写在前面:我们逃避的问题一定会一直积压在心里,并往往在关键时刻,像大难临头一般跳现在面前,搞得人措手不及
剩下的正文:
- 背景
现在,在使用TensorFlow1.4.0封装的InceptionV3模型进行迁移学习解决图像分类的问题,基础版代码可看这里:摘自《TensorFlow实战Google深度学习框架》.
2. 问题:
上述代码将InceptionV3.inceptionV3的参数is_training在训练和测试阶段均设为True,这是错误的,因为is_training布尔值控制着batchnorm是否更新均值mu和sigma,并且还控制着是否使用dropout层。我们知道测试时是不需要更新mu、sigma以及不需要使用dropout的,因此测试和验证时均需要将is_training设为False。
因为验证和测试时is_training=False,导致测试结果很差。这是因为上述代码在训练时没有更新BatchNorm的mu和sigma的原因,我们知道inceptionV3的参数是在ImageNet上训练并保存的,因此在我们自己数据集上微调时,仍需要更新必要的参数,这里必要的参数除了trainable variables还包括BatchNorm/Moving_mean和BatchNorm/Moving_variance。根据TensorFlow的BatchNorm文档https://github.com/tensorflow/docs/blob/r1.4/site/en/api_docs/api_docs/python/tf/contrib/layers/batch_norm.md可知,我们在使用BatchNorm时,应在train_op前加上与tf.GraphKeys.UPDATE_OPS依赖关系:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
仅仅加与moving_mean和moving_variance更新的以来关系还不足以令val_loss收敛的好,如上所述,inceptionV3的ckpt文件是在ImageNet上训练的,因此在我们的小数据集上还需要修改inception_v3_arg_scope()里batch_norm_params['decay']的值,由0.9997改为0.9或者0.99以加快收敛速度,decay的作用可查看滑动平均模型,简言之就是当前的值对滑动平均值的的贡献为(1-0.9)或者(1-0.99)。
3. 微调代码:
因为moving_mean和moving_variance是不可训练参数,当我们保存训练参数时,这两个参数不会被保存,导致在测试时模型找不到这两个变量而报错。以下提供两种方案:
1. 方案1 # 训练时,保存。除了保存trainable variables()也保存moving_vars train_vars = tf.trainable_variables() global_vars = tf.gloal_variables() moving_vars = [var for var in global_vars if "moving" in var.name] var_list = train_vars.extend(moving_vars) saver = tf.train.Saver(var_list=var_list, max_to_keep=1) ... saver.save(sess, save_path, global_step) # 测试时,加载。除了加载trainable variables()也加载moving_vars与上述一致的 train_vars = tf.trainable_variables() global_vars = tf.gloal_variables() moving_vars = [var for var in global_vars if "moving" in var.name] var_list = train_vars.extend(moving_vars) saver = tf.train.Saver(var_list=var_list, max_to_keep=1)#第1种加载方式 ... saver.restore(sess, save_path) load_fn = slim.assign_from_checkpoint_fn(model_path, var_list=var_list, ignore_missing_vars=True) #第2种加载方式 ... load_fn(sess)
2.方案2 #训练时,保存参数。保存所有savable objects saver = tf.train.Saver(max_to_keep=1)#不提供var_list,会使得保存的参数较大 saver.save(sess, save_path, global_step) #测试时,加载参数。 #第一种加载方式 saver = tf.train.Saver() ... saver.restore(sess, save_path) #第二种加载方式
train_vars = tf.trainable_variables()
global_vars = tf.gloal_variables()
moving_vars = [var for var in global_vars if "moving" in var.name]
var_list = train_vars.extend(moving_vars)
load_fn = slim.assign_from_checkpoint_fn(model_path, var_list=var_list, ignore_missing_vars=True)
...
load_fn(sess)
4. 结果
因为使用了验证和测试时BatchNorm/moving_mean和BatchNorm/moving_variance都是使用的训练集的滑动平均模型,因此更新的比较慢,甚至可能出现val_loss为inf的情况,需要等一段时间才能收敛。
下面给出2个不同任务上的loss值曲线,它们之间没有对比关系,可以看出引入BatchNorm后loss收敛的较慢,但是validation loss都很平滑
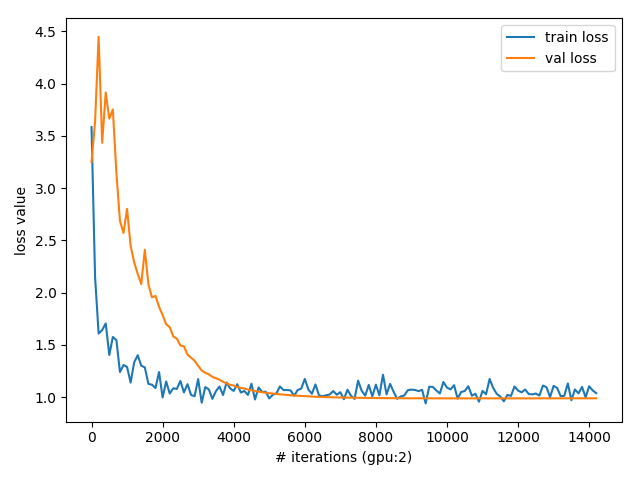

注意:这两个loss之间没有任何关系,仅仅为了展示batchnorm对validation metric的影响
5. 总结:
使用batchnorm的程序中,
1)在train_op之前要加与更新moving_mean和moving_variance的依赖关系,才能保证测试时BatchNorm使用的是正确的train dataset的mu和sigma
2) 如果数据集较小,应该更改inception_v3_arg_scope()里batch_norm_parms['decay']衰减率,更小一些
3)因为mu和sigma是滑动平均累计来的,因此要等一段时间才能在validation dataset上收敛
4)模型持久化时,除了保存trainable variables()还需要保存moving_mean 和 moving_variance才能保证在测试时不会报“参数找不到”的错误