| 这个作业属于哪个课程 | 软件工程 |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 第一次个人项目编程 |
作业Github地址
- GitHub链接
- 可运行main.exe已放在Release上,需包含文件夹dict
作业算法实现
通过查阅资料发现很多办法解决
- simhash+海明距离计算:可以处理大数据量的文本
- 余弦相似度计算:短文本效率较高,但文本超过3000时候,simhash的效率高于其
- 编辑距离计算:耗时长+计算不准确
- jaccard系数计算:耗时较simhash长
分词有jieba,HanLP,jsseg
本项目采用jieba的c++版本,相似使用了simhash+海明距离进行计算。
cppjieba:
其中一开始遇到分词时只能分到一个个词(很明显效果不好);后面在其githun上发现是编码问题,要转化为UTF-8编码。
std::string string_To_UTF8(const std::string& str)
{
int nwLen = ::MultiByteToWideChar(CP_ACP, 0, str.c_str(), -1, NULL, 0);
wchar_t* pwBuf = new wchar_t[nwLen + 1];//一定要加1,不然会出现尾巴
ZeroMemory(pwBuf, nwLen * 2 + 2);
::MultiByteToWideChar(CP_ACP, 0, str.c_str(), str.length(), pwBuf, nwLen);
int nLen = ::WideCharToMultiByte(CP_UTF8, 0, pwBuf, -1, NULL, NULL, NULL, NULL);
char* pBuf = new char[nLen + 1];
ZeroMemory(pBuf, nLen + 1);
::WideCharToMultiByte(CP_UTF8, 0, pwBuf, nwLen, pBuf, nLen, NULL, NULL);
std::string retStr(pBuf);
delete[]pwBuf;
delete[]pBuf;
pwBuf = NULL;
pBuf = NULL;
return retStr;
}
转化编码后可实现正常的分词
Simhash
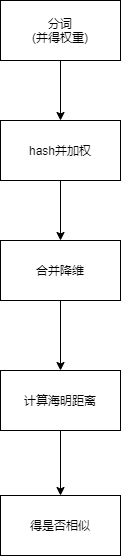
- 分词:使用jieba分词,项目使用了jiaba的TD-IDF来进行关键词提取
- hash:使用c++hash库中hash函数进行计算
- 加权:提取的关键词(前50个),对各自的hash的64位二进制位进行加权
- 合并:把第三步的所有序列进行计算,最后得到一个64位01串
- 降维:每一位进行降维,大于0的输出1,小于0的输出0,最后得到一个64位的二进制
海明距离
最后得到的两个文本的64位二进制进行异或操作,最后输出的01串的1的个数即为海明距离。
海明距离用来判断相似的话比较高效,但是相似度(0~1)的话不太准确。
我用的是某个类似正态分布的函数来海明距离转化为一个0~1之间的数来表示相似度。
[y=frac{1}{sqrt{2*pi*0.16}}e^{(-frac{(0.01x*0.1)^2}{2*(0.0459)^2})}
]
结果输出

接口与模块实现
我只用了一个类来实现,其中这个类包含了jieba类。
整体流程在SimHasher::isSimilarity上
void Simhasher::isSimilarity(uint32_t topk, unsigned int n)
{
std::vector<uint64_t> nums;
for (auto& p : mFiles)
{
std::vector<std::pair<uint64_t, int>> fw;
fw = Participle(p.second, topk);
nums.push_back(CalculaterSimhash(fw));
}
//两两比较(当然现在只有两个文件)
for (size_t i = 0; i < nums.size() - 1; ++i)
{
for (size_t j = i + 1; j < nums.size(); ++j)
{
std::pair<bool, double> flag = CalcularSimilarity(nums[i], nums[j], n);
if (flag.first)
{
std::string str = "文件1:" + mFiles[i].first + " 与 文件二:" + mFiles[j].first + " 相似,相似度:";
char logStr[100]{};
sprintf_s(logStr, "%.2f", flag.second);
str += logStr;
std::cout << str << std::endl;
mLog << str << std::endl;
}
else
{
std::string str = "文件1:" + mFiles[i].first + " 与 文件二:" + mFiles[j].first + " 不相似,相似度:";
char logStr[100]{};
sprintf_s(logStr, "%0.2f", flag.second);
str += logStr;
std::cout << str << std::endl;
mLog << str << std::endl;
}
}
}
}
流程图:
性能改进
下面是所有分词进行计算词频的性能,发现有部分性能消耗在这。
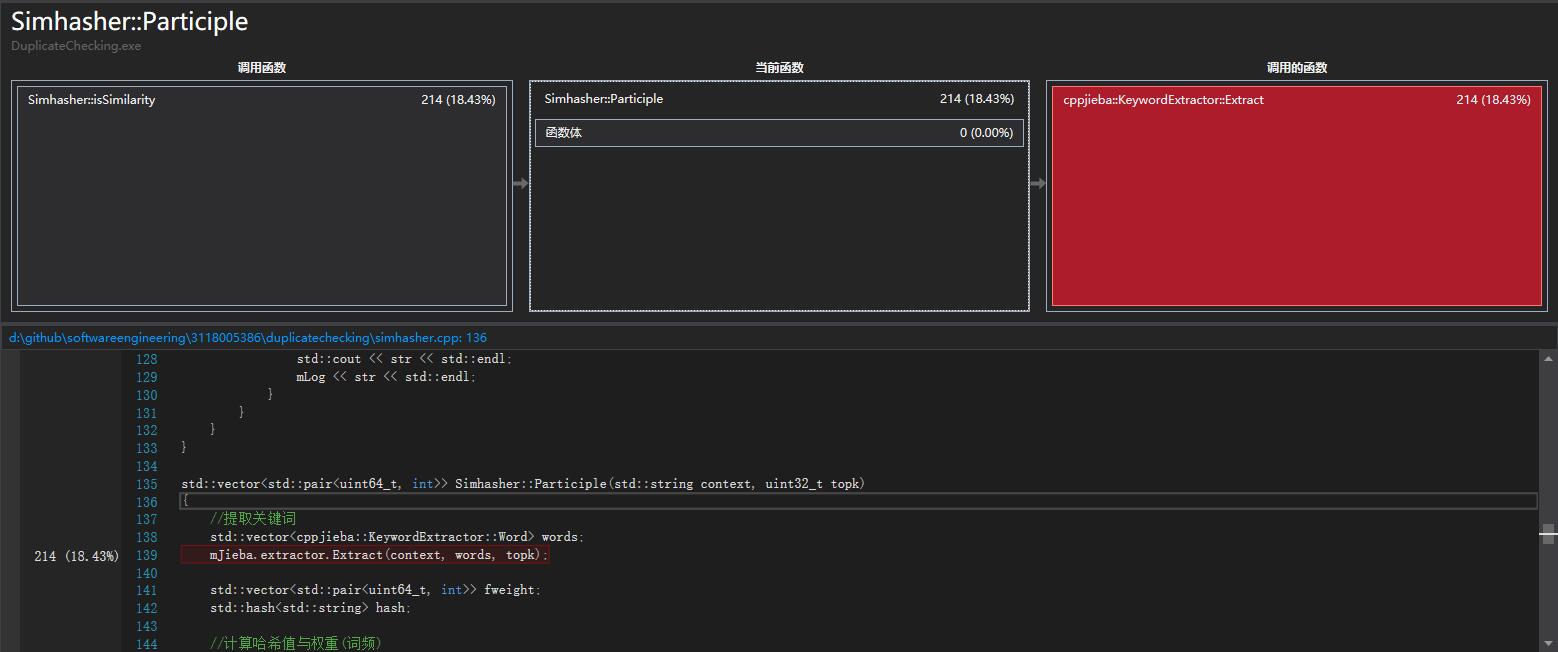
后序发现可以用TD-IDF来得到关键词与其权重,后序实现性能主要在其库上。
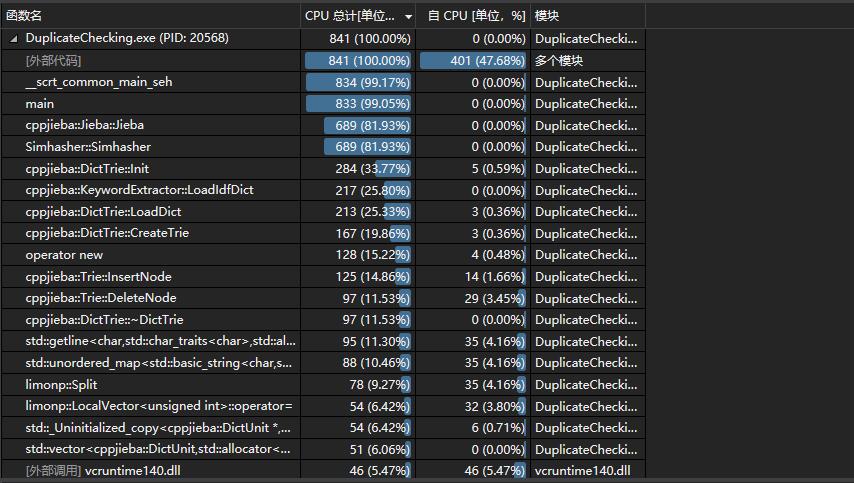
单元测试
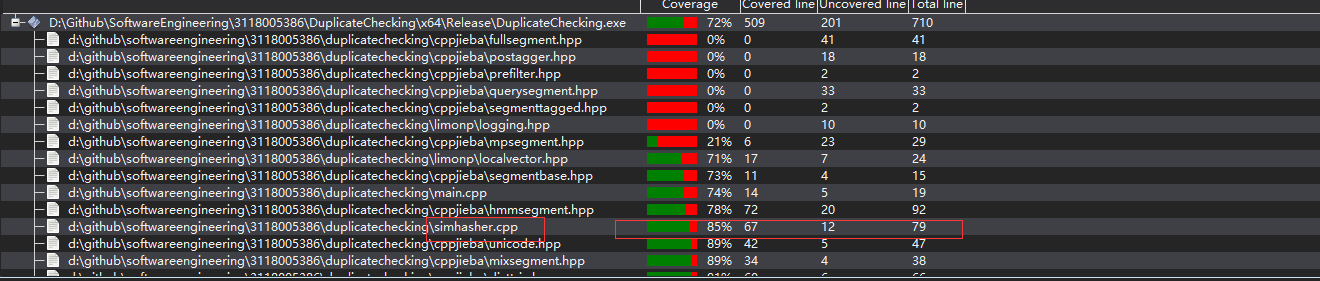
下面图展示了两个单元测试的代码以及测试的结果。
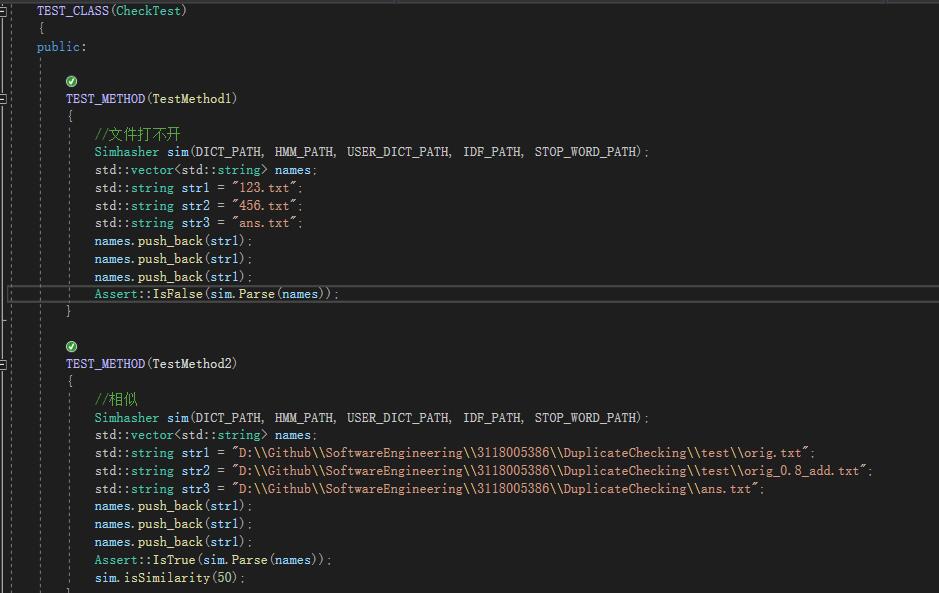

VS上代码覆盖率需要企业版/专业版,我做的时间比较匆忙,暂时只能贴上一个结果是文本相似的代码覆盖率的截图。
可以看到基本覆盖到,有些情况我在单元测试时考虑了,如:文件打不开(不存在),文本不相似。
异常处理
-
参数输入错误
输入的文本的数,过少直接退出
if (argc < 4) { std::cout << "输入参数过少 "; return 0; } -
文件打不开,也是直接显示并退出
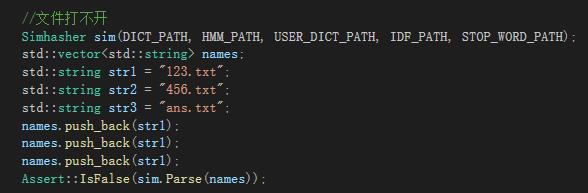
文件不存在以及打不开话,会直接退出,这个单元测试对应了这种场景。
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 480 | 500 |
| · Estimate | · 估计这个任务需要多少时间 | 480 | 500 |
| Development | 开发 | 430 | 500 |
| · Analysis | · 需求分析 (包括学习新技术) | 60 | 60 |
| · Design Spec | · 生成设计文档 | 20 | 15 |
| · Design Review | · 设计复审 | 20 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| · Design | · 具体设计 | 60 | 120 |
| · Coding | · 具体编码 | 180 | 200 |
| · Code Review | · 代码复审 | 20 | 20 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 50 | 50 |
| · Test Repor | · 测试报告 | 10 | 10 |
| · Size Measurement | · 计算工作量 | 10 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 30 | 30 |
| · 合计 | 480 | 500 |
总结
- 时间来说,果然还是比预期慢,对于算法基础这部分还是得进行学习,以及对于c++部分学习仍然有不足之处。
- 在做项目当中,遇到了各种奇怪的问题,其中不乏花费了一定的时间来解决,遇到问题应该分析好问题再去解决可能会更高效。
- 单元测试,仍有不太了解的地方,应该要继续学习。
- 在项目实践过程中,也学习到了很多东西,如git,性能分析等,这些也是一种很好的积累。
作者:Ligo丶
出处:https://www.cnblogs.com/Ligo-Z/
本文版权归作者和博客园共有,欢迎转载,但必须给出原文链接,并保留此段声明,否则保留追究法律责任的权利。