1. C++和C的区别
1)在设计思想上:
C++是面向对象的语言,而C是面向过程的结构化编程语言;
2)在内容方面:
C++是C的超集,即C是C++的子集,C++兼容C;
C++引入类、封装、隐藏、继承、多态等特性;引入STL标准模板库等;
C++提供**引用&**机制,降低使用指针的复杂度;
C++提供内联函数inline;
3)在语法方面:
C++中new和delete是对内存分配的运算符,取代了c的malloc和free;
C++中用控制标准输入输出的iostream类库代替了标准C中的stdio函数库;
C++中的try/catch/throw异常处理机制取代了C中的setjmp()和longjmp();
强制类型转换,C++提供两种两种格式,而C只有第一种;
float el = 123.233;
int i = (int) el; //第一种
int j = int (el);//第二种
C++允许设置函数默认参数,而C不允许;
C++允许对函数进行重载(两个同名函数,若它们参数类型不一致or参数个数不同,则为两个不同的函数),而C不允许;
C++允许在程序任何地方定义变量,而C只允许在函数开头部分定义;
详解可参考文章:C++和C的区别
2、static的作用
1、全局静态变量
存放于静态存储区;
在整个程序运行期间都存在;
未被初始化时自动初始化为0;
作用域:从定义之处开始到文件结尾;
2、局部静态变量
仅作用域与全局静态变量不同:局部静态变量在定义它的函数or语句块结束时,作用域便结束,此时不可访问,当再次调用函数时,即可访问且值不变;
3、静态函数
函数默认extern,即可以被其他文件可用;
而静态函数只能在声明它的文件中可见,不能被其他文件所引用;
4、类的静态成员变量
类的静态成员可实现多个对象之间的数据共享,只存储于溢出,共该类的所有对象共用;
5、类的静态成员函数
调用静态成员函数不需要用对象名(但可以用),且静态成员函数中不能直接引用类中的非静态成员,因为它不知道这个成员为那个对象所有;
调用静态成员函数使用如下格式:<类名>::<静态成员函数名>(<参数表>);
3、C++中的四种cast转换
C++中四种类型转换是:static_cast, dynamic_cast, const_cast, reinterpret_cast;
1、const_cast
用于将const变量转为非const;
2、static_cast
用于各种隐式转换,比如非const转const,void*转指针等, static_cast能用于多态向上转化,如果向下转能成功但是不安全,结果未知;
3、dynamic_cast
用于动态类型转换。只能用于含有虚函数的类,用于类层次间的向上和向下转化。只能转指针或引用。向下转化时,如果是非法的对于指针返回NULL,对于引用抛异常。
向上转换:指的是子类向基类的转换;
向下转换:指的是基类向子类的转换;
它通过判断在执行到该语句的时候变量的运行时类型和要转换的类型是否相同来判断是否能够进行向下转换;
4、reinterpret_cast
几乎什么都可以转,比如将int转指针,可能会出问题,尽量少用;
4、C++/C中指针和引用的区别
1、指针有自己的一块空间,而引用只是别名;
short a=1;
short *p=&a;
short &b=a;
cout<<sizeof(p);//输出4
cout<<sizeof(b);//输出2
2、指针可被初始化为NULL,而引用必须被初始化且必须是一个已有对象的引用;
3、可以有const指针,但是没有const引用;
4、指针可以在使用中指向其他对象,而引用一旦初始化,便不能再指向别的对象;
5、指针可以有多级(**p),而引用只有一级;
6、指针和引用使用++运算符的意义不同;如若变量i是int类型,p指向i,b是i的引用;那么++p表示p的值等于 i 的地址加四个地址单位后的地址;而++b的值是i+1;
7、如果返回动态内存分配的对象或者内存,必须使用指针,引用可能引起内存泄露;
5、什么是野指针
野指针就是指向一个已删除的对象或者未申请访问受限内存区域的指针;
6、为什么对于会被继承的类,其析构函数必须是虚函数?
将可能会被继承的父类的析构函数设置为虚函数,可以保证当我们new一个子类,然后使用基类指针指向该子类对象,释放该子类对象的空间时,可以释放掉子类的空间,防止内存泄漏。
C++默认的析构函数不是虚函数是因为虚函数需要额外的虚函数表和虚表指针,占用额外的内存。而对于不会被继承的类来说,其析构函数如果是虚函数,就会浪费内存。因此C++默认的析构函数不是虚函数,而是只有当需要当作父类时,设置为虚函数。
详解可参考:继承-虚析构函数
7、函数指针
1、定义
函数指针是指向函数的指针变量;
函数指针本身首先是一个指针变量,该指针变量指向一个具体的函数。这正如用指针变量可指向整型变量、字符型、数组一样,这里是指向函数;
C在编译时,每一个函数都有一个入口地址,该入口地址就是函数指针所指向的地址;有了指向函数的指针变量后,可用该指针变量调用函数,就如同用指针变量可引用其他类型变量一样,在这些概念上是大体一致的;
2、用途:
调用函数和做函数的参数,比如回调函数。
3、示例:
int fun(char c) //函数fun
{
return c;
}
int main()
{
int (*pf)(char c); //定义函数指针pf
pf=fun; //将函数指针pf指向函数fun
cout<<pf('a'); //输出97
}
8、C++中析构函数的作用
析构函数与构造函数对应,当对象结束其生命周期,如对象所在的函数已调用完毕时,系统会自动执行析构函数。
析构函数名也应与类名相同,只是在函数名前面加一个位取反符,例如stud( ),以区别于构造函数。它不能带任何参数,也没有返回值(包括void类型)。只能有一个析构函数,不能重载;
如果用户没有编写析构函数,编译系统会自动生成一个缺省的析构函数(即使自定义了析构函数,编译器也总是会为我们合成一个析构函数,并且如果自定义了析构函数,编译器在执行时会先调用自定义的析构函数再调用合成的析构函数),它也不进行任何操作。所以许多简单的类中没有用显式的析构函数;
如果一个类中有指针,且在使用的过程中动态的申请了内存,那么最好显示构造析构函数在销毁类之前,释放掉申请的内存空间,避免内存泄漏;
类析构顺序:1)派生类本身的析构函数;2)对象成员析构函数;3)基类析构函数。
9、静态函数和虚函数的区别
静态函数在编译的时候就已经确定运行时机,虚函数在运行的时候动态绑定。虚函数因为用了虚函数表机制,调用的时候会增加一次内存开销;
10、重载和覆盖
重载:两个函数名相同,但是参数列表不同(个数,类型),返回值类型没有要求,在同一作用域中;
重写/覆盖:子类继承了父类,父类中的函数是虚函数,在子类中重新定义了这个虚函数,这种情况是重写;
11、对虚函数和多态的理解
多态的实现主要分为静态多态和动态多态,静态多态主要是重载,在编译的时候就已经确定;动态多态是用虚函数机制实现的,在运行期间动态绑定。举个例子:一个父类类型的指针指向一个子类对象时候,使用父类的指针去调用子类中重写了的父类中的虚函数的时候,会调用子类重写过后的函数,在父类中声明为加了virtual关键字的函数,在子类中重写时候不需要加virtual也是虚函数。
虚函数的实现:在有虚函数的类中,类的最开始部分是一个虚函数表的指针,这个指针指向一个虚函数表,表中放了虚函数的地址,实际的虚函数在代码段(.text)中。当子类继承了父类的时候也会继承其虚函数表,当子类重写父类中虚函数时候,会将其继承到的虚函数表中的地址替换为重新写的函数地址。使用了虚函数,会增加访问内存开销,降低效率。
12、写个函数在main函数执行前先运行
C++ 的全局对象的构造函数会在 main 函数之前先运行;
其实在 c 语言里面很早就有了,在 gcc 中可以使用attribute关键字指定如下(在编译器编译的时候就绝决定了)
详解可参考文章:如何再main()执行之前先运行其他函数
13、const char *arr=“123”; char *brr=“123”;char crr[]=“123”;的区别
首先, “123”永远都是保存在常量区,要么指针指向常量区"123",要么数组复制“123”到栈区;
1)const char *arr=“123”;
"123"保存在常量区,const本来是修饰arr指向的值不能通过arr去修改,但是字符串“123”在常量区,本来就不能改变,所以加不加const效果都一样;
2) char *brr=“123”;
"123"保存在常量区,brr和arr指向的是同一个位置,同样不能通过brr去修改"123"的值
3)char crr[] = “123”;
这里“123"相当于一个字符数组,"123"从常量区复制到栈区,可以通过crr去修改;
14、C语言是怎么进行函数调用的?
每一个函数调用都会分配函数栈,在栈内进行函数执行过程;
调用前,先把返回地址压栈,然后把当前函数的ebp指针压栈。然后ebp改为当前esp值,此时ebp=esp,表示初始的子函数帧栈大小为0,然后移动帧指针(修改ebp寄存器)与栈指针(修改esp寄存器),为swap函数创建一个栈帧结构;
详解可参考:C语言函数调用过程
15、说一声fork,wait,exec函数
父进程产生子进程使用fork拷贝出来一个父进程的副本,此时只拷贝了父进程的页表,两个进程都读同一块内存,当有进程写的时候使用写时拷贝机制(可参考:操作系统面试题汇总中的fork()与vfork())分配内存,exec函数可以加载一个elf文件去替换父进程,从此父进程和子进程就可以运行不同的程序了。fork()给父进程返回子进程的PID,给子进程返回0;
调用了wait的父进程将会发生阻塞,直到有子进程状态改变,执行成功返回0,错误返回-1;
exec()执行成功则子进程从新的程序开始运行,无返回值,执行失败返回-1;
16、说一下C++中类成员的访问权限
C++通过 public、protected、private 三个关键字来控制成员变量和成员函数的访问权限,它们分别表示公有的、受保护的、私有的,被称为成员访问限定符;
在类的内部(定义类的代码内部),无论成员被声明为 public、protected 还是 private,都是可以互相访问的,没有访问权限的限制;
在类的外部(定义类的代码之外),只能通过对象访问成员,并且通过对象只能访问 public 属性的成员,不能访问 private、protected 属性的成员;
17、C++源文件从文本到可执行文件经历的过程
对于C++源文件,从文本到可执行文件一般需要四个过程:
1、预处理阶段:对源代码文件中文件包含关系(头文件)、预编译语句(宏定义)进行分析和替换,生成预编译文件;
2、编译阶段:将经过预处理后的预编译文件转换成特定汇编代码,生成汇编文件;
3、汇编阶段:将编译阶段生成的汇编文件转化成机器码,生成可重定位目标文件;
4、链接阶段:将多个目标文件及所需要的库连接成最终的可执行目标文件;
18、include头文件的顺序以及双引号””和尖括号<>的区别
双引号和尖括号的区别:编译器预处理阶段查找头文件的路径不一样;
对于使用双引号包含的头文件,查找头文件路径先从当前头文件目录开始,若没找到再从编译器设置的头文件路径开始查找;
而使用尖括号包含头文件,查找头文件路径直接从编译器设置的开始
19、malloc的原理
Malloc函数用于动态分配内存。为了减少内存碎片和系统调用的开销,malloc其采用内存池的方式,先申请大块内存作为堆区,然后将堆区分为多个内存块,以块作为内存管理的基本单位;当用户申请内存时,直接从堆区分配一块合适的空闲块;
Malloc采用隐式链表结构将堆区分成连续的、大小不一的块,包含已分配块和未分配块;同时malloc采用显示链表结构来管理所有的空闲块,即使用一个双向链表将空闲块连接起来,每一个空闲块记录了一个连续的、未分配的地址;
当进行内存分配时,Malloc会通过隐式链表遍历所有的空闲块,选择满足要求的块进行分配;当进行内存合并时,malloc采用边界标记法,根据每个块的前后块是否已经分配来决定是否进行块合并;
Malloc在申请内存时,一般会通过brk或者mmap系统调用进行申请;其中当申请内存小于128K时,会使用系统函数brk在堆区中分配;而当申请内存大于128K时,会使用系统函数mmap ( mmap将一个文件或者其它对象映射进内存 ) 在映射区分配;
20、C++的内存管理是怎样的
在C++中,虚拟内存分为代码段、数据段、BSS段、堆区、文件映射区以及栈区六部分。
1、代码段:包括只读存储区和文本区,其中只读存储区存储字符串常量,文本区存储程序的机器代码;
2、数据段:存储程序中已初始化的全局变量和静态变量;
3、BSS 段:存储未初始化的全局变量和静态变量(局部+全局),以及所有被初始化为0的全局变量和静态变量;
4、堆区:调用new/malloc函数时在堆区动态分配内存,同时需要调用delete/free来手动释放申请的内存;
5、映射区:存储动态链接库以及调用mmap函数进行的文件映射;
6、栈:使用栈空间存储函数的返回地址、参数、局部变量、返回值;
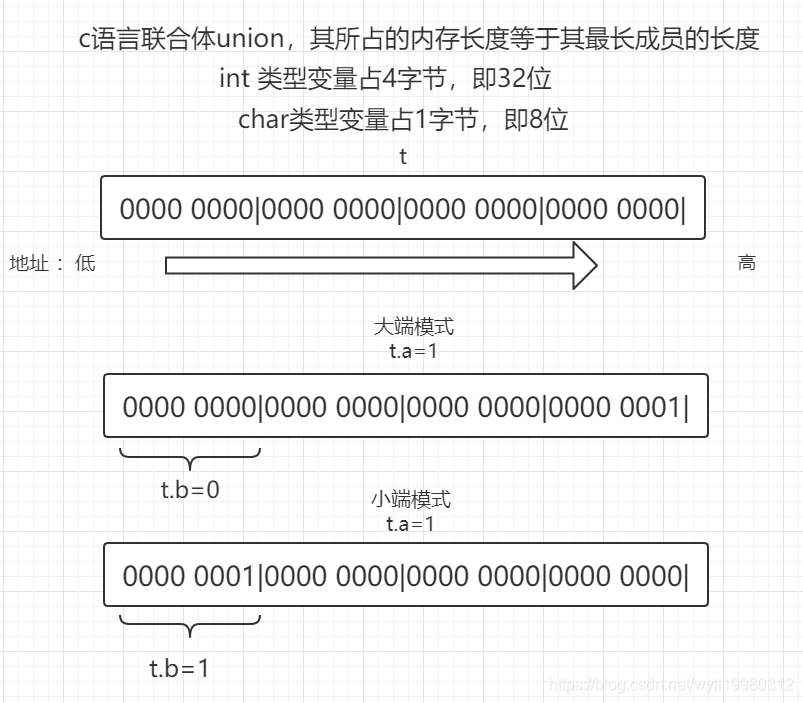
21、什么是大端小端以及如何判断大端小端
大端是指低字节存储在高地址;
小端是指低字节存储在低地址;
可以根据联合体来判断该系统是大端还是小端。因为联合体变量总是从低地址存储;
int fun1(void)
{
union test
{
int a;
char b;
}t;
t.a = 1;
return (t.b==1);
}
如果是大端 t.b=0;如果是小端 则t.b=1;