一、requests库的get()函数访问Google主页20次,打印返回状态,text()内容,计算text()属性和content属性所返回网页内容的长度。
在使用requests库向网页发送请求时,会出现几种情况,其中以返回的响应状态码为标志,常见的状态码如下:
- 200 -> 请求访问成功
- 404 -> 请求访问的网页不存在
- 301 -> 资源(网页等)被永久转移到其它URL
- 500 -> 服务器内部错误
下面就是访问Google主页的代码:
1 import requests 2 3 url = 'http://www.google.cn/' 4 5 #请求头 6 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'} 7 8 def Access(url,headers = headers): 9 try: 10 r = requests.get(url, timeout = 30, headers = headers) 11 r.raise_for_status() 12 status = r.status_code 13 print('响应状态码为:{}------请求访问成功'.format(status)) 14 return r 15 except: 16 print('请求访问失败') 17 for i in range(1,21): 18 print('第{}次'.format(i)) 19 r = Access(url) 20 21 text = r.text 22 content = r.content 23 print('text内容: {}'.format(text)) 24 print('text属性返回的网页内容长度:{}'.format(len(text))) 25 print('contents属性返回的网页内容长度:{}'.format(len(content)))
(1)、访问Google主页20次:

(2)、text内容:
(3)、计算text()属性和content()属性所返回网页内容的长度:

二、完成对简单的html页面的相关计算要求。

<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id=first>我的第一个段落。</p > </body><table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> </tr> </table> </html>
代码如下:
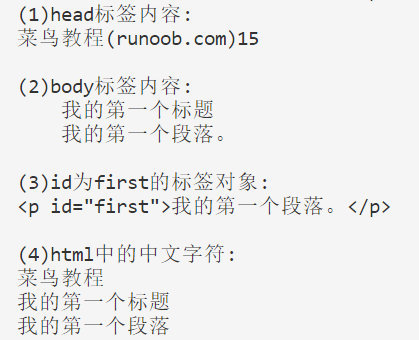
1 import re 2 from bs4 import BeautifulSoup 3 4 #这里是将作业的html代码保存到电脑里,然后用open方法打开这个html文件 5 file = open("myweb.html", 'r',encoding='utf-8') 6 txt = file.read() 7 file.close() 8 9 soup = BeautifulSoup(txt, "html.parser") 10 head = soup.find('head').text.strip(' ') 11 body = soup.find('body').text.strip(' ') 12 first = soup.find(id='first') 13 14 #使用正则匹配来获取html字符串的中文字符,依据汉字的Unicode码表: 从u4e00~u9fa5, 即代表了符合汉字GB18030规范的字符集 15 pattern = re.compile(r'[u4e00-u9fa5]+') 16 result = pattern.findall(txt) 17 18 print('''(1)head标签内容: {0}15 19 20 (2)body标签内容: {1} 21 22 (3)id为first的标签对象: {2} 23 '''.format(head,body,first)) 24 print('(4)html中的中文字符:') 25 for i in result: 26 print(i)
结果如下:
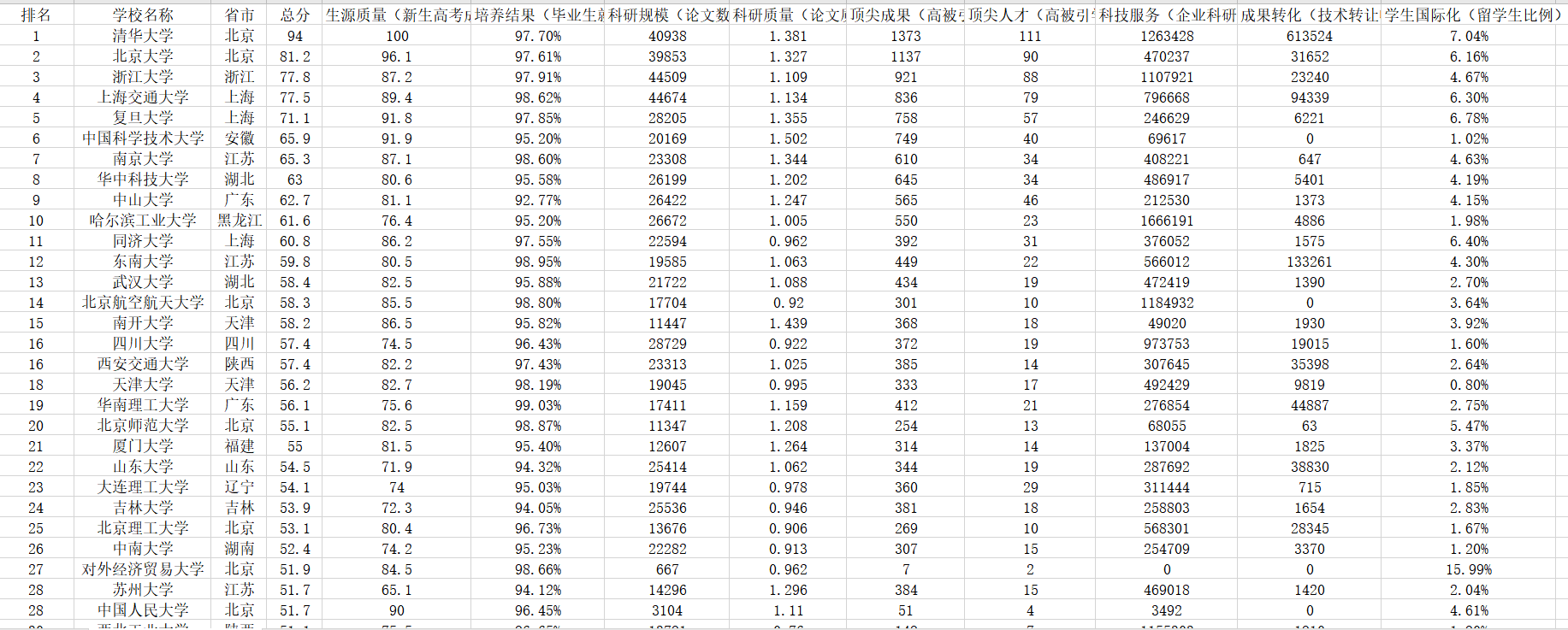
三、爬中国大学排名网站内容,并存为csv。
要求获取这样一个网页的信息:

代码如下:


1 import requests 2 from lxml import etree 3 4 #网站url链接 5 url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2017.html" 6 7 #请求头 8 headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'} 9 10 def Access(url, headers = headers): 11 try: 12 r = requests.get(url, headers = headers) 13 r.raise_for_status() 14 html = etree.HTML(r.content.decode()) 15 return html 16 except: 17 print('请求访问失败') 18 19 #获取每个标题 20 def header_keys(html): 21 theads = [] #储存所有标题 22 thead = html.xpath('/html/body/div[3]/div/div[2]/div/div[3]/div/table/thead')[0] #这里我是直接在浏览器里复制xpath地址,比较方便 23 ths = thead.xpath('//th')[:-1] 24 for th in ths: 25 head = th.text 26 theads.append(head) 27 options = thead.xpath('//th[@class = "hidden-xs"]//option') 28 for option in options: 29 head = option.text.strip(' ') 30 theads.append(head) 31 return theads 32 33 #获取各项指标的数据 34 def data(html): 35 tbodies = [] #储存每所大学数据的列表 36 Onebody = [] #暂时存放单个大学的数据 37 tbody = html.xpath('/html/body/div[3]/div/div[2]/div/div[3]/div/table/tbody')[0] 38 trs = tbody.xpath('./tr') 39 for tr in trs: 40 count = 1 41 tds = tr.xpath('./td') 42 for td in tds: 43 if count == 2: 44 div = td.xpath('./div')[0] 45 Onebody.append(div.text.strip(' ')) 46 else: 47 if td.text is None: #处理None数据,用'无'来代替 48 Onebody.append('无') 49 continue 50 Onebody.append(td.text.strip(' ')) 51 count += 1 52 tbodies.append(tuple(Onebody)) 53 del Onebody[:] 54 return tbodies 55 56 def main(): 57 html = Access(url) 58 csv = [] #csv里的每个元素都是列表, 每个列表储存的是csv文件里面每行的数据 59 theads = header_keys(html) 60 tbodies = data(html) 61 csv.append(theads) 62 for body in tbodies: 63 csv.append(body) 64 #将数据存入csv文件中 65 f = open('2017中国最好大学排名.csv', 'w', encoding='utf-8') 66 for row in csv: 67 f.write(",".join(row) + " ") 68 f.close() 69 70 main()
这里我使用了lxml库,lxml库比bs4库解析网页的速度要快,效率更高,而且寻找标签的时候也比较简单。
部分结果如下: