根据一个网页链接,爬取该网页下所有子网页链接,存入一个队列,再从子网页中爬取新的网页链接。
队列设计 LinkQueue :
待访问链接队列 : unVisitedUrl
已访问链接队列 : visitedUrl
所需实现的具体方法:
队列中取出一个链接
队列添加链接时判断待访问和已访问队列是否存在此链接
队列中移除一个链接
获取待访问队列当前大小
获取已访问队列当前大小
判断队列是否为空
网页解析 HtmlUrlParserTool:
获取一个网页的源码: getUrlIndex
对网页的源码解析获得一个子网页链接队列: htmlUrlPerser
所需实现:
网页解析方法 : jsoup,正则表达式
网页内容下载 DownLoadFile :
获取链接对应文件类型(文件后缀) : getFileNameByUrl
将文件保存至本地 : downLoadFile
所需知识:
I/O流,正则表达式
爬虫主程序 MyClawler :
实现: 操作队列,线程化
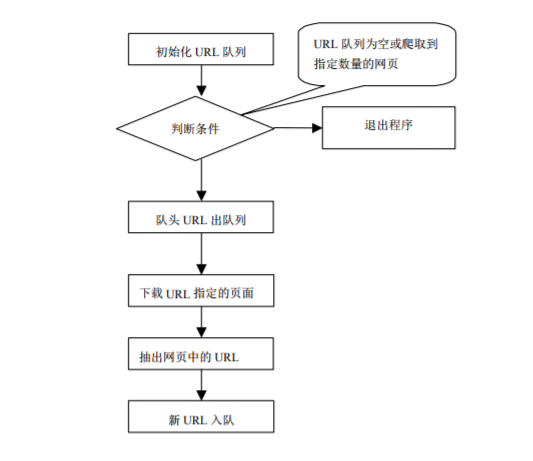
实现代码如下。
队列类:LinkQueue
Queue :
import java.util.LinkedList; public class Queue { // 队列 private LinkedList<String> queue = new LinkedList<String>() ; // 加入 public void enQueue(String t){ queue.addLast(t); } // 移除 public String deQueue(){ return queue.removeFirst(); } public int size(){ return queue.size(); } // 是否为空 空->true public boolean isQueueEmpty(){ return queue.isEmpty(); } // 是否包含t 包含->true public boolean contains(String t){ return queue.contains(t); } }
LinkQueue:
import java.util.HashSet; import java.util.Set; // 优先队列 public class LinkQueue { private static Set<String> visitedUrl = new HashSet<String>(); private static Queue unVisitedUrl = new Queue(); // 获得 URL 队列 public static Queue getUnVisitedUrl(){ return unVisitedUrl ; } // 添加到已访问 public static void addVisitedUrl(String url){ visitedUrl.add(url); } // 移除访问过的 URL public static void removeVisitedUrl(String url){ visitedUrl.remove(url); } // 未访问过的 URL 出列 public static String unVisitedUrlDeQueue(){ return unVisitedUrl.deQueue(); } // 在unVisitedUrl 加入之前判断其中是否有重复的 , 当无重复时才做添加 public static void addUnvisitedUrl(String url){ if((!unVisitedUrl.contains(url))&&(url!=null)&&(!visitedUrl.contains(url))){ unVisitedUrl.enQueue(url); } } // 已访问的数目 public static int getVisitedUrlNum(){ return visitedUrl.size(); } // 待访问的数目 public static int getUnVisitedUrlNum(){ return unVisitedUrl.size(); } // 判断 待访问队列 是否为空 public static boolean unVisitedUrlEmpty(){ return unVisitedUrl.isQueueEmpty(); } }
网页解析类 HtmlUrlParserTool:
// 获取该页面所有URL import org.apache.http.HttpEntity; import org.apache.http.HttpHost; import org.apache.http.client.config.RequestConfig; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class HtmlUrlParserTool { // 获取一个 URL 中 所有 子URL public static Queue htmlUrlPerser(String url) throws Exception { Queue queue = new Queue(); String data = new String( "<a href="http:(.*)html>") ; //String n ; www.cnblogs.com/AWCXV/ String index = getUrlIndex(url) ; Document doc = Jsoup.parse(index); Elements elements = doc.select("a"); for(Element element : elements){ String aurl = element.attr("href") ; if(!queue.contains(aurl)){ queue.enQueue(aurl); } } return queue ; } // 一个URL的解析 public static String getUrlIndex(String url) throws Exception { CloseableHttpClient chc = HttpClients.createDefault() ; HttpGet httpGet = new HttpGet(url);
// 代理IP选择 //String ip = IPQueue.getIp(); //String []ipArr = ip.split("-"); //System.out.println(ipArr[0]+" "+Integer.parseInt(ipArr[1])); //HttpHost httpHost = new HttpHost(ipArr[0],Integer.parseInt(ipArr[1])); RequestConfig rc = RequestConfig.custom() //.setProxy(httpHost) .setConnectTimeout(10000) .setSocketTimeout(10000) .build(); httpGet.setConfig(rc); CloseableHttpResponse chp = chc.execute(httpGet); HttpEntity he = chp.getEntity(); String index = EntityUtils.toString(he); Document doc = Jsoup.parse(index); Elements elements = doc.getElementsByTag("title"); Element element = elements.get(0); Cnblogs.write(element.text()+" "+url); System.out.println(element.text()+" "+url); chc.close(); return index ; } }
网页内容下载类 DownLoadFile :
import java.io.FileOutputStream; import java.io.InputStream; import java.io.OutputStream; import java.net.HttpURLConnection; import java.net.URL; // 下载此 URL 内容 public class DownLoadFile { // url对应 文件类型名 public static String getFileNameByUrl(String url) { // 移除 http:// if (url.contains("http://")) { url = url.substring(7); } // 获取文件类型 return url.replaceAll("[\?/:*|<>"]", ""); } public static String downLoadFile(String url){ URL u ; HttpURLConnection hc ; String filePath = "d:\temp\"+getFileNameByUrl(url); try{ u = new URL(url); hc = (HttpURLConnection) u.openConnection(); if(hc.getResponseCode()==200){ byte[] bs = new byte[1024]; int len ; InputStream is = hc.getInputStream(); OutputStream os = new FileOutputStream(filePath); while ((len = is.read(bs)) != -1) { os.write(bs, 0, len); } os.close(); } }catch (Exception e){ } return filePath ; } }
爬虫主类 MyClawler :
import java.io.File; import java.io.FileOutputStream; import java.io.OutputStream; import java.io.RandomAccessFile; // 主程序 class Cnblogs implements Runnable{ public static void write(String read) throws Exception{ File f = new File("src\fangwen.txt"); OutputStream os = new FileOutputStream(f,true); os.write((read+" ").getBytes()); } public void run() { while (!LinkQueue.unVisitedUrlEmpty()) { try{ String url = LinkQueue.unVisitedUrlDeQueue(); LinkQueue.addVisitedUrl(url); Queue newQ = HtmlUrlParserTool.htmlUrlPerser(url); while(!newQ.isQueueEmpty()){ String oneUrl = newQ.deQueue(); LinkQueue.addUnvisitedUrl(oneUrl); } System.out.println("线程 : "+Thread.currentThread().getName()+" 已访问数目 :"+LinkQueue.getVisitedUrlNum()+" 待访问队列数目 : "+LinkQueue.getUnVisitedUrlNum()); System.out.println(); }catch (Exception e){ }finally { } } } } public class MyClawler { public static void main(String []args) throws Exception { try { File f = new File("src\fangwen.txt"); f.delete(); }catch (Exception e){ }finally { Queue q = HtmlUrlParserTool.htmlUrlPerser("http://www.cnblogs.com/AWCXV/p/7626366.html") ; LinkQueue.addVisitedUrl("http://www.cnblogs.com/AWCXV/p/7626366.html"); while(!q.isQueueEmpty()){ String oneUrl = q.deQueue() ; LinkQueue.addUnvisitedUrl(oneUrl); } //System.out.println("已访问:"+LinkQueue.getVisitedUrlNum()); int i = 0 ; Cnblogs cnblogs = new Cnblogs(); for(i=0;i<100;i++){ new Thread(cnblogs,"线程"+i).start(); } } } }
以下是对博客园博客进行宽度互联网遍历爬取的链接: