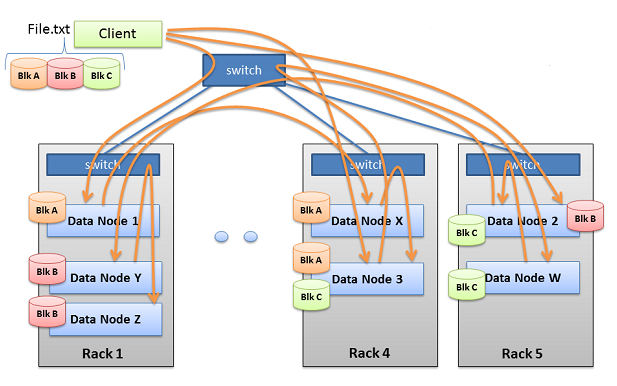
当写入一个文件到 HDFS 时,它被切分成数据块,块大小是由配置文件 hdfs-default.xml 中的参数 dfs.blocksize (自 hadoop-2.2 版本后,默认值为 134217728字节即 128M,可以在 hdfs-site.xml 文件中改变覆盖其值,单位可以为k、m、g、t、p、e等)控制的。每个块存储在一个或者多个节点,这是由同一文件中的配置 dfs.replication (默认为3)控制。块的每一个 copy 叫做 replica (副本)。
replication 流程
当在 HDFS 文件中写数据时,数据首先被写入到客户端本地缓存。当缓存达到块大小时,客户端请求 NameNode 并且获取 DataNode 列表。这个列表包含将承载这个块副本的 DataNode 。DataNode 数基于 replication 的系数,默认值为3。客户端组织从 DataNode 到 DataNode 和 flush 数据块到第一个 DataNode 的流程。第一个 DataNode 开始以小部分(文件系统大小4KB)接受该数据,每一部分写入其本地存储库,并转移同一部分数据至所述列表中的第二个 DataNode。第二个 DataNode 开始依次接受数据块的每一部分,这部分数据写入它的本地存储库,并且 flush 同一部分数据至第三个 DataNode。最后,第三个 DataNode 写数据至其本地存储库。因此,一个 DataNode可以从流程中前一个节点接受数据,并把同一部分数据转发到流程中的下一个节点。因此,数据是线性的从一个 DataNode 到下一个 DataNode。当第一个块被填满,客户端向 NameNode 请求下一个块的副本存储的节点主机以供选择。一个新的流程被组织起来,客户端开始发送文件更进一步的字节数据。这种流动一直进行,直到文件的最后一个块。对于每个块的 DataNode 的选择很可能是不同的。
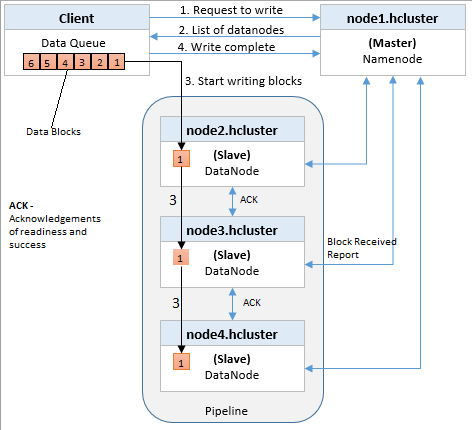
在客户端写 File.txt 文件的"Block A"到集群之前,它想要知道所有预期准备接受这个块的 copy 的 DataNode。它选择对于 Block A 列表的第一个DataNode(DataNode 1),打开一个 TCP 50010 端口的连接并且说:“Hey,准备接受一个块,这儿有一个DataNode列表,包含 DataNode 5 和 DataNode 6。去确认他们也准备好接受这个块。”DataNode 1 打开一个 TCP 连接至 DataNode 5 并且说,“Hey,准备接受一个块,去确认 DataNode 6 也准备好接受这个块。”DataNode 5 将问 DataNode 6,“Hey,你准备好接受一个块了吗?”
在同一个 TCP 管道准备好确认返回,直到初始 DataNode 1 发送一个“准备就绪”的消息回客户端。此时客户端准备好了开始写块数据到集群。
它们也将发送成功的确认消息返回至流程,关闭 TCP 会话。客户端接收到一个成功消息,然后通知 NameNode 块写入成功。NameNode 更新元数据信息和文件 File.txt 的 Block A 的节点位置信息。
副本存放策略
默认的块存放策略如下:
1、第一个副本的位置--随即的机架和节点(如果 HDFS 客户端存在于 hadoop 集群之外)或者在本节点(如果 HDFS 客户端运行在集群中的一个节点)。
本地节点策略:
在一个数据节点(这里使用 hadoop22)的本地路径复制一个文件至 HDFS :
我们期望在节点 hadoop22 看到所有块的第一个副本。
我们可以看到:
文件 File.txt 的块 Block 0 在 hadoop22(rack2)、hadoop33(rack3)、hadoop32(rack3);
File.txt 的块 Block 1 在 hadoop22(rack2)、hadoop33(rack3)、hadoop32(rack3);
2、第二个副本写入与第一个不同的机架,并随机选择。
3、第三个副本写入与第二个相同的机架,不过不是同一个节点。
4、如果有其他副本,将被分散到其他机架。
Replication 机架感知
对于一个大的集群,它可能不会在一个扁平化的拓扑结构中直接的连接所有节点。通常的做法是,在多个机架的分散的节点。机架的节点共享一个开关,并且机架开关由一个或多个核心交换机连接。不同机架的两个节点的通信,要经历多个开关。大部分情况下,同一机架节点之间的网络带宽比不同机架之间的网络带宽要更大。
HDFS使用一个简单的但高有效性的策略来分配块的副本。如果在 HDFS 集群的某些节点上正在执行打开一个文件以用来写入块的操作,那么第一个副本被分配到正在操作的客户端的这台机器上。第二个副本被随机分配到不同于第一个副本所在的机架的另一个机架上。第三个副本被随机分配到第二个副本所在机架的不同节点上。意思是,一个块被分配到了不同的机架上面。这个关键规则适用于数据的每一个快,两个副本在同一机架,另一个在不同的机架上。