
print( "Hello,NumPy!" )
学习痛苦啊,今天学,明天丢。这种天气,还是睡觉最舒服了。

咱说归说,闹归闹,但还是得学才行啊。
之前在学习的过程中一直都有记录笔记的习惯,但笔记质量可不敢恭维,大多都未曾整理,不过拿来复习倒是个不错的选择。

自打接触Python以来,写的最多的就是爬虫了,什么网络小说啊,虚拟游戏币啊,考试题库啊之类的都有写过,也帮别人爬过不少网站公开数据。之前也整理过一篇爬虫相关的文章(太懒了,才一篇,之后有机会有时间,再整理出来吧):网络爬虫之页面花式解析
再之后的话,就对Social Engineering产生了一定的兴趣,或许需要能言善辩,巧舌如簧,达到“江湖骗子”的等级,才能玩转社会工程学吧。之前也写过一篇Web渗透相关的文章:Taoye渗透到一家黑平台总部,背后的真相细思极恐。
这里还是有必要提醒一下大家,对于一些不信任的人或信息,如果你会一些网络安全相关技能,可以当做一次渗透经验,否则的话,最好的处理方式是置之不理,别让你的好奇心成为坠入深渊的开始,尤其是在这云龙混杂的虚拟网络世界中。就在前几天,警方还破获了全国最大网络 luo liao 敲诈案呢,受害者达10余万人,涉案金额也有XXXXXXXXXXXXXXX,大家还是需要注意的。

反正,学的东西很多、很杂,学的也不精,记录的笔记也很少回过头复习。工欲善其事,必先利其器,这不开始系统性学习机器学习么,所以想把之前记录的Numpy、Pandas、Matplotlib“三剑客”笔记重新整理一下,也算是做一个回顾。
后期的话,会学习一些机器学习算法,主要参考《机器学习实战 / Machine Learning in Action》和周志华老师的《机器学习》西瓜书,以及其他一些圈内大佬写的一些技术文章。能手撕的话尽量手撕,不能手撕只能说明自己还有待提高吧。
Flag立的太多,感觉会被啪啪打脸。没事,慢慢来吧,打脸也不怕,反正皮糙肉厚 ( ̄_, ̄ )
这篇文章先把NumPy整理出来吧,可能记录的并不全面,只记录了一些常用的,其他的话后期用到了再进行更新吧。以下内容主要参考菜鸟教程和NumPy官方文档:
- NumPy菜鸟教程:https://www.runoob.com/numpy/numpy-tutorial.html
- NumPy官方文档:https://numpy.org/doc/stable/user/quickstart.html
关于NumPy的安装,前面在介绍深度学习环境搭建的时候已经介绍过了,推荐安装Anaconda,其内部集成了大量第三方工具模块,而不需要手动 pip install ...,这一点就有点像Java中的Maven。Anaconda可参考:基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境
如果您没有安装Anaconda那也没事,只需要在Python环境下执行以下命令安装NumPy即可:
> pip3 install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
以下内容采用的NumPy的版本为:1.18.1
In [1]: import numpy as np
In [2]: np.__version__
Out[2]: '1.18.1'
在NumPy中,操作的对象大多为ndarray类型,也可称其别名为array,我们可以把它看做矩阵或向量。
创建np.ndarray对象有多种方式,NumPy中也有多个api可供调用,比如我们可以通过如下方式创建一个指定的ndarray对象:
In [7]: temp_array = np.array([[1, 2, 3], [4, 5, 6]], dtype = np.int32)
In [8]: temp_array
Out[8]:
array([[1, 2, 3],
[4, 5, 6]])
In [9]: type(temp_array)
Out[9]: numpy.ndarray # 输出的类型为ndarray
当然了,也可以调用arange,然后对其进行reshape操作来改变其形状,将向量转换成2x3的矩阵形式,此时的对象类型依然是numpy.ndarray:
In [14]: temp_array = np.arange(1, 7).reshape(2, 3) # arange产生向量,reshape改变形状,转化成矩阵
In [15]: temp_array
Out[15]:
array([[1, 2, 3],
[4, 5, 6]])
In [16]: type(temp_array) # 输出的类型依然是ndarray
Out[16]: numpy.ndarray
由上,我们可以发现,无论通过什么方式(其他方式后期会有介绍)来创建对象,NumPy操作的都是ndarray类型,且该类型对象中主要包含以下属性:
- ndarray.ndim:表示ndarray的轴数,也可理解成维度,或者可以通俗的理解成外层中括号的数量。比如[1, 2, 3]的ndim就是1,[[1], [2], [3]]的ndim等于2,[[[1]], [[2]], [[3]]]的ndim等于3(注意观察外层中括号的数量)
- ndarray.shape:表示ndarray的形状,输出的是一个元组。该ndarray有n行m列,那输出的就是(n, m),比如[[1], [2], [3]]输出的是(3, 1),[[[1]], [[2]], [[3]]]输出的是(3, 1, 1),[[[1, 2]], [[3, 4]]]输出的是(2, 1, 2)。通过上述3个例子,可以发现shape是按照从外至内的顺序来表示的
- ndarray.size:这个比较容易理解,表示的就是ndarray内部元素的总个数,也就是shape的乘积
- ndarray.dtype:表示ndarray内部元素的数据类型,常见的有
numpy.int32、numpy.int64、numpy.float32、numpy.float64等
以上就是ndarray中常见的一些属性,注意:只是部分,并非全部,其他属性可参考官方文档
我们可以通过以下列子来观察下ndarray的各个属性,以及其内部的属性应该如何修改:

以上例子中涉及到的np.expand_dims和np.astype会在后面进行介绍。
np.zeros可以创建一个元素全0的ndarray,np.ones则可以创建一个元素全1的ndarray。创建的时候可以指定ndarray的shape形状,也可以通过dtype属性指定内部元素的数据类型:
In [70]: np.zeros([2,3,2], dtype=np.float32)
Out[70]:
array([[[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]], dtype=float32)
In [71]: np.ones([3,2,2], dtype=np.float32)
Out[71]:
array([[[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.]]], dtype=float32)
另外,在Tensorflow中可以通过tf.fill产生指定元素的指定shape张量,如下产生2x3的张量,且内部元素为100:
In [76]: import tensorflow as tf
In [77]: tf.fill([2,3], 100)
Out[77]:
<tf.Tensor: shape=(2, 3), dtype=int32, numpy=
array([[100, 100, 100],
[100, 100, 100]])>
而在NumPy中,也有fill接口,只不过只能通过已有的ndarray才能调用fill,而无法直接np.fill进行调用:
In [79]: data = np.zeros([2, 3])
In [80]: data.fill(100)
In [81]: data
Out[81]:
array([[100., 100., 100.],
[100., 100., 100.]])
np.arange与常用的range作用类似,用于产生一个固定区间连续的ndarray,注意取左不取右,且数组之间成一个等差数列,公差可自行定义(可为小数),如下:
In [85]: np.arange(10)
Out[85]: array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
In [86]: np.arange(3, 10, 2)
Out[86]: array([3, 5, 7, 9])
In [87]: np.arange(3, 10, 0.7)
Out[87]: array([3. , 3.7, 4.4, 5.1, 5.8, 6.5, 7.2, 7.9, 8.6, 9.3])
numpy.linspace 函数用于创建一个一维数组,数组是一个等差数列构成的,可以指定元素内部元素的个数以及是否包含stop值。如下,在区间1-5中创建一个元素数目为10的等差数列:
In [89]: np.linspace(1, 5, 10) # 默认包含stop
Out[89]:
array([1. , 1.44444444, 1.88888889, 2.33333333, 2.77777778,
3.22222222, 3.66666667, 4.11111111, 4.55555556, 5. ])
In [90]: np.linspace(1, 5, 10, endpoint = False) # endpoint属性可以设置不包含stop
Out[90]: array([1. , 1.4, 1.8, 2.2, 2.6, 3. , 3.4, 3.8, 4.2, 4.6])
np.random.random和np.random.rand随机从0-1中生成对应shape的ndarray对象:
In [4]: np.random.random([3, 2])
Out[4]:
array([[0.68755531, 0.56727707],
[0.86027161, 0.01362836],
[0.56557302, 0.94283249]])
In [5]: np.random.rand(2, 3)
Out[5]:
array([[0.19894754, 0.8568503 , 0.35165264],
[0.75464769, 0.29596171, 0.88393648]])
np.random.randint随机生成指定范围的ndarray,且内部元素为int类型:
In [6]: np.random.randint(0, 10, [2, 3])
Out[6]:
array([[0, 6, 9],
[5, 9, 1]])
np.random.randn返回满足标准正态分布的ndarray(均值为0,方差为1):
In [7]: np.random.randn(2,3)
Out[7]:
array([[ 2.46765106, -1.50832149, 0.62060066],
[-1.04513254, -0.79800882, 1.98508459]])
另外,我们在NumPy中使用random的时候,都是随机产生的一组数据,而要想每次产生的数据相同,则需要通过np.random.seed来进行设置:
In [33]: np.random.seed(100)
In [34]: np.random.randn(2, 3)
Out[34]:
array([[-1.74976547, 0.3426804 , 1.1530358 ],
[-0.25243604, 0.98132079, 0.51421884]])
In [35]: np.random.seed(100)
In [36]: np.random.randn(2, 3)
Out[36]:
array([[-1.74976547, 0.3426804 , 1.1530358 ],
[-0.25243604, 0.98132079, 0.51421884]])
在NumPy中的一维ndarray里,就如同列表一样操作,可以对其进行切片和遍历等操作:
In [5]: a
Out[5]: array([1., 2., 3., 4., 5., 6., 7., 8., 9.])
In [6]: a[2], a[2:5]
Out[6]: (3.0, array([3., 4., 5.]))
In [7]: a * 3, a ** 3 # 立方
Out[7]:
(array([ 3., 6., 9., 12., 15., 18., 21., 24., 27.]),
array([ 1., 8., 27., 64., 125., 216., 343., 512., 729.]))
In [13]: for i in a:
...: print(i, end=", ")
1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0, 9.0,
假如我们的ndarray并非是一维数组,而是二维矩阵,或是更高维度的ndarray,则我们需要对其进行多维度的切分。且当我们对高维度的ndarray进行遍历的时候,则遍历出单个结果的维度比元维度少一,比如2维矩阵遍历得到的结果为1维向量,三维遍历的结果为2维矩阵。
另外,还有一点需要说明的是,加入我的数据的维度相当高,为了方便我们对数据进行索引,NumPy为我们提供了...的方式来进行切分,具体例子如下:
In [14]: a = np.random.randint(0, 2, 6).reshape(2, 3)
In [15]: a
Out[15]:
array([[1, 1, 1],
[1, 0, 1]])
In [16]: a[:, :2]
Out[16]:
array([[1, 1],
[1, 0]])
In [17]: for i in a: # 对矩阵进行遍历,则输出的是行向量,单个输出的维度比原维度少1
...: print(i, end=", ")
[1 1 1], [1 0 1],
In [19]: data = np.random.randint(0, 2, [2, 2, 3])
In [20]: data
Out[20]:
array([[[0, 0, 1],
[0, 1, 1]],
[[1, 0, 0],
[0, 1, 0]]])
In [21]: data[..., :2] # ...则表示前两个维度全要,相当于 data[:, :, :2]
Out[21]:
array([[[0, 0],
[0, 1]],
[[1, 0],
[0, 1]]])
shape操作:
- a.ravel()、ndarray.flatten(),将ndarray进行拉伸操作(拉直成向量形式)
- a.reshape(),重新改变a的shape外形
- a.T、a.transpose(),返回a的倒置矩阵
以上几个操作返回的都是新的结果,而不改变原来的ndarray(a)。且上述操作默认的都是横向操作,如果需要纵向,则需要控制order参数,具体操作可参考菜鸟教程。除了reshape之外,还有resize,只不过resize会改变a的结果,而并非产生一个新的结果:

还有一个小技巧需要掌握的是,在进行reshape的时候,假如传入-1,则会自动计算出对应的结果。比如一个 2x3的矩阵a,我们进行a.reshape(3, -1),则这里的-1代表的就是2,当我们数据量大的时候,这个用起来还是挺方便的:
In [44]: a
Out[44]:
array([[1, 1, 1],
[1, 0, 1]])
In [45]: a.reshape([3, -1])
Out[45]:
array([[1, 1],
[1, 1],
[0, 1]])
数组维度的修改:
| 维度 | 描述 |
|---|---|
| broadcast_to | 将数组广播到新形状 |
| expand_dims | 扩展数组的形状 |
| squeeze | 从数组的形状中删除一维条目 |
具体操作如下:

数组的连接:
| 函数 | 描述 |
|---|---|
| concatenate | 连接沿现有轴的数组序列 |
| hstack | 水平堆叠序列中的数组(列方向) |
| vstack | 竖直堆叠序列中的数组(行方向) |
下面代码显示了数组连接的操作,其中concatenate可以通过控制axis的值来确定连接的方向,作用等同于hstack和vstack。还有一点需要注意的是:以下示例仅仅是连接两个数组,其实可以同时连接多个的,比如np.concatenate((x, y, z), axis=1)

数组的切分:
| 函数 | 描述 |
|---|---|
| split | 将一个数组分割为多个子数组 |
| hsplit | 将一个数组水平分割为多个子数组(按列) |
| vsplit | 将一个数组垂直分割为多个子数组(按行) |
同数组的连接一样,split可以通过控制axis属性来得到与hsplit、vsplit相同的作用,下面只给出split的示例,关于hsplit和vsplit可参考官方文档:

数组元素的添加和删除:
| 函数 | 描述 |
|---|---|
| append | 将值添加到数组末尾 |
| insert | 沿指定轴将值插入到指定下标之前 |
| delete | 删掉某个轴的子数组,并返回删除后的新数组 |

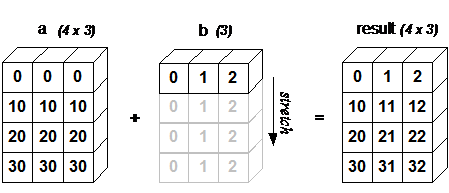
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行。
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同。
In [8]: import numpy as np
In [9]: a = np.array([1,2,3,4])
...: b = np.array([10,20,30,40])
In [10]: a * b
Out[10]: array([ 10, 40, 90, 160])
当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如:
In [11]: a = np.array([[ 0, 0, 0],
...: [10,10,10],
...: [20,20,20],
...: [30,30,30]])
...: b = np.array([1,2,3])
In [12]: a + b
Out[12]:
array([[ 1, 2, 3],
[11, 12, 13],
[21, 22, 23],
[31, 32, 33]])
下面的图片展示了数组 b 如何通过广播来与数组 a 兼容。
np.tile可以对目标操作数组进行广播扩展,比如 1x3 如下操作可以广播为 4x6,注意与前面所说的broadcast_to进行区别,broadcast_to必须要扩维,而tile可扩维,也可不扩维,具体操作根据自己的实际需求进行。
有过Tensorflow经验的读者应该知道,其内部也有tile和broadcast操作,但是当我们的数据量比较大的时候,据说tile的效率比broadcast要低,暂时还没了解原因,以后有用到在了解吧。
In [20]: a
Out[20]: array([[1, 1, 0]])
In [21]: np.tile(a, [4, 2]) # 第二个参数表示各个维度广播的倍数,这里表示的是行扩4倍,列扩2倍
Out[21]:
array([[1, 1, 0, 1, 1, 0],
[1, 1, 0, 1, 1, 0],
[1, 1, 0, 1, 1, 0],
[1, 1, 0, 1, 1, 0]])
关于NumPy中的复制和试图:这个部分的知识也是我之前在学习NumPy时候所遗漏的点,趁着这个机会,把它在这记录一下。
- 没有复制
关于这一点,其实在之前记录LeetCode 热题 HOT 100(01,两数相加)算法的时候同样提到过,这一点还是需要格外注意的。

- 视图或者浅拷贝(view)
同样采用上面一样的代码,仅仅修改了第57行,将 y = x 和 y = x.view(),可以发现,此时的x和y的id值不一样,也就是说他们的内存地址不一样,我们修改x的shape之后,y的shape并没有发生改变。
但是,当我们改变不是shape,而是改一个变数组内部的数据,则另一个数组同样会发生改变

- 副本或者深拷贝(copy)
视图或者浅拷贝采用的是view,而副本或者深拷贝采用的是copy。使用copy的时候无论是修改一个数组的shape,还是内部元素,另一个数组都不会发生改变。
(关于copy,这里就不再演示代码了,读者可自行操作,然后进行比较)
最后总结一下:
- y = x,说明x和y的内存地址相同,修改其中一个,另一个也会随着发生改变(无论是shape,还是内部元素)
- y = x.view(),两者的内存地址不一样,修改其中一个的shape,另一个不会发生改变;而修改其中一个元组的内部元素,则另外一个会跟着发生改变
- y = x.copy(),两者的内存地址不一样,无论是修改一个元组的shape,还是内部元素,另外一个都不会发生改变,两者相互独立
NumPy中的数学相关函数,这部分内容没什么好讲的:
- np.pi,返回π值
- np.sin(),返回正弦值
- np.cos(),返回余弦值
- np.tan(),返回正切值
- numpy.ceil(),返回大于或者等于指定表达式的最小整数,即向上取整。
- np.exp(2),返回指数值,也就是 (e^2)
其他相关数学函数,可参考官方文档。
NumPy中的算术运算,这部分内容也没什么好讲的:
- numpy.add(a,b):两数组相加
- numpy.subtract(a,b):两数组相减
- numpy.multiply(a,b):两数组相乘
- numpy.divide(a,b):两数组相除
- numpy.reciprocal(a),返回倒数
- numpy.power(a, 4),返回a的四次方
NumPy中的统计函数,这个稍微记录一下:

以上示例了在数组中获取最值以及最值之差的方式,传入了axis参数,则按照对应方向获取,假如没有传入axis参数,则表示获取数组整体的最值。除了以上几个接口之外,还有其他一些常见的统计函数,具体操作和上述并无一二,如下:
- np.amin():获取最小值
- np.amax():获取最大值
- np.ptp():获取最值之差
- np.median():获取中位数(中值)
- np.mean():获取均值
- np.var():获取方差,(sigma^2 = frac{1}{n}sum_{i=1}^n(x_i-overline{x})^2)
- np.std():获取标准差,(sigma)
NumPy中的线性代数:
- np.dot(a, b) 就是两个矩阵的乘积
- np.vdot(a, b) 两个矩阵对应位置数的乘积之和
- np.inner(a, b) 內积,就是a的每行与b的每行相乘求和
比如a=[[1, 0], [1, 1]],b=[[1, 2], [1, 3]]
np.inner(a, b)相当于[1, 0] * [1, 2] = 1 -> 为第一个数
[1, 0] * [1, 3] = 1 -> 为第二个数
[1, 1] * [1, 2] = 3 -> 为第三个数
[1, 1] * [1, 3] = 4 -> 为第四个数
矩阵乘积就是第一个矩阵的行与第二个矩阵的列乘积之和,而inner相当于第一个矩阵和第二个矩阵的行乘积之和
- np.matmul(a, b) 目前感觉和np.dot(a, b)作用一样,都是矩阵乘积
- np.linalg.det(a) 计算矩阵的行列式的值
- np.linalg.solve(a, [[1], [1]]) 求线性方程组的解,第一个的参数相当于系数,第二个参数相当于参数项
- np.linalg.inv(a) 计算矩阵的逆矩阵
# 将数组保存到以 .npy 为扩展名的文件中。
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
- file:要保存的文件,扩展名为 .npy,如果文件路径末尾没有扩展名 .npy,该扩展名会被自动加上。
- arr: 要保存的数组
- allow_pickle: 可选,布尔值,允许使用 Python pickles 保存对象数组,Python 中的 pickle 用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化。
- fix_imports: 可选,为了方便 Pyhton2 中读取 Python3 保存的数据。
In [81]: a = np.random.randint(1, 10, [3, 4])
In [82]: np.save("a.npy", a)
In [83]: np.load("a.npy")
Out[83]:
array([[2, 7, 3, 1],
[4, 6, 4, 3],
[2, 2, 9, 5]])
参考资料:
参考资料:
[1] NumPy菜鸟教程:https://www.runoob.com/numpy/numpy-tutorial.html
[2] NumPy官方文档:https://numpy.org/doc/stable/user/quickstart.html
时间不太够,后面写的有点仓促了,但应该并不影响正常阅读和以后的复习,暂时就这样吧。
注意:只记录了一些常用的,其他的话后期用到了再进行更新吧,其他内容可自行参考文档。
本来是打算按照《机器学习实战 / Machine Learning in Action》这本书来手撕其中代码的,但由于实际原因,可能需要先手撕SVM了,这个算法感觉还是挺让人头疼,其中内部太复杂了,也很少有资料将其完整的推导出来,也涉及到了许多陌声的名词,如:非线性约束条件下的最优化、KKT条件、拉格朗日对偶、最大间隔、最优下界、核函数等等,天书或许、可能、大概就是这样的吧。好在之前有学习过SVM,但想必依然需要花费大力气来手撕,也需要参考不少资料,包括但不局限于《机器学习实战 / Machine Learning in Action》、《机器学习》、《统计学习方法》。
所以,下期的话,应该会开始手撕SVM,至于最后能不能手撕成功,还真不好说。时间可能需要不少,这期间的LeetCode HOT 100 还需要正常刷起来。
我是Taoye,爱专研,爱分享,热衷于各种技术,学习之余喜欢下象棋、听音乐、聊动漫,希望借此一亩三分地记录自己的成长过程以及生活点滴,也希望能结实更多志同道合的圈内朋友,更多内容欢迎来访微信公主号:玩世不恭的Coder。
推荐阅读:
干啥啥不行,吃饭第一名
Taoye渗透到一家黑平台总部,背后的真相细思极恐
《大话数据库》-SQL语句执行时,底层究竟做了什么小动作?
那些年,我们玩过的Git,真香
基于Ubuntu+Python+Tensorflow+Jupyter notebook搭建深度学习环境
网络爬虫之页面花式解析
手握手带你了解Docker容器技术
一文详解Hexo+Github小白建站
打开ElasticSearch、kibana、logstash的正确方式