看懂这个算法,首先要了解序列标注任务 QQ522414928 可以在线交流
大体做一个解释,首先需要4个矩阵,当然这些矩阵是取完np.log后的结果,
分别是:初始strat→第一个字符状态的概率矩阵,转移概率矩阵,发射概率矩阵,最后一个字符状态→end结束的概率矩阵,
这些概率矩阵可以是通过统计得到,或者是LSTM+crf这种训练迭代得到。
zero_log 指的是在统计中发射概率没有的情况下用这个很小的值来代替,lstm+crf中应该不会出现不存在的发射概率。
然后看代码
一个矩阵V:里面保存的是每个时间步上的每个状态对应的概率
一个字典path:里面保存的是 {当前标签:他之前所经过的路径}
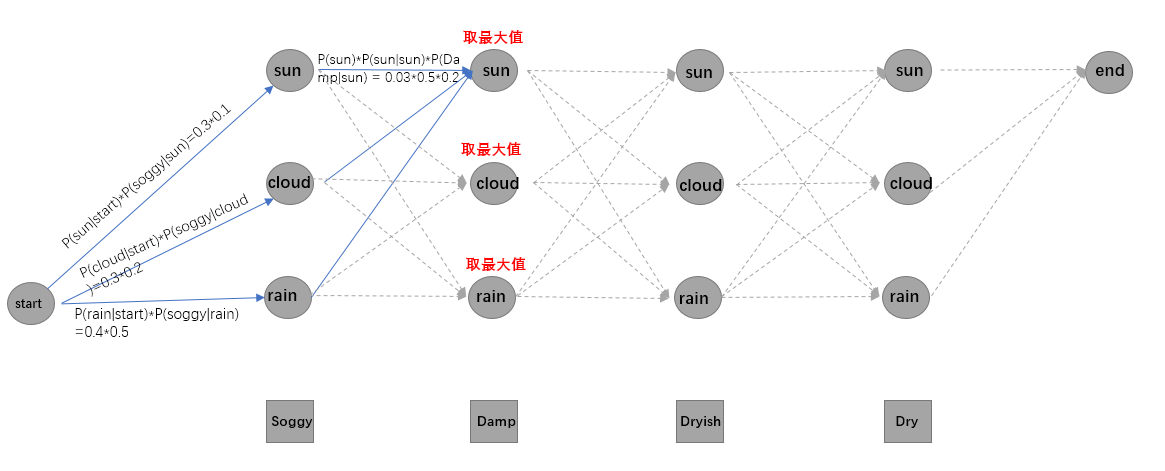
然后最佳路径的计算经过三个部分:初试概率矩阵到第一个字符状态那部分,序列中字符状态转移和发射那部分,最后一个字符状态到end那部分
里边的发射分数和转移分数都使用加法计算是因为 发射矩阵和转移矩阵都经过了log取对数运算
def start_calcute(self,sentence):
'''
通过viterbi算法计算结果
:param sentence: "小明硕士毕业于中国科学院计算所"
:return: "S...E"
'''
zero = -3.14e+100
zero_log = np.log(-3.14e+100)
init_state = self.prob_dict["PiVector_prob"]
trans_prob = self.prob_dict["TransProbMatrix_prob"]
emit_prob = self.prob_dict["EmitProbMartix_prob"]
end_prob = self.prob_dict["EndProbMatrix_prob"]
V = [{}] #其中的字典保存 每个时间步上的每个状态对应的概率
path = {}
#初始概率
for y in self.state_list:
V[0][y] = init_state[y] + emit_prob[y].get(sentence[0],zero_log)
path[y] = [y]
#从第二次到最后一个时间步
for t in range(1,len(sentence)):
V.append({})
newpath = {}
for y in self.state_list: #遍历所有的当前状态
temp_state_prob_list = []
for y0 in self.state_list: #遍历所有的前一次状态
cur_prob = V[t-1][y0]+trans_prob[y0][y]+emit_prob[y].get(sentence[t],zero_log)
temp_state_prob_list.append([cur_prob,y0])
#取最大值,作为当前时间步的概率
prob,state = sorted(temp_state_prob_list,key=lambda x:x[0],reverse=True)[0]
#保存当前时间步,当前状态的概率
V[t][y] = prob
#保存当前的状态到newpath中
newpath[y] = path[state] + [y]
#让path为新建的newpath
path = newpath
#输出的最后一个结果只会是S(表示单个字)或者E(表示结束符)
(prob, state) = max([(V[len(sentence)][y]+end_prob[y], y) for y in ["S","E"]])
return (prob, path[state])