肉骨头真好吃')
}
所以说 JavaScript 这门语言的根本就是原型模式。在 Java 等强类型语言中,原型模式的出现是为了实现类型之间的解耦。而 JavaScript 本身类型就比较模糊,不存在类型耦合的问题,所以说平时不会刻意地去使用原型模式。因此不必强行把原型模式当作一种设计模式去理解,把它作为一种编程范式来讨论会更合适。
二、谈原型模式,其实是谈原型范式
原型编程范式的核心思想就是利用实例来描述对象,用实例作为定义对象和继承的基础。在 JavaScript 中,原型编程范式的体现就是基于原型链的继承。这其中,对原型、原型链的理解是关键。
1、原型
在 JavaScript 中,每个构造函数都拥有一个 prototype 属性,它指向构造函数的原型对象,这个原型对象中有一个 construtor 属性指回构造函数;每个实例都有一个__proto__属性,当我们使用构造函数去创建实例时,实例的__proto__属性就会指向构造函数的原型对象。
具体来说,当我们这样使用构造函数创建一个对象时:
// 创建一个 Dog 构造函数
function Dog(name, age) {
this.name = name
this.age = age
}
Dog.prototype.eat = function () {
console.log('肉骨头真好吃')
}
// 使用 Dog 构造函数创建 dog 实例
const dog = new Dog('旺财', 3)
这段代码里的几个实体之间就存在着这样的关系:

2、原型链
现在在上面那段代码的基础上,进行两个方法调用:
// 输出"肉骨头真好吃"
dog.eat()
// 输出"[object Object]"
dog.toString()
明明没有在 dog 实例里手动定义 eat 方法和 toString 方法,它们还是被成功地调用了。这是因为访问一个 JavaScript 实例的属性/方法时,它首先搜索这个实例本身;当发现实例没有定义对应的属性/方法时,它会转而去搜索实例的原型对象;如果原型对象中也搜索不到,它就去搜索原型对象的原型对象,这个搜索的轨迹,就叫做原型链。
以上面的 eat 方法和 toString 方法的调用过程为例,它的搜索过程就是这样子的:
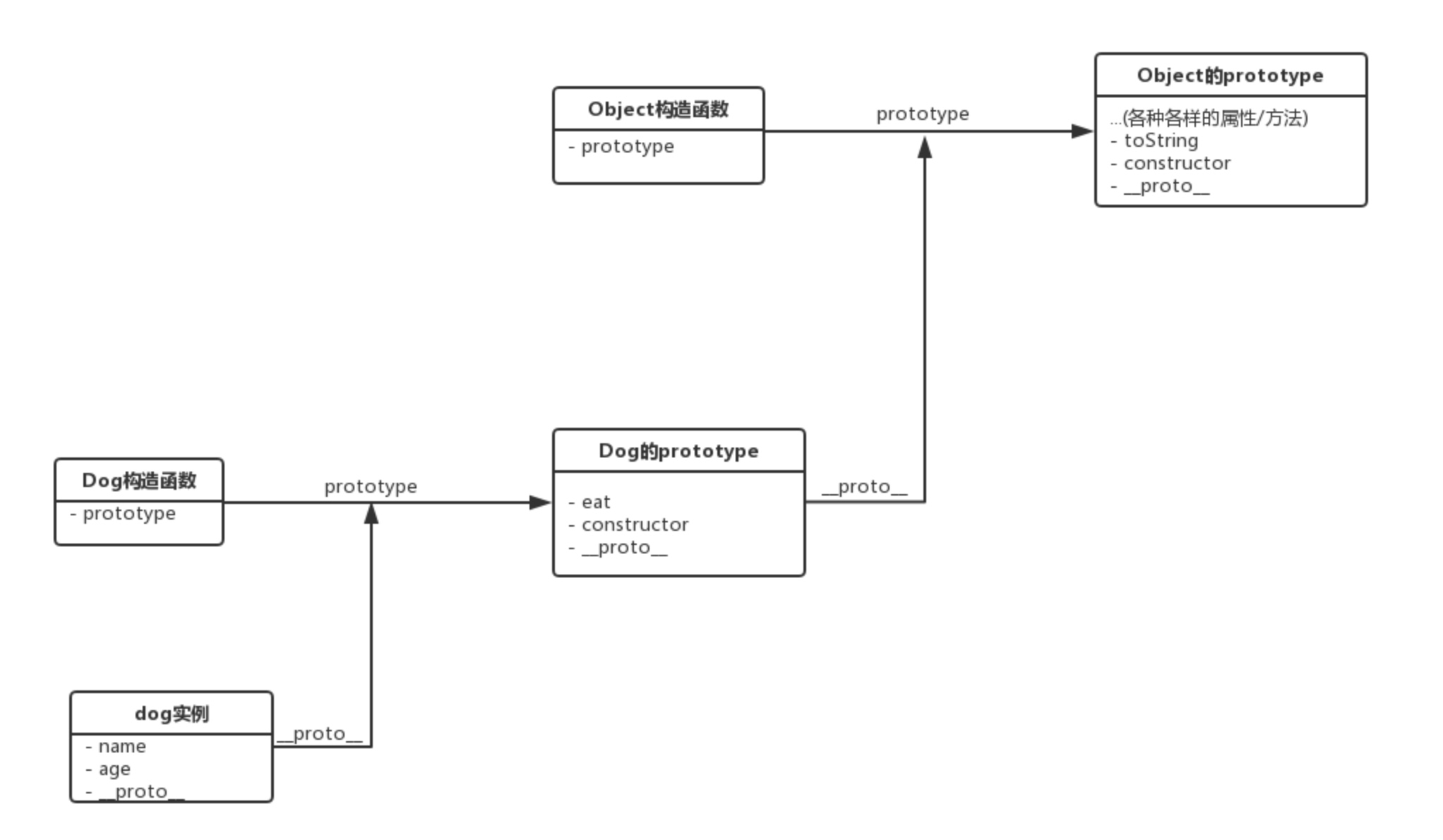
上面这些彼此相连的 prototype,就组成了一个原型链。 几乎所有 JavaScript 中的对象都是位于原型链顶端的 Object 的实例,除了Object.prototype(当然,如果手动用 Object.create(null) 创建一个没有任何原型的对象,那它也不是 Object 的实例)。
三、对象的深拷贝
“模拟 JAVA 中的克隆接口”、“JavaScript 实现原型模式” 其实就是 “实现 JS 中的深拷贝”
实现 JavaScript 中的深拷贝,有一种非常取巧的方式 —— JSON.stringify:
const liLei = {
name: 'lilei',
age: 28,
habits: ['coding', 'hiking', 'running']
}
const liLeiStr = JSON.stringify(liLei)
const liLeiCopy = JSON.parse(liLeiStr)
liLeiCopy.habits.splice(0, 1)
console.log('李雷副本的 habits 数组是', liLeiCopy.habits)
console.log('李雷的 habits 数组是', liLei.habits)
进控制台检验,可以发现引用类型也被成功拷贝了,副本和本体相互不干扰~

但是这个方法存在一些局限性,比如无法处理 function、无法处理正则等等——只有当你的对象是一个严格的 JSON 对象时,可以顺利使用这个方法。
深拷贝没有完美方案,每一种方案都有它的边界 case,多数情况下涉及到递归。递归实现深拷贝的核心思路:
function deepClone(obj) {
// 如果是值类型 或 null,则直接 return
if (typeof obj !== 'object' || obj === null) {
return obj
}
// 定义结果对象
let copy = {}
// 如果对象是数组,则定义结果数组
if (obj.constructor === Array) {
copy = []
}
// 遍历对象的 key
for (let key in obj) {
// 如果 key 是对象的自有属性
if (obj.hasOwnProperty(key)) {
// 递归调用深拷贝方法
copy[key] = deepClone(obj[key])
}
}
return copy
}
调用深拷贝方法,若属性为值类型,则直接返回;若属性为引用类型,则递归遍历。这就是递归实现深拷贝的核心方法。