基础知识详见这篇:banananana:树链剖分原理和实现
请务必看完!这篇主要是对上面的文章进行一点自己的补充强调,及放一点例题。
树剖能够解决的问题:高效进行树链的区间更新/查询(一般搭配线段树使用)
暂时的板子(2020.7.26更新):


//多测时,son和tot记得清空 //在主函数中dfs1(1,0),dfs2(1,1) //如果进行线段树操作,可以直接在id[top[x]],id[x]的去区间上进行 //(区间修改线段树要记得pushup和在tag++后pushdown) int fa[N],dep[N],sz[N],son[N]; inline void dfs1(int x,int f) { sz[x]=1; fa[x]=f; dep[x]=dep[f]+1; for(int i=0;i<v[x].size();i++) { int y=v[x][i]; if(y==f) continue; dfs1(y,x); sz[x]+=sz[y]; if(!son[x] || sz[son[x]]<sz[y]) son[x]=y; } } int tot; int id[N],rnk[N],top[N]; inline void dfs2(int x,int t) { top[x]=t; id[x]=++tot; rnk[tot]=x; if(son[x]) dfs2(son[x],t); for(int i=0;i<v[x].size();i++) { int y=v[x][i]; if(y==fa[x] || y==son[x]) continue; dfs2(y,y); } } inline int lca(int x,int y) { while(top[x]!=top[y]) if(dep[top[x]]>dep[top[y]]) x=fa[top[x]]; else y=fa[top[y]]; return (dep[x]<dep[y]?x:y); }
~ 简单总结与性质强调 ~
根据上面博客的讲解,树链剖分会得到几个很重要的数组
第一次$dfs$得到:$fa[i],dep[i],sz[i],son[i]$,分别表示 父亲节点、深度、子树大小、重节点
第二次$dfs$得到:$id[i],rnk[i],top[i]$,分别表示 节点序号对应的$dfs$序、$dfs$序对应的节点序号、链的顶端(若此节点为重节点,则为重链的顶端;若为轻节点,则为自身)
这里的dfs序大有讲究:由于在第二次dfs保证优先对重节点进行dfs,所以一条重链上所有节点的dfs序相邻(性质1)
同时,树链剖分保证:对于任意一个节点,若想回到根节点,最多只需经过$logN$条链(性质2)
通过这两条性质,如果我们想对树上的一条路径进行某些计算(求最大、求和等等),我们最多只需要枚举$O(logN)$级别的数量的链;而由于链的$dfs$序相邻,我们可以使用数据结构(比如喜闻乐见的线段树)帮助我们高效完成计算
~ 一些题目 ~
最基本的应用是求$LCA$(虽然写题中这个需求并不多)
虽然用倍增比较方便,但是写一写树剖的实现有助于加深理解
比较让人担心的一种情况是,$LCA$恰好在一条重链上,同时$x$、$y$其中有点需要经过这条链
我们有一种办法可以避免“跳过头”,就是比较两个点向上跳一条链后的深度,选择向上跳一条链后较深的那个点进行跳转
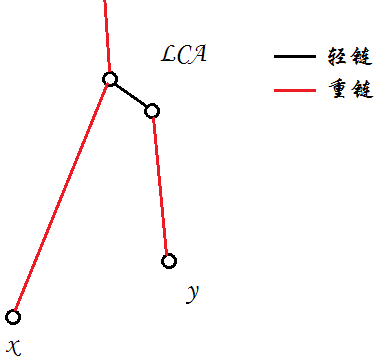
而找到$LCA$的条件是:$x$、$y$位于同一条重链上(即$top[x]==top[y]$),那么$LCA$为深度较低的点
$LCA$模板题:洛谷P3379(【模板】最近公共祖先)
(用$vector$存边就乖乖开$O2$吧)
#include <cstring> #include <cmath> #include <cstdio> #include <vector> using namespace std; const int N=500005; int n,m,root; vector<int> v[N]; int fa[N],dep[N],sz[N],son[N]; inline void dfs1(int x,int f) { sz[x]=1; fa[x]=f; dep[x]=dep[f]+1; for(int i=0;i<v[x].size();i++) { int next=v[x][i]; if(next==f) continue; dfs1(next,x); sz[x]+=sz[next]; if(!son[x] || sz[son[x]]<sz[next]) son[x]=next; } } int cnt; int id[N],rnk[N],top[N]; inline void dfs2(int x,int t) { top[x]=t; id[x]=++cnt; rnk[cnt]=x; if(son[x]) dfs2(son[x],t); for(int i=0;i<v[x].size();i++) { int next=v[x][i]; if(next==fa[x] || next==son[x]) continue; dfs2(next,next); } } inline int lca(int x,int y) { while(top[x]!=top[y]) if(dep[top[x]]>dep[top[y]]) x=fa[top[x]]; else y=fa[top[y]]; return (dep[x]<dep[y]?x:y); } int main() { // freopen("input.txt","r",stdin); scanf("%d%d%d",&n,&m,&root); for(int i=1;i<n;i++) { int x,y; scanf("%d%d",&x,&y); v[x].push_back(y); v[y].push_back(x); } dfs1(root,0); dfs2(root,root); while(m--) { int x,y; scanf("%d%d",&x,&y); printf("%d ",lca(x,y)); } return 0; }
后面的几道题目都是树剖的经典应用,一般都是对于每条重链用线段树进行维护。
一道模板题:洛谷P3384 (【模板】树链剖分)
求和利用的是区间和线段树,修改用懒标记即可
操作$1$、$2$:注意利用两条性质,对于每条链分开处理;单次复杂度$O((logN)^2)$
操作$3$、$4$:多记录一个离开节点$i$的$dfs$序(按理说这个应该更基础点吧);单次复杂度$O(logN)$
#include <cstring> #include <cmath> #include <cstdio> #include <vector> using namespace std; typedef long long ll; const int N=100005; int n,m,root,P,size=1; vector<int> v[N]; int fa[N],dep[N],sz[N],son[N]; inline void dfs1(int x,int f) { sz[x]=1; fa[x]=f; dep[x]=dep[f]+1; for(int i=0;i<v[x].size();i++) { int next=v[x][i]; if(next==f) continue; dfs1(next,x); sz[x]+=sz[next]; if(!son[x] || sz[son[x]]<sz[next]) son[x]=next; } } int cnt; int id[N],rid[N],rnk[N],top[N]; inline void dfs2(int x,int t) { top[x]=t; id[x]=++cnt; rnk[cnt]=x; if(son[x]) dfs2(son[x],t); for(int i=0;i<v[x].size();i++) { int next=v[x][i]; if(next==fa[x] || next==son[x]) continue; dfs2(next,next); } rid[x]=cnt; } int val[N]; int t[N<<2],len[N<<2],tag[N<<2]; inline void Build(int k,int l,int r,int a,int b) { if(a>r) return; if(a==b) { t[k]=val[rnk[a]];//*** len[k]=1; return; } int mid=(a+b)>>1; Build(k<<1,l,r,a,mid); Build(k<<1|1,l,r,mid+1,b); t[k]=(t[k<<1]+t[k<<1|1])%P; len[k]=len[k<<1]+len[k<<1|1]; } inline void Update(int k) { if(!tag[k]) return; tag[k<<1]=(tag[k<<1]+tag[k])%P; t[k<<1]=(t[k<<1]+(ll)len[k<<1]*tag[k])%P; tag[k<<1|1]=(tag[k<<1|1]+tag[k])%P; t[k<<1|1]=(t[k<<1|1]+(ll)len[k<<1|1]*tag[k])%P; tag[k]=0; } inline void Modify(int k,int l,int r,int a,int b,int x) { if(a>r || b<l) return; if(a>=l && b<=r) { tag[k]=(tag[k]+x)%P; t[k]=(t[k]+(ll)len[k]*x)%P; return; } Update(k); int mid=(a+b)>>1; Modify(k<<1,l,r,a,mid,x); Modify(k<<1|1,l,r,mid+1,b,x); t[k]=(t[k<<1]+t[k<<1|1])%P; } inline int Query(int k,int l,int r,int a,int b) { if(a>r || b<l) return 0; if(a>=l && b<=r) return t[k]; Update(k); int mid=(a+b)>>1; return (Query(k<<1,l,r,a,mid)+Query(k<<1|1,l,r,mid+1,b))%P; } int main() { // freopen("input.txt","r",stdin); scanf("%d%d%d%d",&n,&m,&root,&P); for(int i=1;i<=n;i++) scanf("%d",&val[i]); for(int i=1;i<n;i++) { int x,y; scanf("%d%d",&x,&y); v[x].push_back(y); v[y].push_back(x); } dfs1(root,0); dfs2(root,root); while(size<n) size<<=1; Build(1,1,n,1,size); while(m--) { int op,x,y,z,ans=0; scanf("%d",&op); if(op==1) { scanf("%d%d%d",&x,&y,&z); while(top[x]!=top[y]) if(dep[top[x]]>dep[top[y]]) { Modify(1,id[top[x]],id[x],1,size,z); x=fa[top[x]]; } else { Modify(1,id[top[y]],id[y],1,size,z); y=fa[top[y]]; } if(dep[x]>dep[y]) swap(x,y); Modify(1,id[x],id[y],1,size,z); } if(op==2) { scanf("%d%d",&x,&y); while(top[x]!=top[y]) if(dep[top[x]]>dep[top[y]]) { ans=(ans+Query(1,id[top[x]],id[x],1,size))%P; x=fa[top[x]]; } else { ans=(ans+Query(1,id[top[y]],id[y],1,size))%P; y=fa[top[y]]; } if(dep[x]>dep[y]) swap(x,y); ans=(ans+Query(1,id[x],id[y],1,size))%P; printf("%d ",ans); } if(op==3) { scanf("%d%d",&x,&z); Modify(1,id[x],rid[x],1,size,z); } if(op==4) { scanf("%d",&x); printf("%d ",Query(1,id[x],rid[x],1,size)); } } return 0; }
一道不是很裸的题?:洛谷P3401 (洛谷树)
我自己是没憋出思路来...同时恕我真的没有看懂作者给的题解(太简略了吧...)
感谢这位大佬的思路:Running-Coder:题解 P3401 【洛谷树】
首先,过最近公共祖先的路径显然可以通过树剖得到
同时,由于题目给出了“边权小于$1023$”的条件,我们可以推测出将二进制位一个个拆出、分别计算
然后就卡住了...这里是数据结构上的问题,树剖不背锅
大佬的做法是:分别记录一段链上的几个条件
$l,r,m,num,len$
分别表示,从前向后做前缀$xor$一共有多少个$1$、从后向前做后缀$xor$一共有多少个$1$、段内一共有多少个子段$xor$起来是$1$、段内$1$的个数、段长
这样记录有什么用呢?
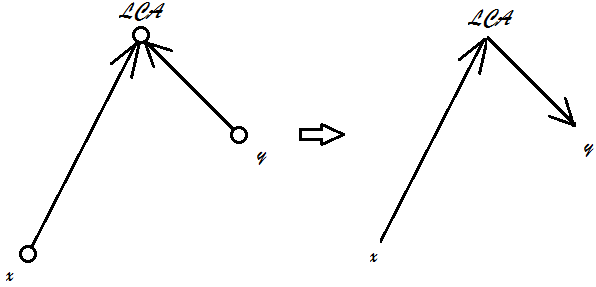
下图给出了一个例子:

当我们将两段合并的时候,我们相当于要求出跨段后,子段$xor$值为$1$的段数
我们可以使用左边段的后缀$xor$和右边段的前缀$xor$
左边段的后缀$xor$再异或上右边段的前缀$xor$,就是我们选出的子段的$xor$值
而要统计子段$xor$值为$1$的段数,可以这样
[左边段后缀中1的个数cdot 右边段前缀中0的个数+左边段后缀中0的个数cdot 右边段前缀中1的个数]
而合并后的整段中,子段$xor$值为$1$的段数有三个来源:全在左边段、全在右边段、跨段
全在单独一段的情况我们能够在之前得到,跨段的情况我们也能够计算,所以我们可以采用线段树合并子段的方法来统计结果
这个问题就被这样转化为了线段树的区间合并问题
由于重链的$dfs$序相邻,所以每次我们取出一条重链的时候,相当于在线段树中区间查询一个子段
但是还有一个细节上的问题:段的方向需要我们人为规定,且段的合并不满足交换律
$x$、$y$到达$LCA$的路径上最多存在$logN$条链,那么我们不妨规定合并的过程中段的开头恒为深度最浅的节点;我们通过一直合并可以得到$x$到$LCA$和$y$到$LCA$的两段,但最终这两段的合并需要将其中一段的前后反转(前缀与后缀交换即可)
#include <cstdio> #include <cstring> #include <cmath> #include <vector> using namespace std; typedef pair<int,int> pii; typedef long long ll; const int N=30005; struct Node { int l,r,m,num,len; Node() { l=r=m=num=len=0; } Node(int a,int b,int c,int d,int e) { l=a,r=b,m=c,num=d,len=e; } }; inline Node Merge(Node left,Node right) { Node res; res.l=left.l+(left.num%2?right.len-right.l:right.l); res.r=right.r+(right.num%2?left.len-left.r:left.r); res.m=left.m+right.m+left.r*(right.len-right.l)+(left.len-left.r)*right.l; res.num=left.num+right.num; res.len=left.len+right.len; return res; } int n,q,R=1; vector<pii> v[N]; struct SegTree { Node t[N<<2]; inline void Modify(int k,int x) { k=k+R-1; t[k]=Node(x,x,x,x,1); k>>=1; while(k) { t[k]=Merge(t[k<<1],t[k<<1|1]); k>>=1; } } inline Node Query(int k,int l,int r,int a,int b) { if(a>r || b<l) return Node(); if(a>=l && b<=r) return t[k]; int mid=(a+b)>>1; return Merge(Query(k<<1,l,r,a,mid),Query(k<<1|1,l,r,mid+1,b)); } }T[10]; int fa[N],dep[N],sz[N],son[N],val[N]; inline void dfs1(int x,int f) { sz[x]=1; fa[x]=f; dep[x]=dep[fa[x]]+1; for(int i=0;i<v[x].size();i++) { int next=v[x][i].first,w=v[x][i].second; if(next==f) continue; val[next]=w; dfs1(next,x); sz[x]+=sz[next]; if(!son[x] || sz[next]>sz[son[x]]) son[x]=next; } } int cnt=0; int id[N],rnk[N],top[N]; inline void dfs2(int x,int t) { top[x]=t; id[x]=++cnt; rnk[cnt]=x; for(int i=0;i<10;i++) T[i].Modify(id[x],(val[x]&(1<<i))?1:0); if(son[x]) dfs2(son[x],t); for(int i=0;i<v[x].size();i++) { int next=v[x][i].first; if(next==fa[x] || next==son[x]) continue; dfs2(next,next); } } inline ll Query(int x,int y) { Node l[10],r[10]; while(top[x]!=top[y]) if(dep[top[x]]>dep[top[y]]) { for(int i=0;i<10;i++) l[i]=Merge(T[i].Query(1,id[top[x]],id[x],1,R),l[i]); x=fa[top[x]]; } else { for(int i=0;i<10;i++) r[i]=Merge(T[i].Query(1,id[top[y]],id[y],1,R),r[i]); y=fa[top[y]]; } for(int i=0;i<10 && dep[x]!=dep[y];i++) if(dep[x]>dep[y]) l[i]=Merge(T[i].Query(1,id[son[y]],id[x],1,R),l[i]); else r[i]=Merge(T[i].Query(1,id[son[x]],id[y],1,R),r[i]); ll ans=0; for(int i=0;i<10;i++) { swap(l[i].l,l[i].r); ans+=(ll)Merge(l[i],r[i]).m*(1<<i); } return ans; } int main() { // freopen("input.txt","r",stdin); scanf("%d%d",&n,&q); while(R<n) R<<=1; for(int i=1;i<n;i++) { int x,y,w; scanf("%d%d%d",&x,&y,&w); v[x].push_back(pii(y,w)); v[y].push_back(pii(x,w)); } dfs1(1,0); dfs2(1,1); while(q--) { int op,x,y,w; scanf("%d%d%d",&op,&x,&y); if(op==1) printf("%lld ",Query(x,y)); else { scanf("%d",&w); if(dep[x]<dep[y]) swap(x,y); for(int i=0;i<10;i++) T[i].Modify(id[x],(w&(1<<i))?1:0); } } return 0; }
其实树链剖分只是一种简化问题的方法,真正关键的是如何利用数据结构维护需要的值
可以解锁$LCT$的技能树啦!(有丶害怕)(2020.7.26 UPD:LCT莫名咕了超久才写,其实根本不难)
计蒜客T38229 $Distance$ $on$ $the$ $tree$(2019南昌邀请赛网络赛)
可以离线树剖线段树
计蒜客T39272 $Tree$(2019陕西省赛)
树剖后拆位线段树卡一下内存能过,不过标解应该是线段树懒标记
(完)