写在前面:院里要求参加研究生的数模竞赛,发现现在开始学 matlab 好像时间来不及了,那就 python 走到底吧hhh
前两章略过。
Chapter3 Built-in Data Structures, Functions, and Files
Tuple
-
A tuple is a fixed-length, immutable sequence of Python objects.
-
If an object inside a tuple is mutable, such as a list, you can modify it in-place.
tup = tuple(['foo', [1,2], True)
# TypeError
tup[2] = False
# Allowed
tup[1].append(1)
List
list.pop(3),表示去掉 index=3 处的元素。list.remove('ss')表示去掉 list 中第一个'ss'元素- Check if a list contains a value using the in keyword.
if 'swagds' in a_list:
...
- Note that list concatenation by addition is a comparatively expensive operation since a new list must be created and the objects copied over.
a = [1,2,3,4]
b = [5,6,7,8]
# NO !
a = a + b
# YES ! (if previous a is not used anymore)
a.extend(b)
bisectmodule implements binary search and insertion into a sorted list.
import bisect
c = [1,2,2,2,3,4,7]
# bisect.bisect 返回插入后仍有序的插入位置
d = bisect.bisect(c, 2) # d = 4
e = bisect.bisect(c, 5) # e = 6
# bisect.insort 插入元素到有序列表的相应位置,使得插入后的序列仍有序
bisect.insort(c, 6)
# c = [1,2,2,2,3,4,6,7]
- Slicing
seq = [7,2,3,7,5,6,0,1]
seq[1:5] # = [2,3,7,5]
seq[3:4] = [6,3] # seq = [7,2,3,6,3,5,6,0,1]
seq[:5] = [7,2,3,6,3]
seq[-4:] = [5,6,0,1] # NOT [1,0,6,5]
seq[::2] # = [7,3,3,6,1] 隔1个选一个
A clever use of this is to pass -1, which has the useful effect of reversing a list or tuple.
seq[::-1] # = [1,0,6,5,3,6,3,2,7]
Built-in Sequence Functions
- enumerate
for i, num in enumerate(seq):
print(i, num)
# Output
# 0 7
# 1 2
# 2 3
# 3 6
# 4 3
# 5 5
# 6 6
# 7 0
# 8 1
- zip
seq1 = ['foo', 'bar', 'baz']
seq2 = ['one', 'two', 'three']
zipped = zip(seq1, seq2)
# print(list(zipped))
# [('foo', 'one'), ('bar', 'two'), ('baz', 'three')]
zip can take an arbitrary number of sequences, and the number of elements it produces is determined by the shortest sequence.
seq3 = [False,True]
# print(list(zip(seq1, seq2, seq3)))
# [('foo', 'one', False), ('bar', 'two', True)]
"unzip"
pitchers = [('Nolan', 'Ryan'), ('Roger', 'Clemens'), ('Alice', 'Smith')]
first_name, last_name = zip(*pitchers)
# print(first_name)
# ('Nolan', 'Roger', 'Alice')
# print(last_name)
# ('Ryan', 'Clemens', 'Smith')
dict
dl = {'a': 'some value', 'b': [1, 2, 3, 4], 7: 'an integer', 5: 'some value', 'dummy': 'another value'}
- del:
del dl[5] - pop:
ret = dl.pop('dummy')
# print(ret)
# 'another value'
-
update: merge one dict into another using the update method
d1.update({'b' : 'foo', 'c' : 12}) -
遍历字典:
for key, value in zip(dl.keys(), dl.values()): -
get: 一种简单写法
value = dl.get(key, d_value),意思是如果 dl 中有 key 这个键,那么 value = dl[key],否则 value = d_value。 -
setdefault: 一种简单写法,一般用来整理 list 中具有某种相同属性的元素为一个dict。
by_letter = {}
for word in words:
letter = word[0]
by_letter.setdefault(letter, []).append(word)
意思是如果存在 letter 键,那么返回相应的列表,否则返回空列表,而且空列表进行 append 之后的列表会写到 by_letter 中。
- defaultdict: 另一种实现 setdefault 类似的方法。
from collections import defaultdict
by_letter = defaultdict(list)
for word in words:
by_letter[word[0]].append(word)
一般的 dict 当 key 不存在时会抛出 KeyError 异常,而 defaultdict 会返回一个其他的值,这个值与参数有关,参数是一个 factory_function,也叫工厂函数,当 key 不存在时会返回 factory_function 的默认值,例如 list 对应一个空列表,int 对应整数0等。
- Valid dict key types: scalar types or tuple,must be hashable and immutable.
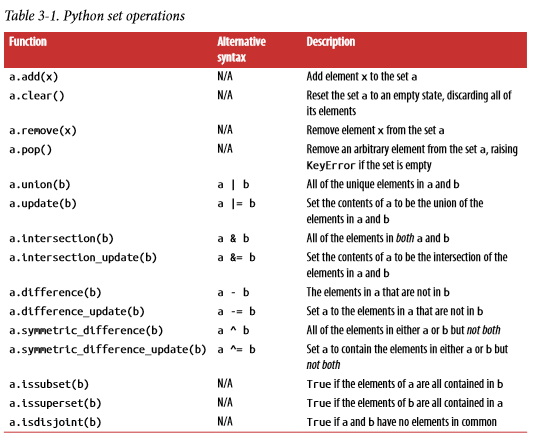
set
A set is an unordered collection of unique elements. You can think of them like dicts, but keys only, no values.
基本操作如下图:
List, Set and Dict Comprehensions
- list comprehension:
[expr for val in collection if condition] - dict comprehension:
{key-expr : value-expr for value in collection if condition} - set comprehension:
{expr for value in collection if condition} - map: 内置函数,用法,返回一个输入序列每个元素经过函数处理后的返回值列表。
- Nested list comprehension: list comprehension 中可以使用多个 for loop。
Functions
- Lambda Functions: a simple function.
strings = ["foo", "card", "bar", "aaaa", "abab"]
string.sort(key=lambda x: len(set(list(x))))
# string = ['aaaa', 'foo', 'abab', 'bar', 'card']
- partial: 主要的作用是固定函数中的某些参数值。
def add_nums(x, y):
return x+y
add_five = lambda y: add_nums(5, y)
from functools import partial
add_five = partial(add_nums, y=5)
- generator:
A generator is a concise way to construct a new iterable object. Whereas normal functions execute and return a single result at a time, generators return a sequence of multiple results lazily, pausing after each one until the next one is requested. use yield instead of return.
有点类似于之前提到的内置函数 map,但是两者还是有很大不同,包括 generator 中的值只能用一次,不能重复使用等。
def squares(n=10):
print('Generating squares from 1 to {0}'.format(n**2))
for i in range(1, n+1):
yield i ** 2
gen = squares()
for num in gen:
print(x, end=" ")
Another way to make a generator:
gen = (x ** 2 for x in range(1, 10))
这个写法 ( generator expressions ) 就是用小括号把 list comprehension 括起来,得到的gen上面的是一样的。
Generator expressions can be used instead of list comprehensions as function arguments in many cases.
Itertools提供了操作可迭代对象的一些方法,有些对于 generators 也十分有用。

重点介绍了 groupby ,它的参数是可迭代对象和一个可选的函数,会返回一个对参数中函数返回值连续相同的 generator ( 书上是这么说的,但是经过试验发现并不是一个 generator,而是一个 itertools._grouper,存疑 ):
import itertools
first_letter = lambda x : x[0]
names = ['Alan', 'Adam', 'Wes', 'Will', 'Albert', 'Steven']
for letter, name in itertools.groupby(names, first_letter):
print(type(name))
print(letter, list(name))
输出结果:
<itertools._grouper object at 0x0000019A9F42C278>
A ['Alan', 'Adam']
<itertools._grouper object at 0x0000019A9F42C320>
W ['Wes', 'Will']
<itertools._grouper object at 0x0000019A9F42C278>
A ['Albert']
<itertools._grouper object at 0x0000019A9F42C320>
S ['Steven']
- Errors and Exception Handleing
比较基础的异常处理,简要介绍了 try, catch, finally 关键字的应用,这里就不赘述了。
Files and Operating System
介绍了一些 IO 的基本操作。
- python file mode

需要注意的是"w"和"x"的区别,除非十分自信,不然尽量使用"x"。
- 及时close
When you use open to create file objects, it is important to explicitly close the file when you are finished with it. Closing the file releases its resources back to the operating system.
一个好习惯是使用with,因为:
This will automatically close the file f when exiting the with block.
with open(path, "r") as f:
lines = [x.rstrip() for x in f]
- 对于 readable 文件的一些常用函数
read(int): 返回 int 个字符(与编码格式相关)
tell(): 返回当前文件指针的位置
seek(int): 改变文件指针位置到 int 处
write(str): 向文件指针写入 str
writelines(strings): 每行写入一个 string
- Bytes and Unicode with Files
可以在 open 中指定编码方式。with open(path, "rb", encoding='utf-8') as f:
处理 uft8 的时候需要注意utf8编码可以使用多个字符表示一个字,比如“对”这个汉字就是'xe5xafxb9',所以如果使用的是二进制形式,那么很可能 read 之后得到的字符并不是完整的字符,举个例子:
# test.txt 对别无二是放醋我TV业务TV我热播wevubjhdvbyuewbdyuqwgudybchbdlvjywbeucygecbu
with open('test.txt', 'rb') as f:
data = f.read(3)
print(data)
print(data.decode("utf8"))
这时的输出是:
b'xe5xafxb9'
对
但是如果把 read 的参数 3 改成 2 就会出现 UnicodeDecodeError:
b'xe5xaf'
Traceback (most recent call last):
File ".mytestmytest.py", line 5, in <module>
print(data.decode("utf8"))
UnicodeDecodeError: 'utf-8' codec can't decode bytes in position 0-1: unexpected end of data
对于 seek 也是一样,utf8 不支持在一个字符的中间 read:
with open('test.txt', 'r', encoding="utf8") as f:
f.seek(2)
data = f.read(3)
会报错:invalid start byte
Traceback (most recent call last):
File ".mytestmytest.py", line 3, in <module>
data = f.read(3)
File "F:applicationSoftwareAnaconda3libcodecs.py", line 321, in decode
(result, consumed) = self._buffer_decode(data, self.errors, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte
Conclusion
本章主要介绍了 python 的内置数据结构和一些基础的函数操作。