曾经144区的王者
学了计算机后
头发逐渐从李白变成了达摩
秀发有何用,变秃亦变强
(emmm徒弟说李白比达摩强,变秃不一定变强)
前言
前几天开了农药的安装包,发现农药是.Net实现的游戏
虽然游戏用的语言和排位一样让人恼火
但感觉图片美工还是可以的
比如:
不知...不知道你们是不是和我一样喜欢
玩阴阳师呢,我可是Ssr只有两只狗子的非酋呢

正文
在 http://pvp.qq.com/web201605/herolist.shtml 可以看到全英雄列表。
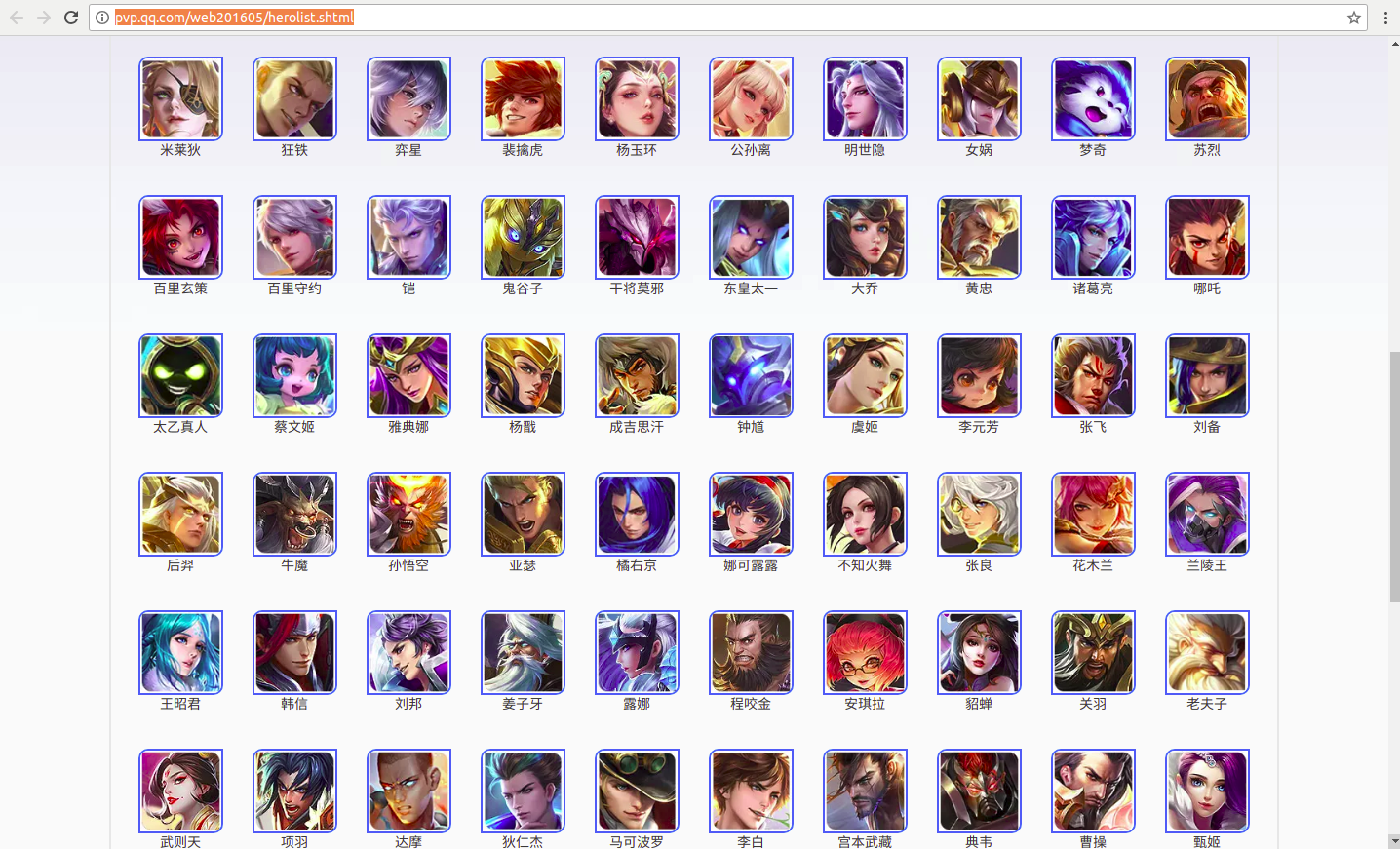
按F12查看元素
看到下面这一堆<li></li>标签了吗
里面的href就是每个英雄的详情地址
图片就在这个链接中
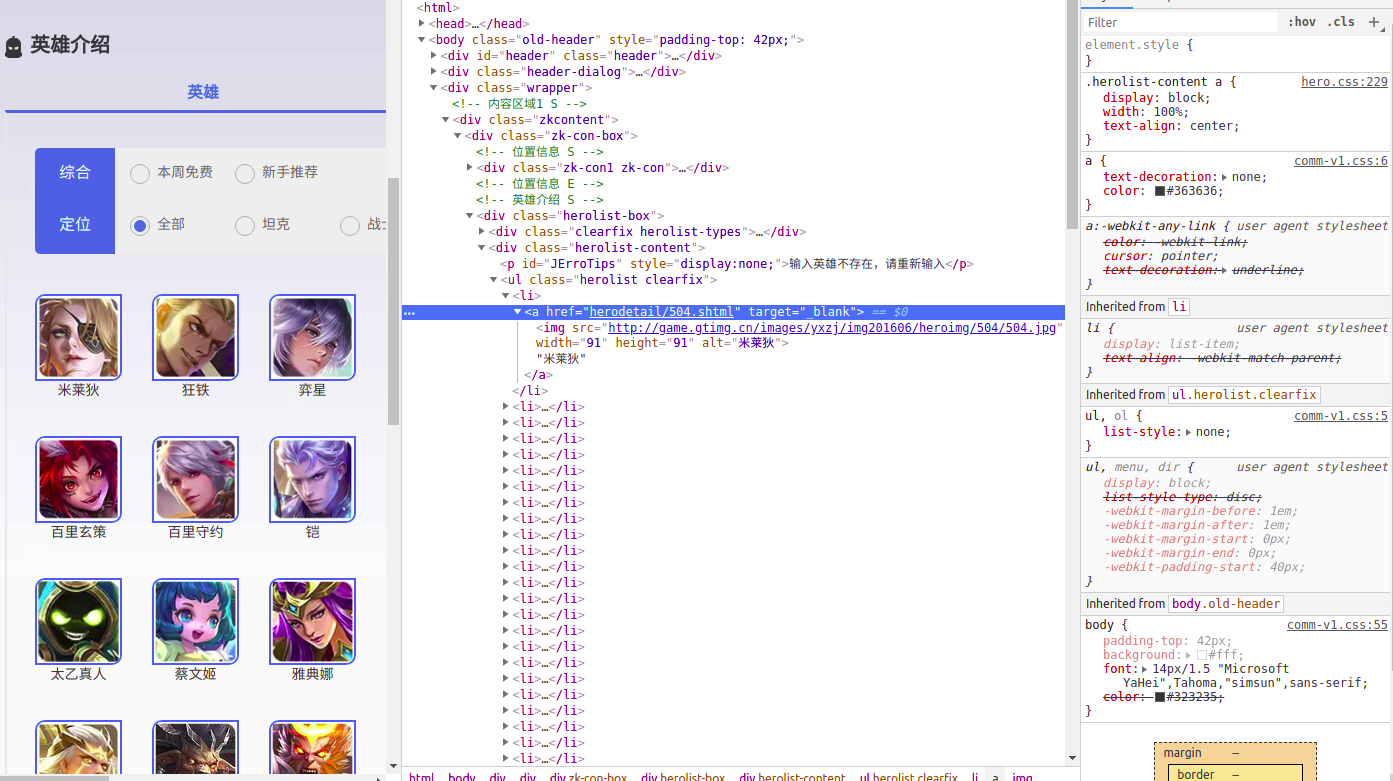
拿到selector
body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li > a
英雄列表获取源码:
1 def getHeroList(): 2 '''取所以英雄存入list中''' 3 hero = {} 4 res = requests.get(mainurl) 5 sp = BeautifulSoup(res.content, "html.parser") 6 lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li') 7 for li in lists: 8 oj = li.select('a')[0]; 9 hero['url'] = oj['href'] 10 hero['name'] = oj.text 11 # 正则表达式取ename编号 12 ename = re.findall('herodetail/(d+).shtml', oj['href'])[0] 13 hero['ename'] = ename 14 herolist.append(hero) 15 hero = {} 16 return herolist
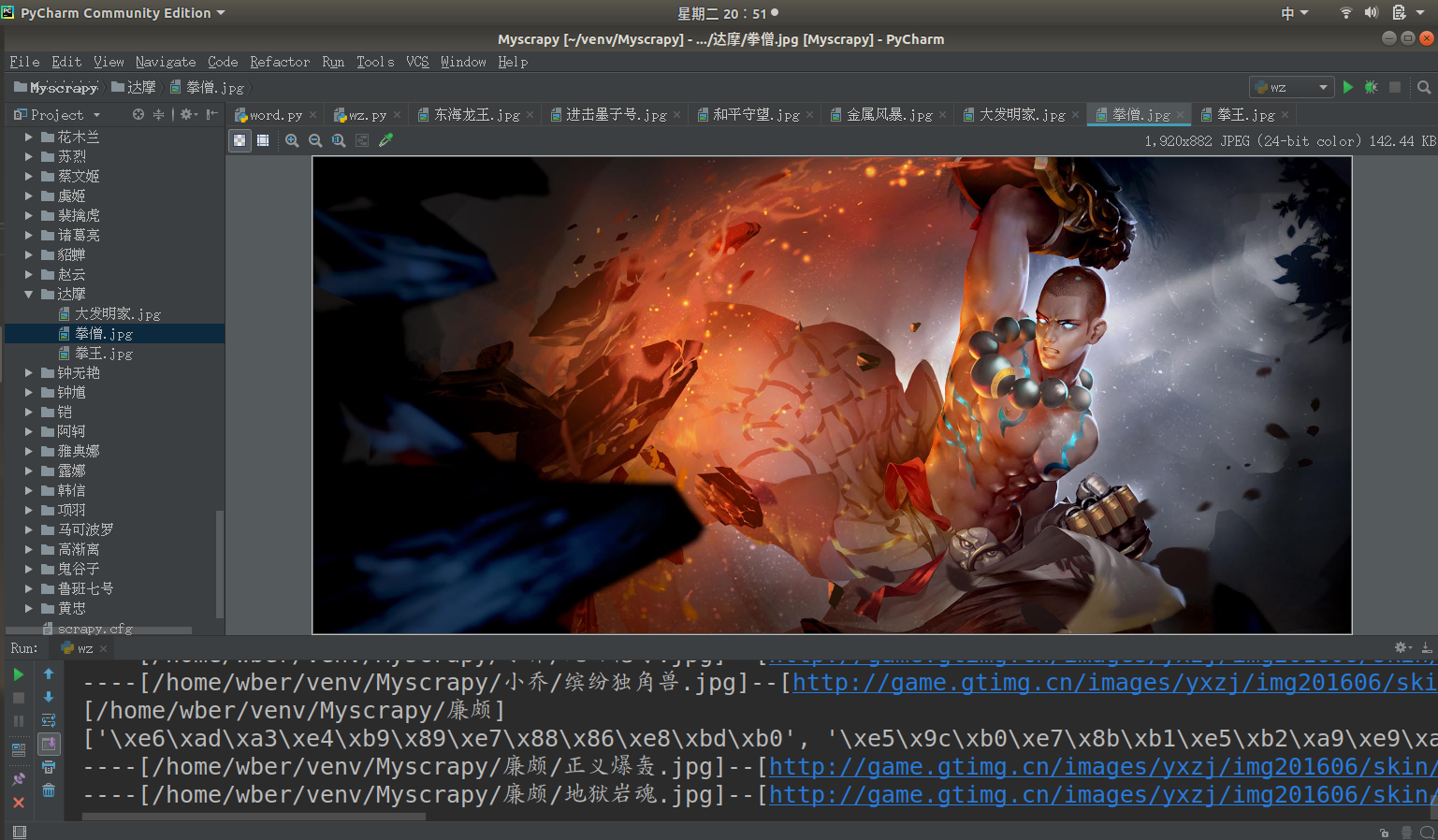
进入英雄详情之后
可以发现,要保存图片的地址也在<li></li>中
他的selector是:
body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul > li > i > img
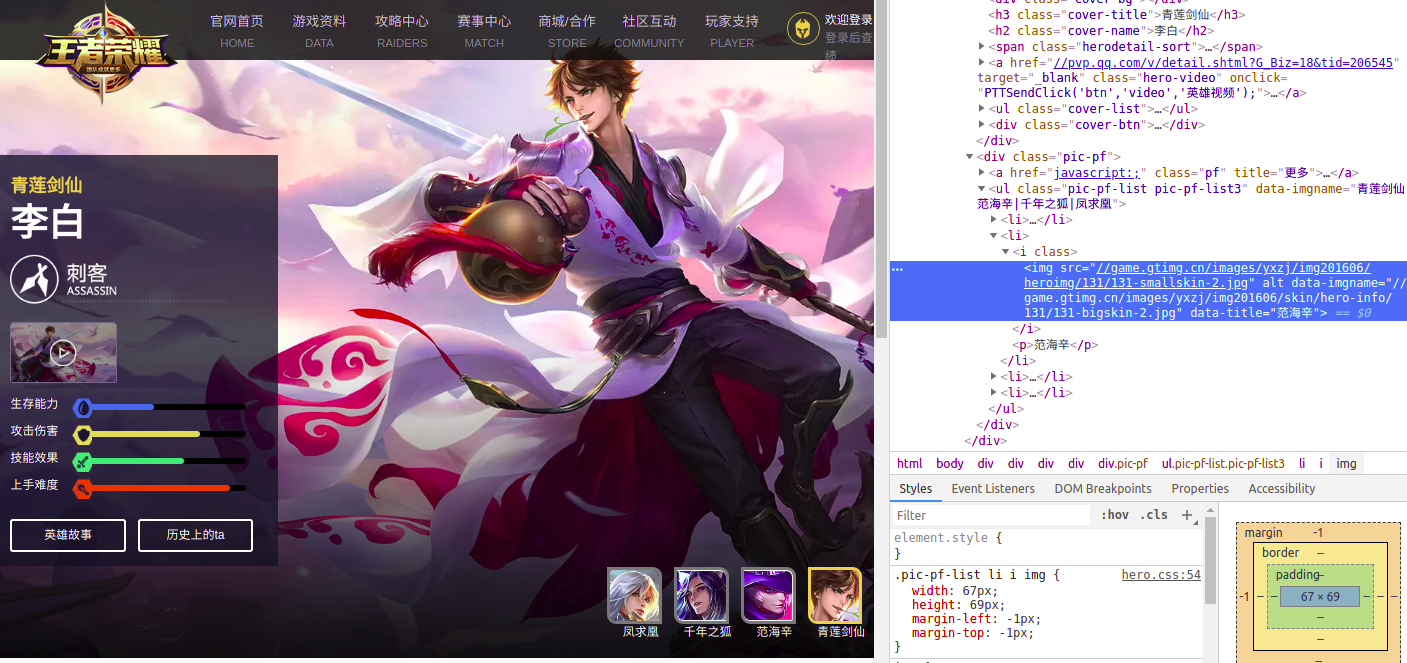
只需要将这个图片保存下来就可以了
代码:
1 def saveImg(filepath, imgUrl): 2 '''下载图片并保存''' 3 r = requests.get(imgUrl, stream=True) 4 with open(filepath, 'wb') as f: 5 for chunk in r.iter_content(chunk_size=1024): 6 if chunk: 7 f.write(chunk) 8 f.flush() 9 f.close()
全部代码:
1 # -*- coding: utf-8 -*- 2 3 import os 4 import re 5 import requests 6 from bs4 import BeautifulSoup 7 8 import sys 9 reload(sys) 10 sys.setdefaultencoding('utf-8') 11 12 baseurl = 'http://pvp.qq.com/web201605' 13 mainurl = 'http://pvp.qq.com/web201605/herolist.shtml' 14 herolist = [] 15 16 17 def getHeroList(): 18 '''取所以英雄存入list中''' 19 hero = {} 20 res = requests.get(mainurl) 21 sp = BeautifulSoup(res.content, "html.parser") 22 lists = sp.select('body > div.wrapper > div > div > div.herolist-box > div.herolist-content > ul > li') 23 for li in lists: 24 oj = li.select('a')[0]; 25 hero['url'] = oj['href'] 26 hero['name'] = oj.text 27 # 正则表达式取ename编号 28 ename = re.findall('herodetail/(d+).shtml', oj['href'])[0] 29 hero['ename'] = ename 30 herolist.append(hero) 31 hero = {} 32 return herolist 33 34 35 def saveImg(filepath, imgUrl): 36 '''下载图片并保存''' 37 r = requests.get(imgUrl, stream=True) 38 with open(filepath, 'wb') as f: 39 for chunk in r.iter_content(chunk_size=1024): 40 if chunk: 41 f.write(chunk) 42 f.flush() 43 f.close() 44 45 46 if __name__ == '__main__': 47 hlist = getHeroList() 48 for hero in herolist: 49 herodir = os.path.join(os.getcwd(), hero['name']) 50 heropage = baseurl + '/' + hero['url'] 51 print('[%s]' % (herodir)) 52 res = requests.get(heropage) 53 sop = BeautifulSoup(res.content, "html.parser") 54 li = sop.select('body > div.wrapper > div.zk-con1.zk-con > div > div > div.pic-pf > ul ')[0]['data-imgname'] 55 li = str(li).split('|') 56 print(li) 57 # 遍历所有皮肤 58 for i in range(len(li)): 59 imgurl = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' 60 + hero['ename'] + '/' + hero['ename'] + '-bigskin-' + str(i + 1) + '.jpg' 61 imgname = os.path.join(herodir, li[i] + ".jpg") 62 print('----[%s]--[%s]---' % (imgname, imgurl)) 63 # 创建英雄目录 64 if os.path.exists(herodir) == False: 65 os.mkdir(herodir) 66 saveImg(imgname, imgurl)
图片生成在同级目录