JAVA语言具有跨平台,unicode字符集编码的特点。
但是在开发过程中处理数据时涉及到的字符编码问题零零散散,尤其是处理中文字符时一不留神就可能出现一堆奇奇怪怪的符号,俗称乱码。
对于乱码,究其原因,就是因为编码和解码过程中使用了错误的字符编码方案导致的。
首先在开头说明本人对 编码 解码 这两个概念的理解(如有错误烦请dalao指出,如有疑问也欢迎交流!):
首先,有一个字符串:
String str="hello,编码";
使用String类的方法getBytes(String charset);指定一个字符编码方案由字符串str其ByteArray形式,称之为为编码过程:
byte[] b_str = str.getBytes("utf-8");
使用String类重载的构造方法之一String(byte[] b,String charset);指定一个字符编码方案从一个ByteArray生成一个字符串,称之为解码过程:
String str_b = new String(b_str, "utf-8");
类似的,在某些在字节流与字符流之间进行转换工作的类及方法也都如此理解,即:
字符→字节:编码
字节→字符:解码
对于java源文件编码的说明:
在编写java源文件时,可能使用了各种编码,只要在编译时通过编译参数指定使用的编码方案即可
-encoding 字符集
无论是.java还是.jsp,涉及java源码的地方,都需要告知编译器使用哪种字符编码方案来处理该源码。
(JSP中:pageEncoding="UTF-8" 的作用是设置JSP编译成Servlet时使用的编码。)
现在这一工作大多已经由各种集成开发环境代为完成了,但我们仍需对其有一定了解以备不时之需。
对于java程序中的编码:
在一个java程序中,涉及到编码问题地方集中在文件读写,各种输入输出流的使用上,本小节着重分析java程序运行时的编码问题。
在对存储内容为字符的文件进行读写的时候,多数情况下是使用了包装类对文件输入输出流进行了包装。
这些字符读写包装类表面上没有涉及编码问题,实际上包装类产生的字符流在调用底层字节流的时候也是需要将数据在字符-字节间进行相应转换的,只不过默认情况下其采用了平台默认字符编码方案来完成编码-解码过程。
当我们有特殊需要的时候,可以主动控制这一过程,让包装类使用我们指定的字符编码方案进行字符-字节的转换。
此处以,字符流(输出字符的包装类PrintWriter,缓冲读取字符的包装类BufferedReader),底层流(文件IO流)为例:
我们利用在包装类使用Writer或Reader作为参数的构造方法,使用InputStreamReader和OutputStreamWriter两个中间类来指定字符-字节转换使用的字符编码方案
try {
File f = new File("d:\coding.txt");
FileOutputStream fos = new FileOutputStream(f);
FileInputStream fis = new FileInputStream(f);
PrintWriter pw = new PrintWriter(new OutputStreamWriter(fos, "utf-8"));
BufferedReader br = new BufferedReader(new InputStreamReader(fis, "utf-8"));
} catch (Exception e) {
e.printStackTrace();
}
通过上述代码,我们就实现了使用包装类且使用我们指定的字符编码方案更便捷的进行字符操作。
对于其他的包装的方法与此相同的以字节为基础的流,此处不再赘述。
有一点值得注意:不同的字符编码方案在错误的解码之后可能会丢失字节。
例如奇数个中文字符以UTF-8编码后以GBK解码再编码后再以UTF-8解码导致部分乱码:
try {
String str = "哈哈哈";
byte[] encode_by_utf8 = str.getBytes("utf-8");
String decode_by_gbk = new String(encode_by_utf8, "gbk");
byte[] encode_by_gbk = decode_by_gbk.getBytes("gbk");
String decode_by_utf8 = new String(encode_by_gbk, "utf-8");
System.out.println(decode_by_utf8); //Output:哈哈??
} catch (Exception e) {
e.printStackTrace();
}
简述其根本原因:两种编码方案对单个中文字符编码时使用的字节数不同导致中间过程中丢失了字节,虽然总体上编码还原了但是边界丢失的字节导致了乱码。
更详细的分析见此文章:http://blog.csdn.net/beyondlpf/article/details/7519786
java程序中有关编码的基础内容到此结束。下面将汇总在java web开发过程中多个软件协同工作时的编码问题。
不想看分析的请看这个简单粗暴的解决办法:http://blog.csdn.net/cfpl12011124/article/details/53488931
1:html页面设置编码 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
2:web.xml中设置编码
<mime-mapping> <extension>htm</extension> <mime-type>text/html;charset=UTF-8</mime-type> </mime-mapping> <mime-mapping> <extension>html</extension> <mime-type>text/html;charset=UTF-8</mime-type> </mime-mapping>
3:Tomcat server.xml中设置编码
<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8"/>
4:如果是IDE启动,设置启动参数 Debug configurations->tomat 8.0->argument
-Dfile.encoding=UTF8
如果是Tomcat服务形式启动,设置catalina.bat
set "JAVA_OPTS=%JAVA_OPTS% %JSSE_OPTS%" -Dfile.encoding=UTF8
5:将文件用记事本或者EditPlus打开,另存为UTF-8格式
以上5种基本可以告别tomcat中文乱码问题.
本人使用的开发环境:
JDK1.8.0_151
外部jar包直接引用Tomcat/lib下的servlet-api.jar
软件工具:
Eclipse Oxygen EE :用于编写.java源文件,编码格式为默认的GBK
Visual Studio Code :用于编写各种前端代码,编码格式均为UTF-8
Tomcat(8.5.24) :通过Eclipse默认配置调用运行。
首先分析一个http请求的正常流程
Tomcat收到http请求后,将相关数据封装成request对象和response对象,通过调用链的形式开始处理请求
调用链的调用从过滤器加载顺序的第一个过滤器开始调用
执行doFilter开始到调用调用链(chain.doFilter(request, response);)处的前半段处理并通过调用调用链(chain.doFilter(request, response);)将request和response传递下去
直到到达目标资源(Servlet或JSP或其他被过滤器过滤的资源),即调用链的终点
再依次折返回到调用调用链(chain.doFilter(request, response);)处执行此处到doFilter方法结束的后半段处理
特别说明:
每个过滤器的doFilter方法可以根据逻辑选择不调用调用链(chain.doFilter(request, response);),使自己成为调用链的终点,同时通过response对象做出应有的响应。
何时调用 request对象和response对象的setCharacterEncoding()方法?
对于request对象,该方法是设置用何种字符编码方案从request对象中解码获得字符数据
该方法必须在获取请求参数(getParameterNames,getParameter,getParameterValues等)和获得字符输入流(getReader)之前使用。
so:尽可能早的调用,通常在第一个过滤器中就调用此方法指定请求数据的解码方式。
附API原文:
setCharacterEncoding
public void setCharacterEncoding(java.lang.String env) throws java.io.UnsupportedEncodingException
- Overrides the name of the character encoding used in the body of this request. This method must be called prior to reading request parameters or reading input using getReader().
- Parameters:
env- aStringcontaining the name of the character encoding.- Throws:
java.io.UnsupportedEncodingException- if this is not a valid encoding
这项设置对POST方式的请求有效
POST方式提交的数据一般是浏览器根据提交页面的Content-Type中charset指定的字符编码方案来编码,并将编码后的数据放在http请求头中发送。
容器中的应用在提取数据时指定以与页面指定相同的字符编码方案解码http请求头中的数据即可。
这项设置在默认情况下对GET方式的请求无效
GET方式是通过URL传递数据的,浏览器使用哪种字符编码方案编码则具有不确定性,将编码后的数据放在URL后作为URL的一部分提交。
对附加在URL后的数据,若为在容器中特殊配置,往往是由容器使用默认URI编码方案直接解码。可以通过修改配置文件Tomcat/conf/server.xml中的<Connector ...>标签来指定默认URI编码方案(设置属性URIEncoding='UTF-8')。
特别说明:要求容器直接使用request的解码方式(设置属性useBodyEncodingForURI='true'),不再是默认情况,即:容器用setCharacterEncoding的设置决定如何解码。
因为:
在不同的字符编码方案中
英文字符的编码方式较为一致,所以即使使用了错误的字符编码方案解码也基本不会导致英文字符乱码,容错性高。
中文字符的编码方式基本不同,所以这种方式很容易导致中文乱码,容错性低。
所以:
实际应用中若需要通过GET方式传递中文数据,往往在提交前将其处理(使用encodeURI编码得到带%的英文字符串,再对该字符串encodeURI编码),容器任意自动解码一次得到带%的英文字符串,再次对该字符串URLDecoder.decode解码得到原始数据。
该方法利用了英文字符在不同编码方案间错误解码时的高容错特性。
更详细的说明见此文章:https://www.cnblogs.com/shazhou-blog/p/6150199.html
对于response对象,该方法是设置用何种字符编码方案编码要发送的响应数据
该方法必须在之前提交响应和获得字符输出流(getWriter)之前使用。
该方法可以多次调用,以最后一次有效调用为准。
该方法的设置会覆盖setContcentType(String)或setLocal()中的charset
setContentType("text/html") 且 setCharacterEncoding("utf-8") 和 setContentType("text/html;charset=utf-8") 是等价的。
so:尽可能早的调用,通常在第一个过滤器中就调用此方法设置响应数据的编码方式。
(优先使用的响应编码方式:setCharacterEncoding > contentType > pageEncoding)
附API原文:
setCharacterEncoding
public void setCharacterEncoding(java.lang.String charset)
- Sets the character encoding (MIME charset) of the response being sent to the client, for example, to UTF-8. If the character encoding has already been set by
setContentType(java.lang.String)orsetLocale(java.util.Locale), this method overrides it. CallingsetContentType(java.lang.String)with theStringoftext/htmland calling this method with theStringofUTF-8is equivalent with callingsetContentTypewith theStringoftext/html; charset=UTF-8.This method can be called repeatedly to change the character encoding. This method has no effect if it is called after
getWriterhas been called or after the response has been committed.Containers must communicate the character encoding used for the servlet response's writer to the client if the protocol provides a way for doing so. In the case of HTTP, the character encoding is communicated as part of the
Content-Typeheader for text media types. Note that the character encoding cannot be communicated via HTTP headers if the servlet does not specify a content type; however, it is still used to encode text written via the servlet response's writer.
- Parameters:
charset- a String specifying only the character set defined by IANA Character Sets (http://www.iana.org/assignments/character-sets)- Since:
- 2.4
- See Also:
#setLocale
关于Tomcat处理请求的方式:
上文已经说明了Tomcat收到请求时的处理流程,每一个请求的调用链终点即为该请求的目标资源。
对于不同类型的资源,Tomcat最终都是交由Servlet处理的,总共分三种:
1.Servlet:交由web.xml文件中映射的类来处理(Tomcat 7以前的版本交由一个叫做 InvokerServlet的类来处理)
2.JSP:将JSP编译为Servlet在交由其处理
3.静态资源(html,css,js,jpg,png等):交由一个叫做DefaultServlet的类来处理
对于前两种调用,只要正确的处理了java源文件编码和java程序中数据的编码解码就不会出现问题。
而第三种则是调用了Tomcat的默认Servlet进行处理,关于该类的详细分析见此文章:http://blog.csdn.net/husan_3/article/details/23792517
简单来说,这个类负责读取请求的各种静态资源并完成响应。
DefaultServlet在读取内容为字符类的文件时,默认情况下该类会用平台默认编码来解码得到字符串,然后将其写入response.getWriter()方法获取到的字符流中。
对于UTF-8编码的文本类文件,在这一步被错误的解码后,即使再次编码再用正确的字符集解码,也有可能出现文章中提到的字节丢失导致的部分乱码。
根据官方帮助文档的描述,我们可以在Tomcat/conf/web.xml中找到这个类的映射并可以为其设置初始化参数fileEncoding及其值UTF-8,使该类用指定的字符编码方案来解码文本类静态资源文件。
原文地址:http://tomcat.apache.org/tomcat-8.5-doc/default-servlet.html
Where is it declared?
It is declared globally in $CATALINA_BASE/conf/web.xml. By default here is it's declaration:
<servlet> <servlet-name>default</servlet-name> <servlet-class> org.apache.catalina.servlets.DefaultServlet </servlet-class> <init-param> <param-name>debug</param-name> <param-value>0</param-value> </init-param> <init-param> <param-name>listings</param-name> <param-value>false</param-value> </init-param> <load-on-startup>1</load-on-startup> </servlet> ... <servlet-mapping> <servlet-name>default</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping>So by default, the default servlet is loaded at webapp startup and directory listings are disabled and debugging is turned off.
What can I change?
The DefaultServlet allows the following initParamters:
Property Description ...... ...... fileEncoding File encoding to be used when reading static resources. [platform default] ...... ......
通过添加初始化参数来指定读取静态资源中文本类文件即可避免在这一环节出现问题导致乱码。
Eclipse与Tomcat:
当在Eclipse中调用Tomcat时需要格外注意,Eclipse默认勾选了自动发布的选项,即Eclipse只认得在它里面部署的项目,因此它会在项目使用的服务器项目下重新生成的web.xml等配置文件替代Tomcat/conf下配置过的文件来启动服务器。
对于这个问题有两种解决办法:
原文地址:https://www.cnblogs.com/ystq/p/6007183.html
当我们在处理中文乱码或是配置数据源时,我们要修改Tomcat下的server.xml和content.xml文件。
但是当我们修改完后重启Tomcat服务器时发现xml文件又被还原了,修改无效果。
为什么会还原?
Tomcat服务器在Eclipse中启动时,会自动发布Eclipse中部署的项目,但是我的项目是自己手动在外面部署的,Eclipse只认得在它里面部署的项目,因此它会创建一个新的server.xml文件覆盖原来的文件,里面只有Eclipse中部署的项目。
解决方法一:
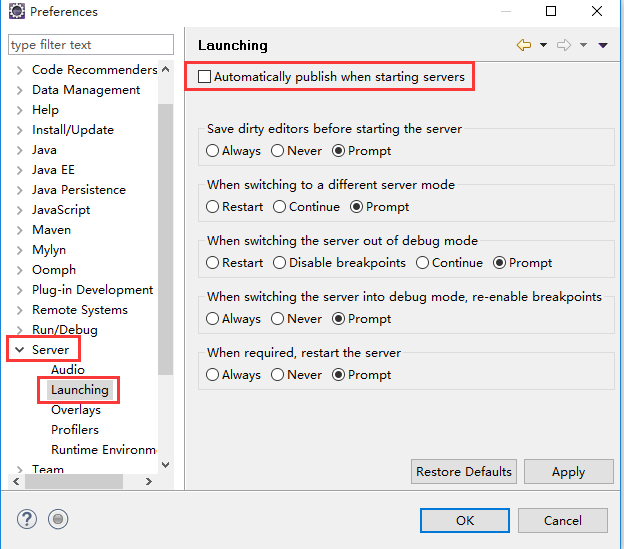
设置Ecplise,取消掉自动发布功能。
依次选择 Window-Preferences-Server-Launching,取消Automatically publish wen starting servers,点击OK,搞定
解决方法二:
Ecplise项目中有一个Server项目,有一个Tomcat v7.0 Server at localhost-config,

跳过这个坑基本就没问题了。
ing