------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
本次主要分享,我们在神经网络模型部署上的其中一次探索,“tensorflow quantization-aware”
参考资源如下:
“Quantizing deep convolutional networks for efficient inference: A whitepaper”
”Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference“
”https://github.com/google/gemmlowp“
”https://spatial-lang.org/gemm“
“https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite”
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 现状:
智能移动设备的日益普及以及基于深度学习的模型令人生畏的计算成本要求建立有效而准确的设备上推理方案。我们提出了一种量化方案,该方案允许使用integer-only 算法进行推理,该算法比在通常可用的仅整数硬件上的浮点推理更有效地实现。我们还共同设计了一种训练程序,以保持量化后的端到端模型准确性。结果,所提出的量化方案improves the tradeoff between accuracy and on-device latency 。即使在以运行时效率闻名的模型系列MobileNets上,这些改进也非常重要,并且在ImageNet分类和流行CPU的COCO检测中得到了证明。
当前最先进的卷积神经网络(CNN)不太适合在移动设备上使用。自AlexNet 问世以来,主要根据分类/检测准确性对现代CNN进行了评估。因此,网络架构的发展没有重新评估模型的复杂性和计算效率。另一方面,要在移动平台(例如智能手机,AR / VR设备(HoloLens,Daydream)和无人机)上成功部署CNN,则需要较小的模型尺寸来适应有限的设备内存,以及用户交互的低延迟。这导致了一个新兴的研究领域,该领域专注于以最小的精度损失来减小CNN的模型大小和推理时间。
该领域的方法大致可分为两类。第一类以MobileNet ,SqueezeNet ,ShuffleNet 和DenseNet 为例,代表了利用计算/内存有效操作设计的新型网络体系结构。第二类将CNN的权重或激活从32位浮点调整为低位深度表示。这种方法被如下网络所采用,如三元重量网络(TWN ),二进制神经网络(BNN ),XNOR-NET,是我们调查的重点。尽管有很多种方法,但当前的量化方法在两个方面存在不足,无法准确地平衡延迟。
其次,许多量化方法无法在实际硬件上提供可验证的效率提升。weight-only的方法是主要关注设备上的存储,较少关注计算效率。值得注意的例外是二元,三元和位移网络。这些方法将权重表示为为0或2的幂,这允许通过位移来实现乘法。 然而,尽管移位在传统的硬件中可能是有效的,但它们对现有的硬件的累加指令几乎没有好处,而乘法指令在正确使用(即流水线)后,其成本并不比单独的累加昂贵。此外,只有在操作数较宽的情况下乘法才是昂贵的,并且一旦量化权重和激活量,避免乘法的需求就随着位深度而减小。值得注意的是,这些方法很少提供设备上的测量来验证承诺的耗时改进。更具run-time友好性的一些方法将权重和激活都量化为1位表示,用这些方法,乘法和加法都可以通过有效的bit-shift和bit-count操作来实现,这在自定义GPU内核中得到了展示(BNN)。但是,但是1bit量化会导致性能大幅下降,并且在模型表示上可能过于严格。
在本文中,我们通过改善常见移动硬件上MobileNets的延迟与准确性之间的权衡来解决上述问题。我们的具体贡献是:
• 我们提供了一个量化方案,将权重和激活都量化为8位整数,而仅将几个参数(bais 向量)量化为32位整数。
• 我们提供一个量化的推理框架,在仅允许整数运算的硬件上如Qualcomm Hexagon ,和我们描述一个有效准确的实现在ARM NEON上。
• 我们提供了与量化推论共同设计的量化训练框架,以最大程度地减少对真实模型进行量化带来的准确性损失。
• 我们将我们的框架应用于基于MobileNets的高效分类和检测系统,并在流行的ARM cpu上提供基准测试结果,展示了在最新的MobileNet架构的latency-vsaccuracy tradeoffs 的显著提升,在ImageNet分类任务,和coco的对象检测任务,以及其他任务。
我们的工作从Deep learning with limited numerical precision.中获得灵感,它利用低精度定点算法来加速CNN的训练速度,在Deep Learning
and Unsupervised Feature Learning NIPS Workshop 中,它使用8 位定点算法来加快x86 CPU的推理速度。 我们的量化方案专注于提高推理速度与CPU设备的精度之间的权衡。
2 量化推理
2.1量化方案
在此,我们描述了一种通用的”量化方案“(这里描述的量化方案是TensorFlow Lite[5]中采用的方案,我们将参考其代码的特定部分来说明下面讨论。
我们之前在gemmlowp[18]的文档中描述过这种量化方案。作为本节中开发的一些主题的替代处理,以及作为其自身包含的示例代码),即bit进行数值表示的对应关系(q ,表示“量化值”),数学实数(r , “实际值”)。我们的量化方案是推理中使用纯整数在训练过程中使用纯浮点数,两种实现都保持了高度的对应性。我们首先给出量化方案的严格数学定义,然后分别采用该方案进行整数-算术推理和浮点训练。
我们的量化方案的基本要求是,它允许仅对量化值使用整数算术运算来高效执行所有算子(我们避免使用需要查找表的实现,因为与SIMD硬件上的纯算术相比,它们的执行性能较差)。这等效于要求量化方案是整数q 到实数r 的仿射映射,即形式为:
![]()
常数S 和Z 是量化参数。量化方案对每个激活数组和每个权重数组中的所有值使用一组量化参数。单独的数组使用单独的量化参数。 对于8位量化,q 被量化为8位整数(对于B 位量化,q 被量化为B 位整数)。一些数组(通常为bais 向量)被量化为32位整数。
常数S (”scale“)是任意正实数。它通常在软件中表示为浮点数,如实际值r 。2.2描述了避免在推理工作负载中表示此类浮点数量的方法。
常数Z (”zero-point“)与量化值q 属于同一类型,并且实际上是与真实的”0“值所对应的量化值q。为了满足实际值的要求 r = 0 可以用一个量化值精确表示。因为有效实施神经网络运营商通常需要在边界周围对阵列进行零填充。
我们的讨论到目前为止总结在下面的量化Buffer数据结构(在TensorFlow lite Converter的实际数据结构是头文件中的QuantizationParams 和Array。我们在下一个小节将会讨论,该数据结构仍然包含浮点数量,不会出现在实际的量化的设备上inference代码中)中,具有这样的的一个实例Buffer现有用于在神经网络的每个激活阵列和权重阵列。我们使用C ++语法,因为它允许类型的明确传达:

2.2 只使用矩阵乘法器的整数算法
现在我们转向如何仅使用整数算术进行推理的问题,即如何使用方程式将实数计算转换为量化值计算,以及如何将后者设计为仅包含整数算术,即使S 不是整数。
考虑实数的两个平方N × N 矩阵r 1 和r 2 的乘积,其乘积以r 3 = r 1 r 2表示。我们表示每一个矩阵的元素伪rα(α= 1、2或3)为rα(i, j),其中1<=i,j<=N ,它们量化的量化参数(SαZα)。我们通过qa[i,j]表示量子化的条目(i, j)。则式(1)变为:
![]()
根据矩阵乘法的定义,我们有:
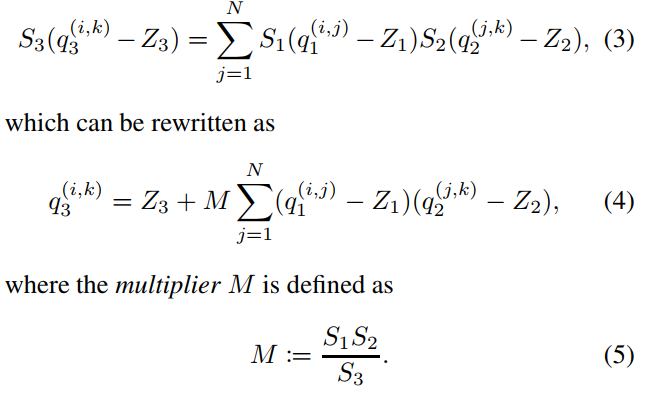
在等式(4),唯一的非整数为M。作为仅取决于量化scale S 1 ,S 2 ,S 3 的常数,可以离线计算。我们凭经验发现它总是在区间(0 ,1) ,因此可以把它标准化成以下形式:
![]()
其中M 0 在区间[0.5,1 )和Ñ 是一个非负整数。现在归一化乘法器M0 现在很适合表示为定点乘法器(例如,int16或int32,具体取决于硬件功能)。
例如,如果使用int32,表示M 0 的整数是最接近2^31*M0 的int32值。由于M 0 > = 0.5 ,这个值总是在>=2^30 ,因此将始终具有至少30bits的相对精度。
因此,与M0相乘可以实现为定点相乘()。同时,可以通过有效的移位实现2^−n 的乘法运算,尽管这需要具有正确的舍入到行为,稍后介绍。
2.3 对ZERO-POINT的有效处理
为了高效地执行方程(4),而不必执行2*N^3次减法,无需将乘法的操作数扩展为16位整数,我们首先注意到,通过在公式(4)中分配乘法,可以将其重写为
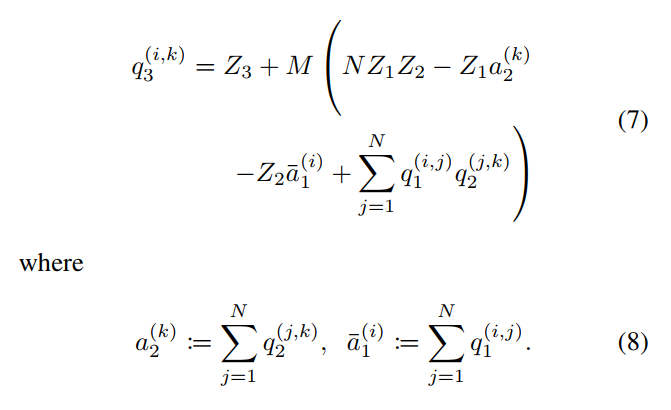
每一个a2(k)或者一个a1(i)只需要N个加法就可以进行计算,所以一共只需要2n^2个加法,公式(7)的其余代价几乎全部集中在核心整数矩阵乘法的累加上

它需要2N^3个算术运算;实际上,(7)中的其他所有项都是O(N^2)在O中有一个小常数。
因此,扩张到形式(7),提出计算a2^k和a1~(i)启用低开销处理任意零点为N的最小值,减少了相同的核心问题整数矩阵乘法积累(9)
我们必须计算在其他任何zero-points-free量化方案
2.3 实现一个典型的融合层
我们继续第2.3节的讨论,但现在明确定义所有涉及的量的数据类型,并修改量化的矩阵乘法(7),将偏置加法和激活函数计算直接合并到其中。将整个层融合到单个操作中不仅是一种优化。由于我们必须在推理代码中再现训练中使用的相同算法,推理代码中融合运算符的粒度(采用8位量化输入并生成8位量化输出)必须与训练图中的“伪量化”运算符的设置匹配
对于我们在ARM和x86 CPU架构上的实现,我们使用gemmlowp库[18],它的
GemmWithOutputPipeline入口点提供了支持我们现在描述的融合操作5(本节的讨论是在TensorFlow Lite[5]中实现的,例如一个卷积运算符(参考代码是自包含的,对gemmlowp[18]的优化代码调用)。)
我们取q1矩阵为权重,q2矩阵为激活值。权重和激活的类型都是uint8(我们可以等效地选择int8,并适当修改零点)。累加uint8值的积需要一个32位的累加器,我们为累加器选择了一个有符号的类型,原因很快就会清楚了。公式(9)的SUM形式如下:
![]()
为了使量化的Bais是在int32累加器中加入一个int32偏置,对偏置向量进行量化处理,其量子化数据类型为int32;采用0作为量化零点Zbias;它的量化标度Sbias与累加器的Sbias相同,是权重的标度与输入激活量的乘积。在第2.3节的符号中
![]()
尽管偏置向量被量化为32位值,但它们只占神经网络参数的一小部分。此外,使用更高的精度偏差向量满足真正的需要:当每个偏置向量项被添加到许多输出激活时,偏置向量中的任何量化错误都倾向于作为一个整体偏差(一个非零均值的误差项) 为了保持良好的端到端神经网络精度,必须避免哪些情况.
对于int32累加器的最终值,还有三件事情要做:按比例缩小到8位输出激活所使用的最终规模,向下转换到uint8并应用激活函数来生成最终的8位输出激活
我们关注的是仅仅是clamps的激活函数,如ReLU、ReLU6。数学函数在附录A.1中进行了讨论,我们目前还没有将它们融合到这样的层中。因此,我们的融合激活函数需要做的惟一一件事就是在存储最终的uint8输出激活之前,将uint8值进一步固定到某个子区间[0,255]。在实践中,量子化的训练过程(第3部分)倾向于学会利用整个输出uint8 [0, 255]间隔使激活函数不再做任何事情,其作用被包含在clamping 中
3 使用simulated quantization进行训练
训练量子化网络的一种常见方法是在浮点数中进行训练,然后对产生的权值进行量子化(有时需要进行额外的后量子化训练以进行微调)。我们发现,这种方法对于具有相当大的代表性的大型模型非常有效,但是对于小型模型却会导致显著的精度下降。简单训练后量化的常见失效模式包括:
1)不同输出通道的权值范围差异较大(大于100×)(第2节规定同一层的所有通道都要量化到
未完--