继承实现原理
python中的类可以同时继承多个父类,继承的顺序有两种:深度优先和广度优先。
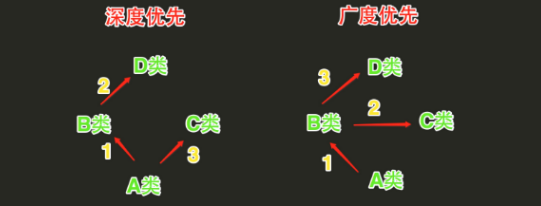
一般来讲,经典类在多继承的情况下会按照深度优先的方式查找,新式类会按照广度优先的方式查找
示例解析:
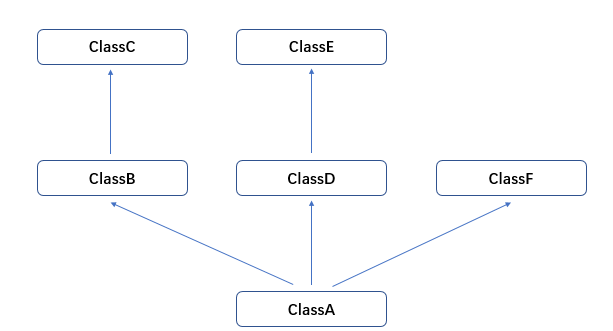
没有共同头部父类的类型

1 class E:
2 def test(self):
3 print('from E')
4 # pass
5 class F:
6 def test(self):
7 print('from F')
8 # pass
9
10 class C:
11 def test(self):
12 print('from C')
13 # pass
14
15 class B(C):
16 def test(self):
17 print('from B')
18 # pass
19
20 class D(E):
21 def test(self):
22 print('from D')
23 # pass
24 class A(B,D,F):
25 def test(self):
26 print('from A')
27 # pass
28 obj=A()
29 obj.test()
在这种模型下,新式类和经典类的继承顺序都一样。
调用obj.test(),首先找boj对象的__dict__字典,然后找生成类A的__dict__字典,如果这两个都没有,会按照以下顺序进行查找,找到为止:
ClassA->ClassB->ClassC->ClassD->ClassE->ClassF
如果都找不到,抛出异常错误。
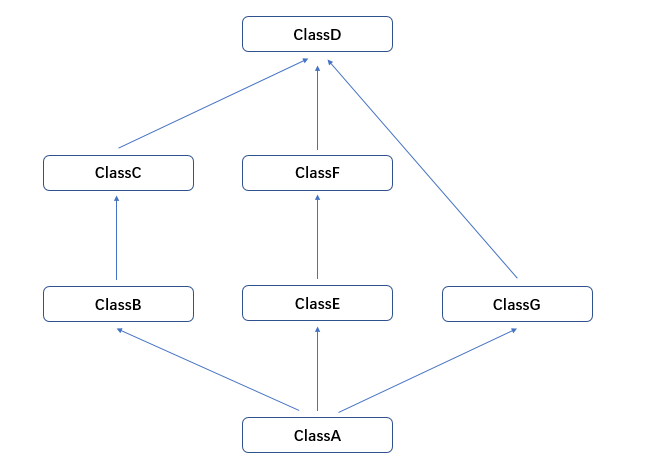
有共同头部父类的类型
1 class D(object):
2 def test(self):
3 print('from D')
4 # pass
5 class C(D):
6 def test(self):
7 print('from C')
8 # pass
9 class B(C):
10 def test(self):
11 print('from B')
12 # pass
13 class F(D):
14 def test(self):
15 print('from F')
16 # pass
17 class E(F):
18 def test(self):
19 print('from E')
20 # pass
21 class H(D):
22 def test(self):
23 print('from H')
24 # pass
25 class G(H):
26 def test(self):
27 print('from G')
28 # pass
29
30 class A(B,E,G):
31 def test(self):
32 print('from A')
33 # pass
34
35 obj=A()
36 obj.test()
37 print(A.mro())
在这种模型下,新式类和经典类查找继承顺序不同。
新式类使用的是广度优先的方式,调用obj.test(),首先找boj对象的__dict__字典,然后找生成类A的__dict__字典,如果这两个都没有,会按照以下顺序进行查找,找到为止:
classA->classB->classC->classE->classF->classG->classH->classD->-classobject
1 #经典类不继承object
2 class D:
3 def test(self):
4 print('from D')
5 # pass
6 class C(D):
7 def test(self):
8 print('from C')
9 # pass
10 class B(C):
11 def test(self):
12 print('from B')
13 # pass
14 class F(D):
15 def test(self):
16 print('from F')
17 # pass
18 class E(F):
19 def test(self):
20 print('from E')
21 # pass
22 class H(D):
23 def test(self):
24 print('from H')
25 # pass
26 class G(H):
27 def test(self):
28 print('from G')
29 # pass
30
31 class A(B,E,G):
32 def test(self):
33 print('from A')
34 # pass
35
36 obj=A()
37 obj.test()
经典类(python2中才有经典类的概念,python3中都是新式类)使用的是深度优先的方式,调用obj.test(),首先找boj对象的__dict__字典,然后找生成类A的__dict__字典,如果这两个都没有,会按照以下顺序进行查找,找到为止:
ClassA->ClassB->ClassC->ClassD->ClassE->ClassF->ClassG
mro方法
python的继承顺序,是按照一定的算法生成的mro表进行顺序查找继承的,只有在新式类中才有该方法:该方法有以下三个特点:
1.子类会先于父类被检查:
2.多个父类会根据它们在列表中的顺序被检查
3.如果对下一个类存在两个合法的选择,选择第一个父类
例如示例二有共同头部父类的模型,新式类mro输出表如下,按照表顺序进行继承:
1 print(A.mro()) 2 [<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.E'>, <class '__main__.F'>, <class '__main__.G'>, <class '__main__.H'>, <class '__main__.D'>, <type 'object'>]
子类调用父类的方法(内置函数super)
low版调用方法,还是那个teacher还是那个people:
1 class People:
2 def __init__(self,name,age,sex):
3 self.name=name
4 self.age=age
5 self.sex=sex
6 def foo(self):
7 print('from parent')
8
9 class Teacher(People):
10 def __init__(self,name,age,sex,salary,level):
11 People.__init__(self,name,age,sex) #指名道姓地调用People类的__init__函数
12 self.salary=salary
13 self.level=level
14 def foo(self):
15 print('from child')
16
17 t=Teacher('bob',18,'male',3000,10)
18 print(t.name,t.age,t.sex,t.salary,t.level)
19 t.foo()
low版调用方法,在更改父类的名字之后,需要改动的地方除了子类继承的父类名字,还要改子类里面调用的父类名,比较麻烦
高端大气调用方式:只需要改动子类继承的父类名,即括号里的父类名字
1 class People:
2 def __init__(self,name,age,sex):
3 self.name=name
4 self.age=age
5 self.sex=sex
6 def foo(self):
7 print('from parent')
8
9 class Teacher(People):
10 def __init__(self,name,age,sex,salary,level):
11 #在python3中
12 super().__init__(name,age,sex) #调用父类的__init__的功能,实际上用的是绑定方法,用到了mro表查询继承顺序,只能调用一个父类的功能
13 #在python2中
14 # super(Teacher,self).__init__(name,age,sex) #super(Teacher,self)是一个死格式
15 self.salary=salary
16 self.level=level
17 def foo(self):
18 super().foo()
19 print('from child')
20
21 t=Teacher('bob',18,'male',3000,10)
22 print(t.name,t.age,t.sex,t.salary,t.level)
23 t.foo()
但是这种方式也有一个缺点,就是当一个子类继承了多个父类的时候,如果多个父类都包含了相同的属性名,当要调用该功能的时候,只能调用第一个父类的功能,无法实现多个父类同时调用。多个父类同时调用还是要用low版方法。
封装
封装是一种隐藏的方式,包括数据封装和功能封装,即类里的数据属性和功能属性,隐藏数据和功能是为了限制直接调用,通过人为的添加调用接口进行数据和功能的调用。
封装不是单纯意义的隐藏:(史上最lowB的解释)
1:封装数据的主要原因是:保护隐私(作为男人的你,脸上就写着:我喜欢男人,你害怕么?)
2:封装方法的主要原因是:隔离复杂度,提供简单的访问接口(快门就是傻瓜相机为傻瓜们提供的接口,该方法将内部复杂的照相功能都隐藏起来了,拍照只需要通过快门这个接口就可以了,再比如你不必知道你自己的尿是怎么流出来的,你直接掏出自己的接口就能用尿这个功能)
提示:在编程语言里,对外提供的接口(接口可理解为了一个入口),可以是函数,称为接口函数,这与接口的概念还不一样,接口代表一组接口函数的集合体。
封装的两个层面
基础的封装(什么都不用做):创建类和对象会创建各自的名称空间,通过类名. 或者对象. 的方式去访问类或对象里面的数据属性和功能属性。
还是这个people
1 class People:
2 def __init__(self,name,age,sex):
3 self.name=name
4 self.age=age
5 self.sex=sex
6 def foo(self):
7 print('from parent')
8 print(People.__dict__)
9 p=People('natasha',18,'female')
10 print(p.name)
11 p.foo()
通过p.name访问到了natasha,通过p.age访问到了18,这一类就是最基础的类和对象的封装,而p.name、p.foo()就是接口,访问数据属性和功能属性的接口。
二层封装:类中把某些属性和方法隐藏起来(或者说定义成私有的),只在类的内部使用、外部无法访问,或者留下少量接口(函数)供外部访问。
封装方式:在python中用双下划线的方式实现隐藏属性(设置成私有的)
1 class Teacher:
2 __school='oldboy' #实际上转换成了_Teacher__school
3 def __init__(self,name,salary):
4 self.name=name
5 self.__salary=salary #实际上转换成了self._Teacher__salary
6 def __foo(self):
7 print('====foo====')
8 t=Teacher('egon',3000)
9
10 # print(t.__school) #无法调用
11 print(Teacher.__dict__)
12 # t.foo() #无法调用
13 t._Teacher__foo()
14 # print(t.salary) #无法调用
15 # print(t.__salary) #无法调用
16 print(t.__dict__)
17 print(t._Teacher__salary)
python中的隐藏并不是真正意义上的隐藏,而是通过语法这一层面进行转换,虽然无法直接通过例如t.__salary或t.salary的方式调用,但是实际上在类的__dict__中可以查看到变形后的调用方式
类中所有双下划线开头的名称如__x都会自动变形成:_类名__x的形式,但是这种变形操作只在定义阶段发生,后边手动添加的不会自动变形
1 Teacher.__N=111111
2 print(Teacher.__dict__)
3 t.__x=1
4 print(t.__dict__)
5 输出结果:
6 {'__module__': '__main__', '_Teacher__school': 'oldboy', '__init__': <function Teacher.__init__ at 0x00000296CDD5B8C8>, '_Teacher__foo': <function Teacher.__foo at 0x00000296CDD5B950>, '__dict__': <attribute '__dict__' of 'Teacher' objects>, '__weakref__': <attribute '__weakref__' of 'Teacher' objects>, '__doc__': None, '__N': 111111}
7 {'name': 'egon', '_Teacher__salary': 3000, '__x': 1}
在类的外部,无法直接使用变形的属性,但是在类的内部可以直接使用
1 class Teacher:
2 __school='oldboy' #_Teacher__school='oldboy'
3 def __init__(self,name,salary):
4 self.name=name
5 self.__salary=salary #self._Teacher__salary=salary
6
7 def foo(self):
8 print('====>',self.__salary) #内部可以调用
9 # print('====>',self._Teacher__salary)
10 t=Teacher('egon',3000)
11
12 # print(t.__salary) #外部无法调用
13 t.foo()
当子类和父类有相同的功能属性,两个类里变形过的功能可以分别调用:
不变形的功能只能调用到子类里的,无法调用父类的func功能
1 class Foo:
2 def func(self):
3 print('from Foo')
4 class Bar(Foo):
5 def func(self):
6 print('from Bar')
7 b=Bar()
8 b.func()
变形后可以分别调用
1 class Foo:
2 def __func(self): #_Foo__func
3 print('from Foo')
4
5 class Bar(Foo):
6 def __func(self): #_Bar__func
7 print('from Bar')
8 b=Bar()
9 b._Foo__func()
10 b._Bar__func()
类里的功能属性和功能属性间调用:
A类和B类同时包含bar功能,A类通过foo功能调用自己的bar功能,通过B实例化b对象,当b对象调用foo的时候,由于B类没有foo功能,所以从A类中找foo功能,找到后调用,并在执行foo功能的过程中调用bar功能,按照mro表顺序查找,通过B类内找到bar功能并执行
1 class A:
2 def foo(self):
3 print('from A.foo')
4 self.bar()
5 def bar(self):
6 print('from A.bar')
7 class B(A):
8 def bar(self):
9 print('from B.bar')
10 b=B()
11 b.foo()
12 输出结果
13 from A.foo
14 from B.bar
变形后调用:定义的过程中已经变形了,所以foo功能在找bar函数的时候实际上找的是变形后的_A__bar()功能
1 class A:
2 def foo(self):
3 print('from A.foo')
4 self.__bar() #self._A__bar()
5 def __bar(self): #_A__bar()
6 print('from A.bar')
7 class B(A):
8 def __bar(self): #_B__bar
9
10 b=B()
11 b.foo()
隐藏所有直接调用属性,通过接口的方式调用属性:又来了,还是那个people
1 class People:
2 def __init__(self,name,age,sex,height,weight):
3 self.__name=name
4 self.__age=age
5 self.__sex=sex
6 self.__height=height
7 self.__weight=weight
8 #name、age、sex、height、weight都是经过变形后存储的,所以在调用的时候没办法直接调用,当然了要调用是可以的
9 def tell_name(self):
10 print(self.__name)
11 #通过手动创建接口的方式返回name的内容,屏蔽了直接调用
12 def set_name(self,val):
13 if not isinstance(val,str):
14 raise TypeError('名字必须是字符串类型')
15 self.__name=val
16 #通过手动创建修改接口修改name的属性值,屏蔽了直接调用
17 def tell_info(self):
18 print('''
19 ---------%s info
20 name:%s
21 age:%s
22 sex:%s
23 height:%s
24 weight:%s
25 ''' %(self.__name,
26 self.__name,
27 self.__age,
28 self.__sex,
29 self.__height,
30 self.__weight))
31 #通过手动创建接口,展示所有的信息
测试验证:
1 bob=People('bob',18,'male','179cm','70kg') #实例化对象
2 bob.tell_info() #通过接口查看bob的所有信息
3 bob.tell_name() #通过接口查看name属性
4 # bob.set_name(123)
5 bob.set_name('natasha') #通过接口修改name属性值
6 bob.tell_info()
property:封装的特性之一
property是一种特殊的属性,访问它时会执行一段功能(函数)然后返回值
手动创建的接口都是函数接口,函数接口在调用的时候都需要加()执行才能调用,如上边的例子bob.tell_name()通过接口查询name属性,基于用户角度来讲,比较显得美好简单的调用方式是bob.name,用户心理毛病多:我只是想看一下名字,为什么要我执行的这个东西?
示例:计算bmi健康指数
1 class People: 2 def __init__(self,name,age,sex,height,weight): 3 self.__name=name 4 self.__age=age 5 self.__sex=sex 6 self.__height=height 7 self.__weight=weight 8 9 @property #bmi=property(bmi),是一个内置函数,本质就是个装饰器 10 def bmi(self): 11 res=self.__weight / (self.__height ** 2) 12 return res
测试验证:
1 bob=People('bob',18,'male',1.79,70)
2 print(bob.bmi) #当调用bob.bmi时候,会返回res的值
使用这种方式,遵循了统一访问的原则,即用户感知不到我是执行了一个函数才获取的值。
但是仅仅这样,还是有问题,比如我想要删除一个属性,是无法删除的,比如del bmi,会提示AttributeError: can't delete attribute,想要通过bob.name='NAME'的方式修改内容也是不行的。
想要实现,需要继续加装饰器:
1 class People:
2 def __init__(self,name,age,sex,height,weight,permission=False):
3 self.__name=name
4 self.__age=age
5 self.__sex=sex
6 self.__height=height
7 self.__weight=weight
8 self.permission=permission
9
10 @property
11 def name(self):
12 return self.__name
13
14 @name.setter #支持obj.name='NAME'的方式执行
15 def name(self,val):
16 if not isinstance(val,str):
17 raise TypeError('must be str')
18 self.__name=val
19
20 @name.deleter #支持del删除操作
21 def name(self):
22 if not self.permission:
23 raise PermissionError('不让删')
24 del self.__name
测试验证:
1 natasha.name=123 2 print(natasha.name) 3 print(natasha.permission) 4 natasha.permission=True #不改成True,if认证不通过会删除失败 5 del natasha.name 6 #print(egon.name) #无法查询,已删除
多态与多态性
多态
多态并不是一个新的知识
多态是指一类事物有多种形态,在类里就是指一个抽象类有多个子类,因而多态的概念依赖于继承
举个栗子:动物有多种形态,人、狗、猫、猪等,python的序列数据类型有字符串、列表、元组,文件的类型分为普通文件和可执行文件,人类又有多种形态,男女老少。。等等例子
1 import abc
2 class Animal(metaclass=abc.ABCMeta): #模拟动物类
3 @abc.abstractmethod
4 def talk(self):
5 pass
6 class People(Animal): #模拟人类
7 def talk(self):
8 print('say hello world')
9 class Cat(Animal): #模拟猫类
10 def talk(self):
11 print('say miaomiaomiao')
12 class Dog(Animal): #模拟狗类
13 def talk(self):
14 print('say wangwangwang')
动物都能叫,所以人类、猫类、狗类也都可以叫,只不过叫的方式不一样。
多态性:
多态性是指具有不同功能的函数可以使用相同的函数名,这样就可以用一个函数名调用到不同功能的函数。
在面向对象方法中一般是这样表述多态性:向不同的对象发送同一条消息(!!!obj.func():是调用了obj的方法func,又称为向obj发送了一条消息func),不同的对象在接收时会产生不同的行为(即方法)
多态性实际上就是一个接口,即调用同一个函数,产生不同的结果。
示例1:使用数据对象的__len__属性统计对象长度
1 def func(obj):
2 obj.__len__()
3 func('hello')
4 func([1,2,3,4])
5 func(('a','b','c'))
示例2:
1 import abc
2 class Animal(metaclass=abc.ABCMeta): #模拟动物类
3 @abc.abstractmethod
4 def talk(self):
5 pass
6 class People(Animal): #模拟人类
7 def talk(self):
8 print('say hello world')
9 class Cat(Animal): #模拟猫类
10 def talk(self):
11 print('say miaomiaomiao')
12 class Dog(Animal): #模拟狗类
13 def talk(self):
14 print('say wangwangwang')
15
16 p1=People()
17 c1=Cat()
18 d1=Dog()
19
20 def talk(obj): #多态性
21 obj.talk()
22 talk(p1)
23 talk(c1)
24 talk(d1)
多态性的优点1:以不变应万变,统一调用接口,使用者只用一种调用方式即可
多态性的优点2:增加扩展性,比如上述代码再加一个Pig类,调用talk功能的方式不会改变,就是talk(Pig对象)
绑定方法与非绑定方法
类中定义的函数分为两类:绑定方法和非绑定方法
绑定方法:绑定给谁就给谁用,可以是对象,也可以是类本身。
绑定到对象的方法:
定义:凡是在类中定义的函数(没有被任何装饰器修饰),都是绑定给对象的,无论有有没有传参
给谁用:给对象用
特点:例如obj.bar() 自动把obj当做第一个参数传入,因为bar中的逻辑就是要处理obj这个对象
示例:
1 class People:
2 def __init__(self, name, weight, height):
3 self.name = name
4 self.weight = weight
5 self.height = height
6 def bmi(self): #绑定到对象,需要传入对象的名字,而类本身是无法使用的,如果硬要使用,也需要把对象名字传进来
7 print(self.weight / (self.height ** 2))
8 f = People('bob', 70, 1.80)
9 f.bmi() #绑定对象使用的方法
10 People.bmi(f) #类使用需要传入对象名字
绑定到类的方法:
定义:在类中定义的,被classmethod装饰的函数就是绑定到类的方法
给谁用:给类用
特点:例如People.talk() 自动把类当做第一个参数传入,因为talk中的逻辑就是要处理类
注意:自动传值只是使用者意淫的,属于类的函数,类可以调用,但是必须按照函数的规则来,在任何过程中都没有自动传值那么一说,传值都是事先定义好的,只不过使用者感知不到。
示例1:
1 class People:
2 def __init__(self,name):
3 self.name=name
4 def bar(self):
5 print('Object name:',self.name)
6 @classmethod #将方法绑定给类People
7 def func(cls): #传入的值只能是类的名字
8 print('Class name:',cls)
9 f=People('natasha')
10 print(People.func) #绑定给类
11 print(f.bar) #绑定给对象
12 People.func() #类调用绑定到类的方法
13 f.func() #对象调用绑定到类的方法,打印的依然是类的名字
输出结果:
1 <bound method People.func of <class '__main__.People'>> #绑定到类的方法 2 <bound method People.bar of <__main__.People object at 0x0000026FC4109B38>> #绑定到对象的方法 3 Class name: <class '__main__.People'> #类调用返回类名 4 Class name: <class '__main__.People'> #对象调用返回类名
非绑定方法:
用staticmethod装饰器装饰的方法,非绑定方法不与类或对象绑定,类和对象都可以调用,但是没有自动传值那么一说。就是一个普通工具而已
注意:没有传值的普通函数并不是非绑定方法,只有被staticmethod装饰的才是非绑定方法。
示例
1 import hashlib
2 import pickle
3 import os
4 # 模拟注册,生成一个唯一id标识
5 student_path=r'C:UsersMr.chaiDesktopPythonProject笔记2017.7.6db'
6
7 class People:
8 def __init__(self,name,sex,user_id):
9 self.name=name
10 self.sex=sex
11 self.user_id=user_id
12 self.id=self.create_id()
13 def tell_info(self): #打印所有信息
14 print('''
15 =====%s info=====
16 id:%s
17 name:%s
18 sex:%s
19 user_id:%s
20 ''' %(self.name,self.id,self.name,self.sex,self.user_id))
21 def create_id(self): #生成一个id号,对name、sex和user_id进行哈希
22 m=hashlib.md5()
23 m.update(self.name.encode('utf-8'))
24 m.update(self.sex.encode('utf-8'))
25 m.update(str(self.user_id).encode('utf-8'))
26 return m.hexdigest()
27 def save(self): #将id号序列化到文件,以id号为文件名字
28 idfile_path=student_path+'\'+self.id
29 with open(idfile_path,'wb') as f:
30 pickle.dump(self,f)
31 @staticmethod #反序列化程序,是一个非绑定方法,无关类和对象
32 def get_all():
33 res=os.listdir(student_path)
34 for item in res:
35 file_path = r'%s\%s' %(student_path,item)
36 with open(file_path,'rb') as f:
37 obj = pickle.load(f)
38 obj.tell_info()
测试:生成序列化文件
1 #实例化对象
2 p1=People('natasha','male',370283111111111111)
3 p2=People('hurry','male',3702832222222222222)
4 p3=People('bob','male',3702833333333333333)
5 #查询唯一标识
6 print(p1.id)
7 print(p2.id)
8 print(p3.id)
9 #对象pickle序列化
10 p1.save()
11 p2.save()
12 p3.save()
13
14 查询输出:
15 b4ea1e1f1e45428ee16035e101caac7b
16 274496ab60ceea8bf4c89c841d2b225c17 0defdb74fdee00f2164839343c16a7d7
生成文件

反序列化:
1 p1.get_all() 2 # p2.get_all() 3 # p3.get_all() 4 5 输出结果 6 7 =====bob info===== 8 id:0defdb74fdee00f2164839343c16a7d7 9 name:bob 10 sex:male 11 user_id:3702833333333333333 12 13 14 =====hurry info===== 15 id:274496ab60ceea8bf4c89c841d2b225c 16 name:hurry 17 sex:male 18 user_id:3702832222222222222 19 20 21 =====natasha info===== 22 id:b4ea1e1f1e45428ee16035e101caac7b 23 name:natasha 24 sex:male 25 user_id:370283111111111111 26