python+selenium+HTMLTestRunner+unittest生成HTML测试报告
首先要准备HTMLTestRunner文件,官网的HTMLTestRunner是python2语法写的,看官手动把官网的HTMLTestRunner.py改成python3的语法:https://pan.baidu.com/s/1dEZQ0pz可下载修改之后的。
修改之后将HTMLTestRunner.py复制到python35的lib目录下
from time import sleep
from selenium import webdriver
import HTMLTestRunner
import unittest
class login(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(5)
self.base_url = "https://www.baidu.com"
self.driver.maximize_window()
def test_login(self):
driver = self.driver
driver.get(self.base_url)
#输入selenium python
driver.find_element_by_xpath("//input[@name='wd']").send_keys("selenium python")
#点击“百度”
driver.find_element_by_xpath("//input[@id='su']").click()
sleep(3)
def tearDown(self):
self.driver.quit()
#测试测试用例是否能正常执行
# if __name__ == "__main__":
# unittest.main()
if __name__ == "__main__":
#定义一个测试容器
test = unittest.TestSuite()
#将测试用例,加入到测试容器中
test.addTest(login("test_login"))
#定义个报告存放的路径,支持相对路径
file_path = "C:\Users\000\Pyresult\sresult.html"
file_result= open(file_path, 'wb')
#定义测试报告
runner = HTMLTestRunner.HTMLTestRunner(stream = file_result, title = u"百度搜索测试报告", description = u"用例执行情况")
#运行测试用例
runner.run(test)
file_result.close()
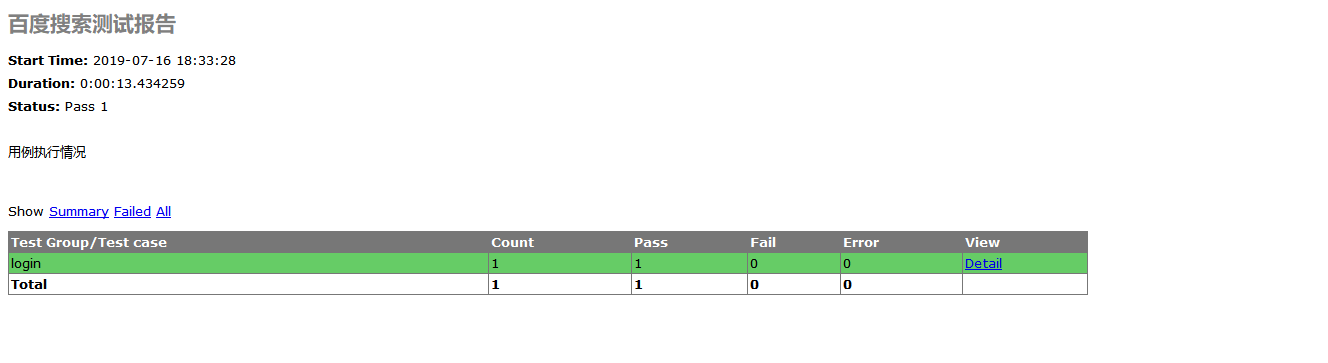
最后的结果显示如下: