一.数据库
1.如何设计一个关系型数据库?

数据库的各个模块:
存储(文件系统): 将数据持久化到硬盘。
程序实例:
- 存储管理 : 为了减少IO,防止查询时多次查询,可以将查询操作设计为按页查询,按块查询。
- 缓存机制 : 通过缓存机制防止多次IO,有缓存机制,也有淘汰机制。
- SQL解析 : 解析SQL命令。
- 日志管理 : 发生错误进行排查。
- 权限划分 : 数据访问修改权限的设计。
- 容灾机制
索引管理(重点设计)锁模块(重点设计)
2.为什么要使用索引?
之前在存储管理中说到按页块存储,那么在查询时我们要将块页加载进内存,进行全表扫描。数据量比较小时全表扫描很方便,但在大量数据时该方法就不适用了。所以需要使用索引这种高效的方法。利用关键信息来提升查询速度。
3.什么样的信息能成为索引?
能够把记录限制在一定范围内的信息,如主键,唯一键。
3.索引的数据结构
二叉查找树,平衡二叉树,B-Tree,B+-Tree,Hash结构。
mysql使用的主要是B+-Tree。
- 二叉查找树:每个节点最多只有两个子树的结构。对于一个节点来说,他的左子树节点小于他,右子树节点大于他。

- 平衡二叉树:在二叉树的基础上,他的任意一个节点的左子树高度均不超过1。
但是二叉树因为每个节点只有两个子节点,所以树的高度非常高,IO次数也会增大,有时候效率并没有全表扫描高。所以这时候就需要B-Tree了。
- B-Tree : 每个节点最多有m个孩子,m阶B树。根节点至少包括两个孩子,树中每个节点最多包含有m个孩子,所有叶子节点都位于同一层。
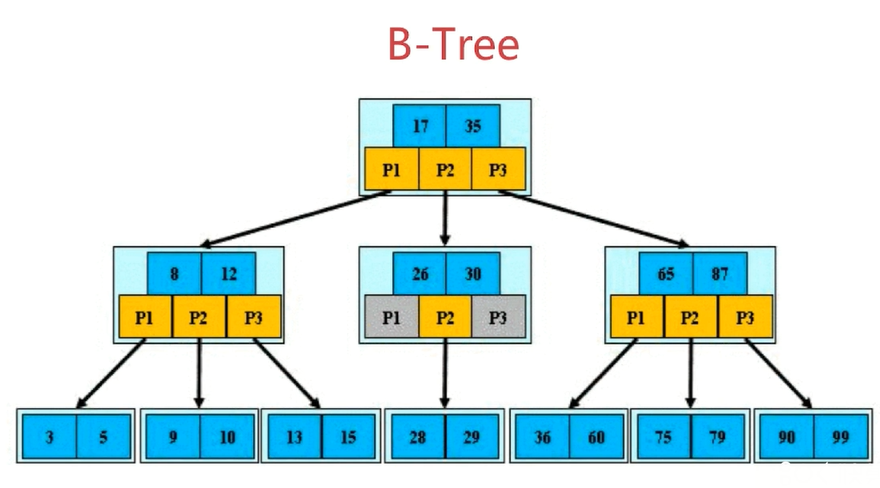
目的是为了让每一个索引块尽可能多的存储更多的信息,尽可能减少IO次数。
- B+-Tree : 树中节点指针与关键字数目一样,且数据均在叶子节点中。
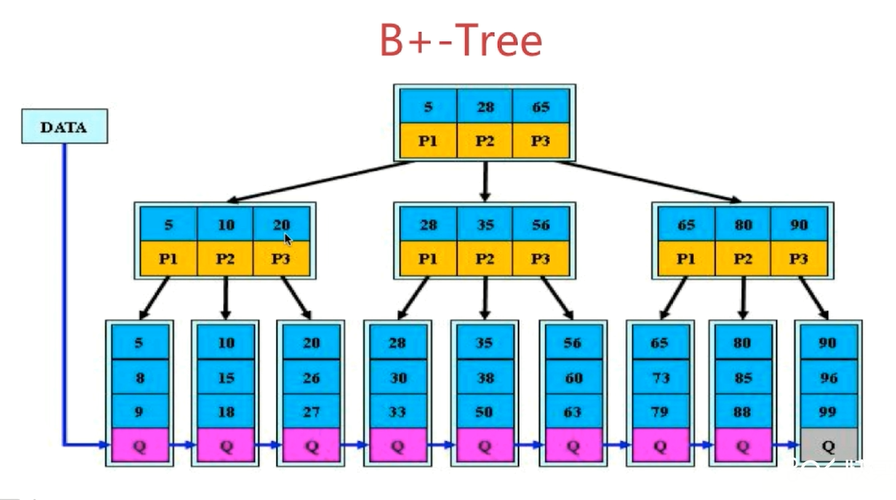
所以B+Tree更适合用来做索引存储,磁盘读写代价低,查询效率稳定。
- Hash索引 : 通过Hash运算直接定位到目标。
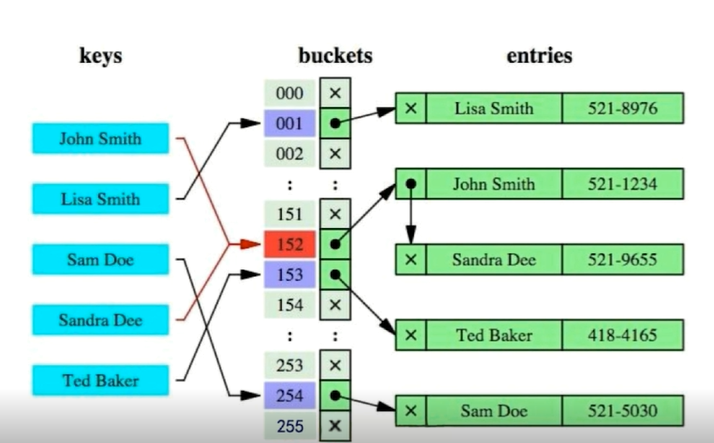
虽然效率高,但是只能满足=,IN,不能范围查询,无法避免排序操作。
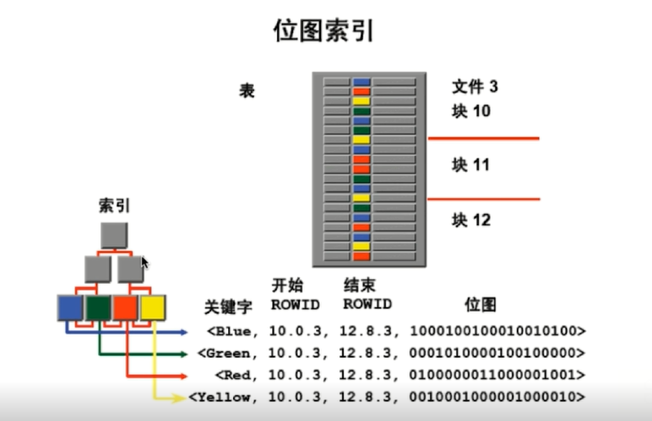
- BitMap位图索引
修改数据时对其他数据影响极大。
4.密集索引和稀疏索引的区别
-
密集索引 : 为每一个搜索码值都对应一个索引值
-
稀疏索引 : 只给索引码的某些值建立索引项
