一、 Beautiful Soup是啥
Beautiful Soup是可以从html文件中提取数据的库。
官网链接:https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/index.html#
可以从父子点的html获取回来,利用Beautiful Soup在本地分析
二、Beautiful Soup安装
pip install beautifulsoup4
pip install html5lib
三、一个简单的例子
# -*- coding: utf-8 -*-
html_doc = '''
<!DOCTYPE html>
<html>
<head>
<title>这是个标题</title>
<a href = "http://baidu.com">
</head>
<body>
<h1>这是一个一个简单的HTML</h1>
<a href = "http://sina.com">
<p>Hello World!</p>
</body>
</html>
'''#1. 这是一段html代码,也可以从文件中读取
from bs4 import BeautifulSoup#2.引入
soup = BeautifulSoup(html_doc,"html5lib")#3.选择文件和html5lib
tag = soup.find('a')#4.寻找文件中的a标签
print(tag)#5.打印
结果:

四、find_all
1. 返回的是列表
2. 查找所有结果
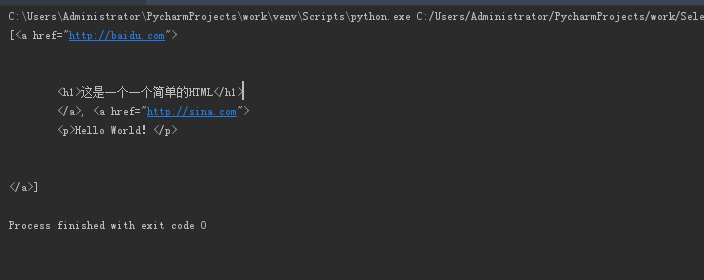
# -*- coding: utf-8 -*- html_doc = ''' <!DOCTYPE html> <html> <head> <title>这是个标题</title> <a href = "http://baidu.com"> </head> <body> <h1>这是一个一个简单的HTML</h1> <a href = "http://sina.com"> <p>Hello World!</p> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html5lib") tag = soup.find_all('a') print(tag)
结果:
五、find_all可以根据属性缩小范围
# -*- coding: utf-8 -*- html_doc = ''' <!DOCTYPE html> <html> <head> <title>这是个标题</title> <a href = "http://baidu.com"> </head> <body> <h1>这是一个一个简单的HTML</h1> <a href = "http://sina.com" id=link1> <p>Hello World!</p> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html5lib") tag = soup.find_all('a',id = 'link1')#这里筛选了id为link1属性的内容 print(tag)

六、按子节点查找
# -*- coding: utf-8 -*- html_doc = ''' <!DOCTYPE html> <html> <head> <div> <title>这是个标题</title> <a href = "http://baidu.com"> </div> </head> <body> <div> <h1>这是一个一个简单的HTML</h1> <a href = "http://sina.com" id=link1> <p>Hello World!</p> </div> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html5lib") tag = soup.div.a#这里就是按照连续的子节点进行查找 print(tag)
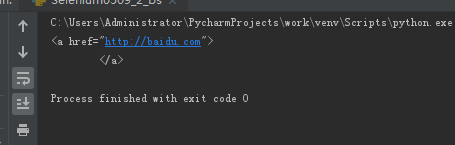
七、按父节点查找
# -*- coding: utf-8 -*- html_doc = ''' <!DOCTYPE html> <html> <head> <div> <title>这是个标题</title> <a href = "http://baidu.com"> </div> </head> <body> <div> <h1>这是一个一个简单的HTML</h1> <p>Hello World!</p> </div> </body> </html> ''' from bs4 import BeautifulSoup soup = BeautifulSoup(html_doc,"html5lib") tag = soup.p.parent#这里就是查找p元素的父节点 print(tag)
