1-1:数据压缩的一个基本问题是“我们要压缩什么”,对此你是怎样理解的?
解答:我们要压缩的是在存储空间、时间空间、结构空间等方面具有冗余特点的图形图像、音频视频等信号源头,这些信号源头存在一定的统计规律。
1-2:数据压缩的另一个基本问题是“为什么进行压缩”,对此你又是如何理解的?
解答:当下,人们对于信息的需求量日益增加,在要求保证信息的有效性和可靠性的同时,又要求优化信息存储空间的大小等。而数据压缩不仅能满足用户需求,亦能做到更好。首先,如果数据进行压缩,能解决数据传输的有效性、可靠性,安全性问题。其次,数据压缩能去除数据中的冗余度,实现数据在时间域、频率域、能量域、空间域的压缩,更利于数据的传输或存储。最后,数据压缩能实现用户利益最大化,减少不必要的开支。数据压缩使我们获得诸多好处,与我们的生活息息相关。
1-6:数据压缩技术是如何进行分类的?
解答:数据压缩可分成有损压缩和无损压缩。
(1)有损压缩
有损压缩是对压缩后的数据进行重构,但重构后的数据与原始数据有一定的差异,这种压缩方式在一定程度上并不影响原始数据表达的信息。有损压缩用于重构的信号不一定与原始信号一致的场合。例如,图像和声音的压缩就可以采用有损压缩,因为其中包含的数据往往多于我们的视觉系统和听觉系统所能接收的信息,倘若丢失少量不必要数据,并不会对原始数据所表达的信息产生较大影响,这种压缩方式既能保证信息质量,也实现存储空间、时间空间等方面的优化。
(2)无损压缩
有损压缩是对压缩后的数据进行重构,(或者叫做还原,解压缩),重构后的数据与原始数据完全相同;无损压缩用于要求重构的信号与原始信号完全一致的场合。一个很常见的例子是磁盘文件的压缩。根据目前的技术水平,无损压缩算法一般可以把普通文件的数据压缩到原来的1/2~1/4。一些常用的无损压缩算法有霍夫曼(Huffman)算法和LZW(Lenpel-Ziv & Welch)压缩算法。
1.4、用你的计算机上的压缩工具来压缩不同文件。研究原文件的大小和类型对于压缩文件与原文件大小之比的影响。
备注:压缩率K=压缩文件大小/原文件大小
|
文件类型 |
原文件大小 |
压缩文件大小 |
K |
|
|
图片 |
JPG |
858KB |
857KB |
0.9988 |
|
757KB |
754KB |
0.9960 |
||
|
PSD |
2.07MB |
1.33MB |
0.6425 |
|
|
2.27MB |
1.33MB |
0.5859 |
||
|
PNG |
1.17MB |
1.17MB |
1.000 |
|
|
1.16MB |
1.16MB |
1.000 |
||
|
音频 |
MP3 |
1.34MB |
1.32MB |
0.9850 |
|
7.65MB |
7.62MB |
0.9960 |
||
|
APE |
7.89MB |
7.89MB |
1.0000 |
|
|
23.2MB |
23.2MB |
1.0000 |
||
|
WAV |
32.50MB |
26.0MB |
0.8000 |
|
|
14.8MB |
12.6MB |
0.8513 |
解答:通过对图片、音频的简单调查,得出如上的调查表。通过对该调查表的简单分析,得出如下结论:
(1) 对于已是无损压缩这一类型的文件,当我们再次使用压缩软件来压缩该文件时,K值大小为1,这说明,使用压缩软件前后,原文件与压缩文件大小一致。例如针对PNG这类图片文件以及APE这类音频文件,它们本身就是属于无损压缩,当我们再次使用压缩软件,并不能影响再次压缩后的文件大小。简而言之,对于本身已是无损压缩这类图片、音频文件来说,原文件的大小和类型并不影响压缩文件与原文件之比。
(2) 与(1)道理相通,对于已是有损压缩这一类型文件,K值在(0,1)范围内活动,这说明,使用压缩软件前后,原文件与压缩文件大小有所差异。例如针对JPG、PSD这类图片以及MP3、WAV这类音频文件,他们本身属于有损压缩,当再次使用压缩软件时,压缩文件与原文件大小并不相等。简而言之,对于本身已是有损压缩这类图片、音频文件来说,原文件的大小和类型影响着压缩文件与原文件之比。
2、从一本通俗杂志中摘录几段文字,并删除所有不会影响理解的文字,实现压缩。例如,在"this is the dog that belong to my friend” 中,删除 is 、the、that和to之后,仍然能传递相同的意思。用被删除的单词数与原文本的总单词数之比来衡量文本中的冗余度。用一本技术期刊中的文字来重复这一实验。对于摘自不同来源的文字,我们能否就其冗余度做出定量论述?
解答:不能,因为在处理文本信息时,除了信息冗余外,还有信息重复等情况,而信息来源不同,情况也不一样,处理方式也不一样。
3、给定符号集A={a1,a2,a3,a4},求以下条件下的一阶熵:
(a)P(a1)=P(a2)=P(a3)=P(a4)=1/4 (b)P(a1)=1/2 , P(a2)=1/4 , P(a3)=P(a4)=1/8 (c)P(a1)=0.505 , P(a2)=1/4 , P(a3)=1/8 , P(a4)=0.12
(a)
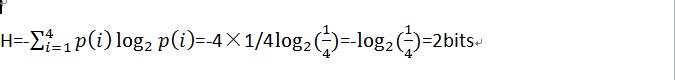
(b)
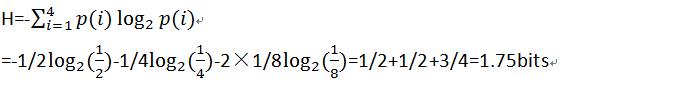
(c)

5、考虑以下序列:
ATGCTTAACGTGCTTAACCTGAAGCTTCCGCTGAAGAACCTG
CTGAACCCGCTTAAGCTTAAGCTGAACCTTCTGAACCTGCTT
(a)根据此序列估计个概率值,并计算这一序列的一阶、二阶、三阶和四阶熵。
(b)根据这些熵,能否推断此序列具有什么样的结构?

7、做一个实验,看看一个模型能够多么准确地描述一个信源。
(a)编写一段程序,从包括26个字母的符号集{a,b,...,z}中随机选择字母,组成100个四字母单词,这些单词中有多少是有意义的?
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
void main(){
char a[27]="abcdefghijklmnopqrstuvwxyz";
int i,j,k;
srand((int)time(0));
for(i=0;i<100;i++)
{
for(j=0;j<4;j++)
{
k= rand()%26;
printf("%c",a[k]);
}
printf(" ");
}
}

解答:通过这种随机获取的单词,大多数都是无效。这种方式限制了单词的长度,在要求单词长度的同时,也要求单词的正确率,这几乎是不可能完成。