第1章 RDD概述
1.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。
代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。(简单说就是一个抽象类)
1.1.1 RDD类比工厂生产
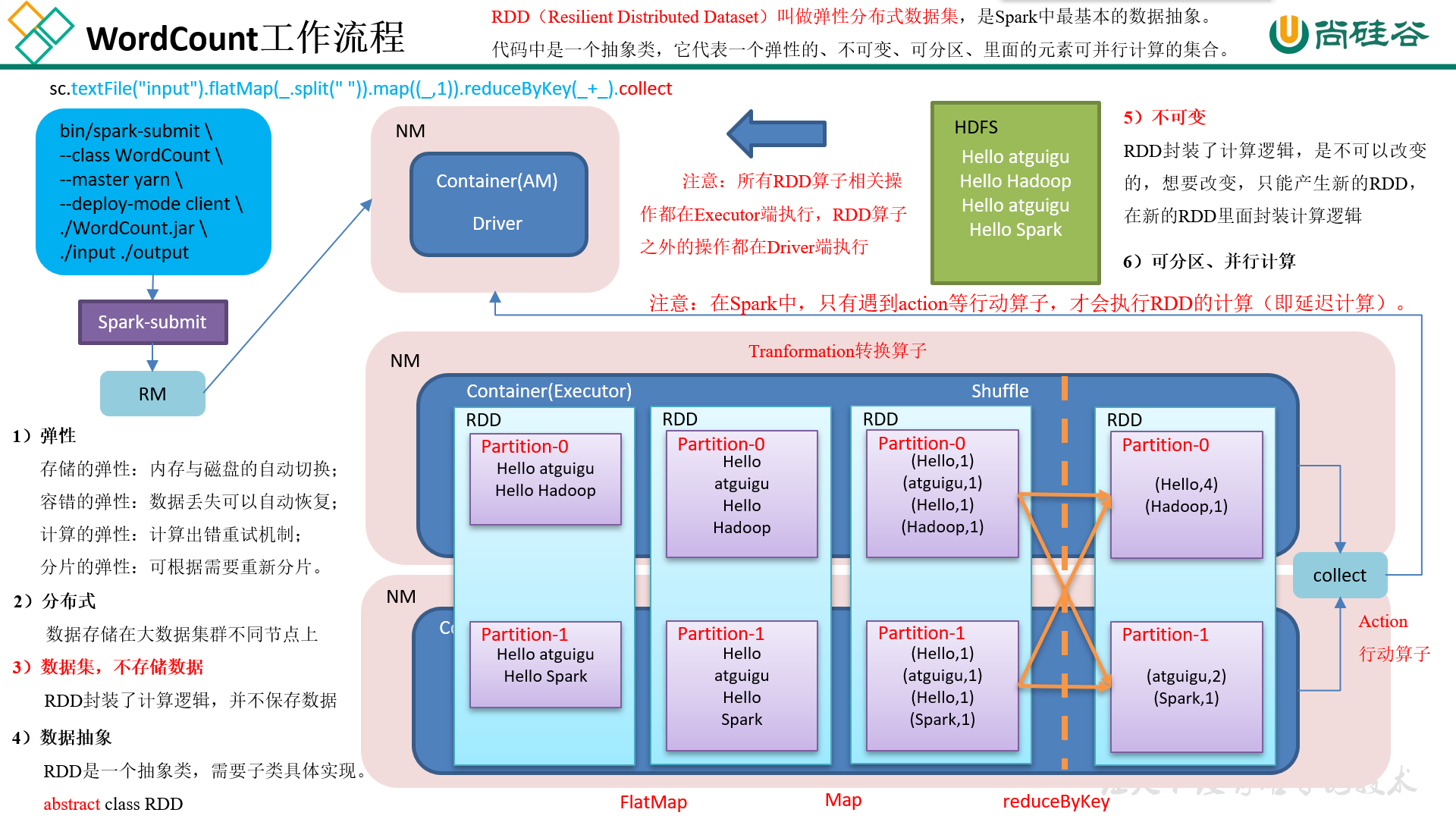
1.1.2 WordCount工作流程
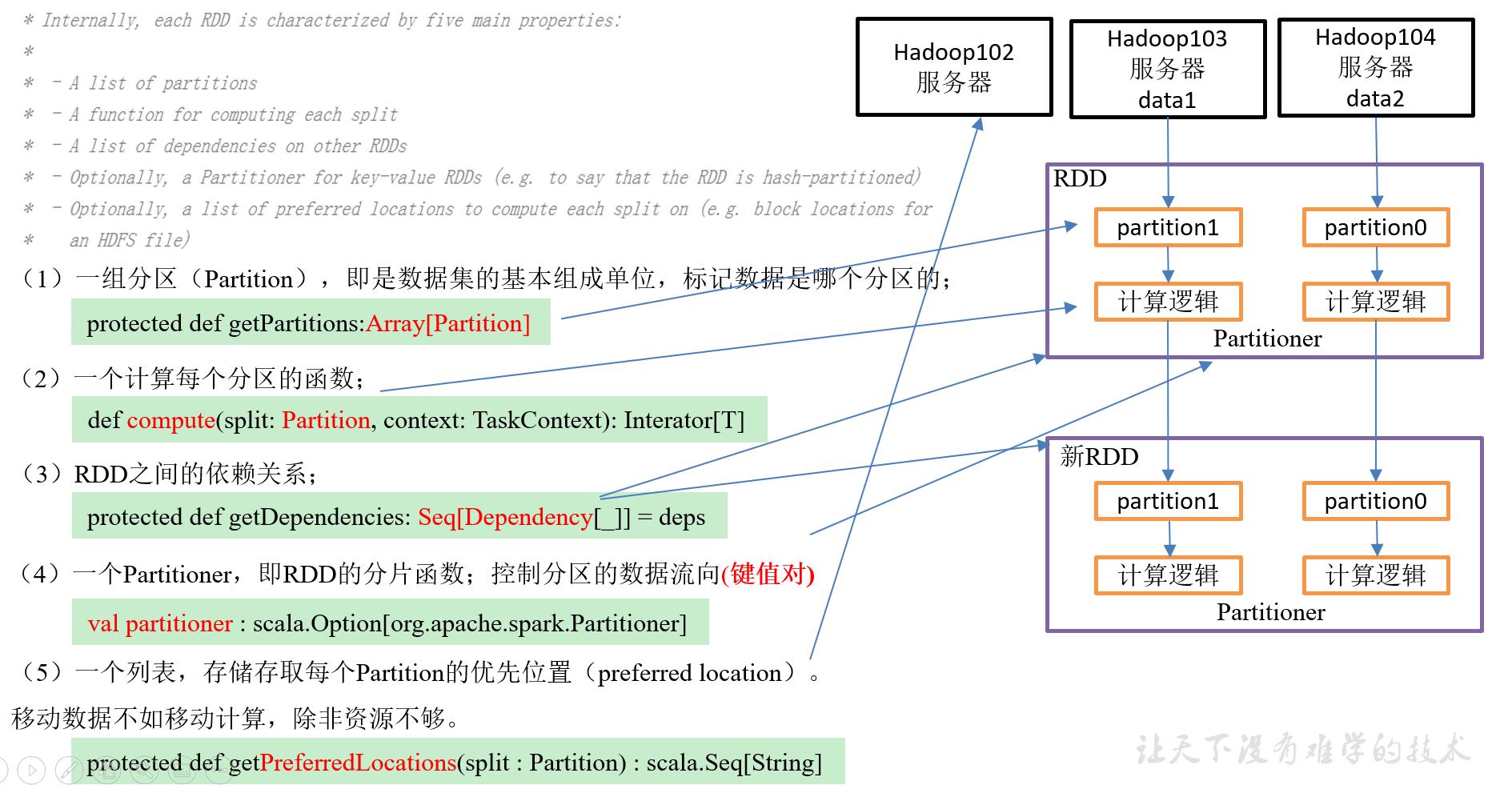
1.2 RDD五大特性
第2章 RDD编程
2.1 RDD的创建
在Spark中创建RDD的创建方式可以分为三种:从集合中创建RDD、从外部存储创建RDD、从其他RDD创建。
2.1.1 IDEA环境准备
1)创建一个maven工程
2)添加scala框架支持
3)创建一个scala文件夹,并把它修改为Source Root
4)创建包名
5)在pom文件中添加
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>3.0.0</version> </dependency> </dependencies> <build> <finalName>SparkCoreTest</finalName> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.4.6</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
2.1.2 从集合中创建
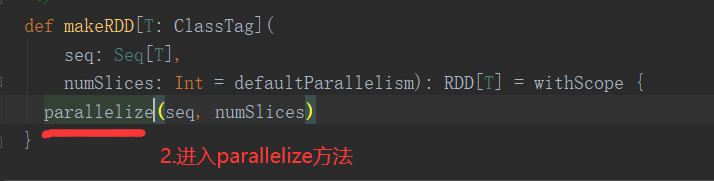
1)从集合中创建RDD,Spark主要提供了两种函数:parallelize和makeRDD
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestRDDOne { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("TestRDDOne") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //使用parallelize()创建RDD val rdd: RDD[Int] = sc.parallelize(List(1,3,5,7,9,10)) //遍历执行 rdd.collect().foreach(println) //使用makeRDD()创建RDD val makeRDD: RDD[Int] = sc.makeRDD(List(2,4,6,8,11)) //遍历执行 makeRDD.collect().foreach(println) sc.stop() } }
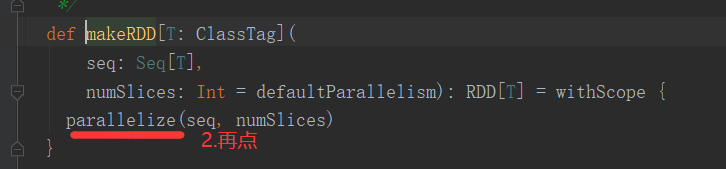
注意:makeRDD有两种重构方法,重构方法一如下,makeRDD和parallelize功能一样。
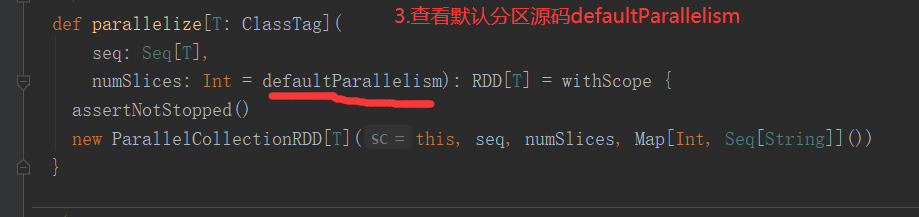
def makeRDD[T: ClassTag]( seq: Seq[T], numSlices: Int = defaultParallelism): RDD[T] = withScope { parallelize(seq, numSlices) }
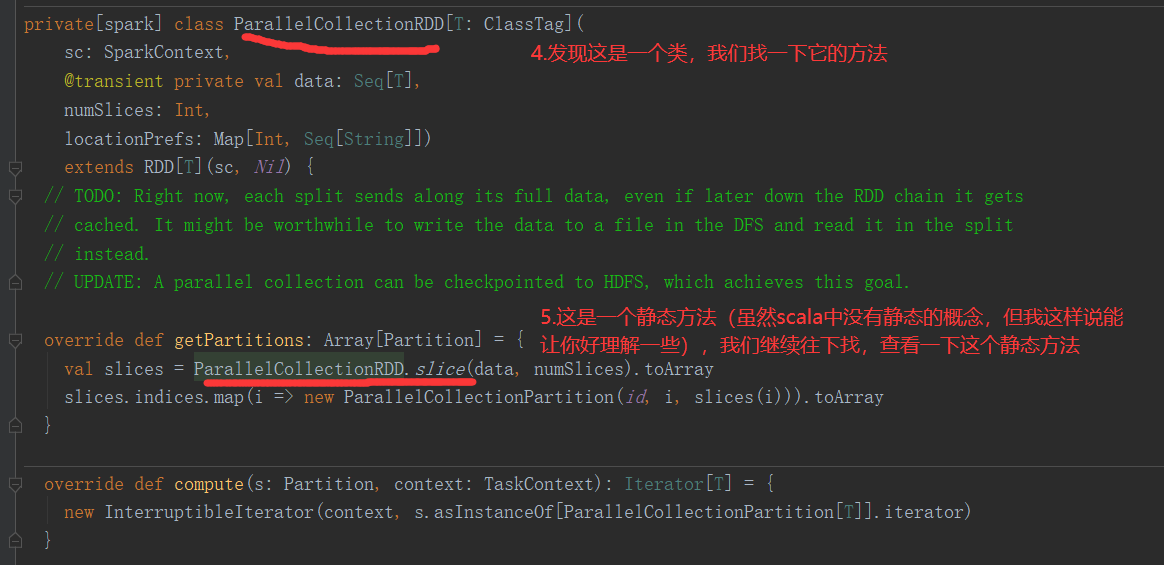
2)makeRDD的重构方法二,增加了位置信息(只需要知道makeRDD不完全等于parallelize即可)
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope { assertNotStopped() val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap new ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs) }
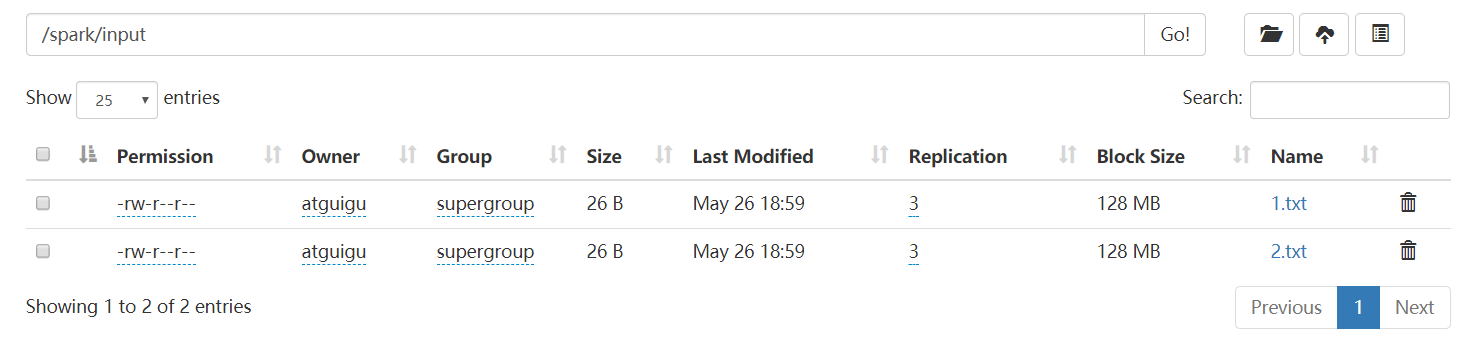
2.1.3 从外部存储系统的数据集创建
由外部存储系统的数据集创建RDD包括:本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、HBase等。
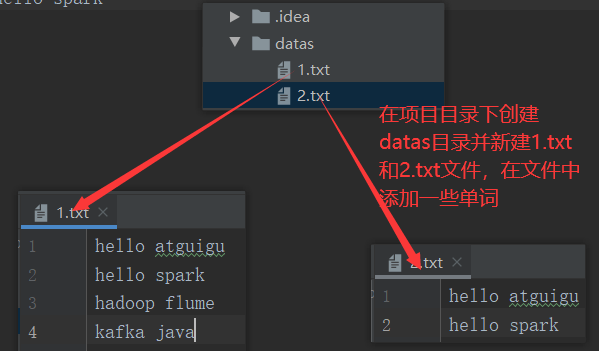
1)数据准备
在新建的Maven项目的名称上右键=》新建datas文件夹=》在datas文件夹上右键=》分别新建1.txt和2.txt。每个文件里面准备一些word单词
hello atguigu
hello spark
hadoop flume
2)创建RDD
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestRDDTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置Master和AppName val conf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("TestRDDTwo") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //读取文件,若是HDFS集群,则路径为:hdfs://hadoop102:8020/... // val lineRDD: RDD[String] = sc.textFile("datas") val lineRDD: RDD[String] = sc.textFile("hdfs://hadoop102:8020/spark/input") //打印 lineRDD.foreach(println) //关闭sc sc.stop() } }
2.1.4 从其他RDD创建
主要是通过一个RDD运算完后,再产生新的RDD。
2.1.5 创建IDEA快捷键
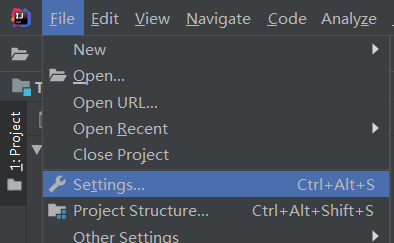
1)点击File->Settings…->Editor->Live Templates->output->Live Template
2)点击左下角的Define->选择Scala
3)在Abbreviation中输入快捷键名称scc,在Template text中填写,输入快捷键后生成的内容。
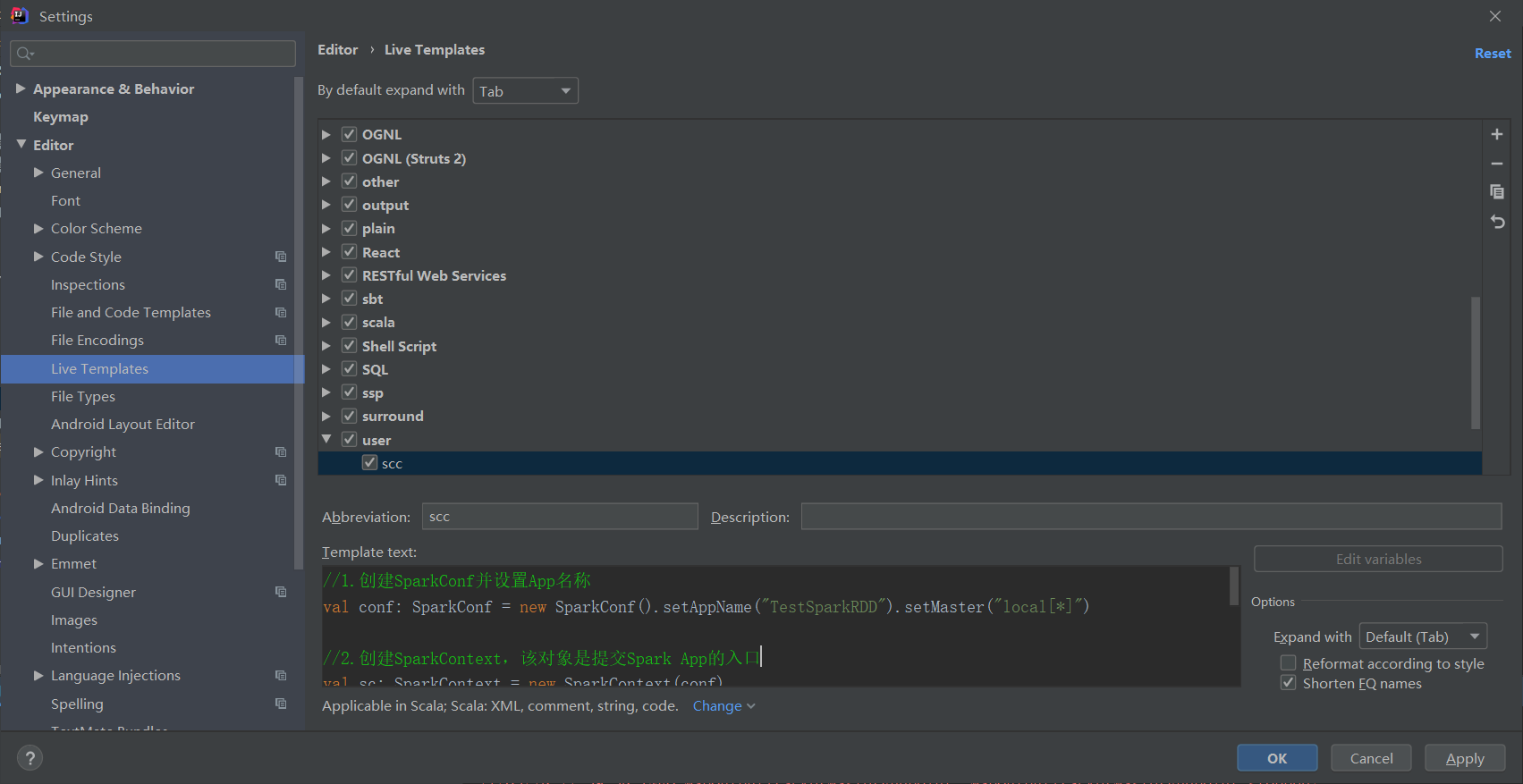
//1.创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //4.关闭连接 sc.stop()
2.2 分区规则
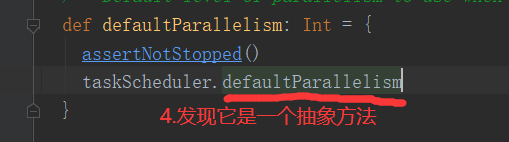
2.2.1 默认分区源码(RDD数据从集合中创建)
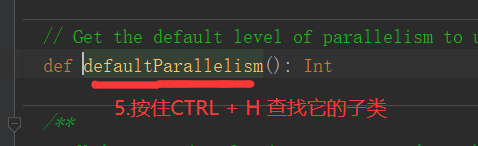
1)默认分区数源码解读(查看源码必备快捷键技能--跳转到上一个/下一个位置编辑位置:Ctrl + Alt + 左/右箭头)
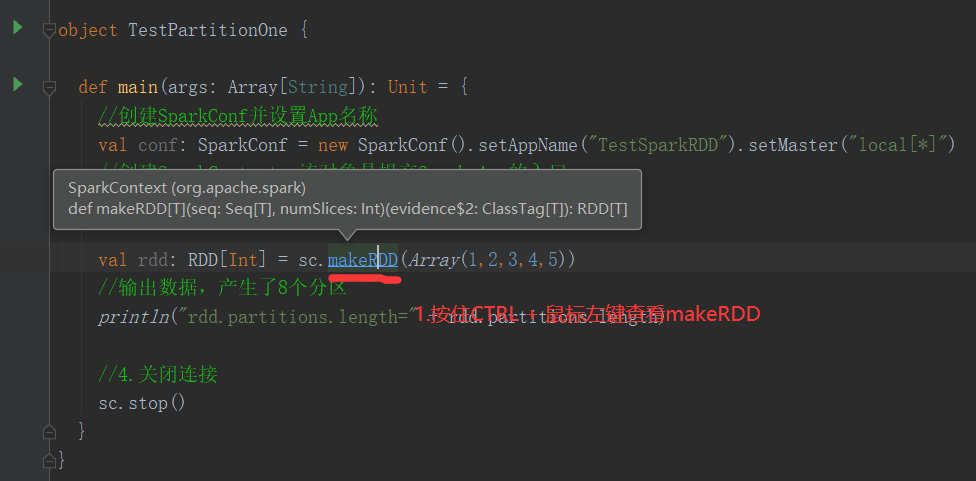
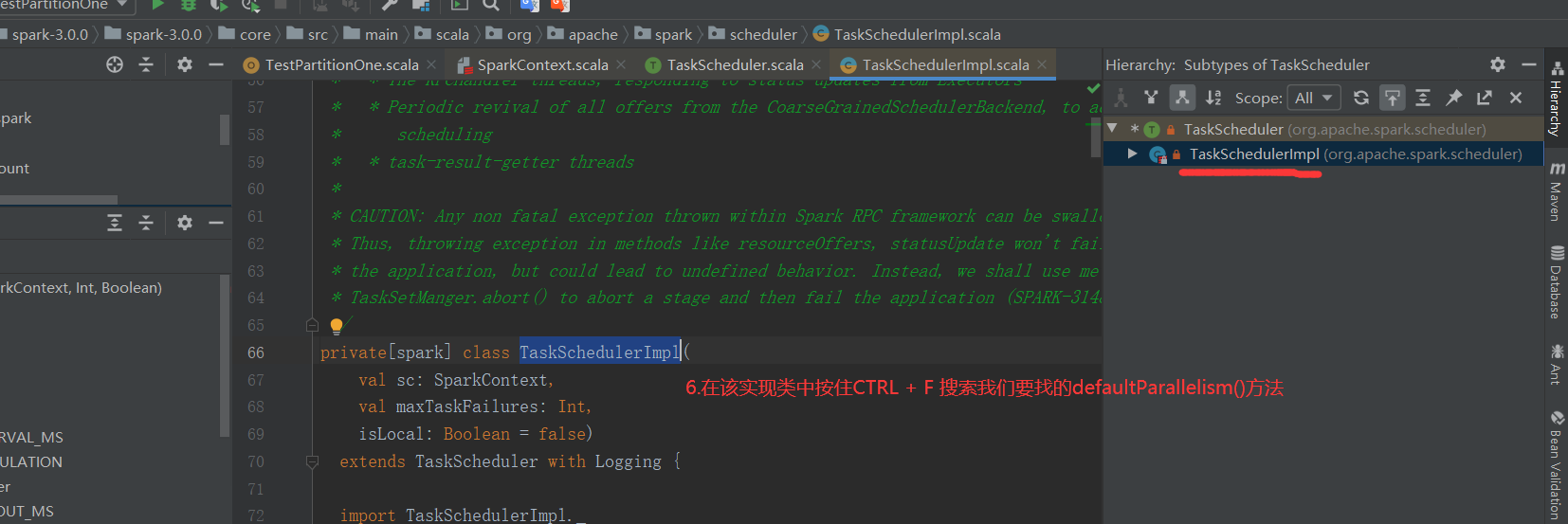
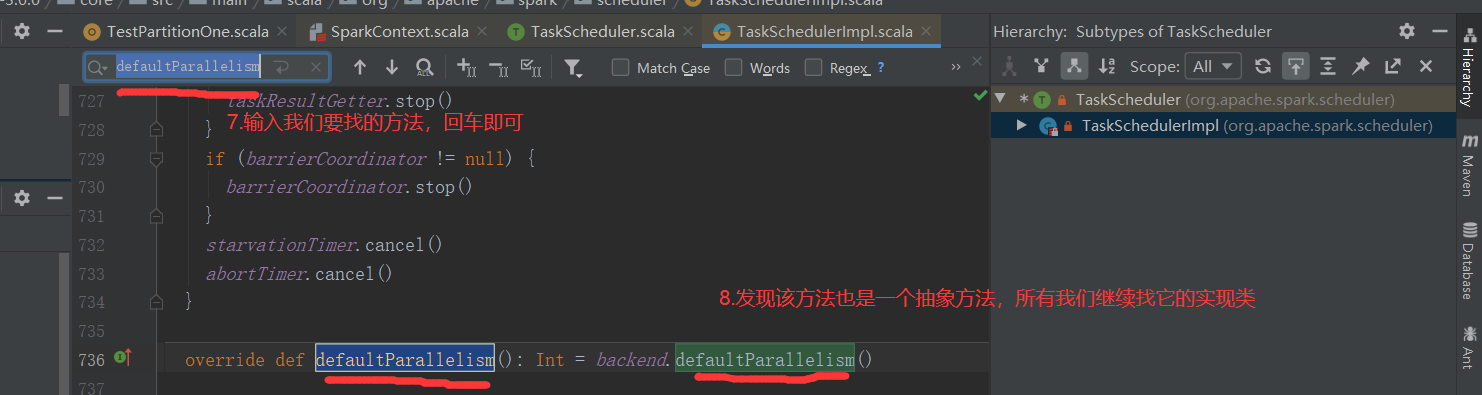
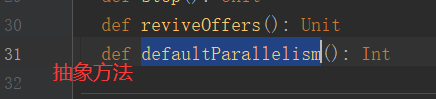
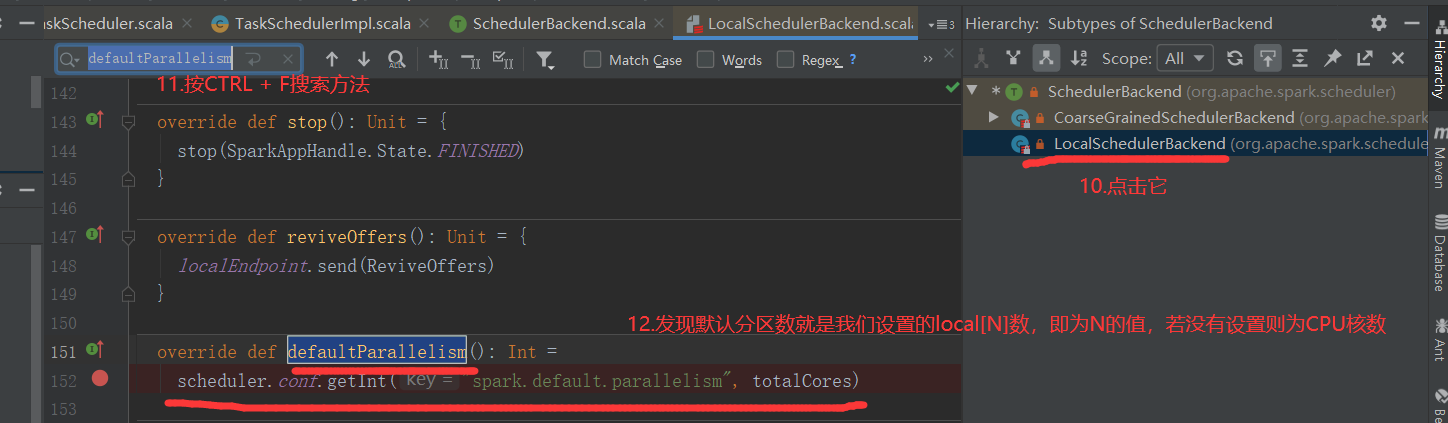

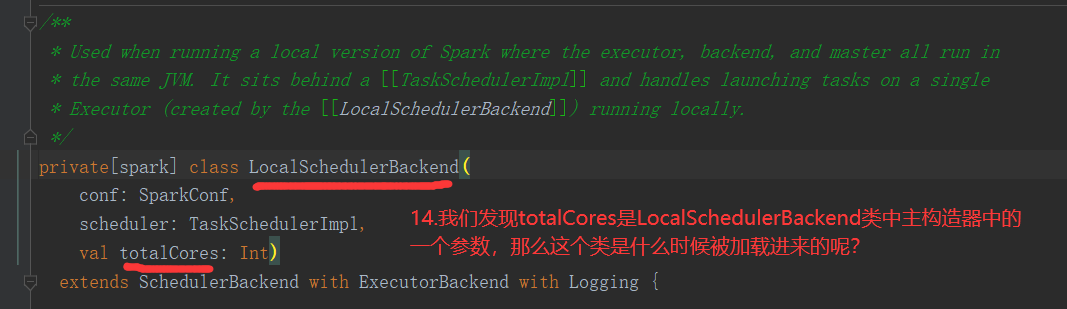

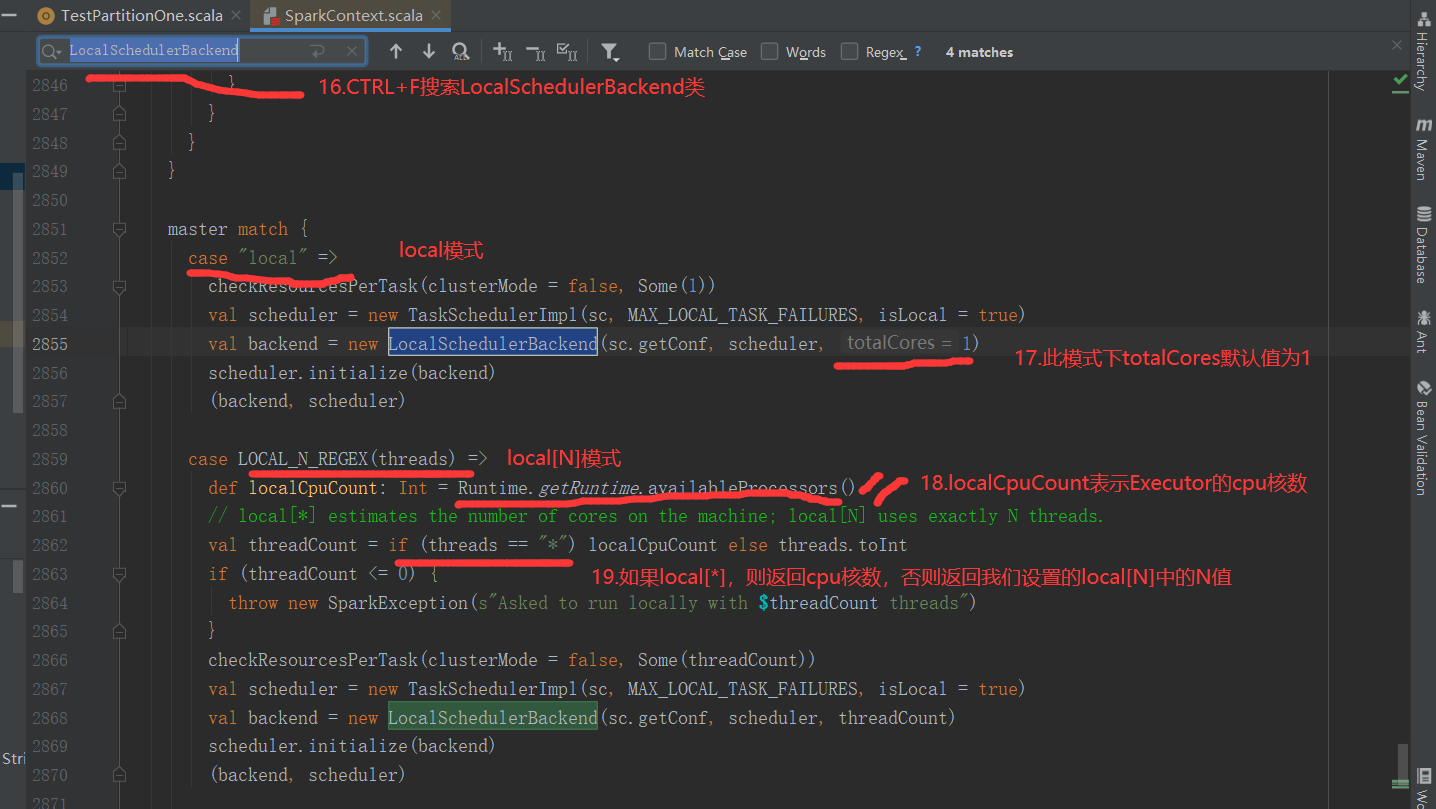

2)代码验证
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestPartitionOne { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5)) //输出数据,产生了16个分区 println("rdd.partitions.length=" + rdd.partitions.length) //关闭连接 sc.stop() } }

3)思考:数据就5个,分区却产生了16个(我的CPU核数是16核),严重浪费资源,怎么办?
2.2.2 分区源码(RDD数据从集合中创建)
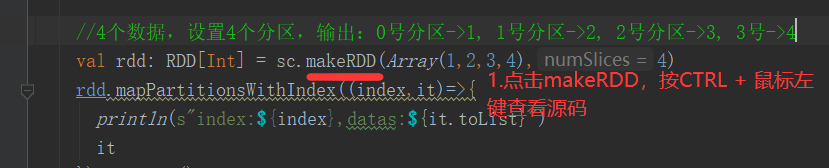
1)分区测试(RDD数据从集合中创建)
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestPartitionTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //4个数据,设置4个分区,输出:0号分区->1, 1号分区->2, 2号分区->3, 3号->4 val rdd: RDD[Int] = sc.makeRDD(Array(1,2,3,4),4) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() println("-"*100) //4个数据,设置3个分区,输出:0号分区->1, 1号分区->2, 2号->3,4 val rdd2: RDD[Int] = sc.makeRDD(Array(1,2,3,4),3) rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() println("-"*100) //5个数据,设置3个分区,输出:0号分区->1, 1号分区->2,3, 2号分区->4,5 val rdd3: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5),3) rdd3.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //关闭连接 sc.stop() } }
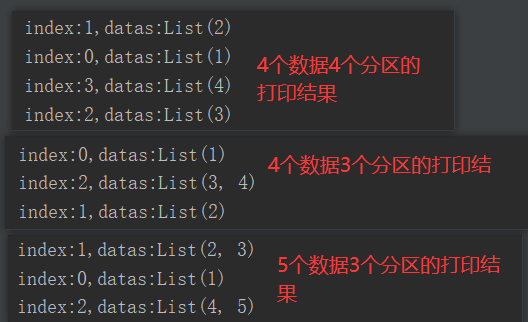
2)分区源码

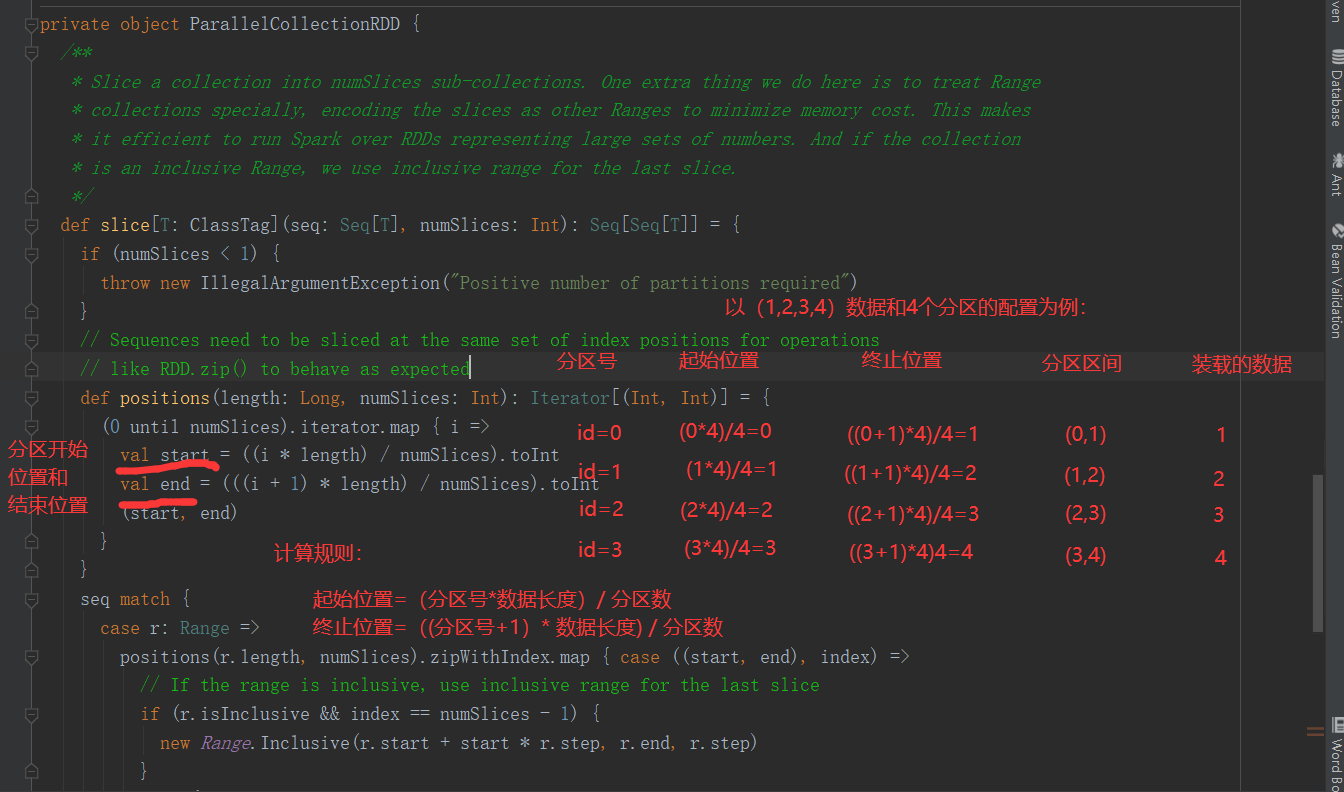

结论:分区的开始位置 = 分区号 * 数据总长度/分区总数,分区的结束位置 =(分区号 + 1)* 数据总长度/分区总数
2.2.3 默认分区源码(RDD数据从文件中读取后创建)
1)数据准备
2)分区测试
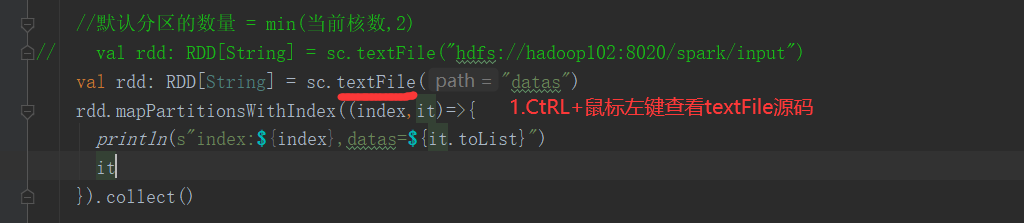
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestPartitionThree { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //默认分区的数量 = min(当前核数,2) // val rdd: RDD[String] = sc.textFile("hdfs://hadoop102:8020/spark/input") val rdd: RDD[String] = sc.textFile("datas") rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas=${it.toList}") it }).collect() //关闭连接 sc.stop() } }

3)分区源码
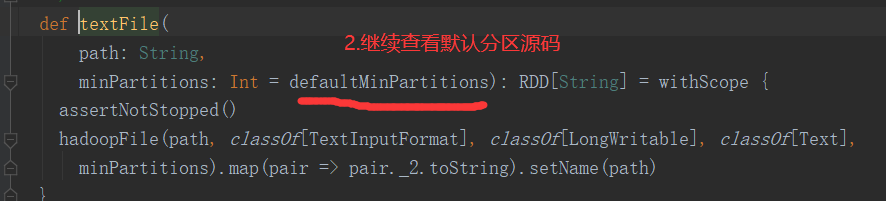

2.2.4 分区源码(RDD数据从文件中读取后创建)
1)数据准备
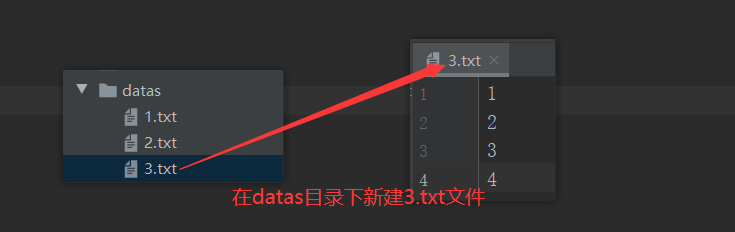
2)分区测试
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestPartitionFour { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //输入数据1-4,每行一个数据,输出:0号分区->1,2 1号分区->3 2号分区->4 3号分区->空 val rdd: RDD[String] = sc.textFile("datas/3.txt",3) rdd.mapPartitionsWithIndex((index,it) => { println(s"index:${index},datas:${it.toList}") it }).collect() //关闭连接 sc.stop() } }

3)源码解析

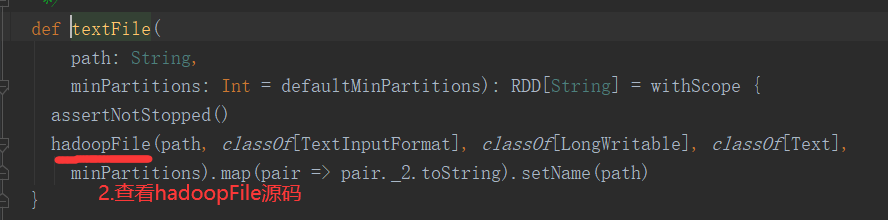
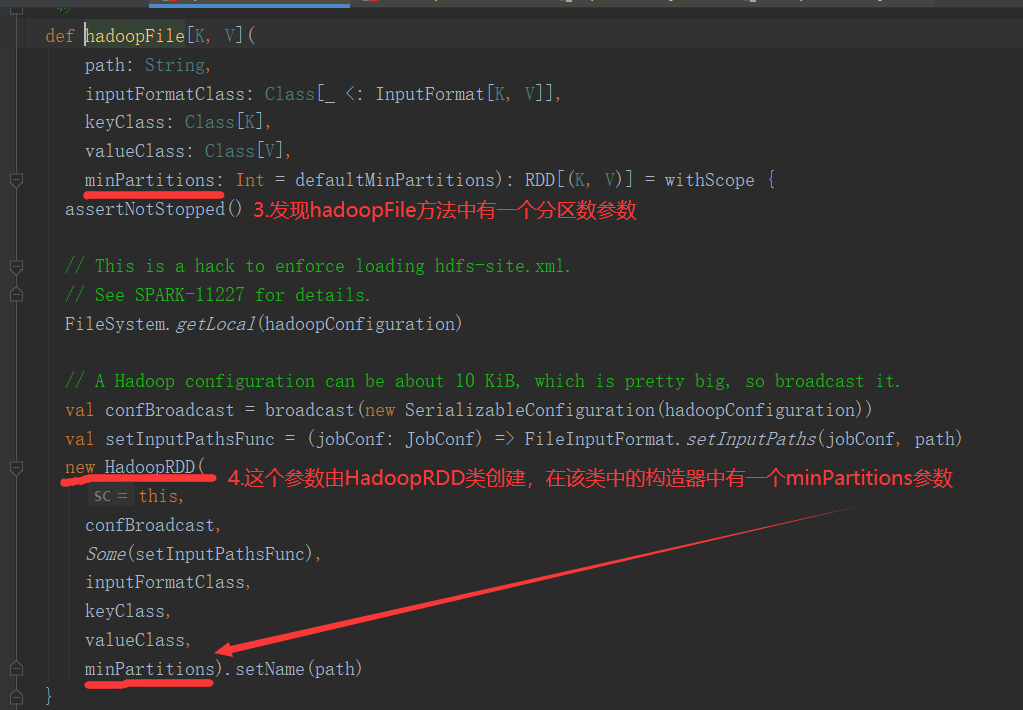
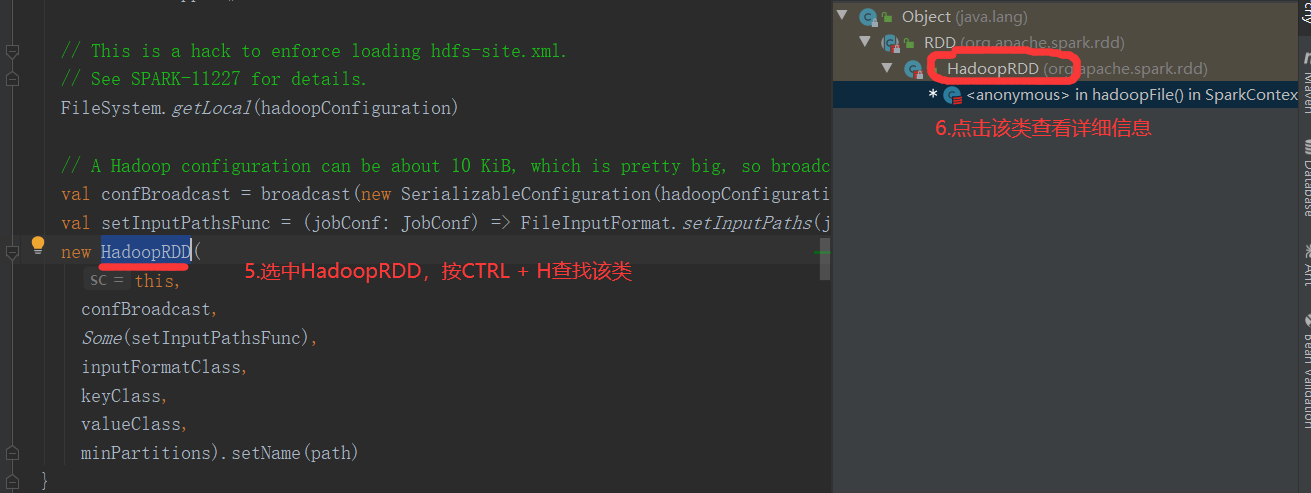
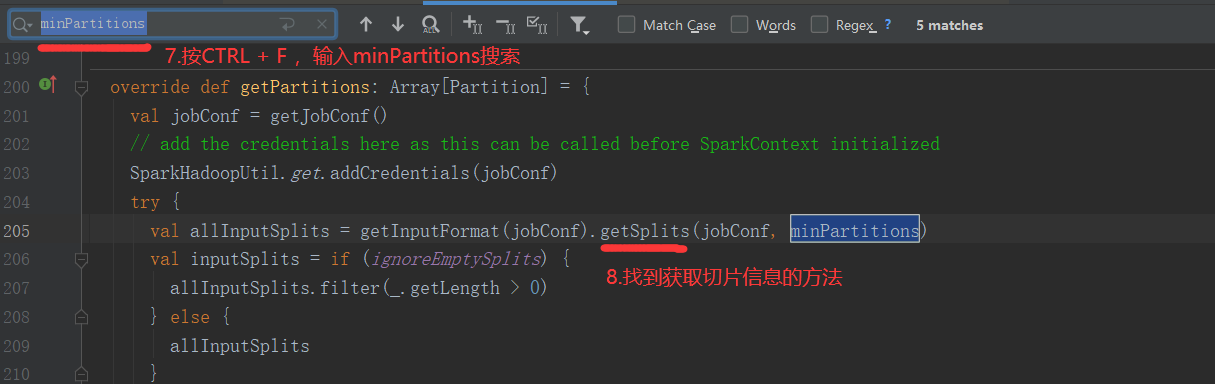
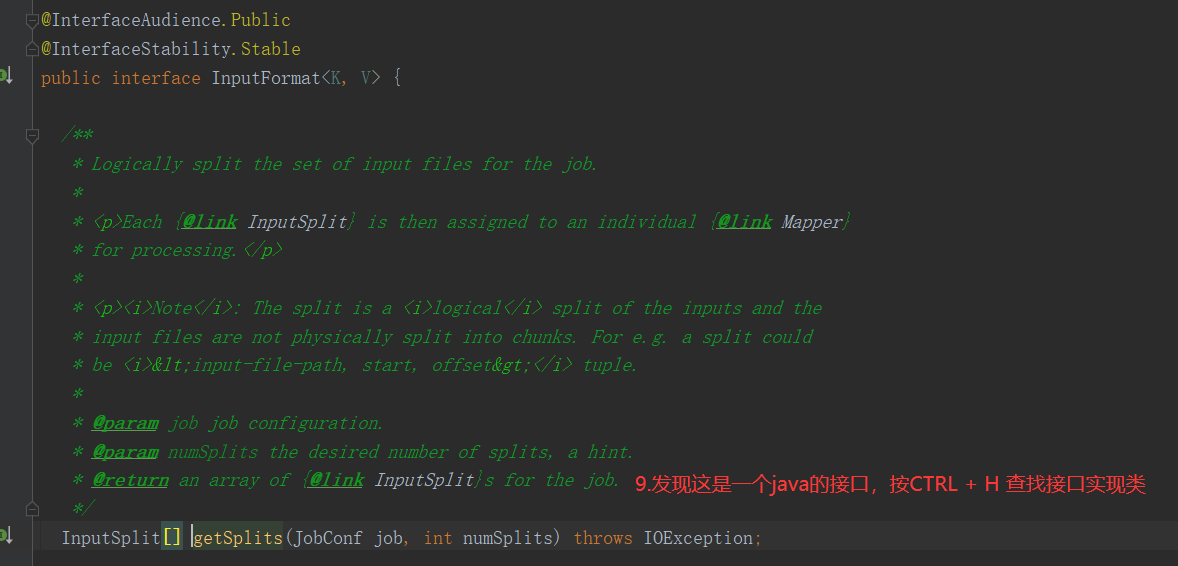
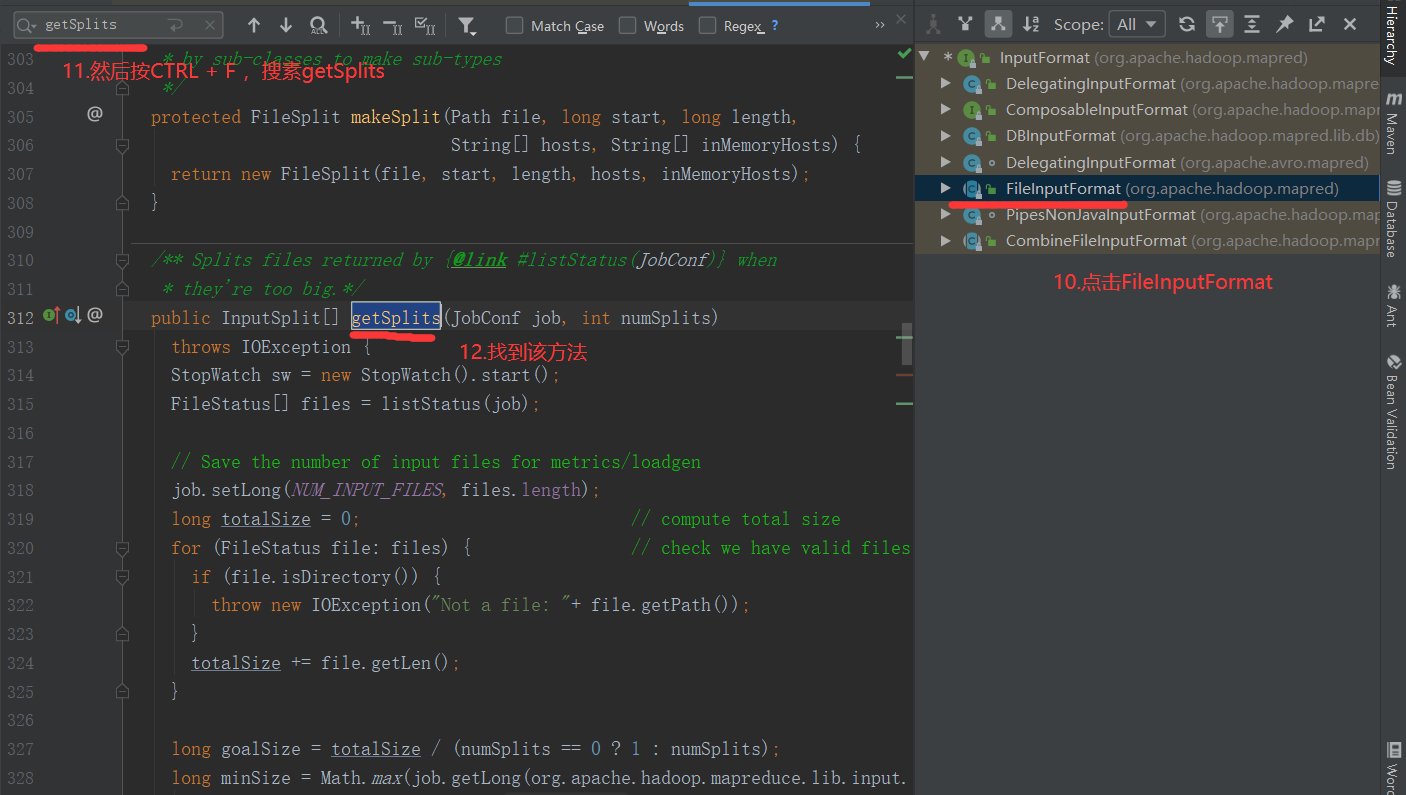
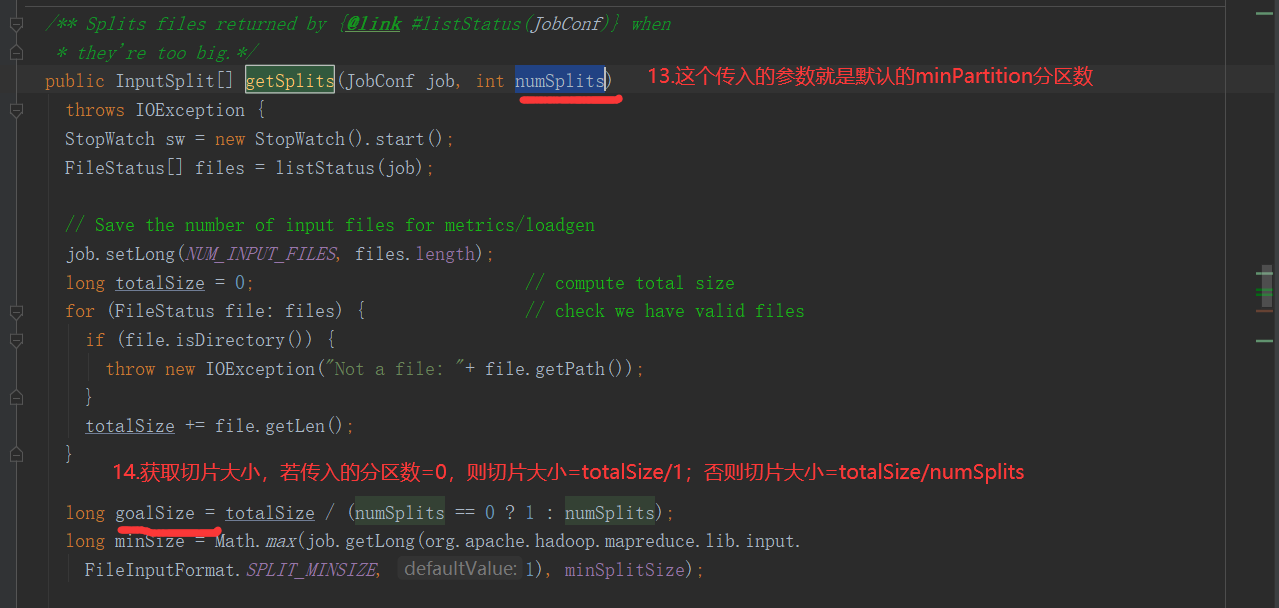


注意:getSplits文件返回的是切片规划,真正读取是在compute方法中创建LineRecordReader读取的,有两个关键变量: start = split.getStart() end = start + split.getLength
2.3 Transformation转换算子(面试开发重点)
RDD整体上分为Value类型、双Value类型和Key-Value类型
2.3.1 Value类型
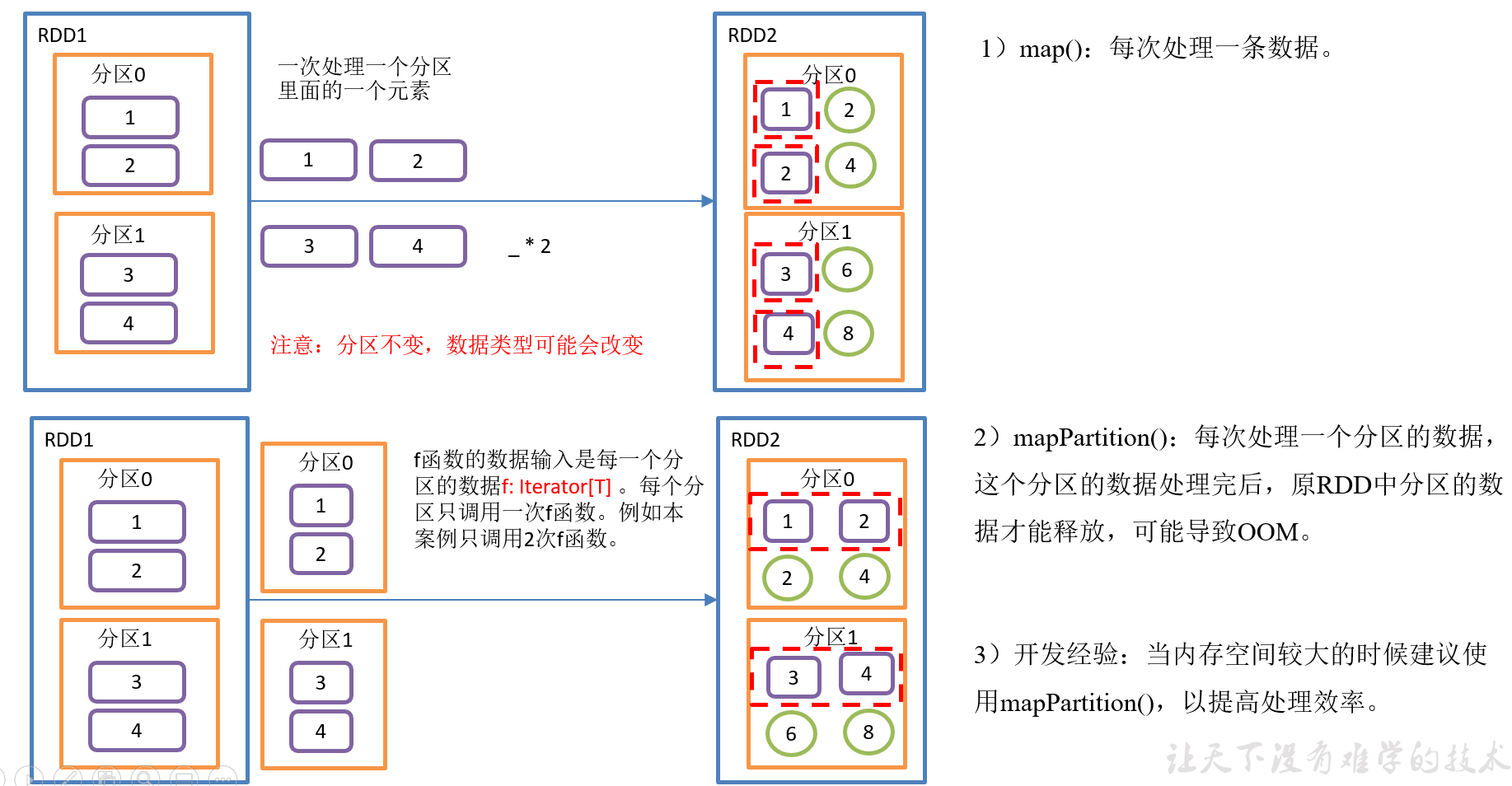
2.3.1.1 map()映射
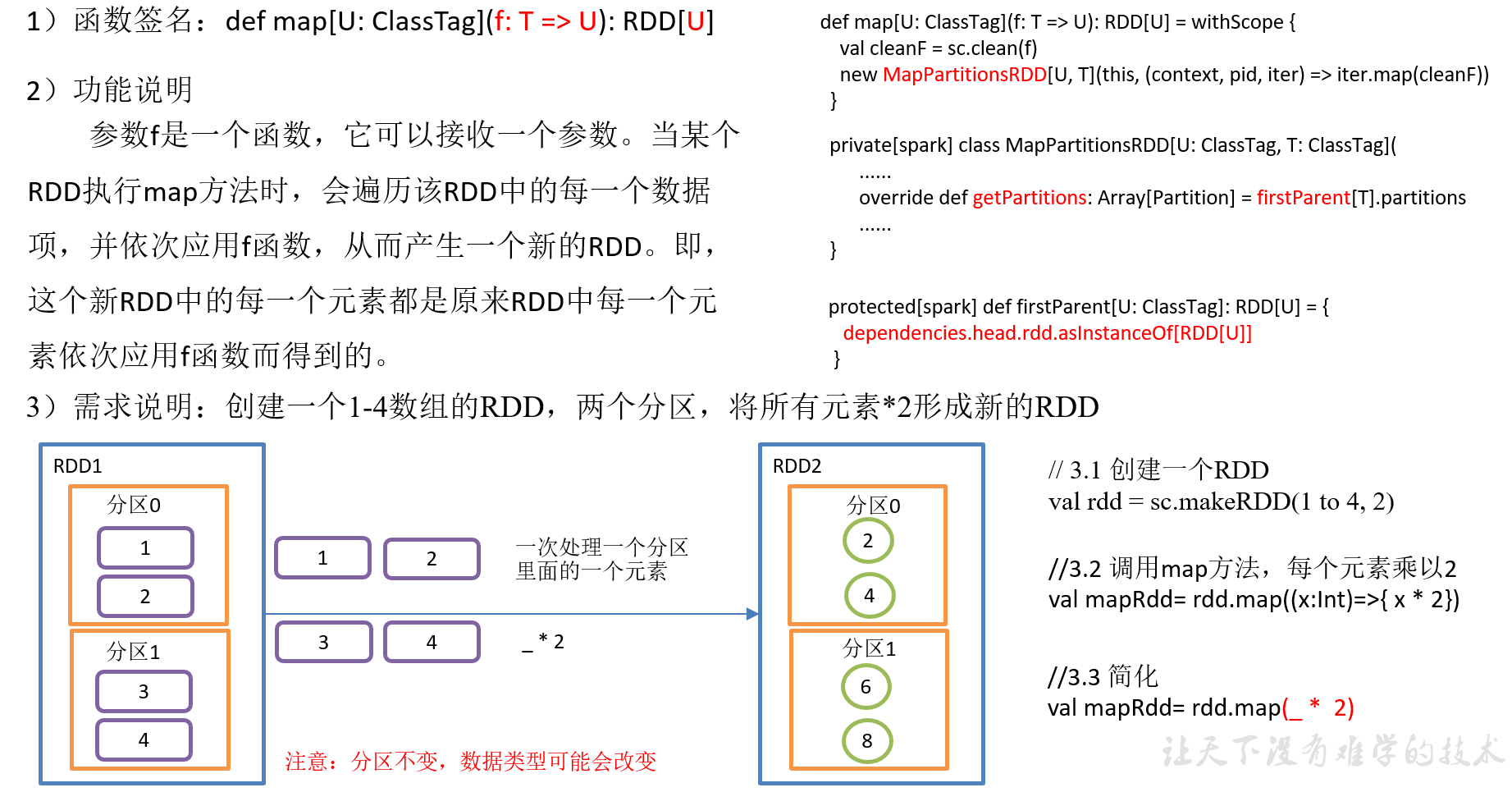
4)具体实现
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestMapOne { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,2) //调用map方法,每个元素*2 val rdd2: RDD[Int] = rdd.map(_ * 2) rdd2.foreach(println) //关闭连接 sc.stop() } }

2.3.1.2 mapPartitions()以分区为单位执行Map
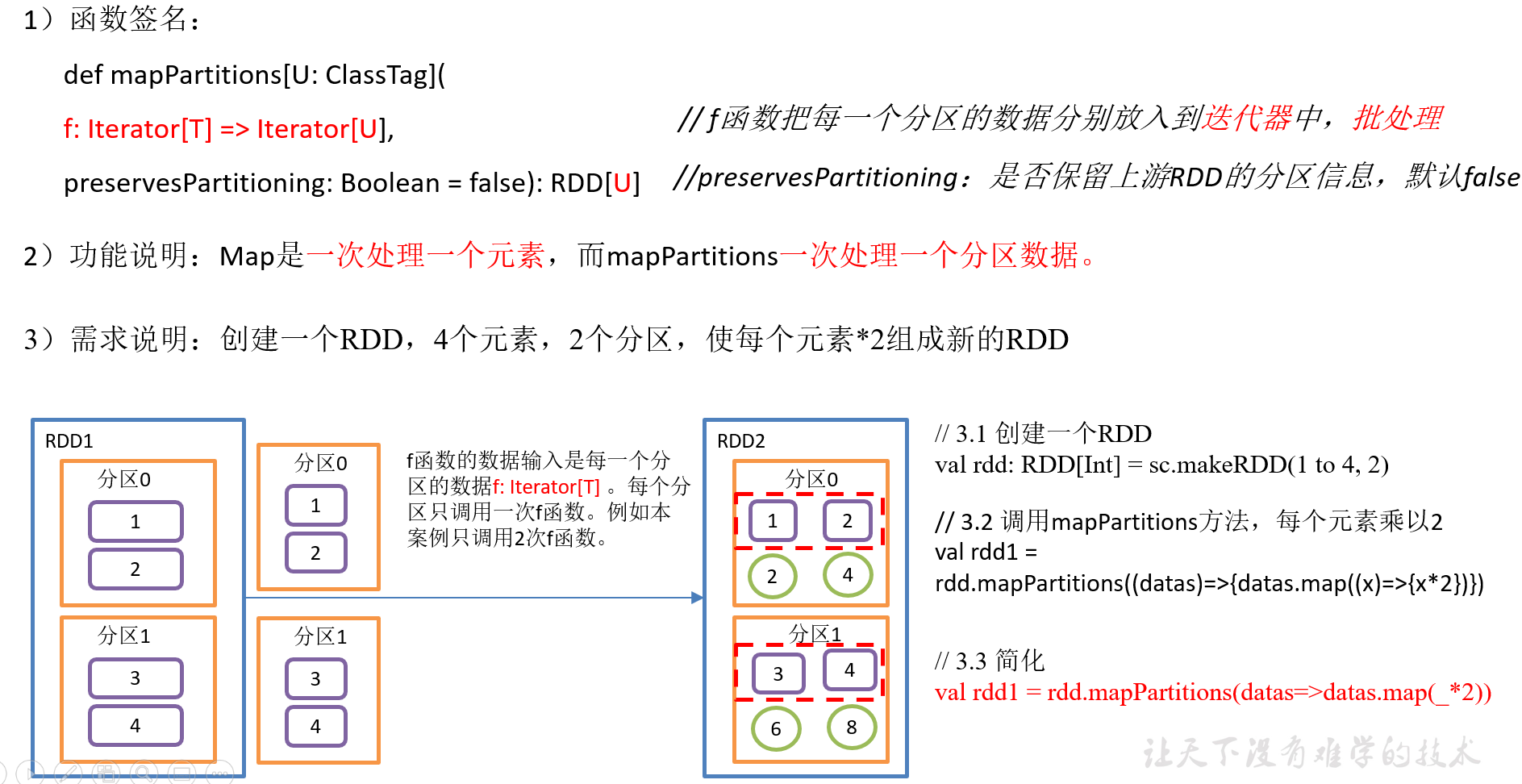
4)具体实现
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestMapPartition { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,2) var rdd2: RDD[Int] = rdd.mapPartitions(x =>{ x.map(_ * 2) }) rdd2.collect().foreach(println) //关闭连接 sc.stop() } }

2.3.1.3 map()和mapPartitions()区别
2.3.1.4 mapPartitionsWithIndex()带分区号
1)函数签名:
def mapPartitionsWithIndex[U: ClassTag]( f: (Int, Iterator[T]) => Iterator[U], // Int表示分区编号 preservesPartitioning: Boolean = false): RDD[U]
2)功能说明:类似于mapPartitions,比mapPartitions多一个整数参数表示分区号
3)需求说明:创建一个RDD,使每个元素跟所在分区号形成一个元组,组成一个新的RDD
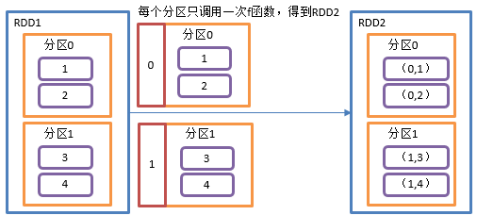
4)具体实现
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestMapPartitionsWithIndex { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,2) //创建一个RDD,使得每一个元素所在的分区号形成一个元组,组成一个新的RDD var rdd2 = rdd.mapPartitionsWithIndex((index,items)=>{ items.map((index,_)) }) rdd2.collect().foreach(println) //关闭连接 sc.stop() } }

2.3.1.5 flatMap()扁平化
1)函数签名:def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
2)功能说明
与map操作类似,将RDD中的每一个元素通过应用f函数依次转换为新的元素,并封装到RDD中。
区别:在flatMap操作中,f函数的返回值是一个集合,并且会将每一个该集合中的元素拆分出来放到新的RDD中。
3)需求说明:创建一个集合,集合里面存储的还是子集合,把所有子集合中数据取出放入到一个大的集合中。

4)具体实现:
package com.yuange.spark.day02 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestFlatMap { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd = sc.makeRDD(List(List(1,2),List(3,4),List(5,6),List(7)),2) //把所有子集合中的数据取出放入到一个新集合中 rdd.flatMap(list=>list).collect()foreach(println) //关闭连接 sc.stop() } }
2.3.1.6 glom()分区转换数组
1)函数签名:def glom(): RDD[Array[T]]
2)功能说明
该操作将RDD中每一个分区变成一个数组,并放置在新的RDD中,数组中元素的类型与原分区中元素类型一致
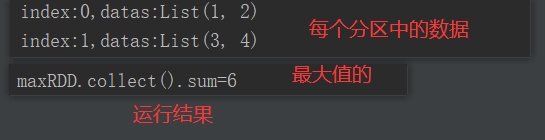
3)需求说明:创建一个2个分区的RDD,并将每个分区的数据放到一个数组,求出每个分区的最大值
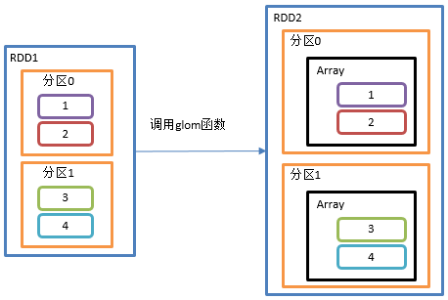
4)具体实现
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestGlom { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,2) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //求出每个分区的最大值:0号分区->1,2 1号分区->3,4 val maxRDD: RDD[Int] = rdd.glom().map(_.max) //求出所有分区的最大值的和:2+4=6 println("maxRDD.collect().sum=" + maxRDD.collect().sum) //关闭连接 sc.stop() } }
2.3.1.7 groupBy()分组(进行shuffle操作)
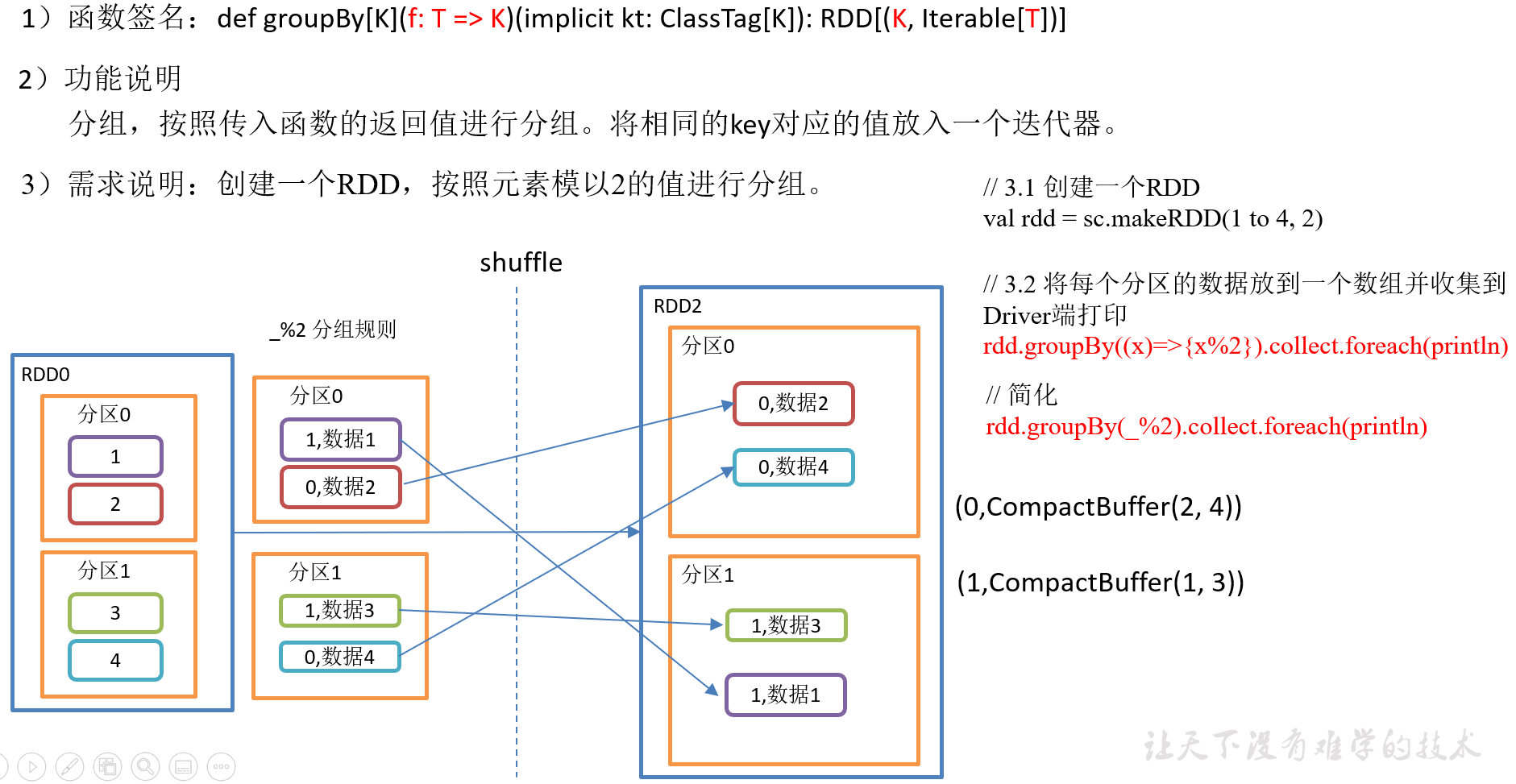
4)具体实现
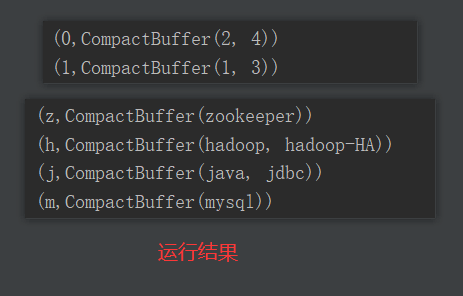
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestGroupBy { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,2) //将每个分区中的数据放到一个数组中并收集到Driver端打印 rdd.groupBy(_ % 2).collect().foreach(println) println("-"*100) //创建一个RDD val rdd2: RDD[String] = sc.makeRDD(List("java","jdbc","mysql","hadoop","hadoop-HA","zookeeper")) //按照首字母第一个相同的分组 rdd2.groupBy(x=>{ x.substring(0,1) }).collect().foreach(println) //关闭连接 sc.stop() } }
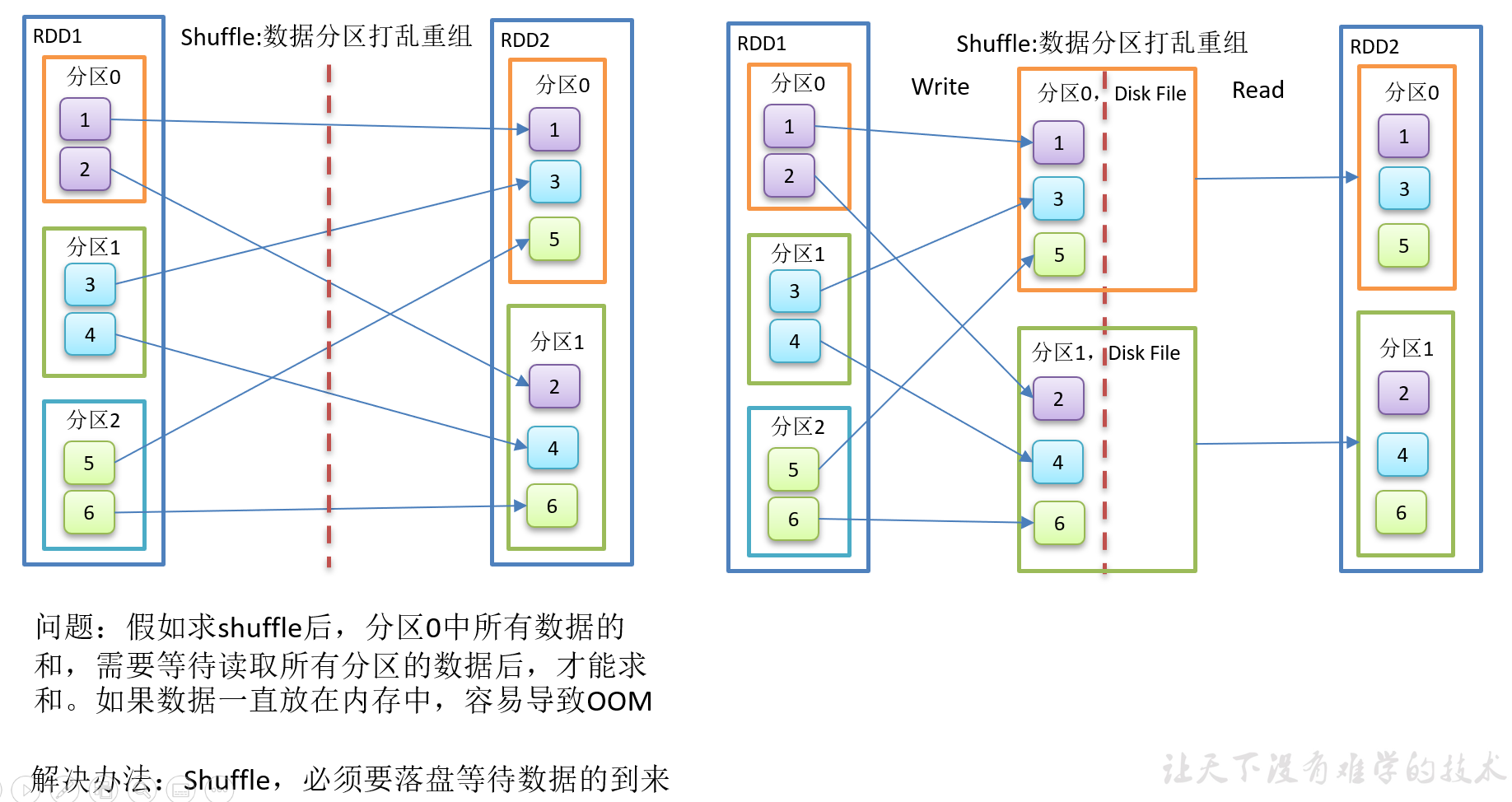
5)groupBy会存在shuffle过程,shuffle就是将不同的分区数据进行打乱重组的过程,shuffle一定会落盘。可以在local模式下执行程序,通过4040看效果。
2.3.1.8 GroupBy之WordCount
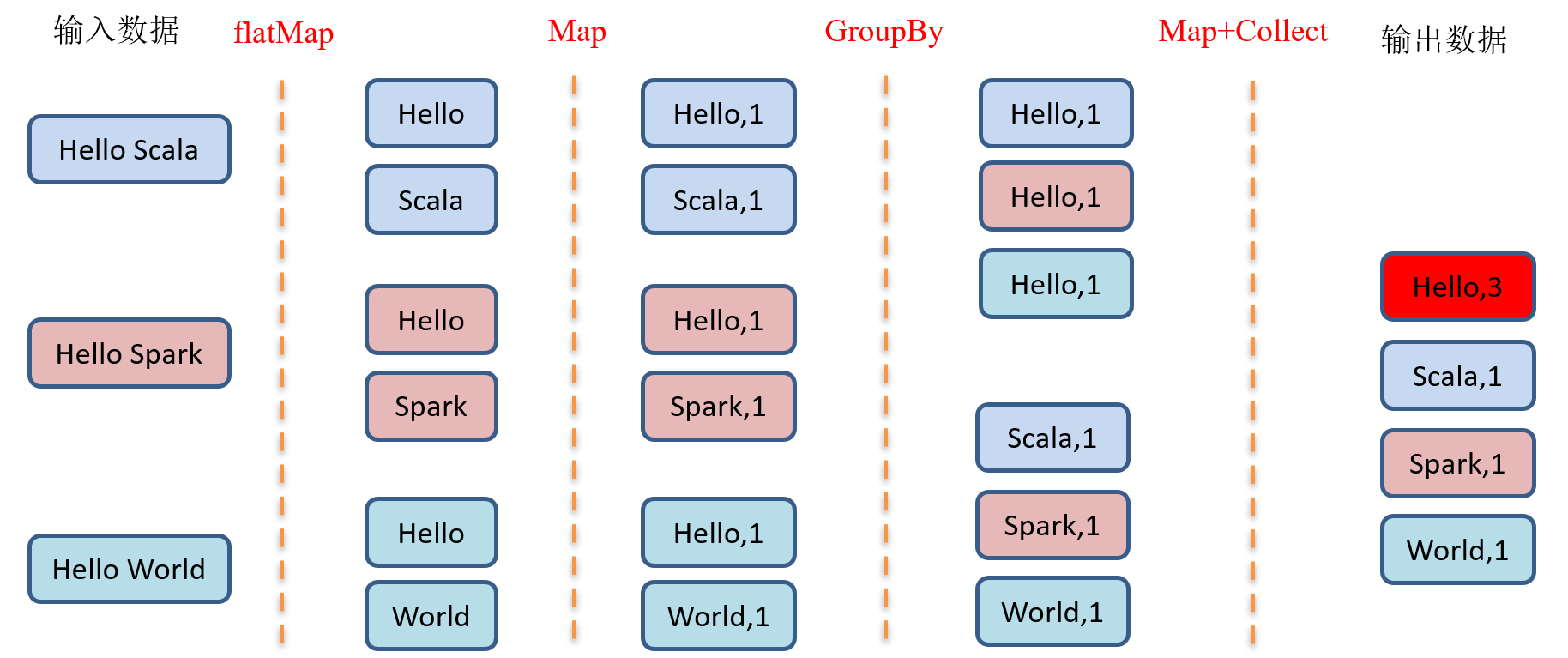
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestGroupByTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val list: List[String] = List("Hello Scala","Hello Spark","Hello World") val rdd: RDD[String] = sc.makeRDD(list) //将字符串拆分成一个个单词 val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) //将结果进行转换 val rddMap: RDD[(String,Int)] = rdd2.map(x => { (x, 1) }) //分组 val rdd3: RDD[(String,Iterable[(String,Int)])] = rddMap.groupBy(x => { x._1 }) //计算相同单词个数 var rdd4: RDD[(String,Int)] = rdd3.map(x=>{ (x._1,x._2.size) }) // var rdd5: RDD[(String,Int)] = rdd3.map{ // case (word,list) => { // (word,list.size) // } // } //打印 rdd4.collect().foreach(println) //关闭连接 sc.stop() } }

2.3.1.9 filter()过滤
1)函数签名: def filter(f: T => Boolean): RDD[T]
2)功能说明
接收一个返回值为布尔类型的函数作为参数。当某个RDD调用filter方法时,会对该RDD中每一个元素应用f函数,如果返回值类型为true,则该元素会被添加到新的RDD中。
3)需求说明:创建一个RDD,过滤出对2取余等于0的数据
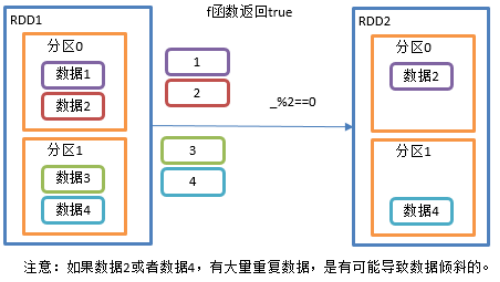
4)代码实现
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestFilter { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),2) //过滤出符合条件的数据 // var rdd2: RDD[Int] = rdd.filter(x=>{ // x % 2 == 0 // }) var rdd2: RDD[Int] = rdd.filter(_ % 2 == 0) //打印 rdd2.collect().foreach(println) //关闭连接 sc.stop() } }

2.3.1.10 sample()采样
1)函数签名:
def sample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong): RDD[T] // withReplacement: true为有放回的抽样,false为无放回的抽样 // fraction表示:以指定的随机种子随机抽样出数量为fraction的数据 // seed表示:指定随机数生成器种子
2)功能说明:从大量的数据中采样
3)需求说明:创建一个RDD(1-10),从中选择放回和不放回抽样

4)代码实现
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSample { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6)) /** * 伯努利算法(抽取数据不放回):又叫0、1分布。例如扔硬币,要么正面,要么反面。 * 具体实现:根据种子和随机算法算出一个数和第二个参数设置几率比较,小于第二个参数要,大于不要 * 第一个参数:抽取的数据是否放回,false:不放回 * 第二个参数:抽取的几率,范围在[0,1]之间,0:全不取;1:全取; * 第三个参数:随机数种子 */ val rdd2: RDD[Int] = rdd.sample(false,0.5) rdd2.collect().foreach(println) println("-"*100) /** * 抽取数据放回(泊松算法) * 第一个参数:抽取的数据是否放回,true:放回;false:不放回 * 第二个参数:重复数据的几率,范围大于等于0.表示每一个元素被期望抽取到的次数 * 第三个参数:随机数种子 */ val rdd3: RDD[Int] = rdd.sample(true,2) rdd3.collect().foreach(println) //关闭连接 sc.stop() } }
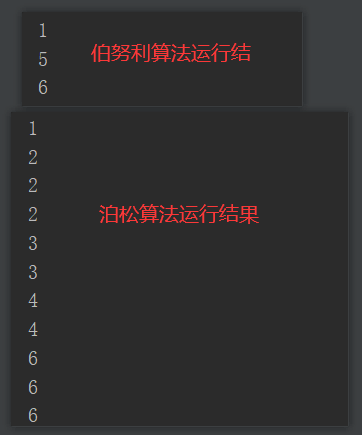
5)随机数测试
package com.yuange.spark.days03 import scala.util.Random object TestSampleTwo { def main(args: Array[String]): Unit = { //随机算法相同,种子相同,则随机数相同 // val random: Random = new Random(100) //不输入参数,种子取当前时间的纳秒值,从而随机结果不同 val random: Random = new Random() for (i <- 0 until 5){ println(random.nextInt(10)) } println("-"*100) // val random2: Random = new Random(100) val random2: Random = new Random() for (i <- 0 until 5){ println(random2.nextInt(10)) } } }


2.3.1.11 distinct()去重
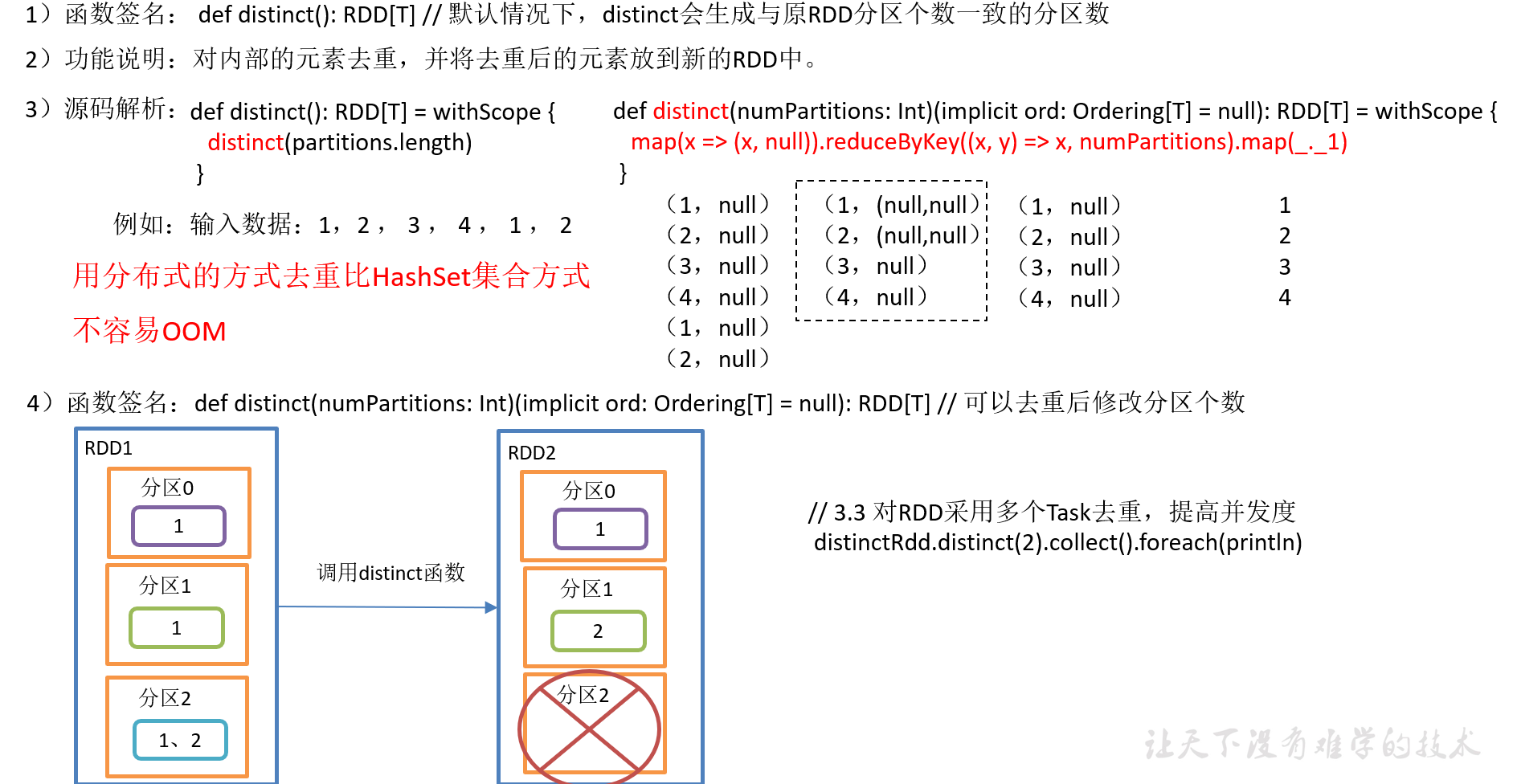
4)代码实现
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestDistinct { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,3,5,7,2,2,4,3,1,9)) //去重并打印新RDD rdd.distinct().collect().foreach(println) //对RDD采用多个Task去重,提高并行度 rdd.distinct(2).collect().foreach(println) //关闭连接 sc.stop() } }
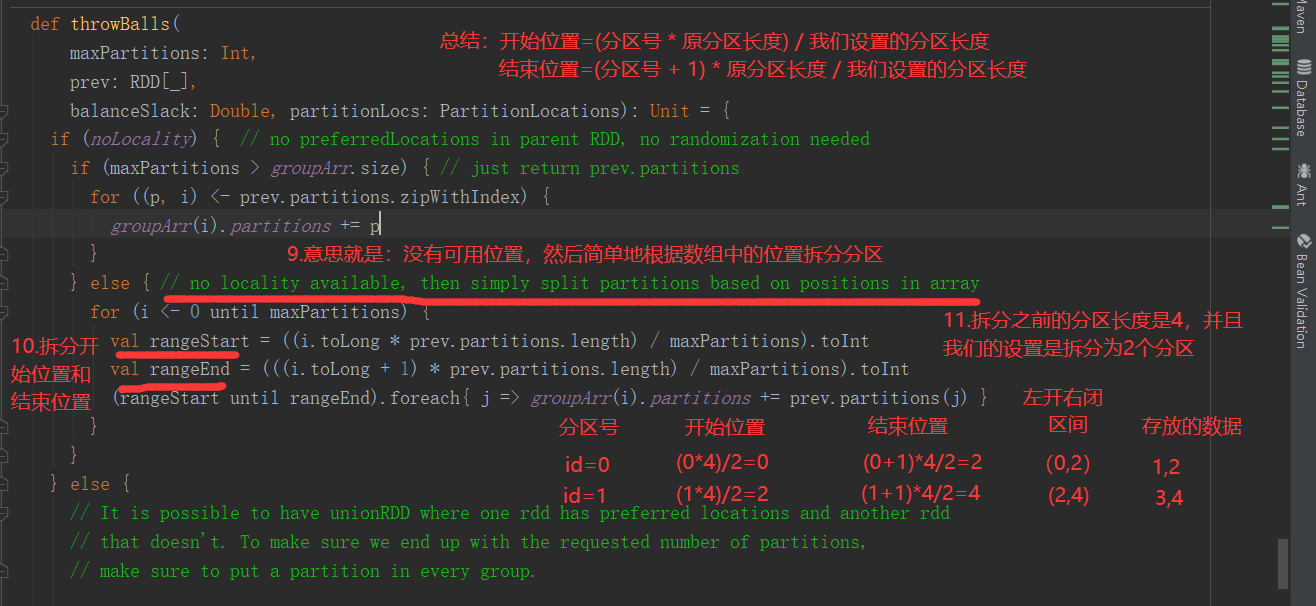
2.3.1.12 coalesce()合并分区
Coalesce算子包括:配置执行Shuffle和配置不执行Shuffle两种方式
1、不执行Shuffle方式
1)函数签名:
def coalesce(numPartitions: Int, shuffle: Boolean = false, //默认false不执行shuffle partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null) : RDD[T]
2)功能说明:缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。
3)需求:4个分区合并为2个分区
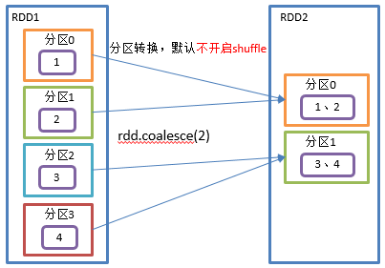
4)分区源码
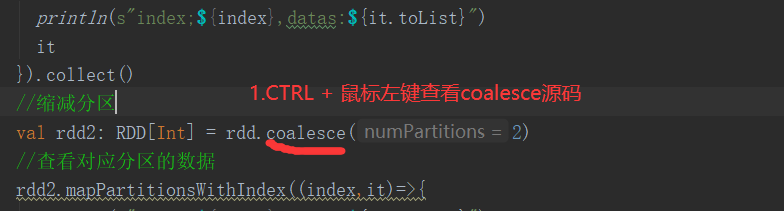
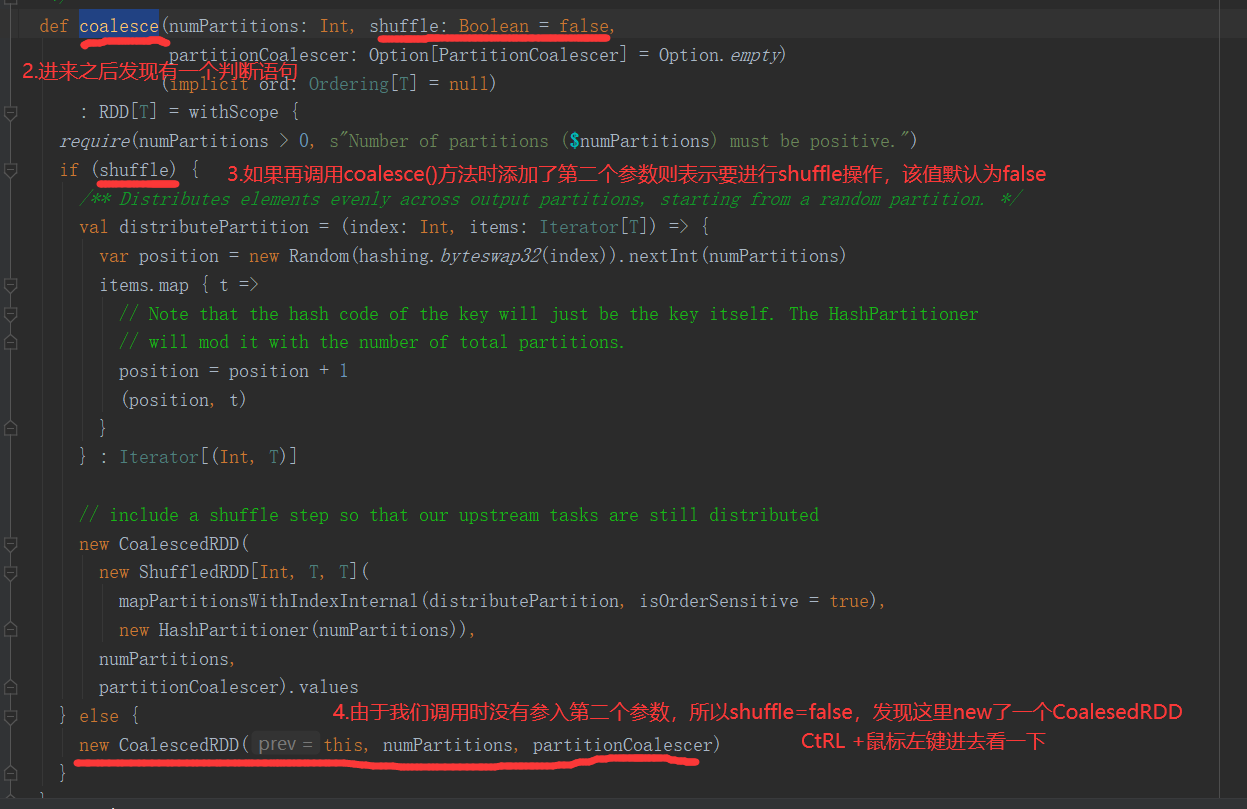
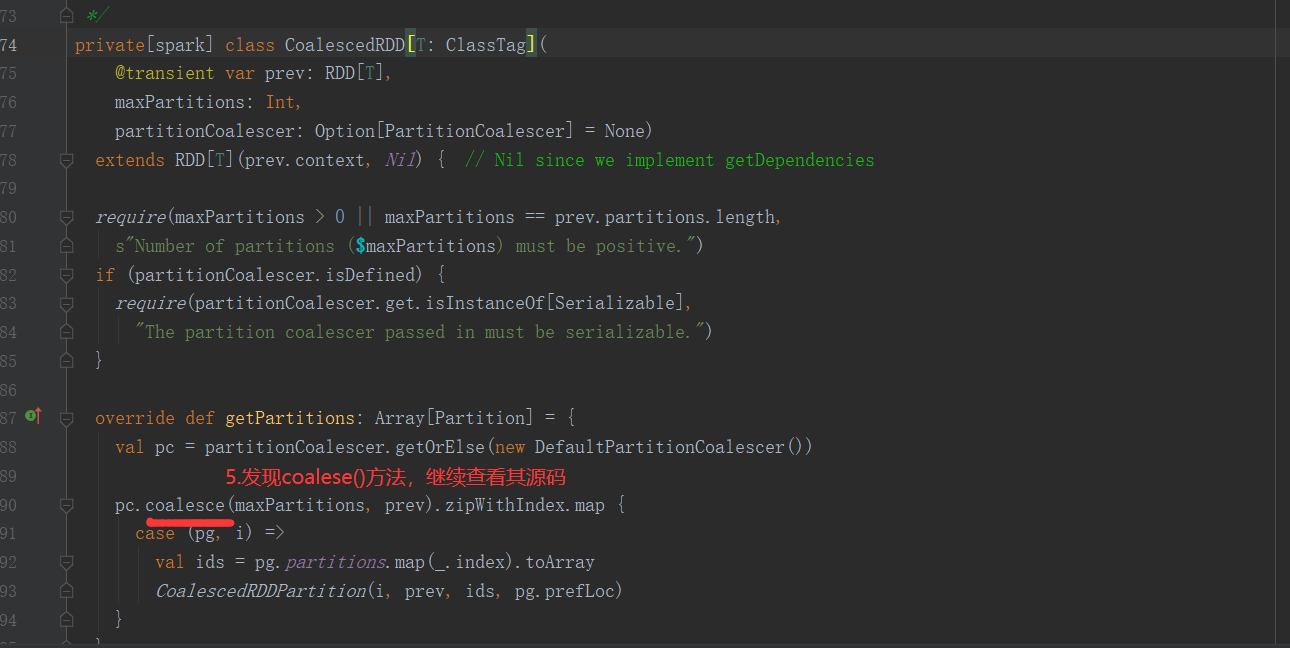
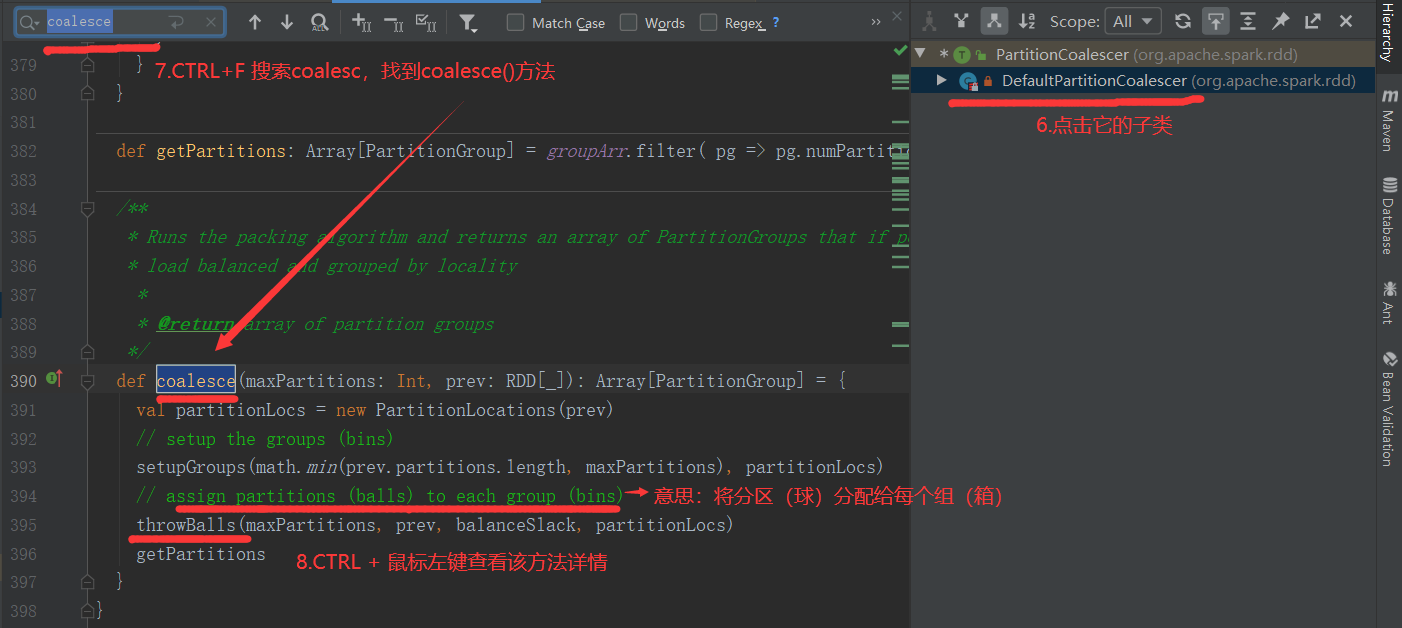
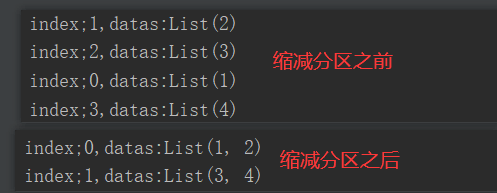
5)代码实现(未执行shuffle)
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCoalesce { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4),4) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index;${index},datas:${it.toList}") it }).collect() //缩减分区 val rdd2: RDD[Int] = rdd.coalesce(2) //查看对应分区的数据 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index;${index},datas:${it.toList}") it }).collect() //延迟一段时间,观察http://localhost:4040页面,查看Shuffle读写时间 Thread.sleep(100000) //关闭连接 sc.stop() } }
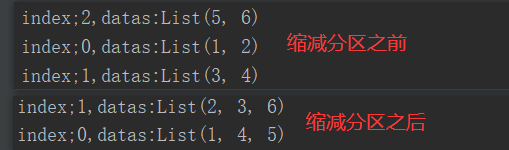
2、执行Shuffle方式
package com.yuange.spark.days03 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD object TestCoalesceTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,5,6),3) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index;${index},datas:${it.toList}") it }).collect() //缩减分区,执行shuffle val rdd2: RDD[Int] = rdd.coalesce(2,true) //查看对应分区的数据 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index;${index},datas:${it.toList}") it }).collect() //延迟一段时间,观察http://localhost:4040页面,查看Shuffle读写时间 Thread.sleep(100000) //关闭连接 sc.stop() } }
3、Shuffle原理
2.3.1.13 repartition()重新分区(执行Shuffle)
1)函数签名: def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
2)功能说明
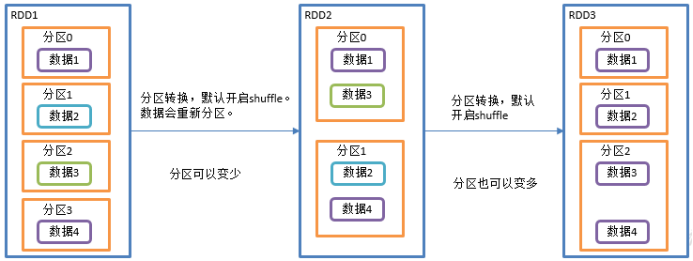
该操作内部其实执行的是coalesce操作,参数shuffle的默认值为true。无论是将分区数多的RDD转换为分区数少的RDD,还是将分区数少的RDD转换为分区数多的RDD,repartition操作都可以完成,因为无论如何都会经shuffle过程。
3)需求说明:创建一个4个分区的RDD,对其重新分区。
4)代码实现
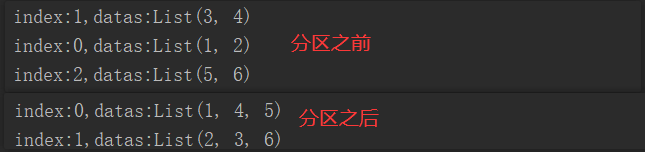
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestRepartition { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(Array(1,2,3,4,5,6),3) //分区之前:打印并查看数据 rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //缩减分区 // val rdd2: RDD[Int] = rdd.coalesce(2) //未执行shuffle操作 val rdd2: RDD[Int] = rdd.repartition(2) //执行shuffle操作 //分区之后:打印并查看数据 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //查看shuffle执行情况:http://localhost:4040 Thread.sleep(100000) //关闭连接 sc.stop() } }
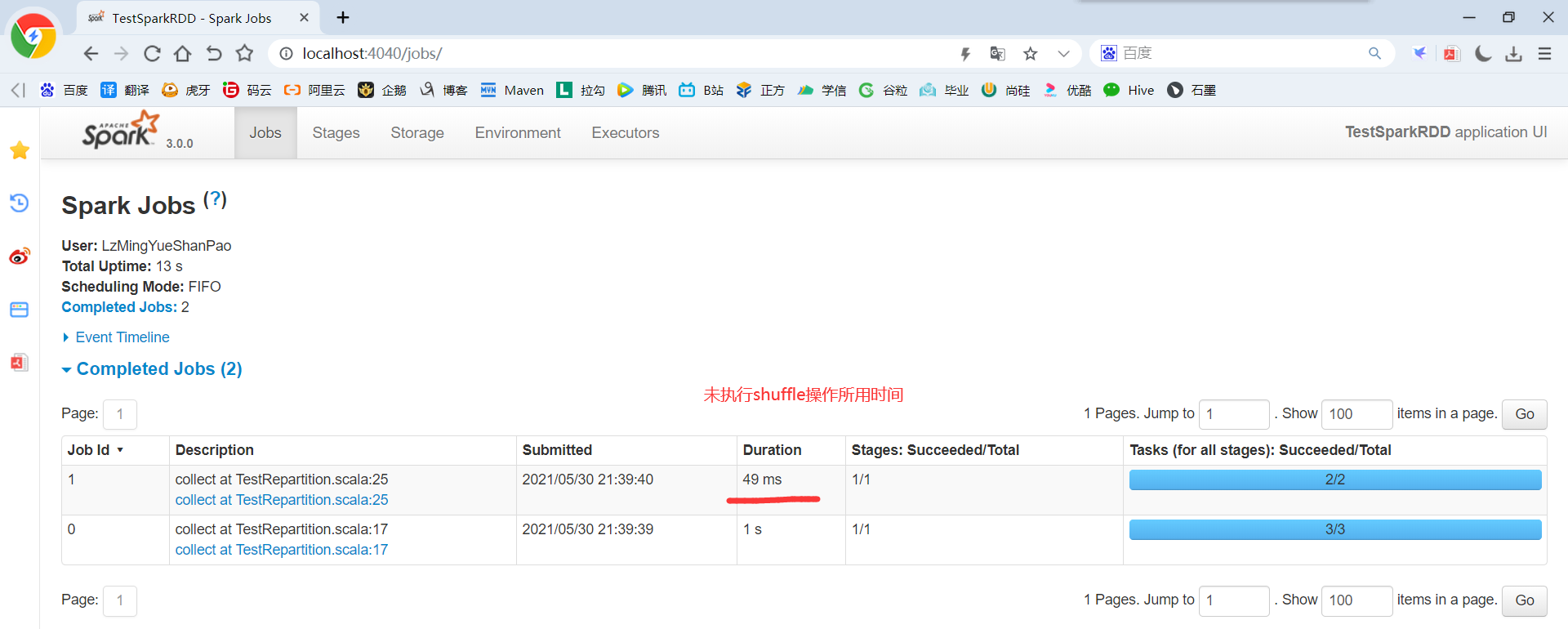
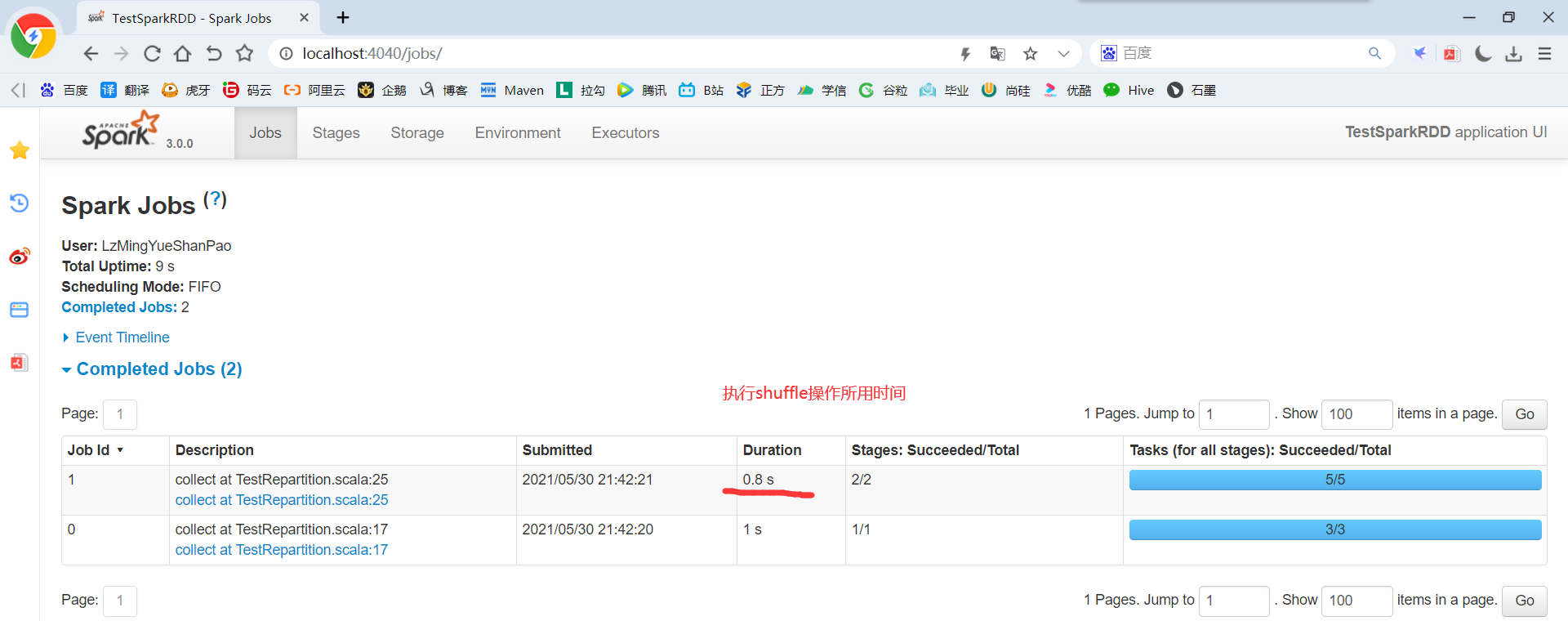
2.3.1.14 coalesce和repartition区别
1)coalesce重新分区,可以选择是否进行shuffle过程。由参数shuffle: Boolean = false/true决定。
2)repartition实际上是调用的coalesce,进行shuffle。源码如下:
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) }
3)coalesce一般为缩减分区,如果扩大分区,不使用shuffle是没有意义的,repartition扩大分区执行shuffle。
2.3.1.15 sortBy()排序
1)函数签名:
def sortBy[K]( f: (T) => K, ascending: Boolean = true, // 默认为正序排列 numPartitions: Int = this.partitions.length) (implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
2)功能说明
该操作用于排序数据。在排序之前,可以将数据通过f函数进行处理,之后按照f函数处理的结果进行排序,默认为正序排列。排序后新产生的RDD的分区数与原RDD的分区数一致。
3)需求说明:创建一个RDD,按照数字大小分别实现正序和倒序排序
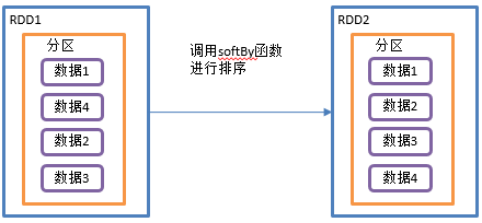
4)代码实现:
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSortBy { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(2,1,3,5,7,4,9)) //排序之前 rdd.collect().foreach(println) println("-"*100) //默认升序排序 rdd.sortBy(x=>x).collect().foreach(println) println("-"*100) //配置为倒序 rdd.sortBy(x=>x,false).collect().foreach(println) println("-"*100) //创建一个RDD val rdd2: RDD[String] = sc.makeRDD(List("12","13","10","8","9")) //按照字符的Int值排序 rdd2.sortBy(x=>x.toInt).collect().foreach(println) println("-"*100) //创建一个RDD val rdd3: RDD[(Int,Int)] = sc.makeRDD(List((1,3),(5,7),(2,9),(4,1))) //按照tuple的_1排序,如相同,则再按照tuple的_2排序 rdd3.sortBy(x=>x).collect().foreach(println) //关闭连接 sc.stop() } }
2.3.1.16 pipe()调用脚本(一个分区调用一次脚本)
1)函数签名: def pipe(command: String): RDD[String]
2)功能说明
管道,针对每个分区,都调用一次shell脚本,返回输出的RDD。
注意:在Worker节点可以访问到的位置脚本需要放
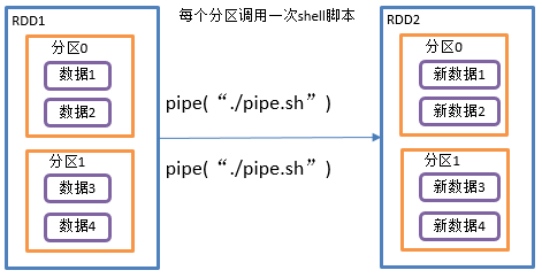
3)需求说明:编写一个脚本,使用管道将脚本作用于RDD上。
(1)编写一个脚本,并增加执行权限
vim /opt/module/spark-local/pipe.sh
#!/bin/bash echo "开始" while read LINE;do echo ">>>"${LINE} done
chmod +x /opt/module/spark-local/pipe.sh
(2)创建一个只有一个分区的RDD
bin/spark-shell
val rdd = sc.makeRDD (List("hi","Hello","how","are","you"), 1)
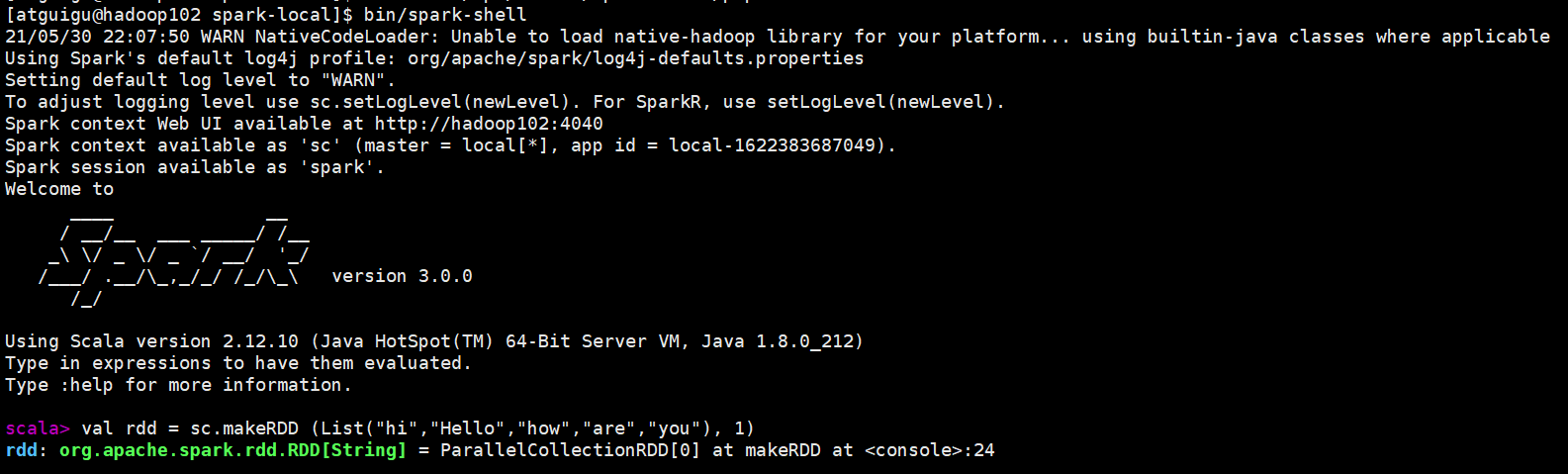
(3)将脚本作用该RDD并打印
rdd.pipe("/opt/module/spark-local/pipe.sh").collect()

(4)创建一个有两个分区的RDD
val rdd2 = sc.makeRDD(List("hi","Hello","how","are","you"), 2)

(5)将脚本作用该RDD并打印
rdd2.pipe("/opt/module/spark-local/pipe.sh").collect()

2.3.2 双Value类型交互
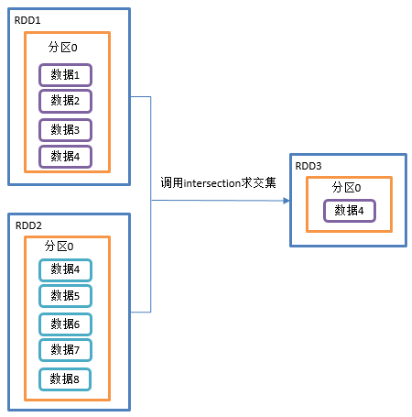
2.3.2.1 intersection()交集
1)函数签名:def intersection(other: RDD[T]): RDD[T]
2)功能说明:对源RDD和参数RDD求交集后返回一个新的RDD
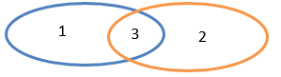
交集:只有3
3)需求说明:创建两个RDD,求两个RDD的交集
4)代码实现:
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestIntersection { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建第一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4) //创建第二个RDD val rdd2: RDD[Int] = sc.makeRDD(4 to 8) //计算交集并打印 rdd.intersection(rdd2).collect().foreach(println) //关闭连接 sc.stop() } }
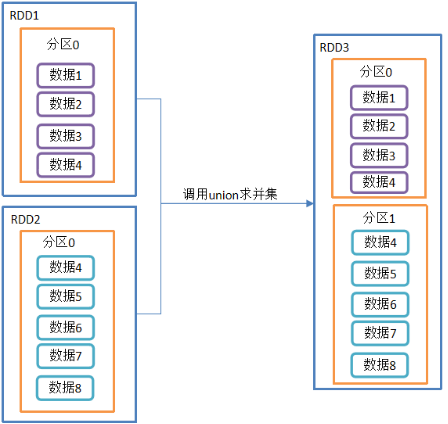
2.3.2.2 union()并集(没有shuffle操作)
1)函数签名:def union(other: RDD[T]): RDD[T]
2)功能说明:对源RDD和参数RDD求并集后返回一个新的RDD
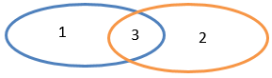
并集:1、2、3全包括
3)需求说明:创建两个RDD,求并集
4)代码实现:
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestUnion { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4) //创建一个RDD val rdd2: RDD[Int] = sc.makeRDD(4 to 8) //计算并集并打印 rdd.union(rdd2).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.2.3 subtract()差集(执行shuffle操作)
1)函数签名:def subtract(other: RDD[T]): RDD[T]
2)功能说明:计算差的一种函数,去除两个RDD中相同元素,不同的RDD将保留下来
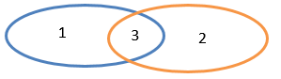
差集:只有1
3)需求说明:创建两个RDD,求第一个RDD与第二个RDD的差集
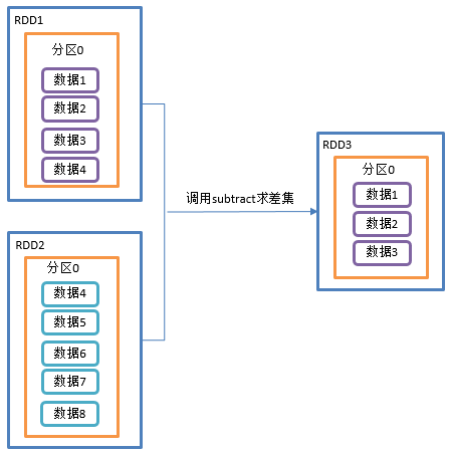
4)代码实现:
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSubtract { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4) //创建一个RDD val rdd2: RDD[Int] = sc.makeRDD(4 to 8) //计算差集并打印 rdd.subtract(rdd2).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.2.4 zip()拉链
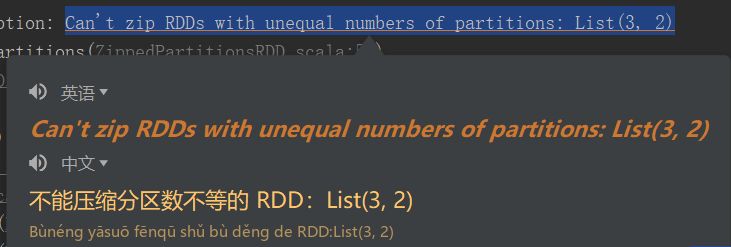
1)函数签名:def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]
2)功能说明:该操作可以将两个RDD中的元素,以键值对的形式进行合并。其中,键值对中的Key为第1个RDD中的元素,Value为第2个RDD中的元素。默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
3)需求说明:创建两个RDD,并将两个RDD组合到一起形成一个(k,v)RDD
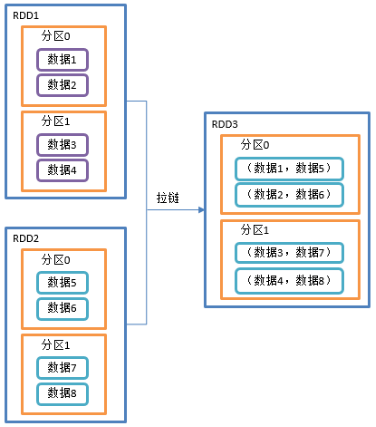
4)代码实现:
package com.yuange.spark.days03 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestZip { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(Array(12,13,14),3) //创建一个RDD val rdd2: RDD[String] = sc.makeRDD(Array("java","jdbc","mysql"),3) //组合并打印 rdd.zip(rdd2).collect().foreach(println) //再创建一个RDD val rdd3: RDD[String] = sc.makeRDD(Array("a","b"), 3) //元素个数不同,不能拉链 // rdd.zip(rdd3).collect().foreach(println) //error //创建第四个RDD(与1,2分区数不同) val rdd4: RDD[String] = sc.makeRDD(Array("a","b","c"), 2) //分区数不同,不能拉链 // rdd.zip(rdd4).collect().foreach(println) //error //关闭连接 sc.stop() } }


2.3.3 Key-Value类型
2.3.3.1 partitionBy()按照K重新分区
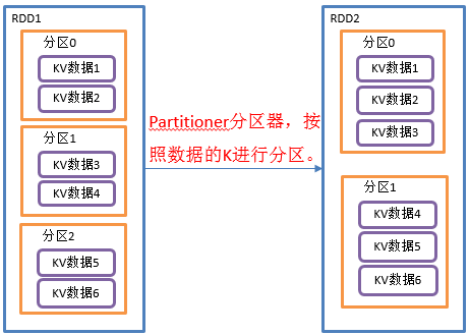
1)函数签名:def partitionBy(partitioner: Partitioner): RDD[(K, V)]
2)功能说明:将RDD[K,V]中的K按照指定Partitioner重新进行分区;如果原有的RDD和新的RDD是一致的话就不进行分区,否则会产生Shuffle过程。
3)需求说明:创建一个3个分区的RDD,对其重新分区
4)代码实现:
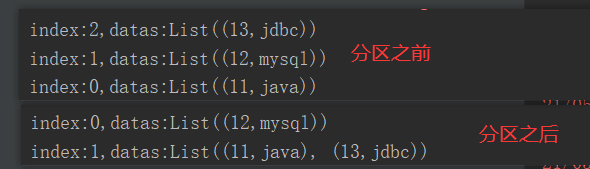
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object TestPartitionBy { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((11,"java"),(12,"mysql"),(13,"jdbc")),3) //打印数据 rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //重新分区 val rdd2: RDD[(Int,String)] = rdd.partitionBy(new HashPartitioner(2)) //打印数据 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect() //关闭连接 sc.stop() } }
2.3.3.2 自定义分区
1)HashPartitioner源码解读
/** * A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using * Java's `Object.hashCode`. * * Java arrays have hashCodes that are based on the arrays' identities rather than their contents, * so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will * produce an unexpected or incorrect result. */ class HashPartitioner(partitions: Int) extends Partitioner { require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.") def numPartitions: Int = partitions def getPartition(key: Any): Int = key match { case null => 0 case _ => Utils.nonNegativeMod(key.hashCode, numPartitions) } override def equals(other: Any): Boolean = other match { case h: HashPartitioner => h.numPartitions == numPartitions case _ => false } override def hashCode: Int = numPartitions }
2)自定义分区器,要实现自定义分区器,需要继承org.apache.spark.Partitioner类,并实现下面三个方法。
(1)numPartitions: Int:返回创建出来的分区数。
(2)getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。
(3)equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样Spark才可以判断两个RDD的分区方式是否相同
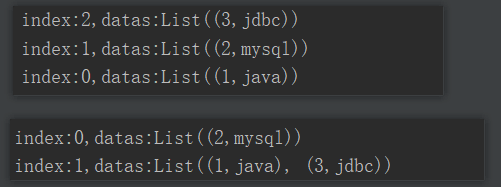
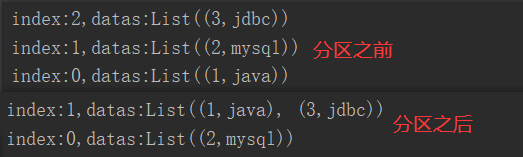
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} //自定义分区类,继承Partitioner class MyPartitioner(number: Int) extends Partitioner{ //设置分区数 var number2 = if (number < 2){ 2 }else{ this.number } override def numPartitions: Int = number2 //分区逻辑 override def getPartition(key: Any): Int = { if (key.isInstanceOf[Int]){ val keyInt: Int = key.asInstanceOf[Int] if (keyInt % 2 == 0){ //将数据放在0号分区 0 }else{ //将数据放在1号分区 1 } }else{ //将数据放在0号分区 0 } } } object TestPartitionByTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((1,"java"),(2,"mysql"),(3,"jdbc")),3) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect().foreach(println) //自定义分区 var rdd2: RDD[(Int,String)] = rdd.partitionBy(new MyPartitioner(2)) //打印 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect().foreach(println) //关闭连接 sc.stop() } }
2.3.3.3 reduceByKey()按照K聚合V(溢写磁盘时进行了类似于MR的Combiner预聚合,效率比 groupBy + map 更高)
1)函数签名:
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
2)功能说明:该操作可以将RDD[K,V]中的元素按照相同的K对V进行聚合。其存在多种重载形式,还可以设置新RDD的分区数。
3)需求说明:统计单词出现次数
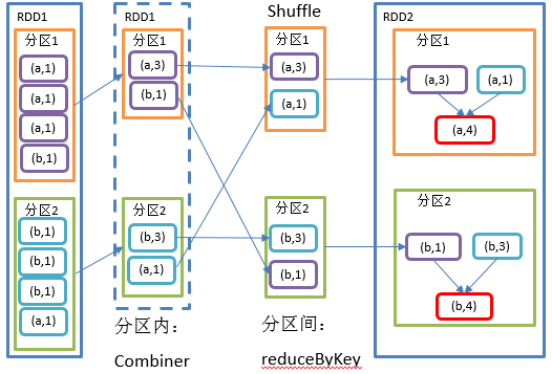
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestReduceByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2))) //计算key对应的value相加的结果 // val rdd2: RDD[(String,Int)] = rdd.reduceByKey((value1,value2) => value1 + value2) //前一个value与后一个value两两相加 val rdd2: RDD[(String,Int)] = rdd.reduceByKey(_ + _) //打印 rdd2.collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.4 groupByKey()按照K重新分组
1)函数签名:def groupByKey(): RDD[(K, Iterable[V])]
2)功能说明:groupByKey对每个key进行操作,但只生成一个seq,并不进行聚合,该操作可以指定分区器或者分区数(默认使用HashPartitioner)
3)需求说明:统计单词出现次数(重画一下图)
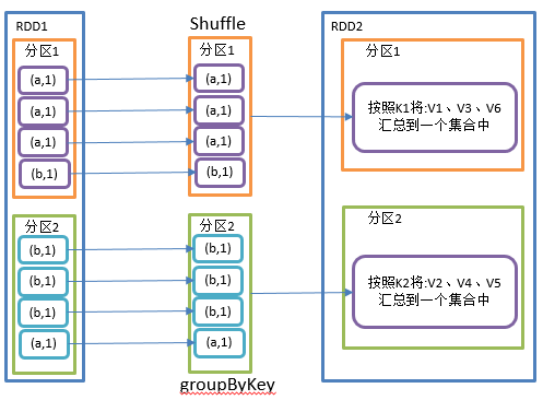
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestGroupByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a",1),("b",5),("a",5),("b",2))) //将相同的key聚集在一起,把value放入迭代器中 val rdd2: RDD[(String,Iterable[Int])] = rdd.groupByKey() //打印 rdd2.collect().foreach(println) //计算相同key的value相加后的值并打印 rdd2.map(x=>{ (x._1,x._2.sum) }).collect().foreach(println) //关闭连接 sc.stop() } }
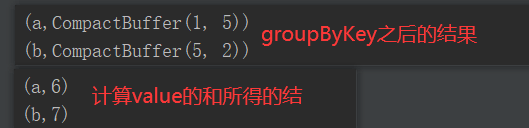
2.3.3.5 reduceByKey和groupByKey区别
1)reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[K,V]。
2)groupByKey:按照key进行分组,直接进行shuffle。
3)开发指导:在不影响业务逻辑的前提下,优先选用reduceByKey。求和操作不影响业务逻辑,求平均值影响业务逻辑。
2.3.3.6 aggregateByKey()按照K处理分区内和分区间逻辑
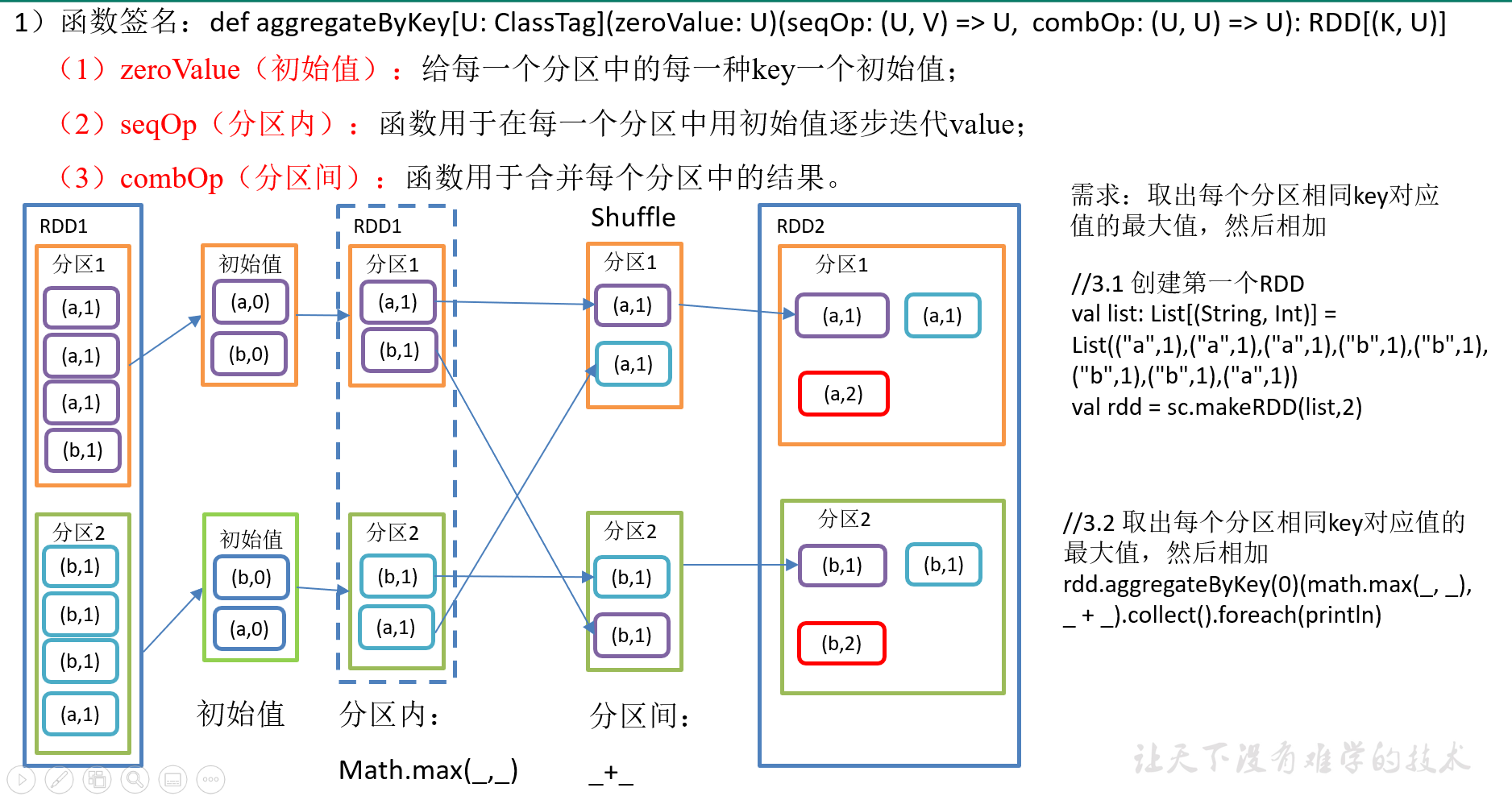
2)需求分析
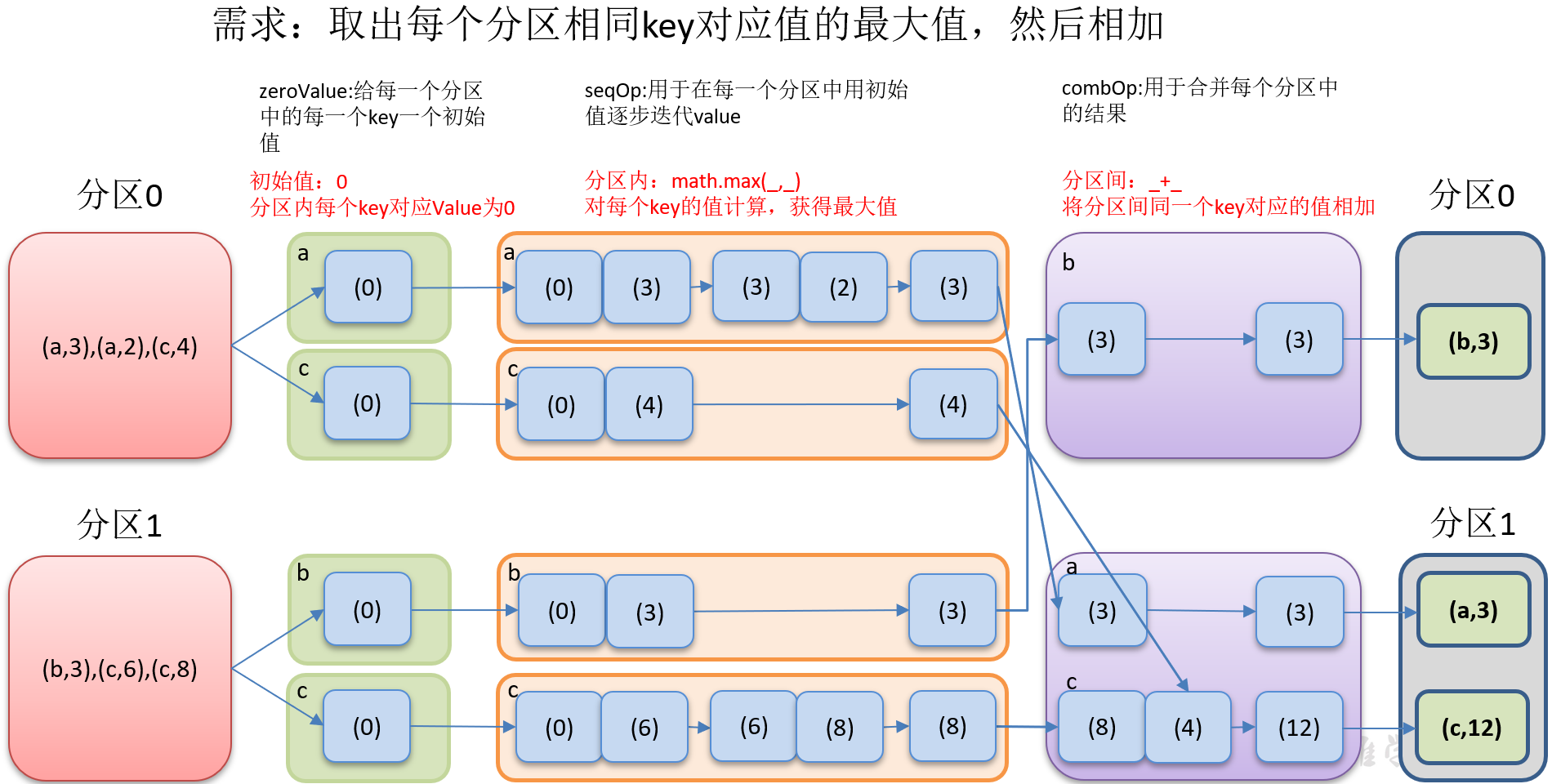
3)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestAggregateByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a", 3), ("a", 2), ("c", 4), ("b", 3), ("c", 6), ("c", 8)), 2) //取出每个分区相同Key的最大值,然后相加 rdd.aggregateByKey(0)(Math.max(_,_),_+_).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.7 foldByKey()分区内和分区间相同的aggregateByKey()
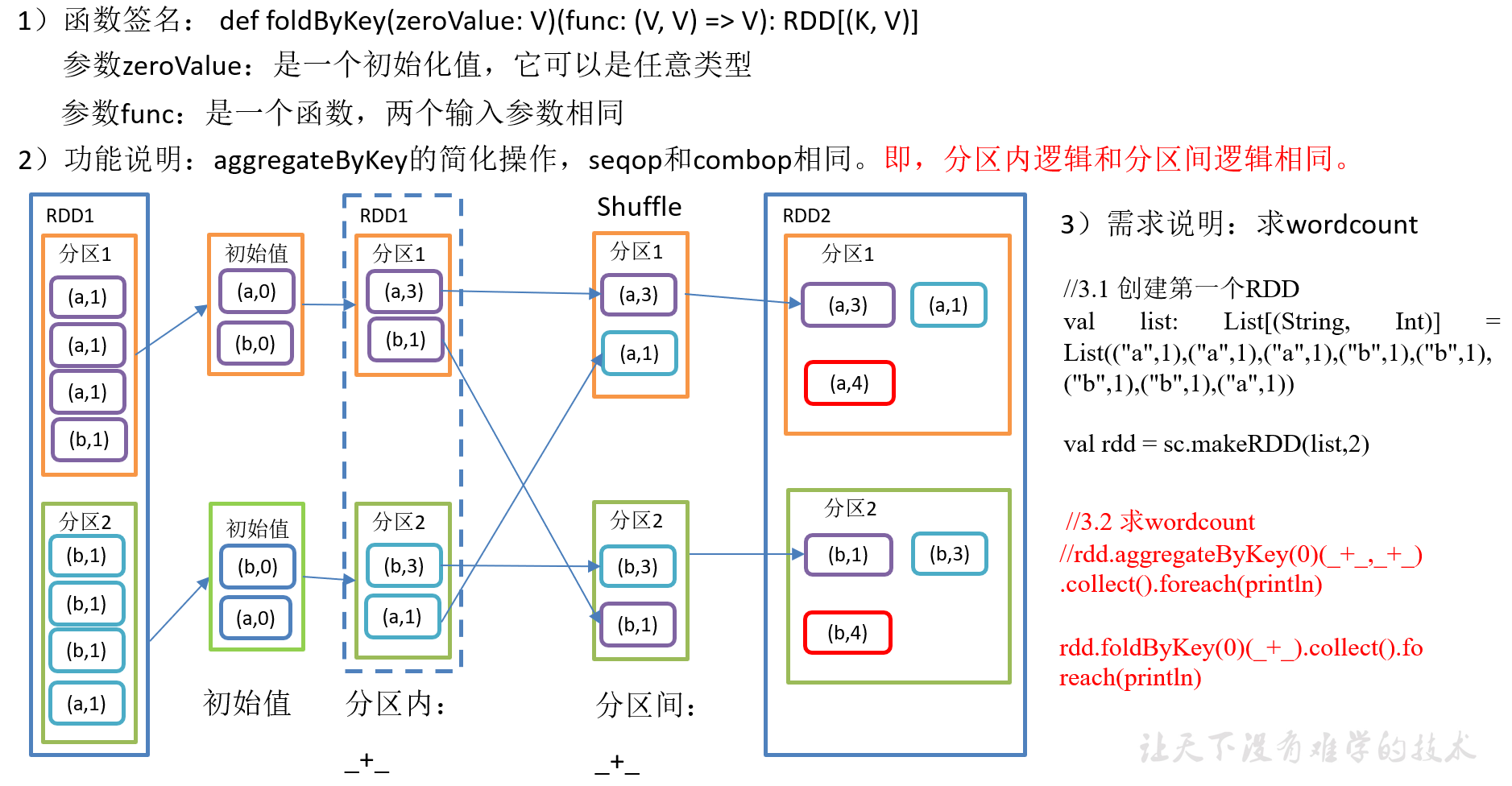
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestFoldByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a",1),("a",1),("a",1),("b",1),("b",1),("b",1),("b",1),("a",1)),2) //求wordCount并打印 // rdd.aggregateByKey(0)(_+_,_+_).collect().foreach(println) rdd.foldByKey(0)(_+_).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.8 combineByKey()转换结构后分区内和分区间操作
1)函数签名:
def combineByKey[C]( createCombiner: V => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDD[(K, C)]
(1)createCombiner(转换数据的结构): combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值
(2)mergeValue(分区内): 如果这是一个在处理当前分区之前已经遇到的键,它会使用mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并
(3)mergeCombiners(分区间): 由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的mergeCombiners()方法将各个分区的结果进行合并。
2)功能说明:针对相同K,将V合并成一个集合。
3)需求说明:创建一个pairRDD,根据key计算每种key的均值。(先计算每个key出现的次数以及可以对应值的总和,再相除得到结果)
4)需求分析:
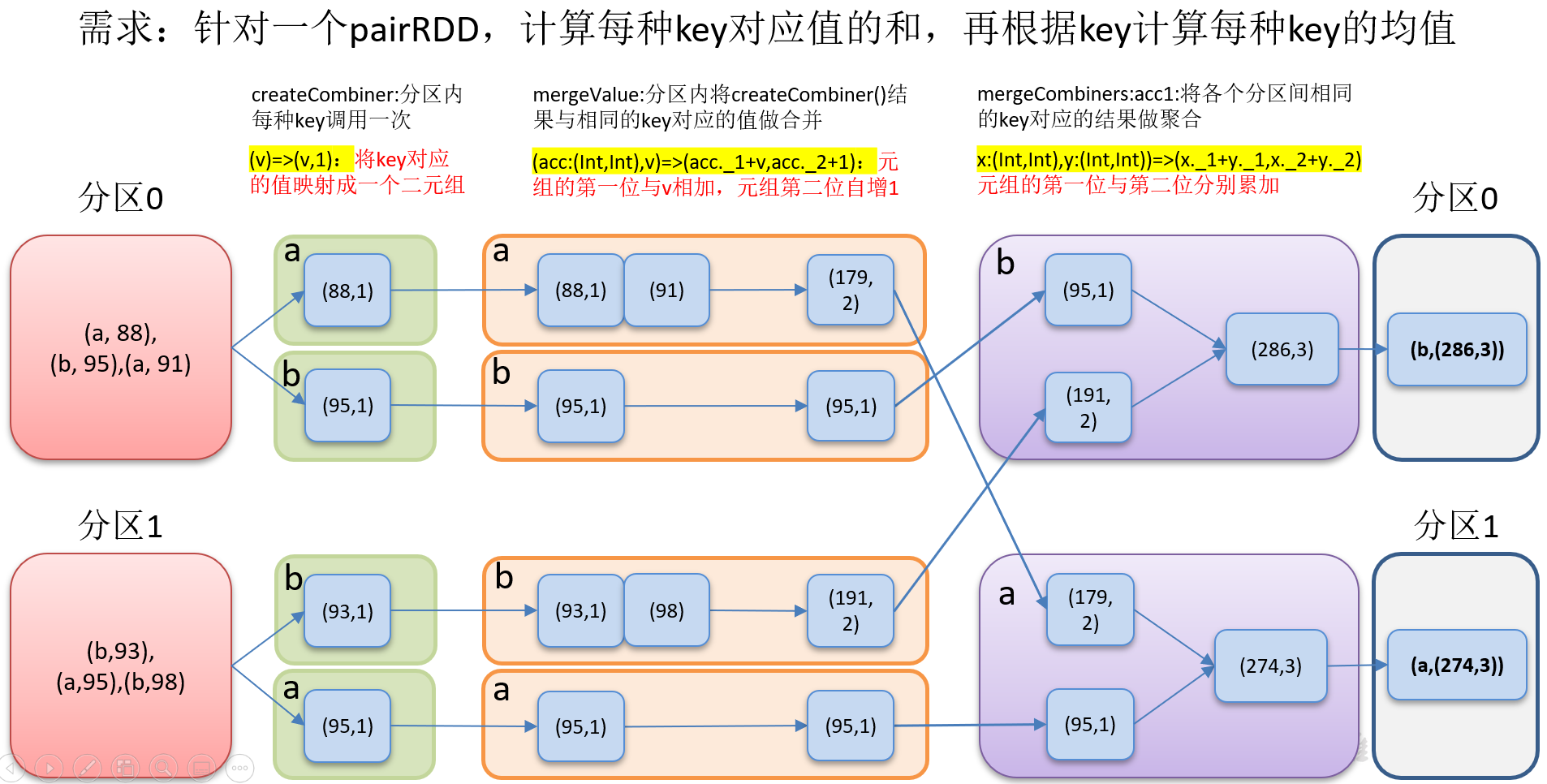
5)代码实现
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCombineByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.makeRDD(List(("a", 88), ("b", 95), ("a", 91), ("b", 93), ("a", 95), ("b", 98))) //将相同的key对应的值相加,同时记录该key出现的次数,放入一个二元元组 val rdd2: RDD[(String,(Int,Int))] = rdd.combineByKey( (_,1), (acc: (Int,Int),v) => (acc._1 + v,acc._2 + 1), (acc2: (Int,Int),acc3: (Int,Int)) => (acc2._1 + acc3._1, acc2._2 + acc3._2) ) //打印结果 rdd2.collect()foreach(println) //计算平均值 rdd2.map(x=>{ (x._1, x._2._1 / x._2._2.toDouble) }).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.9 reduceByKey、foldByKey、aggregateByKey、combineByKey

2.3.3.10 sortByKey()按照K进行排序
1)函数签名:
def sortByKey( ascending: Boolean = true, // 默认,升序 numPartitions: Int = self.partitions.length) : RDD[(K, V)]
2)功能说明:在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD
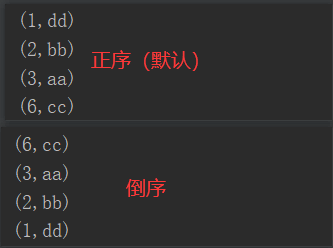
3)需求说明:创建一个pairRDD,按照key的正序和倒序进行排序
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSortByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd"))) //按照key的正序排序 rdd.sortByKey().collect().foreach(println) //按照key的倒序排序 rdd.sortByKey(false).collect().foreach(println) //关闭连接 sc.stop() } }
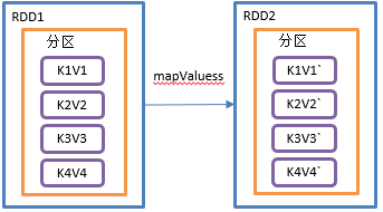
2.3.3.11 mapValues()只对V进行操作
1)函数签名:def mapValues[U](f: V => U): RDD[(K, U)]
2)功能说明:针对于(K,V)形式的类型只对V进行操作
3)需求说明:创建一个pairRDD,并将value添加字符串"|||"
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestMapValues { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((1, "a"), (1, "d"), (2, "b"), (3, "c"))) //对key的value值添加字符串"|||" // rdd.mapValues(v=>v + "|||").collect().foreach(println) rdd.mapValues(_ + "|||").collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.12 join()连接
1)函数签名:
def join[W](other: RDD[(K, W)]): RDD[(K, (V, W))]
def join[W](other: RDD[(K, W)], numPartitions: Int): RDD[(K, (V, W))]
2)功能说明:在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD
3)需求说明:创建两个pairRDD,并将key相同的数据聚合到一个元组。
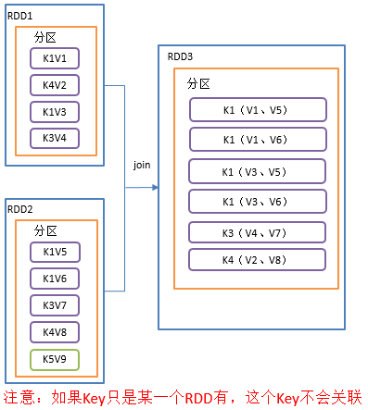
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestJoin { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((1, "a"), (2, "b"), (3, "c"))) //再创建一个RDD val rdd2: RDD[(Int,Int)] = sc.makeRDD(Array((1, 4), (2, 5), (4, 6))) //join并打印 rdd.join(rdd2).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.3.13 cogroup()类似全连接,但是在同一个RDD中对key聚合
1)函数签名:def cogroup[W](other: RDD[(K, W)]): RDD[(K, (Iterable[V], Iterable[W]))]
2)功能说明:在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD,操作两个RDD中的KV元素,每个RDD中相同key中的元素分别聚合成一个集合。
3)需求说明:创建两个pairRDD,并将key相同的数据聚合到一个迭代器。
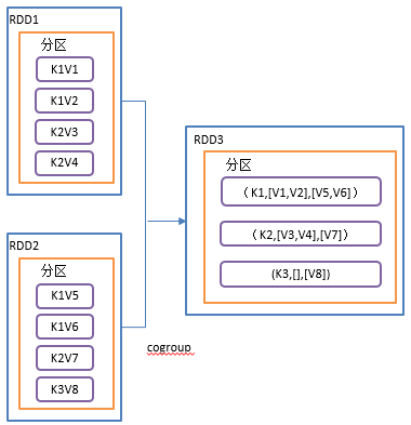
4)代码实现:
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCogroup { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((1,"a"),(2,"b"),(3,"c"))) //创建一个RDD val rdd2: RDD[(Int,Int)] = sc.makeRDD(Array((1,4),(2,5),(4,6))) //进行全连接并聚合 rdd.cogroup(rdd2).collect().foreach(println) //关闭连接 sc.stop() } }

2.3.4 案例实操(省份广告被点击Top3)
1)数据准备:时间戳,省份,城市,用户,广告,中间字段使用空格分割,下载链接(找到agent.log文件):https://pan.baidu.com/s/1pzEPLfug0hrh6ERdJa4GZA 提取码:fg2x
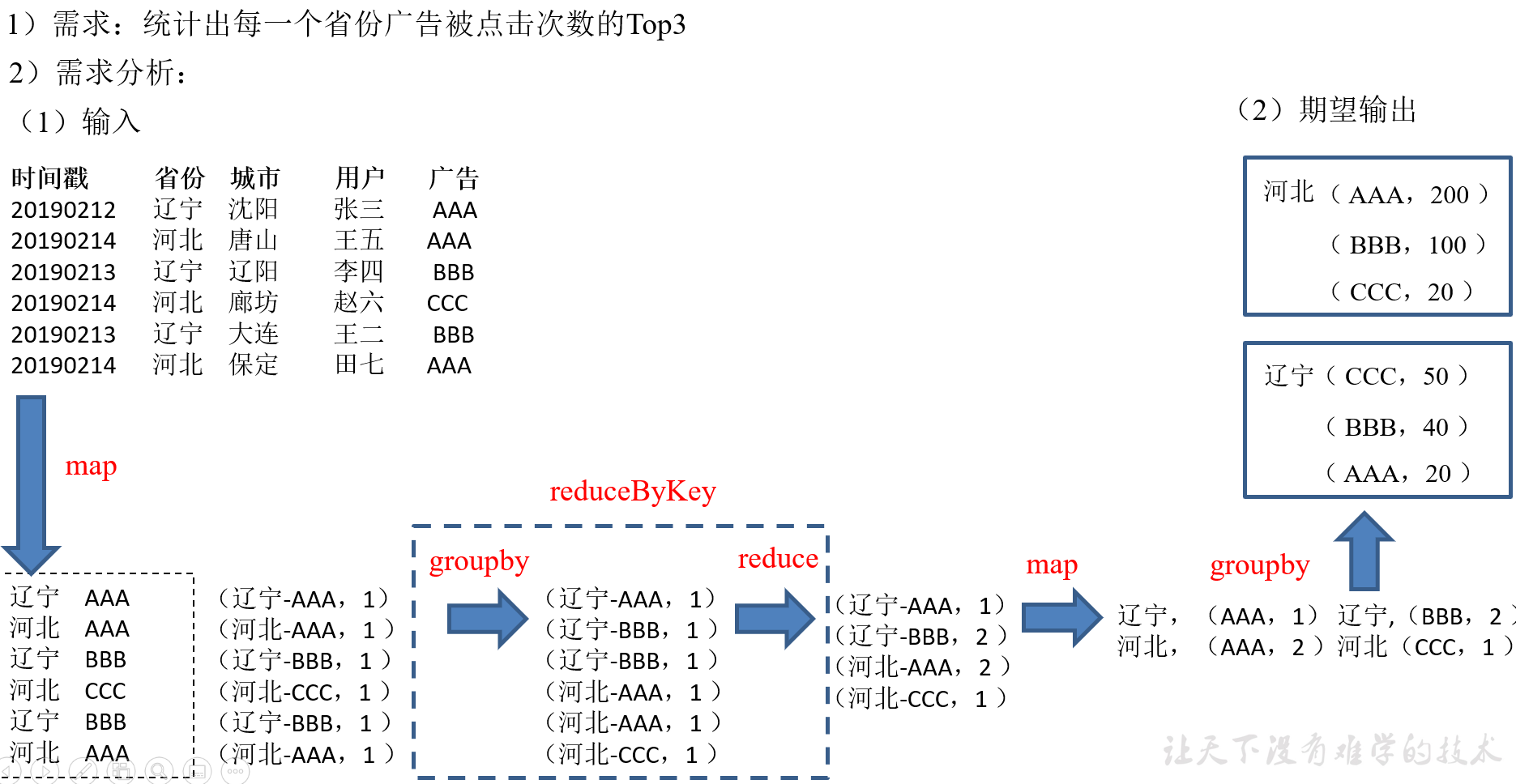
3)实现过程
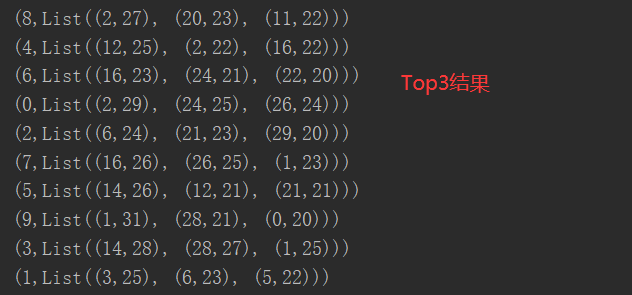
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestWordCountTopThree { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.textFile("datas/agent.log") var rdd2: RDD[(String,Int)] = rdd.map(x=>{ var arr: Array[String] = x.split(" ") (arr(1) + "-" + arr(4),1) }) //聚合 val rdd3: RDD[(String,Int)] = rdd2.reduceByKey(_ + _) //结构转换 var rdd4: RDD[(String,(String,Int))] = rdd3.map{ case (provinceAndUser,sum) => { val arr: Array[String] = provinceAndUser.split("-") (arr(0),(arr(1),sum)) } } //分组、排序(降序并且取前三) rdd4.groupByKey().map(x=>{ var arr = x._2.toList.sortBy(y=>{ y._2 }).reverse.take(3) (x._1,arr) }).collect().foreach(println) //关闭连接 sc.stop() } }
2.4 Action行动算子
行动算子是触发了整个作业的执行。因为转换算子都是懒加载,并不会立即执行
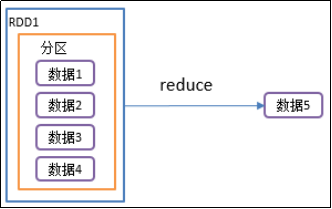
2.4.1 reduce()聚合
1)函数签名:def reduce(f: (T, T) => T): T
2)功能说明:f函数聚集RDD中的所有元素,先聚合分区内数据,再聚合分区间数据
3)需求说明:创建一个RDD,将所有元素聚合得到结果
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestReduce { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(2,4,6,7,9)) //聚合数据 println(rdd.reduce(_ + _)) //关闭连接 sc.stop() } }
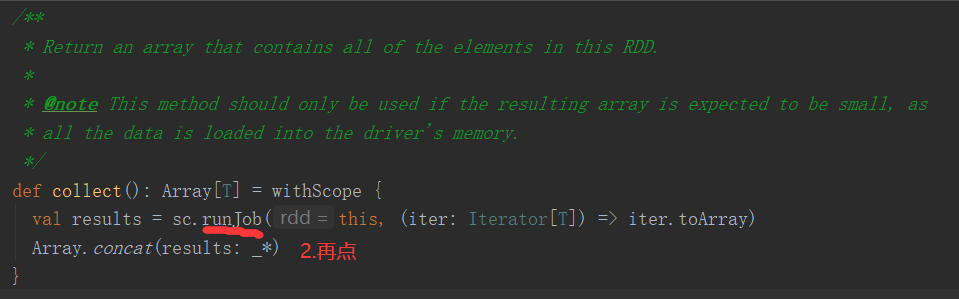
2.4.2 collect()以数组的形式返回数据集
1)函数签名:def collect(): Array[T]
2)功能说明:在驱动程序中,以数组Array的形式返回数据集的所有元素(所有的数据都会被拉取到Driver端,慎用)
3)需求说明:创建一个RDD,并将RDD内容收集到Driver端打印
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCollect { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(4,5,6,1,2)) //收集数据至Driver端并打印 rdd.collect().foreach(println) //关闭连接 sc.stop() } }
2.4.3 count()返回RDD中元素个数
1)函数签名:def count(): Long
2)功能说明:返回RDD中元素的个数
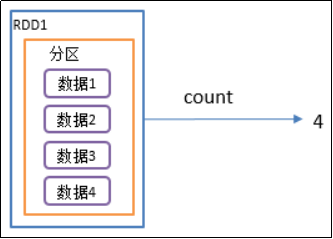
3)需求说明:创建一个RDD,统计该RDD的条数
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCount { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(2,4,6,9)) //统计rdd中数据个数 println(rdd.count()) //关闭连接 sc.stop() } }
2.4.4 first()返回RDD中的第一个元素
1)函数签名:def first(): T
2)功能说明:返回RDD中的第一个元素
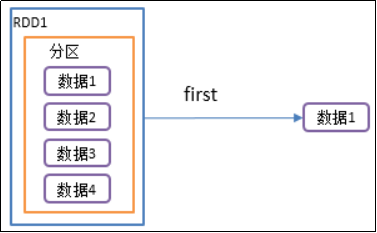
3)需求说明:创建一个RDD,返回该RDD中的第一个元素
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestFirst { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(11,12,13,15)) //取出RDD中的第一个元素 println(rdd.first()) //关闭连接 sc.stop() } }
2.4.5 take()返回由RDD前n个元素组成的数组
1)函数签名:def take(num: Int): Array[T]
2)功能说明:返回一个由RDD的前n个元素组成的数组
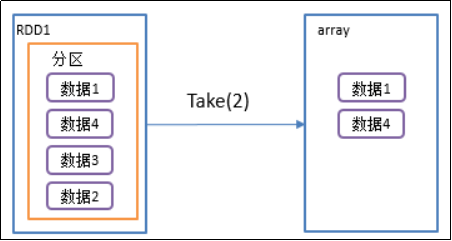
3)需求说明:创建一个RDD,统计该RDD的条数
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestTake { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(1,3,5,7,9,12,14)) //取前5个数据 println(rdd.take(5).mkString(",")) //关闭连接 sc.stop() } }
2.4.6 takeOrdered()返回该RDD排序后前n个元素组成的数组
1)函数签名:def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T]
2)功能说明:返回该RDD排序后的前n个元素组成的数组
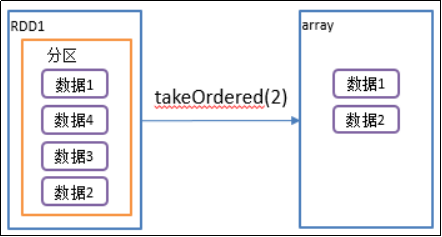
def takeOrdered(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope { ...... if (mapRDDs.partitions.length == 0) { Array.empty } else { mapRDDs.reduce { (queue1, queue2) => queue1 ++= queue2 queue1 }.toArray.sorted(ord) } }
3)需求说明:创建一个RDD,获取该RDD排序后的前2个元素
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestTakeOrdered { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(List(2,1,5,3,8,7)) //返回RDD中排完序中的前三个元素 println(rdd.takeOrdered(3).mkString(",")) //关闭连接 sc.stop() } }
2.4.7 aggregate()案例
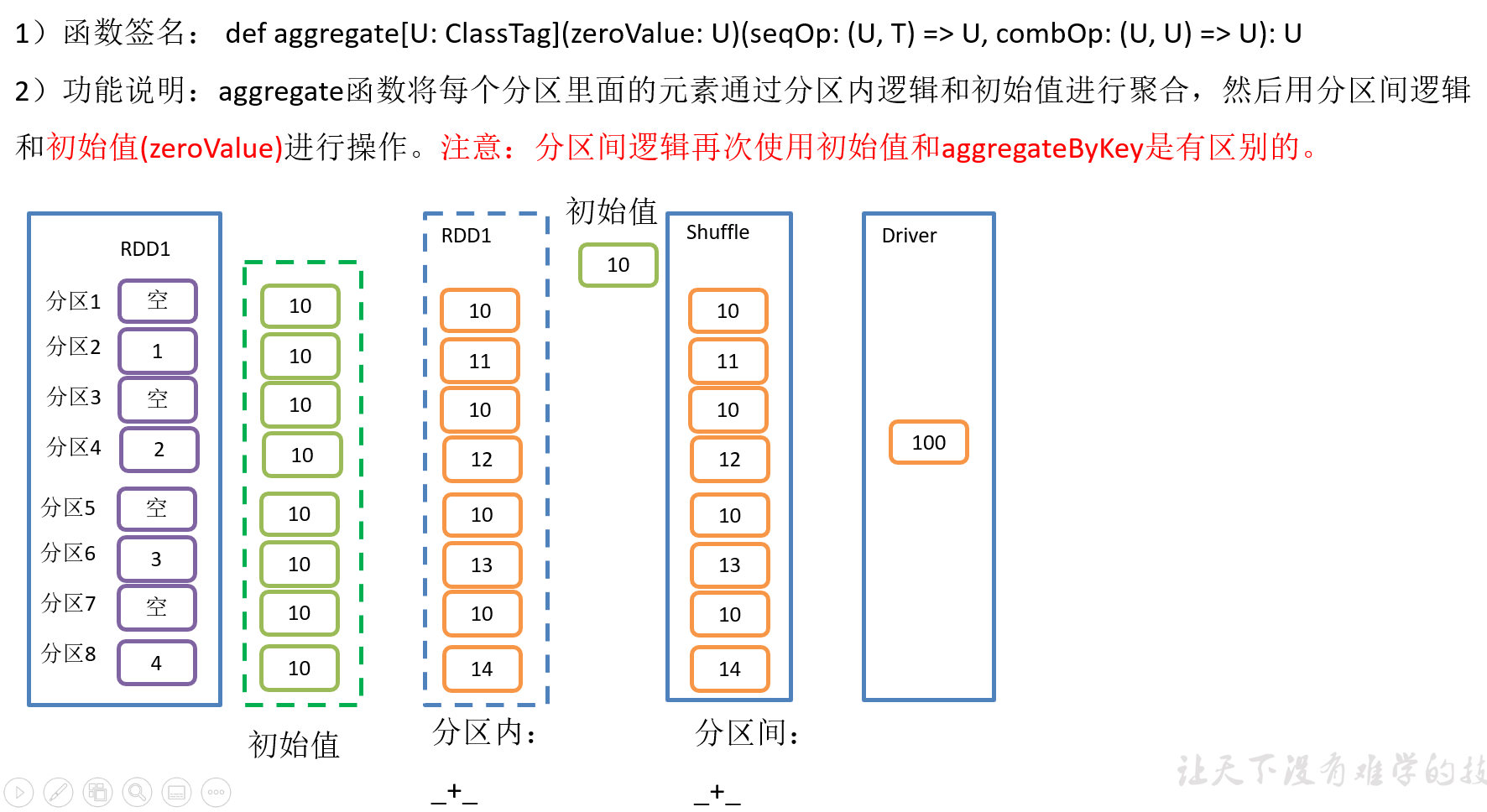
3)需求说明:创建一个RDD,将所有元素相加得到结果
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestAggregate { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.makeRDD(1 to 4,8) //将该RDD所有元素相加 // println(rdd.aggregate(0)(_ + _, _ + _)) println(rdd.aggregate(10)(_ + _, _ + _)) //关闭连接 sc.stop() } }
2.4.8 fold()案例
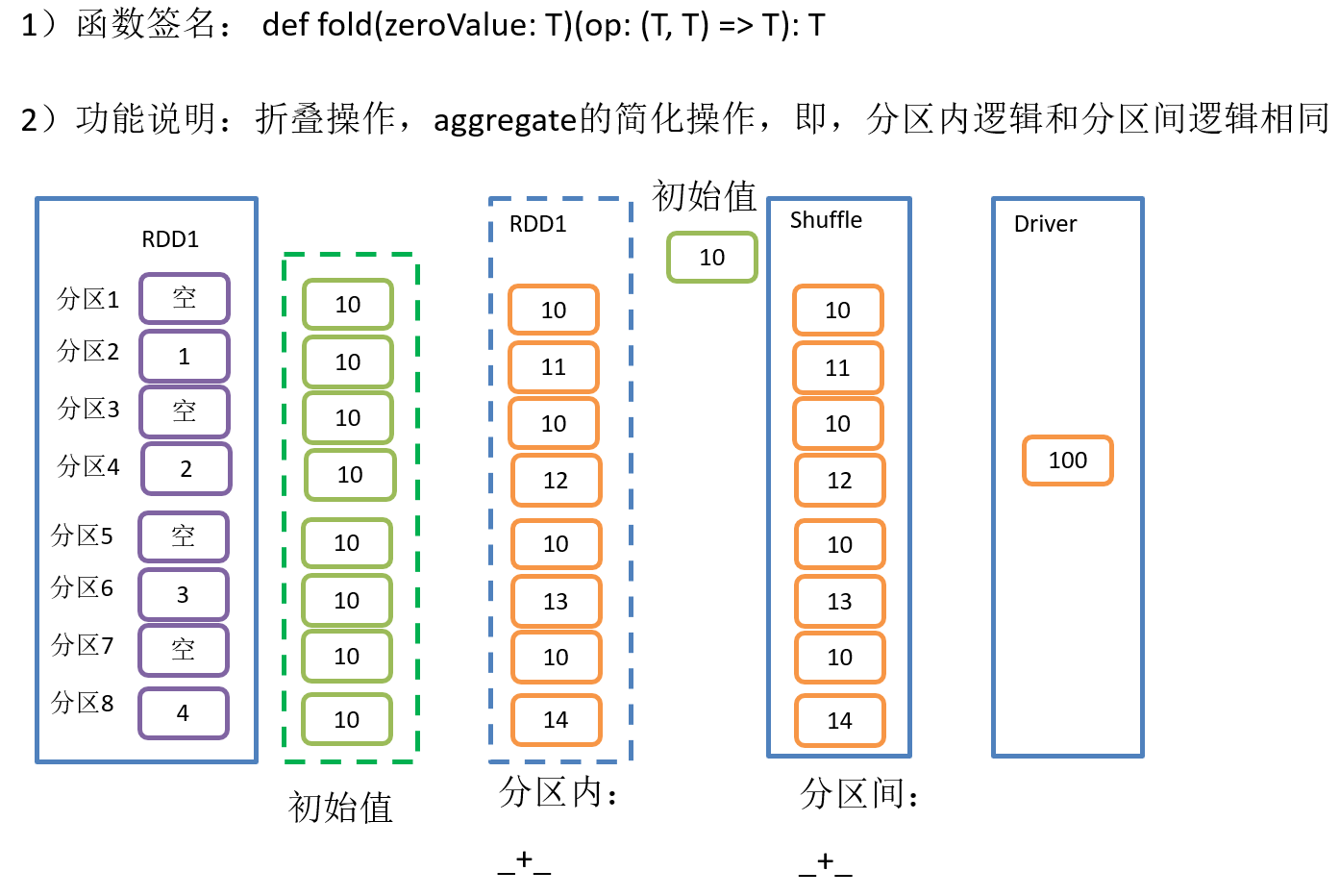
3)需求说明:创建一个RDD,将所有元素相加得到结果
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestFold { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.parallelize(1 to 4,8) //将RDD元素相加得到结果 // println(rdd.fold(0)(_ + _)) println(rdd.fold(10)(_ + _)) //关闭连接 sc.stop() } }
2.4.9 countByKey()统计每种key的个数
1)函数签名:def countByKey(): Map[K, Long]
2)功能说明:统计每种key的个数
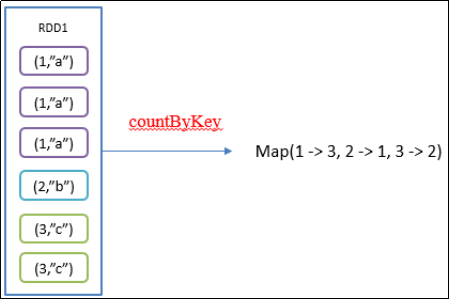
3)需求说明:创建一个PairRDD,统计每种key的个数
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCountByKey { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.parallelize(List((1, "a"), (1, "a"), (1, "a"), (2, "b"), (3, "c"), (3, "c"))) //统计每种key的数量 println(rdd.countByKey()) //关闭连接 sc.stop() } }

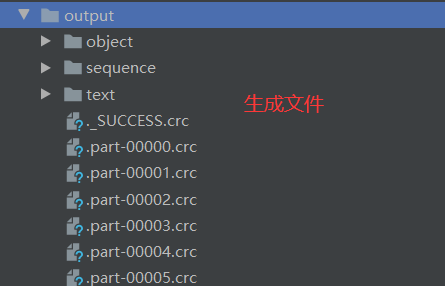
2.4.10 save相关算子
1)saveAsTextFile(path)保存成Text文件
(1)函数签名
/** * Save this RDD as a compressed text file, using string representations of elements. */ def saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): Unit = withScope { this.mapPartitions { iter => val text = new Text() iter.map { x => require(x != null, "text files do not allow null rows") text.set(x.toString) (NullWritable.get(), text) } }.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path, codec) }
(2)功能说明:将数据集的元素以textfile的形式保存到HDFS文件系统或者其他支持的文件系统,对于每个元素,Spark将会调用toString方法,将它装换为文件中的文本
2)saveAsSequenceFile(path) 保存成Sequencefile文件(只有kv类型RDD有该操作,单值的没有)
(1)函数签名
def saveAsSequenceFile(path: String,codec: Option[Class[_ <: CompressionCodec]] = None)
(2)功能说明:将数据集中的元素以Hadoop Sequencefile的格式保存到指定的目录下,可以使HDFS或者其他Hadoop支持的文件系统。
3)saveAsObjectFile(path) 序列化成对象保存到文件
(1)函数签名
/** * Save this RDD as a SequenceFile of serialized objects. */ def saveAsObjectFile(path: String): Unit = withScope { this.mapPartitions(iter => iter.grouped(10).map(_.toArray)) .map(x => (NullWritable.get(), new BytesWritable(Utils.serialize(x)))) .saveAsSequenceFile(path) }
(2)功能说明:用于将RDD中的元素序列化成对象,存储到文件中。
4)代码实现
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSave { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.parallelize(1 to 4,2) //保存为Text文件 rdd.saveAsTextFile("output/text") //保存为Sequencefile文件 rdd.map((_,1)).saveAsSequenceFile("output/sequence") //保存序列化对象至文件 rdd.saveAsObjectFile("output/object") //关闭连接 sc.stop() } }
2.4.11 foreach(f)遍历RDD中每一个元素
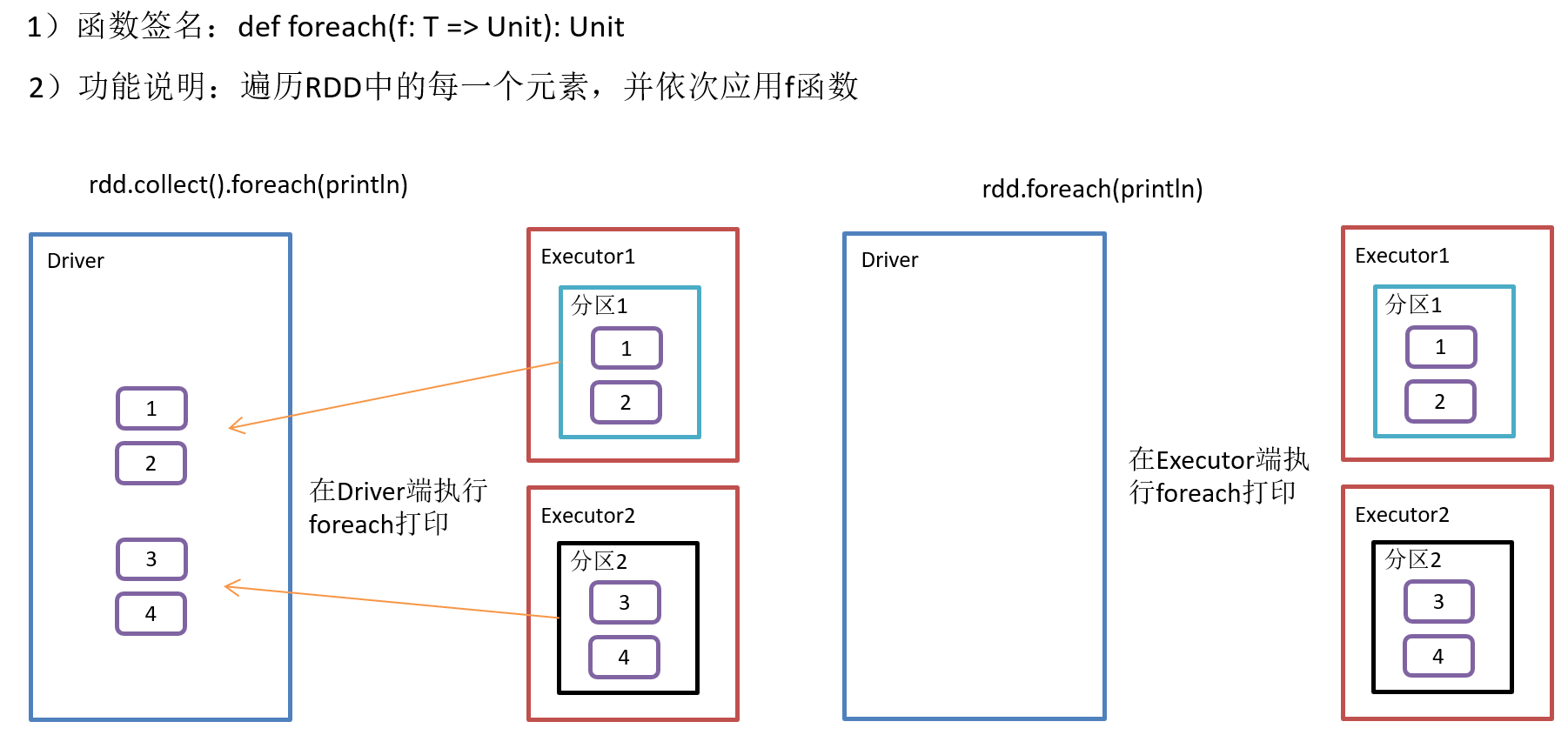
3)需求说明:创建一个RDD,对每个元素进行打印
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestForeach { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.parallelize(1 to 4,2) //打印:Driver端 rdd.collect().foreach(println) //打印:Executor端 rdd.foreach(println) //关闭连接 sc.stop() } }
2.5 RDD序列化
在实际开发中我们往往需要自己定义一些对于RDD的操作,那么此时需要注意的是,初始化工作是在Driver端进行的,而实际运行程序是在Executor端进行的,这就涉及到了跨进程通信,是需要序列化的。下面我们看几个例子:
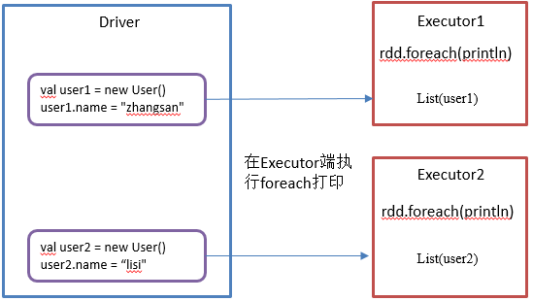
2.5.1 闭包检查
1)闭包引入(有闭包就需要进行序列化)
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} class User extends Serializable{ var name: String = _ } object TestObject { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val user = new User() user.name = "zhangsan" val user2 = new User() user2.name = "lisi" val list: RDD[User] = sc.parallelize(List(user,user2)) list.foreach(user=>{ println(user.name) }) //关闭连接 sc.stop() } }
2.5.2 序列化方法和属性
1)说明
Driver:算子以外的代码都是在Driver端执行
Executor:算子里面的代码都是在Executor端执行
2)代码实现
package com.yuange.spark.day05 import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD class Search(query: String) extends Serializable{ def isMatch(s: String): Boolean = { s.contains(query) } //函数序列化 def getMatch2(rdd: RDD[String]): RDD[String] = { rdd.filter(isMatch) } //属性序列化 def getMatch3(rdd: RDD[String]): RDD[String] = { rdd.filter(x => { x.contains(query) }) } } object TestFunction { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.parallelize(Array("hello world", "hello spark", "hive", "atguigu")) val search = new Search("hello") //函数传递 search.getMatch2(rdd).collect().foreach(println) //属性传递 search.getMatch3(rdd).collect().foreach(println) //关闭连接 sc.stop() } }
3)问题一说明
//过滤出包含字符串的RDD def getMatch1 (rdd: RDD[String]): RDD[String] = { rdd.filter(isMatch) }
(1)在这个方法中所调用的方法isMatch()是定义在Search这个类中的,实际上调用的是this. isMatch(),this表示Search这个类的对象,程序在运行过程中需要将Search对象序列化以后传递到Executor端。
(2)解决方案:类继承scala.Serializable即可
class Search() extends Serializable{...}
4)问题二说明
//过滤出包含字符串的RDD def getMatche2(rdd: RDD[String]): RDD[String] = { rdd.filter(x => x.contains(query)) }
(1)在这个方法中所调用的方法query是定义在Search这个类中的字段,实际上调用的是this. query,this表示Search这个类的对象,程序在运行过程中需要将Search对象序列化以后传递到Executor端。
(2)解决方案一
(a)类继承scala.Serializable即可
class Search() extends Serializable{...}
(b)将类变量query赋值给局部变量
//修改getMatche2为 //过滤出包含字符串的RDD def getMatche2(rdd: RDD[String]): RDD[String] = { val q = this.query//将类变量赋值给局部变量 rdd.filter(x => x.contains(q)) }
(3)解决方案二
//把Search类变成样例类,样例类默认是序列化的。 case class Search(query:String) {...}
2.5.3 Kryo序列化框架
参考地址: https://github.com/EsotericSoftware/kryo
Java的序列化能够序列化任何的类。但是比较重,序列化后对象的体积也比较大。
Spark出于性能的考虑,Spark2.0开始支持另外一种Kryo序列化机制。Kryo速度是Serializable的10倍。当RDD在Shuffle数据的时候,简单数据类型、数组和字符串类型已经在Spark内部使用Kryo来序列化(即使使用Kryo序列化,也要继承Serializable接口)
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} case class Searche(val query: String){ def isMatch(s: String) = { s.contains(query) } def getMatchedRDD(rdd: RDD[String]) = { rdd.filter(isMatch) } def getMatchedRDD2(rdd: RDD[String]) = { val q = query rdd.filter(_.contains(q)) } } object TestKryo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //替换默认的序列化机制 .set("spark.serializer","org.apache.spark.serializer.KryoSerializer") //注册需要使用kryo序列化的自定义类 .registerKryoClasses(Array(classOf[Searche])) //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.parallelize(Array("hello world", "hello atguigu", "atguigu", "hahah"), 2) val searche = new Searche("hello") searche.getMatchedRDD(rdd).collect().foreach(println) //关闭连接 sc.stop() } }

2.6 RDD依赖关系
2.6.1 查看血缘关系
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
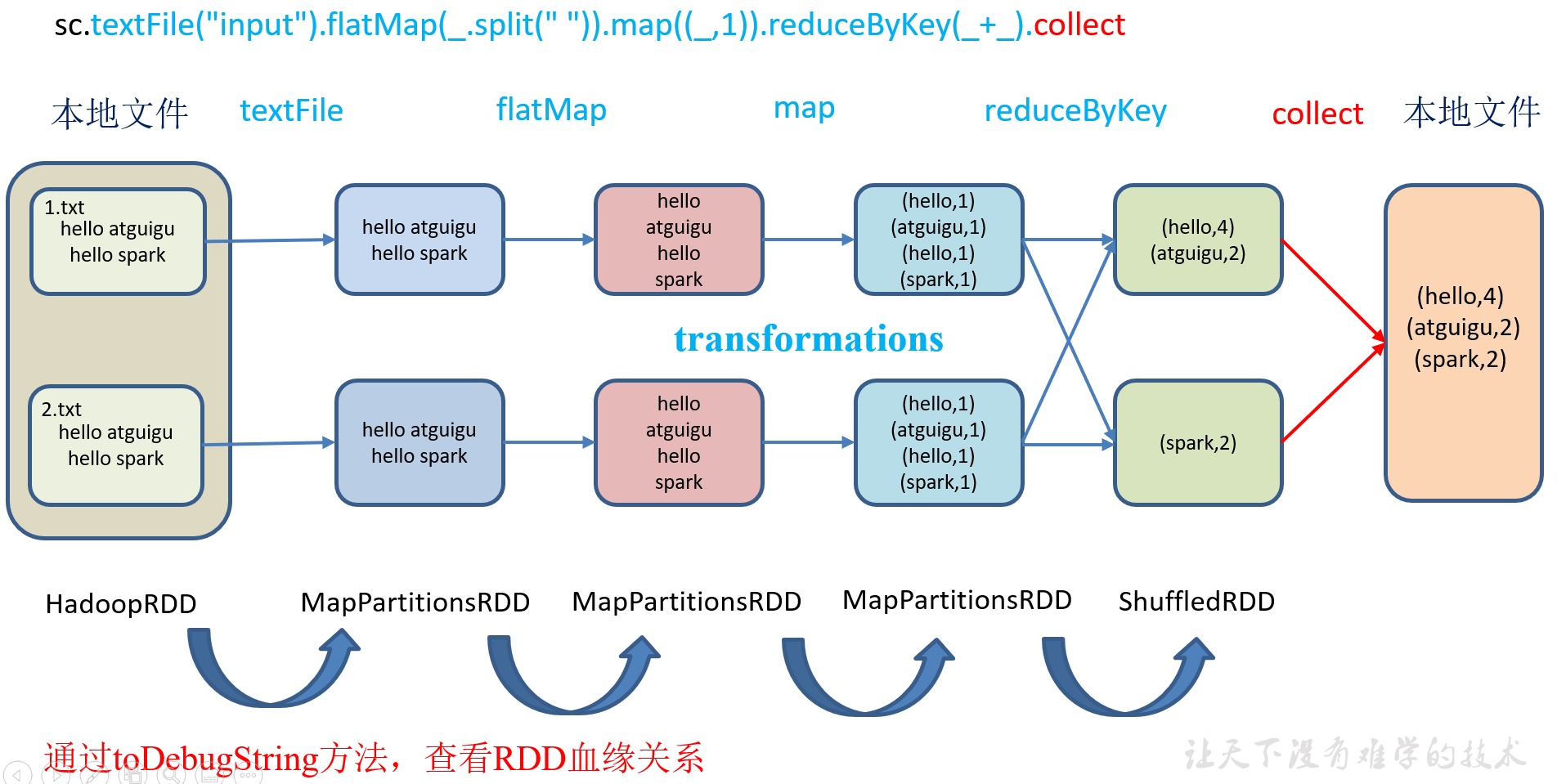
1)代码实现
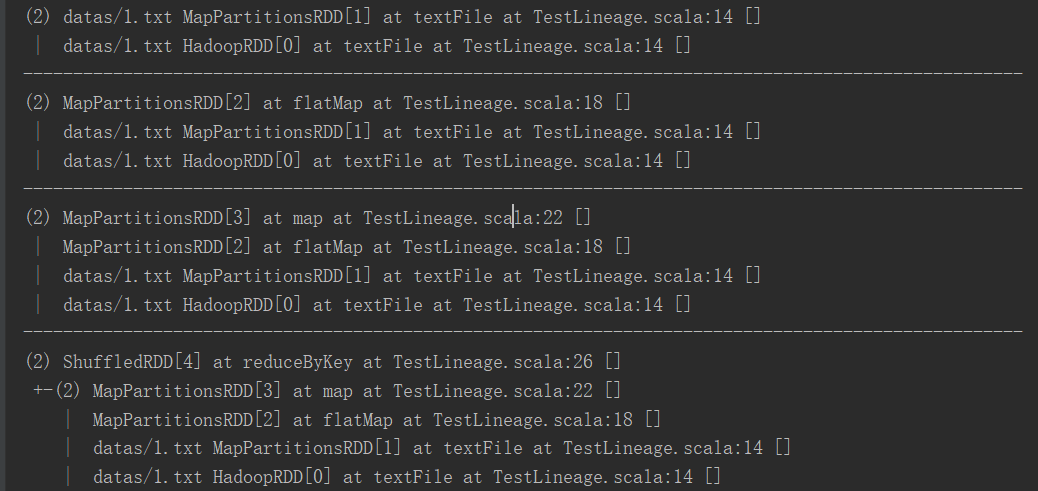
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestLineage { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.textFile("datas/1.txt") println(rdd.toDebugString) println("-"*100) val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) println(rdd2.toDebugString) println("-"*100) val rdd3: RDD[(String,Int)] = rdd2.map((_,1)) println(rdd3.toDebugString) println("-"*100) val rdd4: RDD[(String,Int)] = rdd3.reduceByKey(_ + _) println(rdd4.toDebugString) rdd4.collect() //关闭连接 sc.stop() } }
2)打印结果(圆括号中的数字表示RDD的并行度,也就是有几个分区)
2.6.2 查看依赖关系
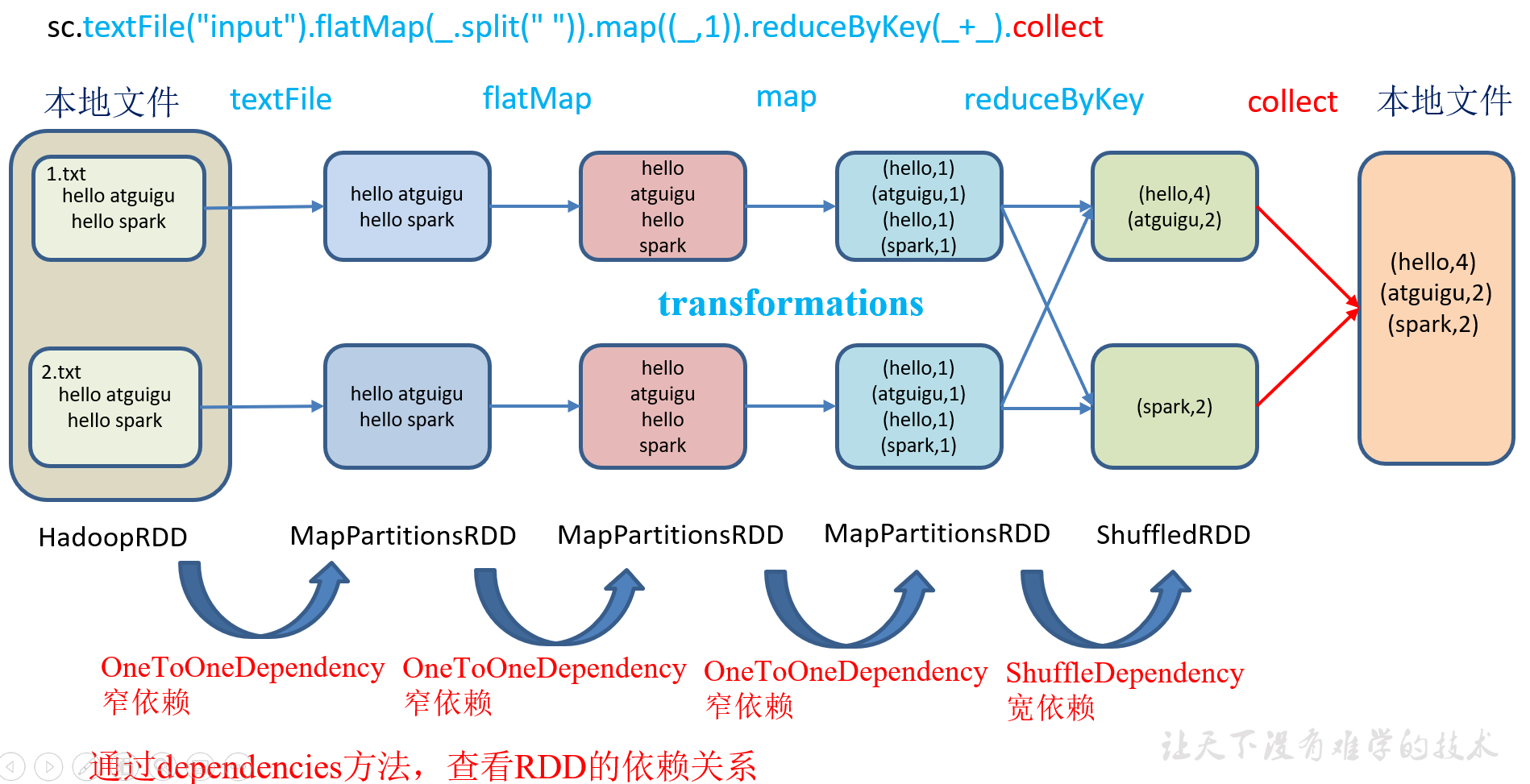
1)代码实现(要想理解RDDS是如何工作的,最重要的就是理解Transformations)
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestLineageTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.textFile("datas/1.txt") println(rdd.dependencies) println("-"*100) val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) println(rdd.dependencies) println("-"*100) val rdd3: RDD[(String,Int)] = rdd2.map((_,1)) println(rdd3.dependencies) println("-"*100) val rdd4: RDD[(String,Int)] = rdd3.reduceByKey(_ + _) println(rdd4.dependencies) rdd4.collect() //查看http://localhost:4040 Thread.sleep(100000) //关闭连接 sc.stop() } }
2)打印结果
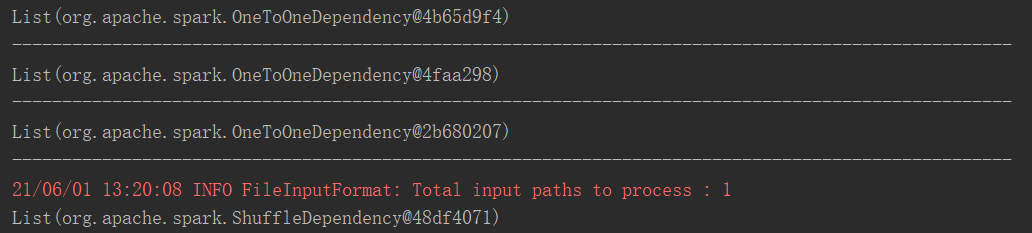

3)全局搜索(ctrl+n)org.apache.spark.OneToOneDependency
class OneToOneDependency[T](rdd: RDD[T]) extends NarrowDependency[T](rdd) { override def getParents(partitionId: Int): List[Int] = List(partitionId)
RDD之间的关系可以从两个维度来理解:一个是RDD是从哪些RDD转换而来,也就是 RDD的parent RDD(s)是什么; 另一个就是RDD依赖于parent RDD(s)的哪些Partition(s),这种关系就是RDD之间的依赖。
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
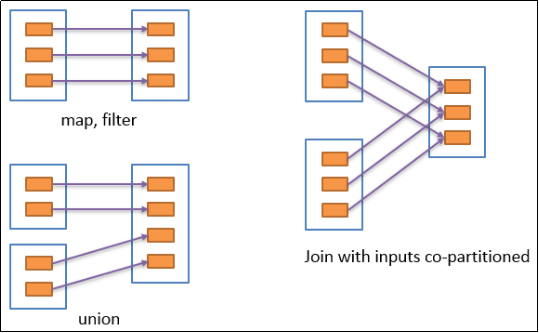
2.6.3 窄依赖
窄依赖表示每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。
2.6.4 宽依赖
宽依赖表示同一个父RDD的Partition被多个子RDD的Partition依赖,会引起Shuffle,总结:宽依赖我们形象的比喻为超生。
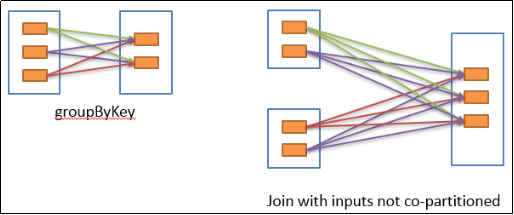
具有宽依赖的transformations包括:sort、reduceByKey、groupByKey、join和调用rePartition函数的任何操作。
宽依赖对Spark去评估一个transformations有更加重要的影响,比如对性能的影响。
2.6.5 Stage任务划分(面试重点)
1)DAG有向无环图:DAG(Directed Acyclic Graph)有向无环图是由点和线组成的拓扑图形,该图形具有方向,不会闭环。例如,DAG记录了RDD的转换过程和任务的阶段。
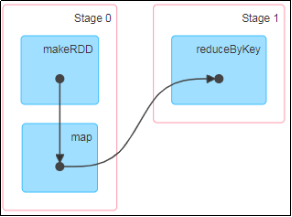
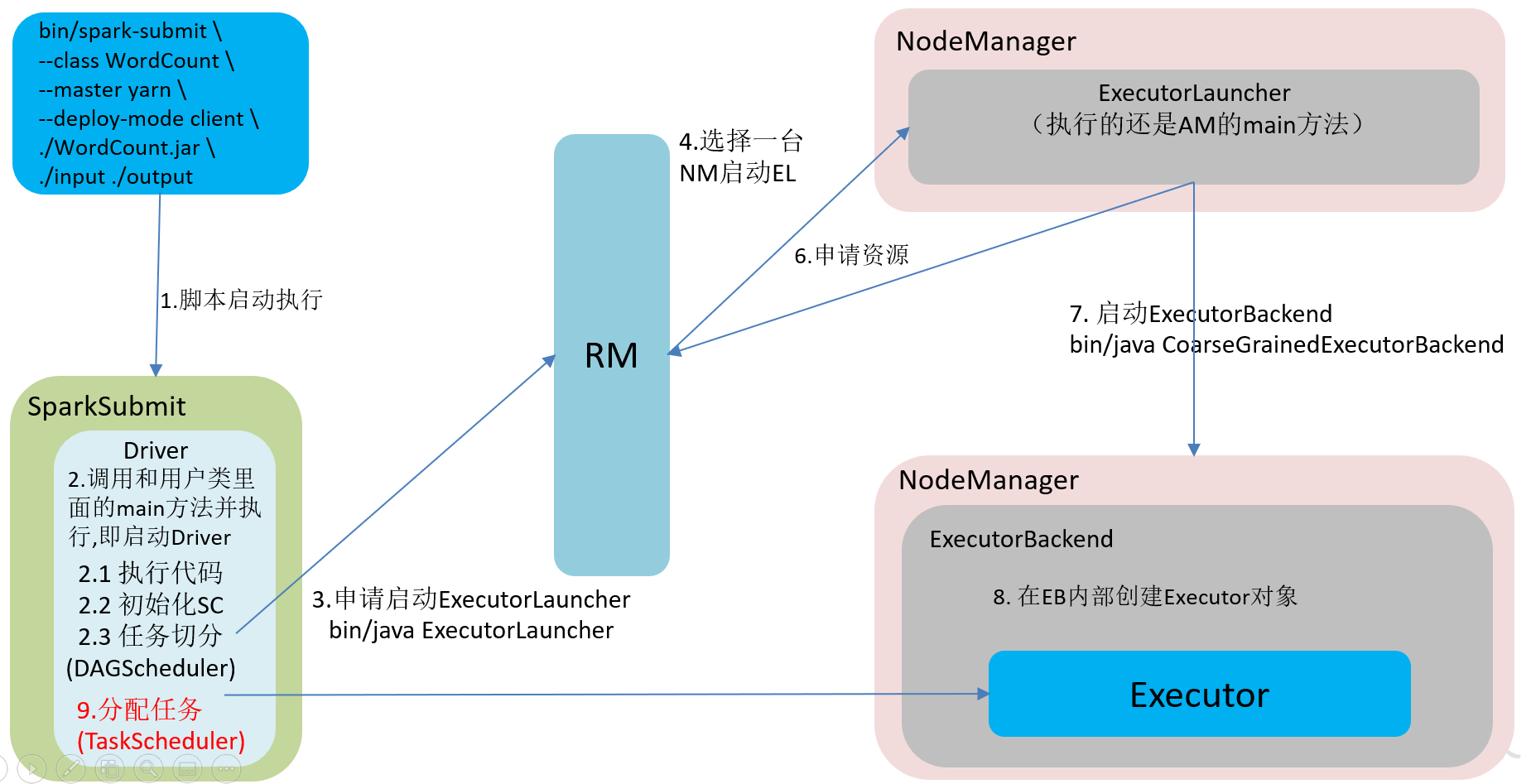
2)任务运行的整体流程
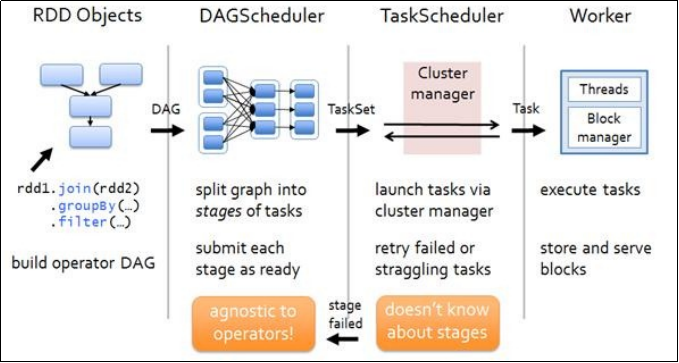
3)RDD任务切分中间分为:Application、Job、Stage和Task(Application->Job->Stage->Task每一层都是1对n的关系)
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
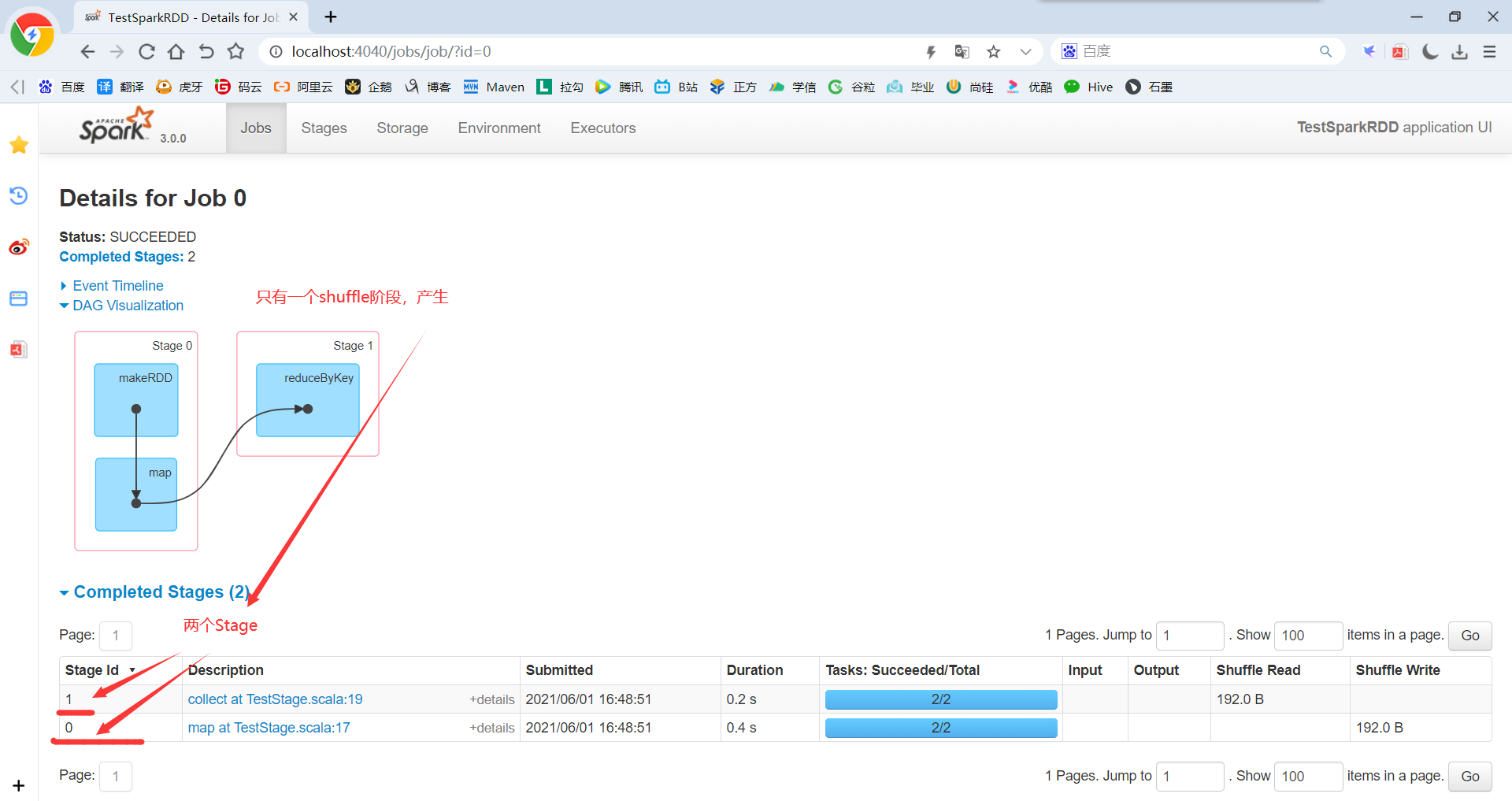
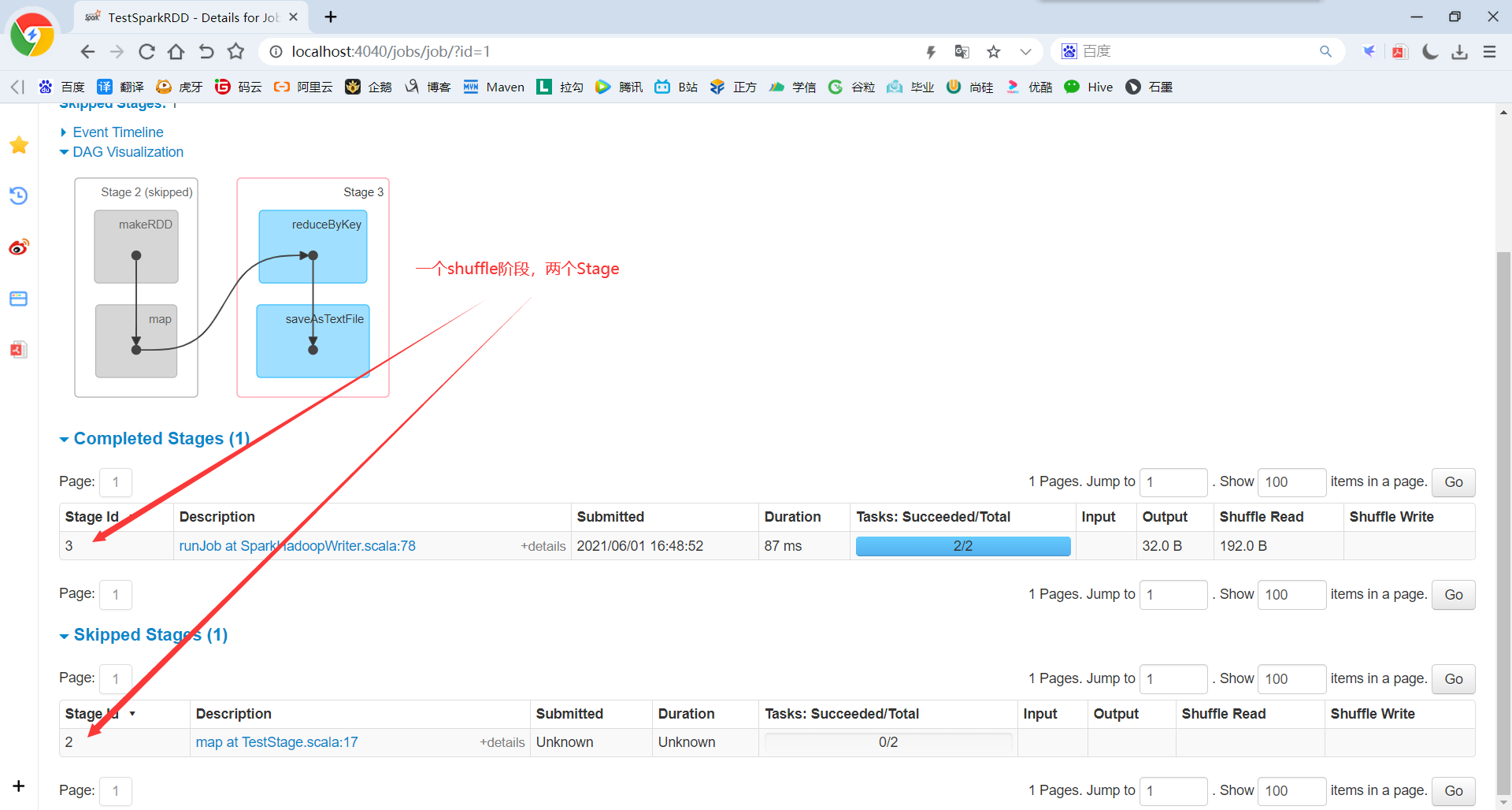
(3)Stage:Stage等于宽依赖的个数加1;
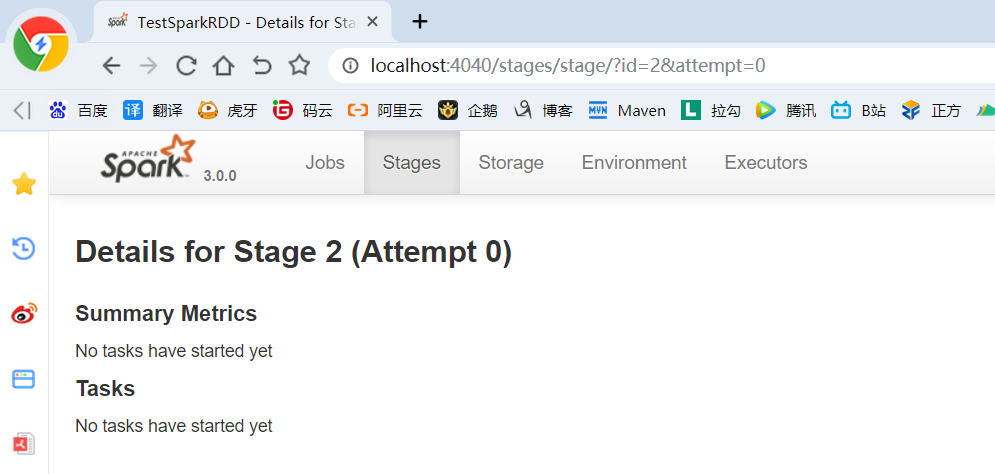
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
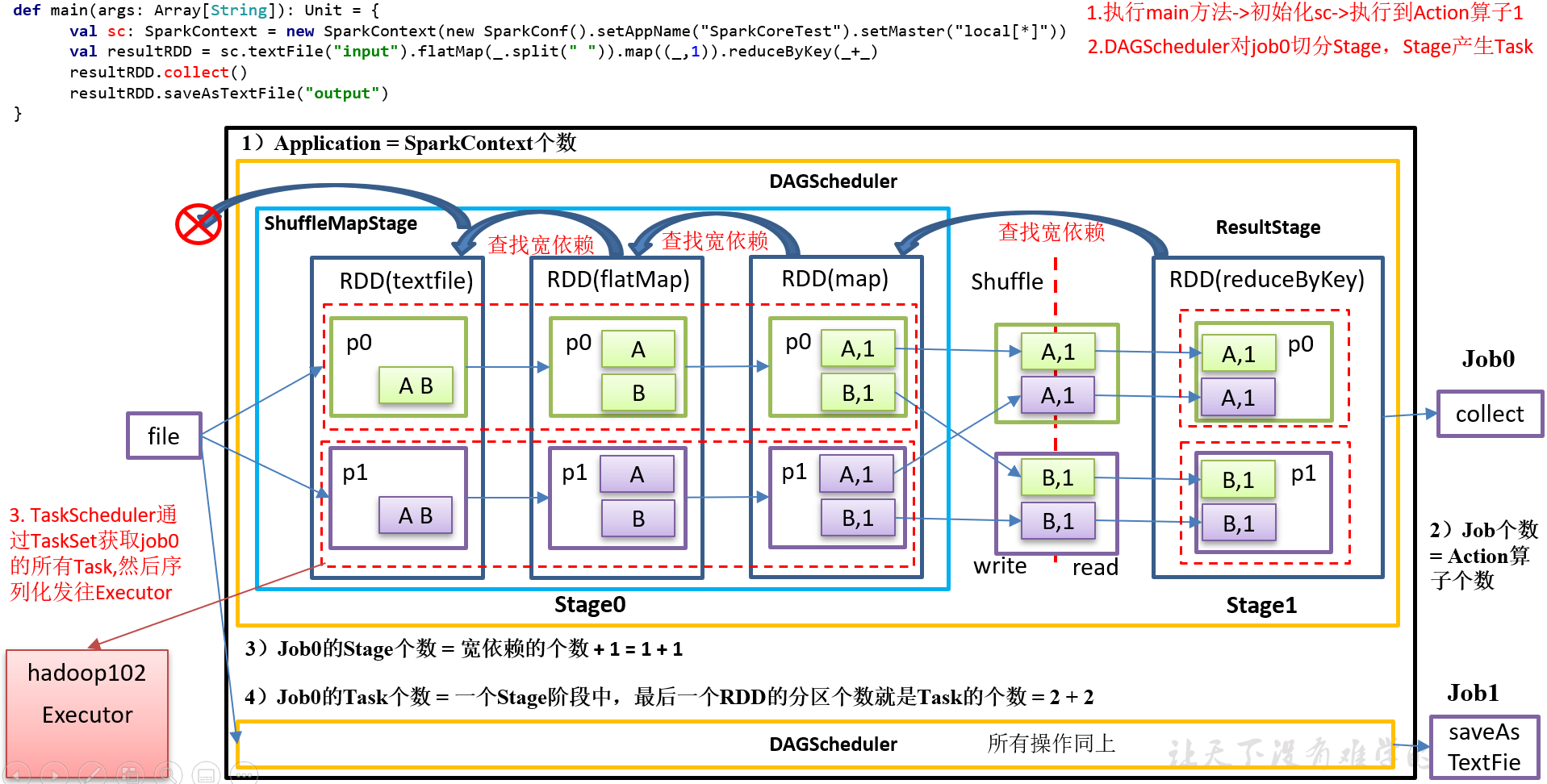
4)代码实现
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestStage { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[Int] = sc.makeRDD(List(1,2,3,4,1,2),2) //聚合 val rdd2: RDD[(Int,Int)] = rdd.map((_,1)).reduceByKey(_ + _) //一个action算子生成一个job rdd2.collect().foreach(println) //一个action算子生成一个job rdd2.saveAsTextFile("output/stage/test01") //http://localhost:4040 Thread.sleep(1000000) //关闭连接 sc.stop() } }
5)查看Job个数:http://localhost:4040
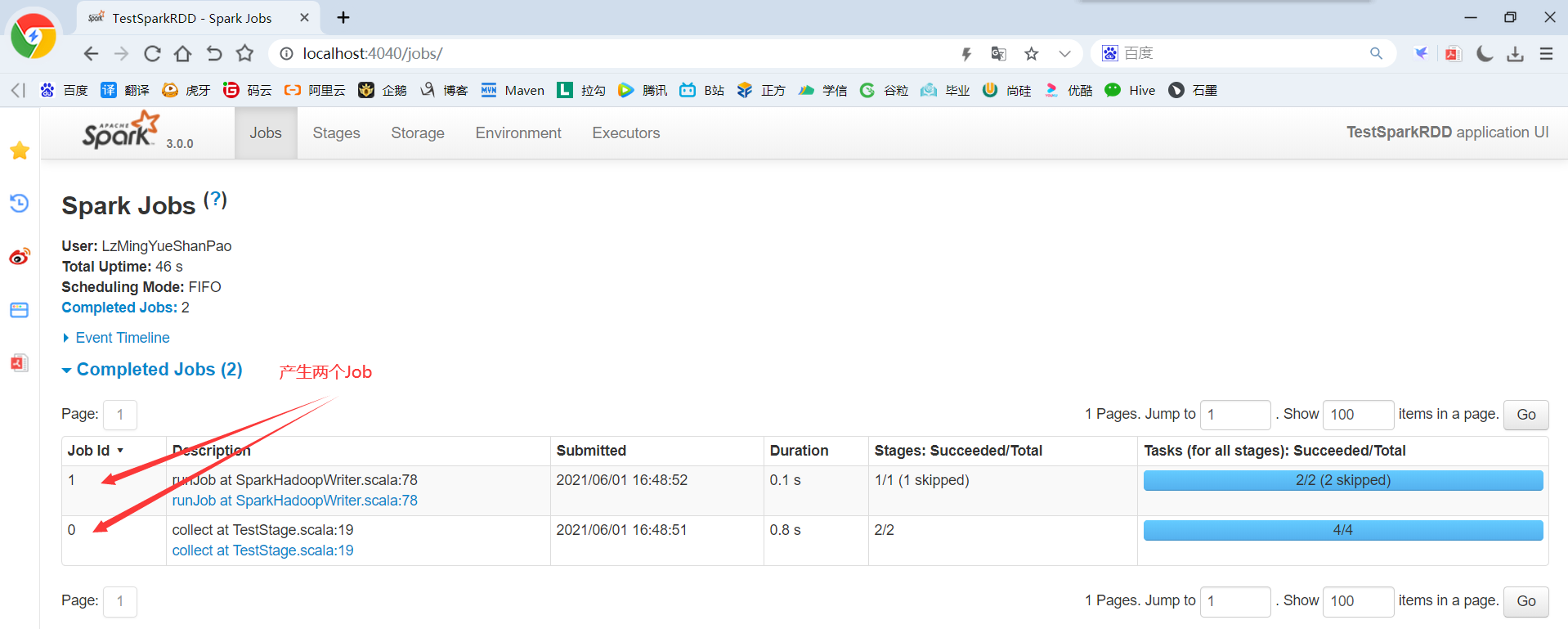
6)查看Stage个数
(1)查看Job0的Stage。由于只有1个Shuffle阶段,所以Stage个数为2。
(2)查看Job1的Stage。由于只有1个Shuffle阶段,所以Stage个数为2
7)Task个数
(1)查看Job0的Stage0的Task个数

(2)查看Job0的Stage1的Task个数

(3)查看Job1的Stage2的Task个数
(4)查看Job1的Stage3的Task个数(如果存在shuffle过程,系统会自动进行缓存,UI界面显示skipped的部分)

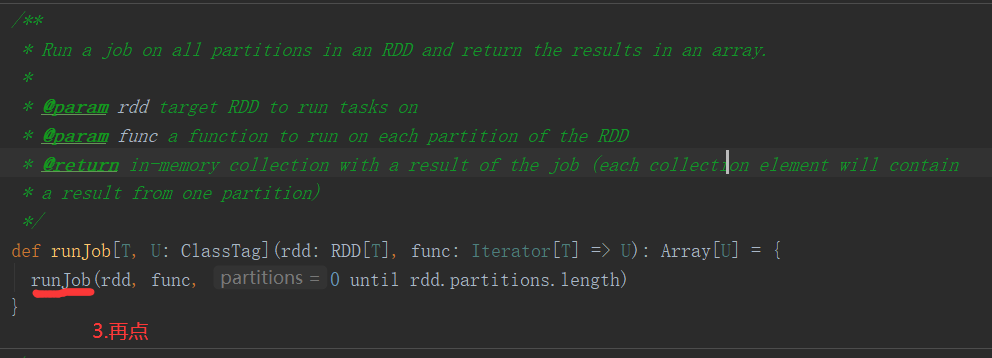
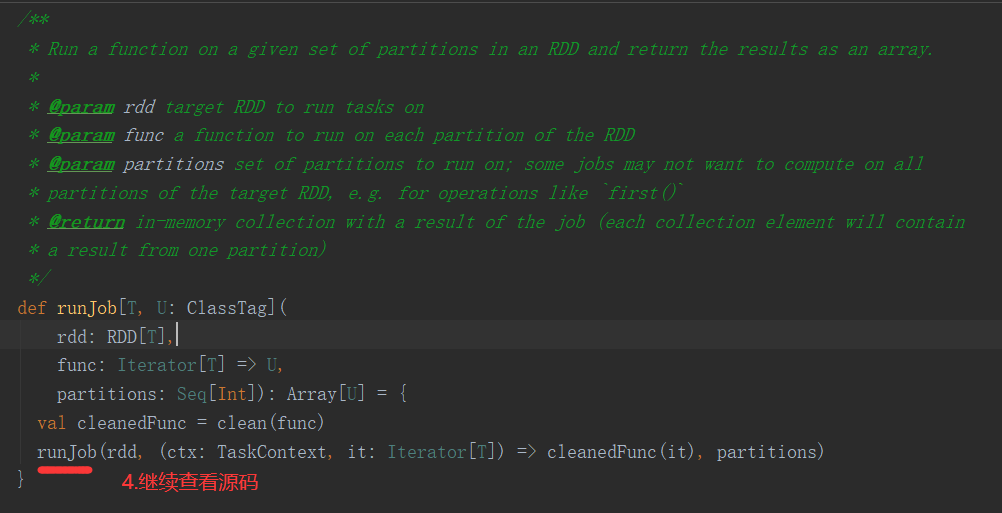
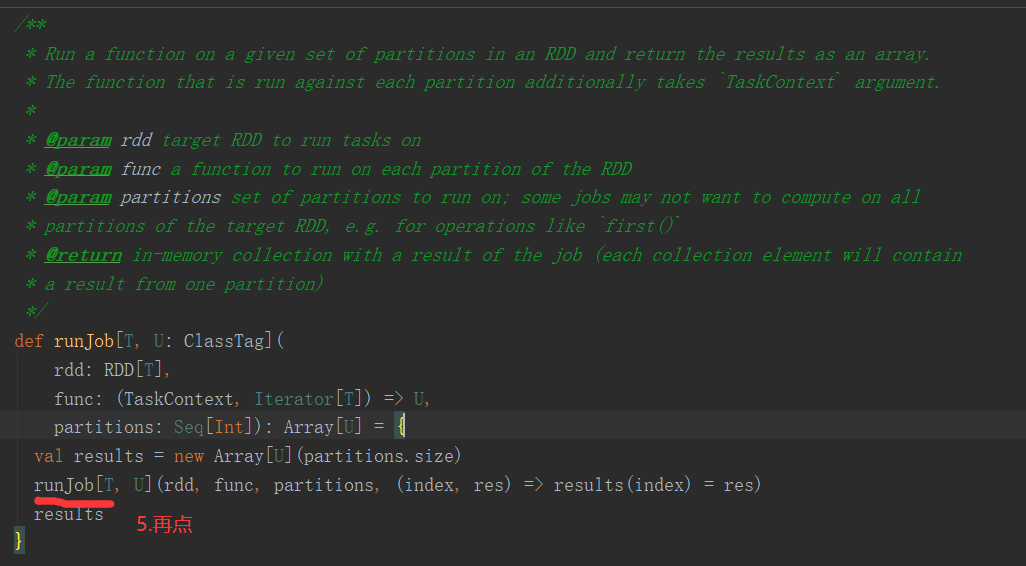
2.6.6 Stage任务划分源码分析


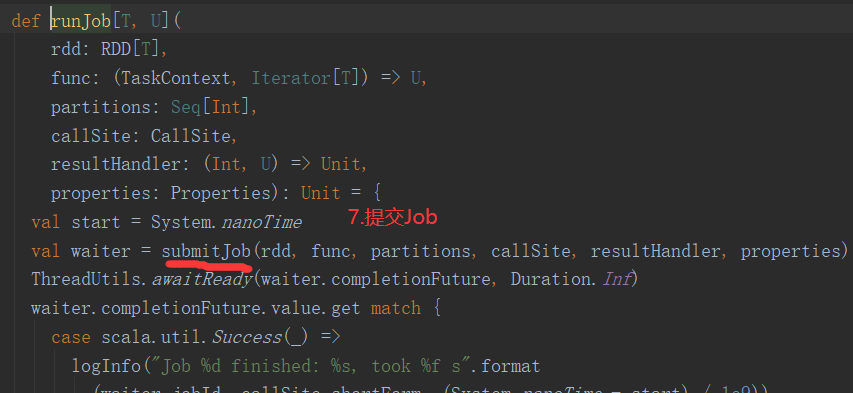
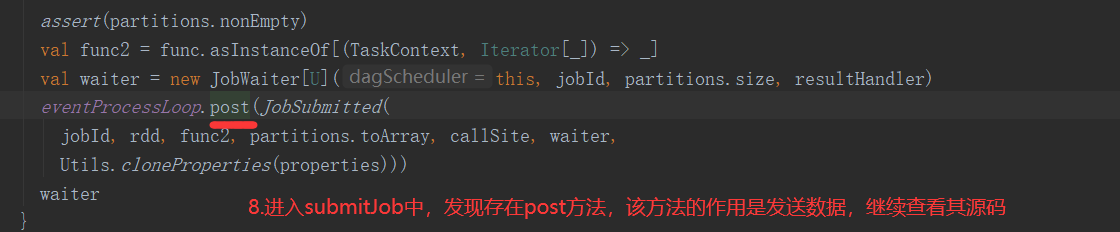
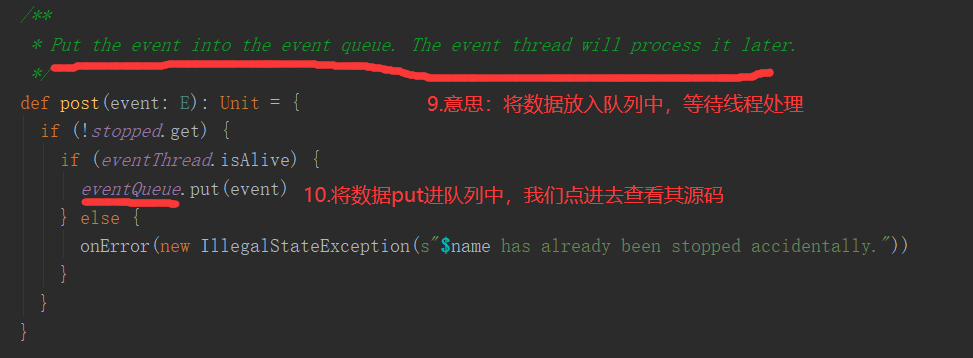
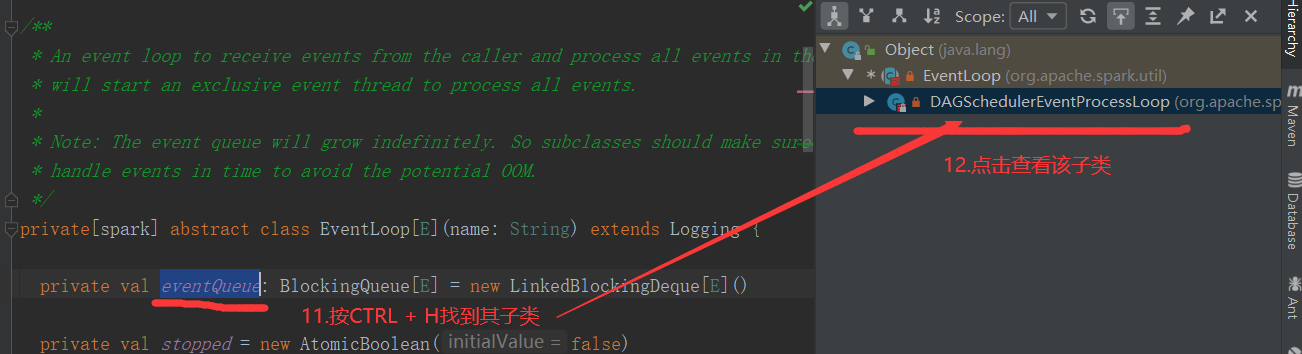
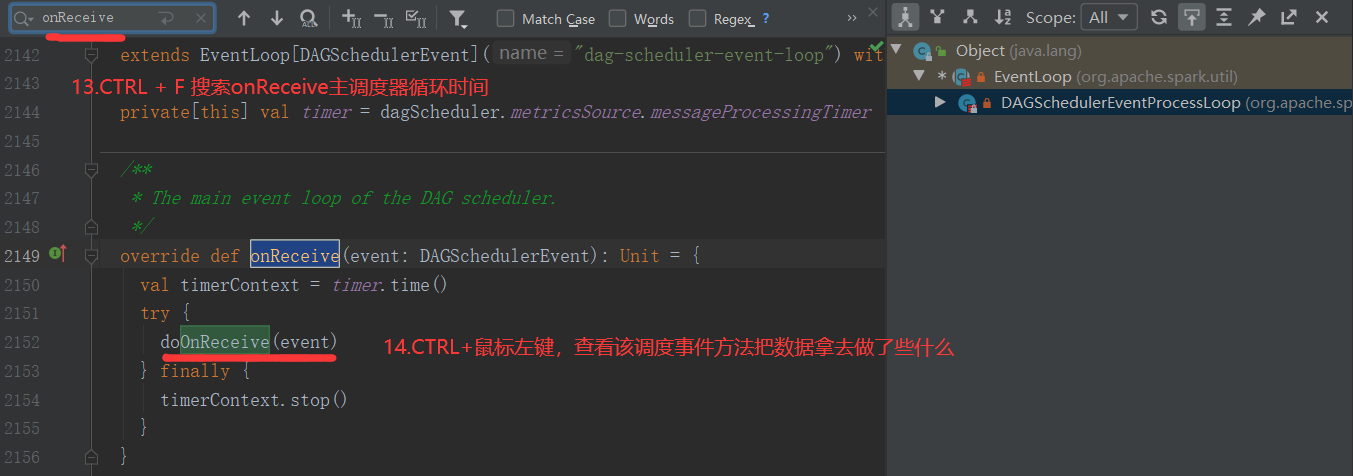
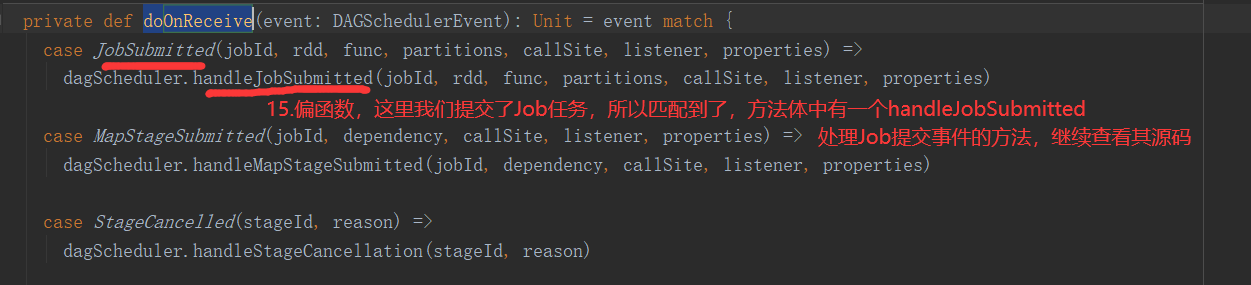
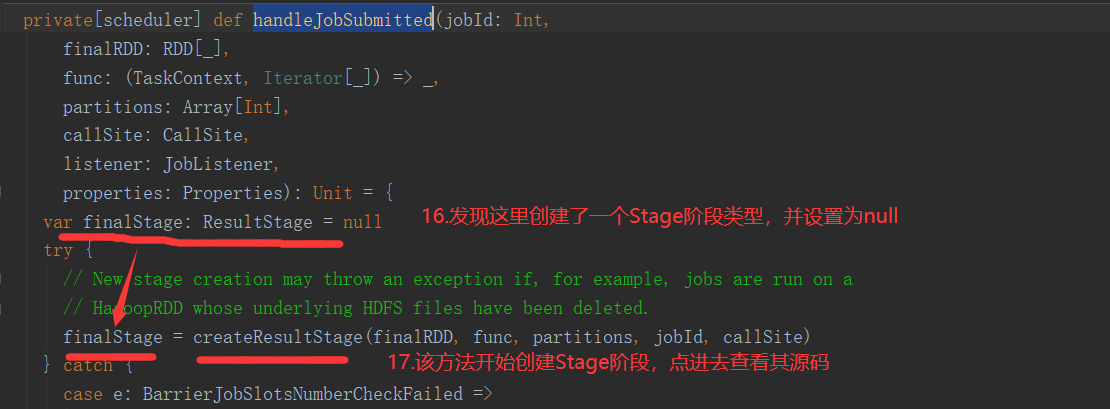
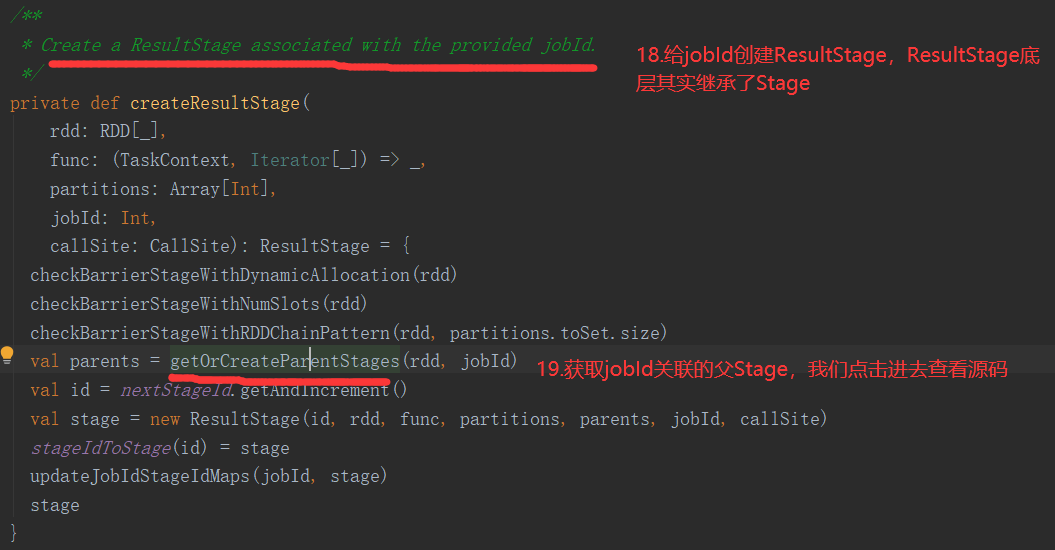
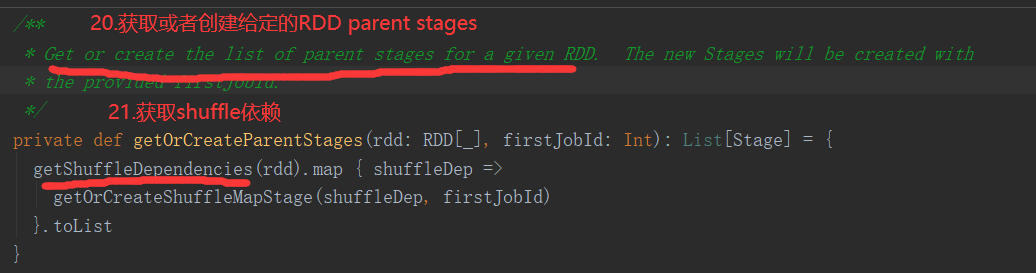
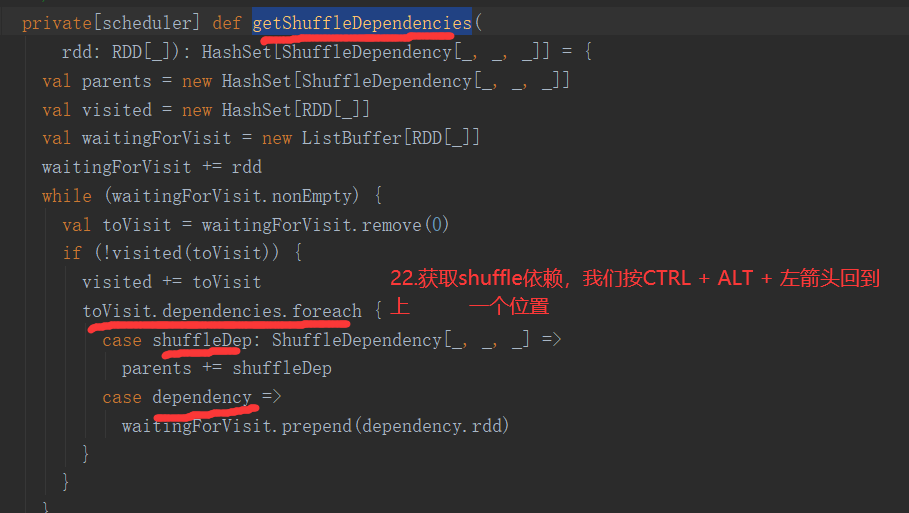
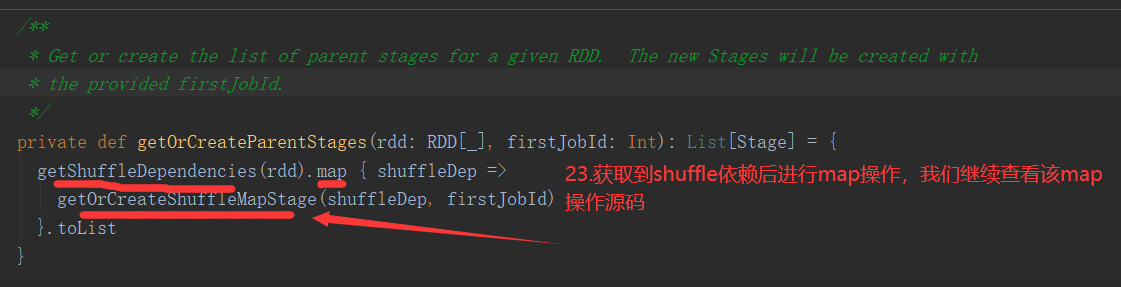
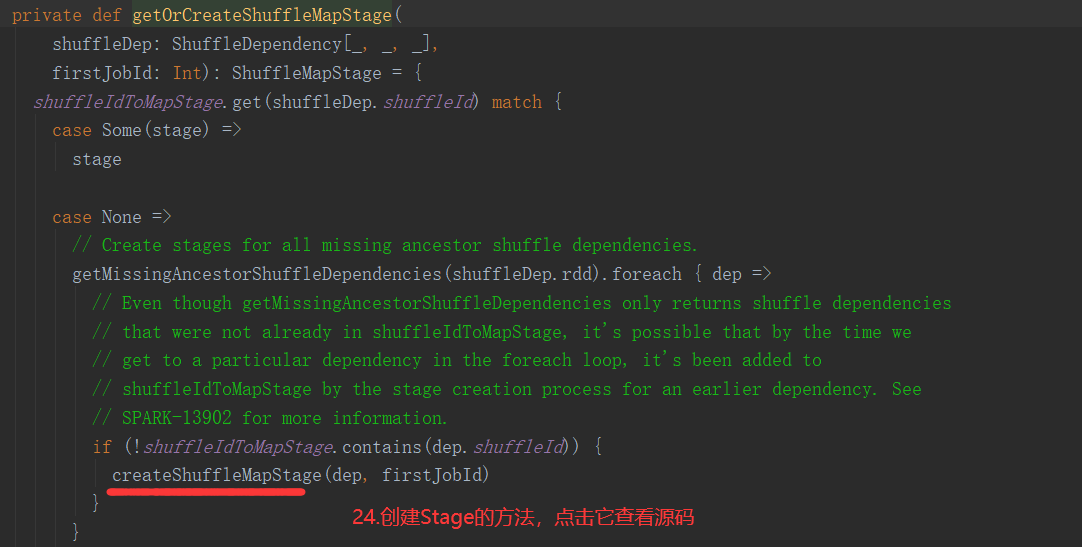
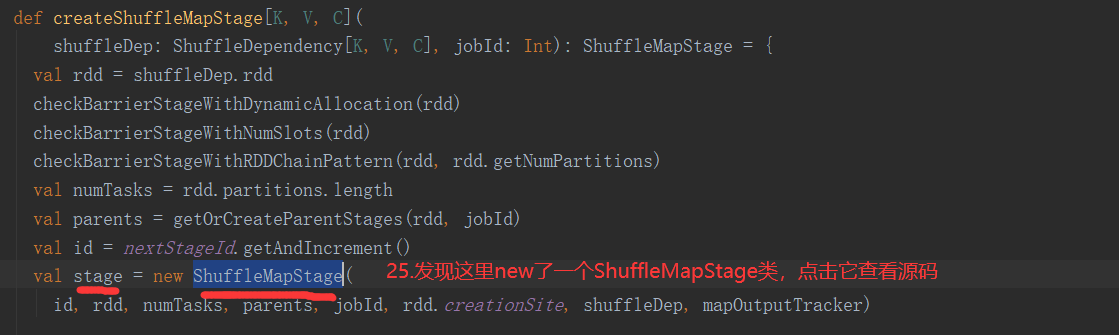
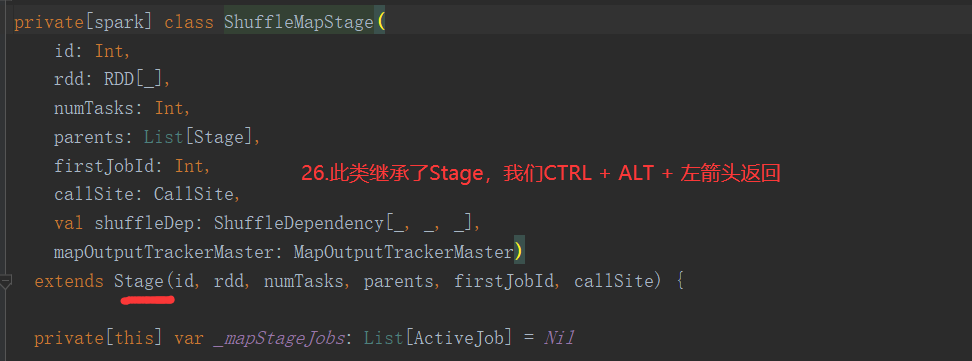
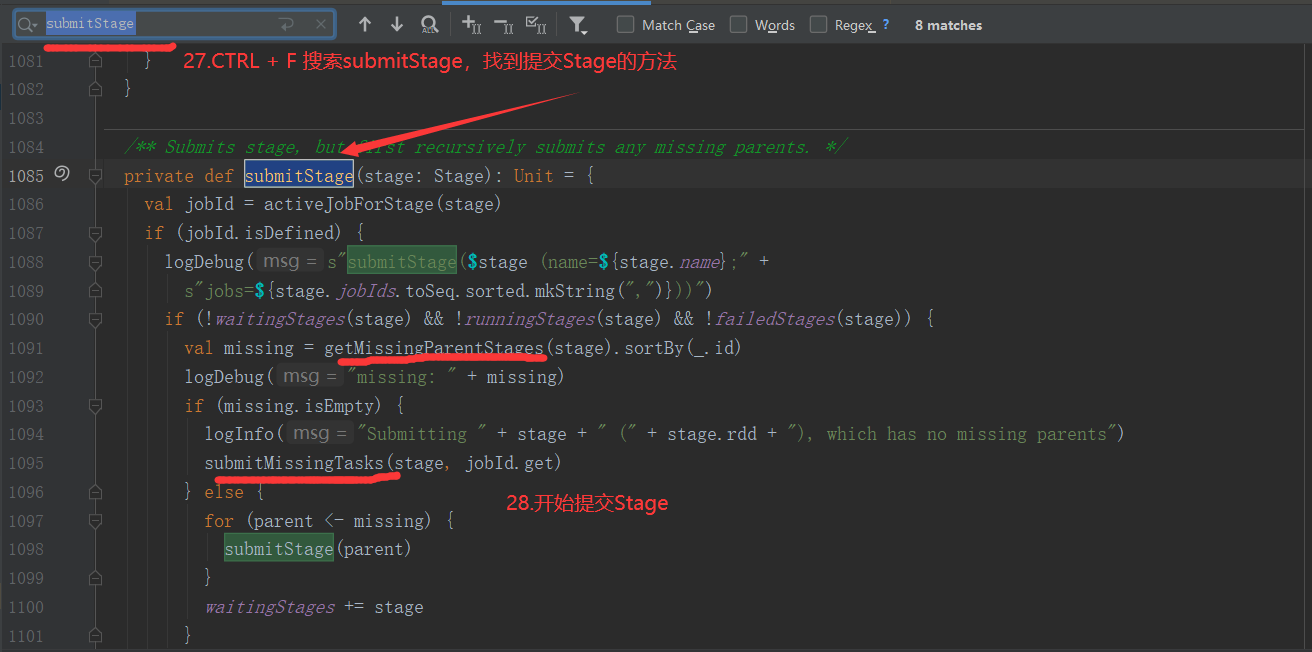

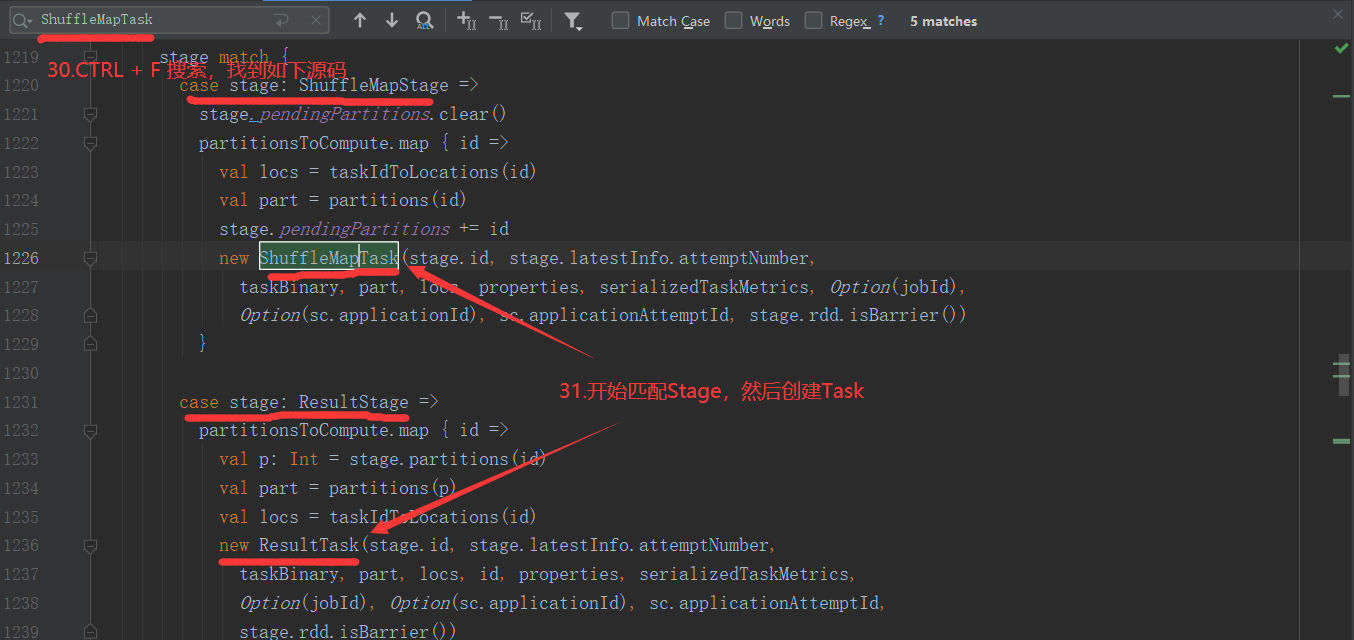
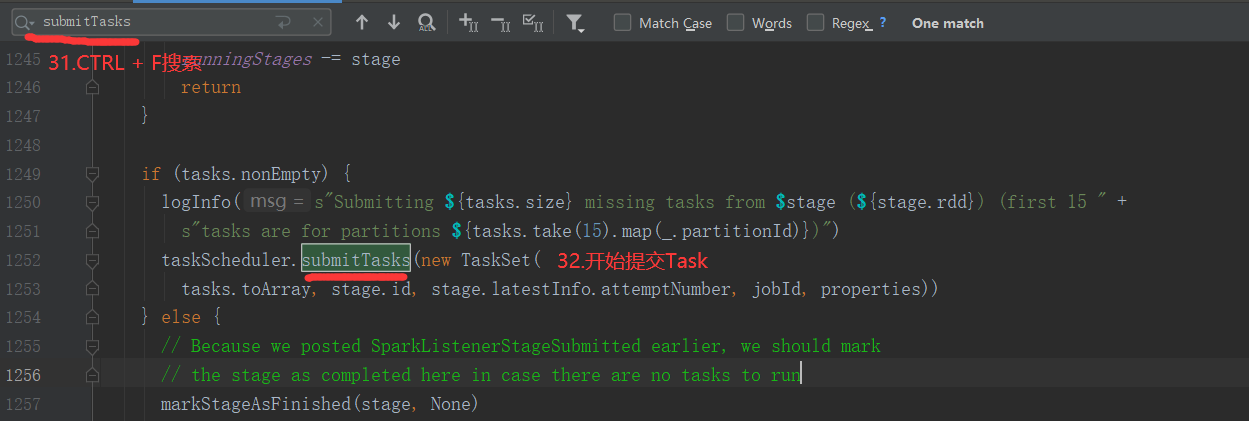
2.7 RDD持久化
2.7.1 RDD Cache缓存
RDD通过Cache或者Persist方法将前面的计算结果缓存,默认情况下会把数据以序列化的形式缓存在JVM的堆内存中。但是并不是这两个方法被调用时立即缓存,而是触发后面的action时,该RDD将会被缓存在计算节点的内存中,并供后面重用。
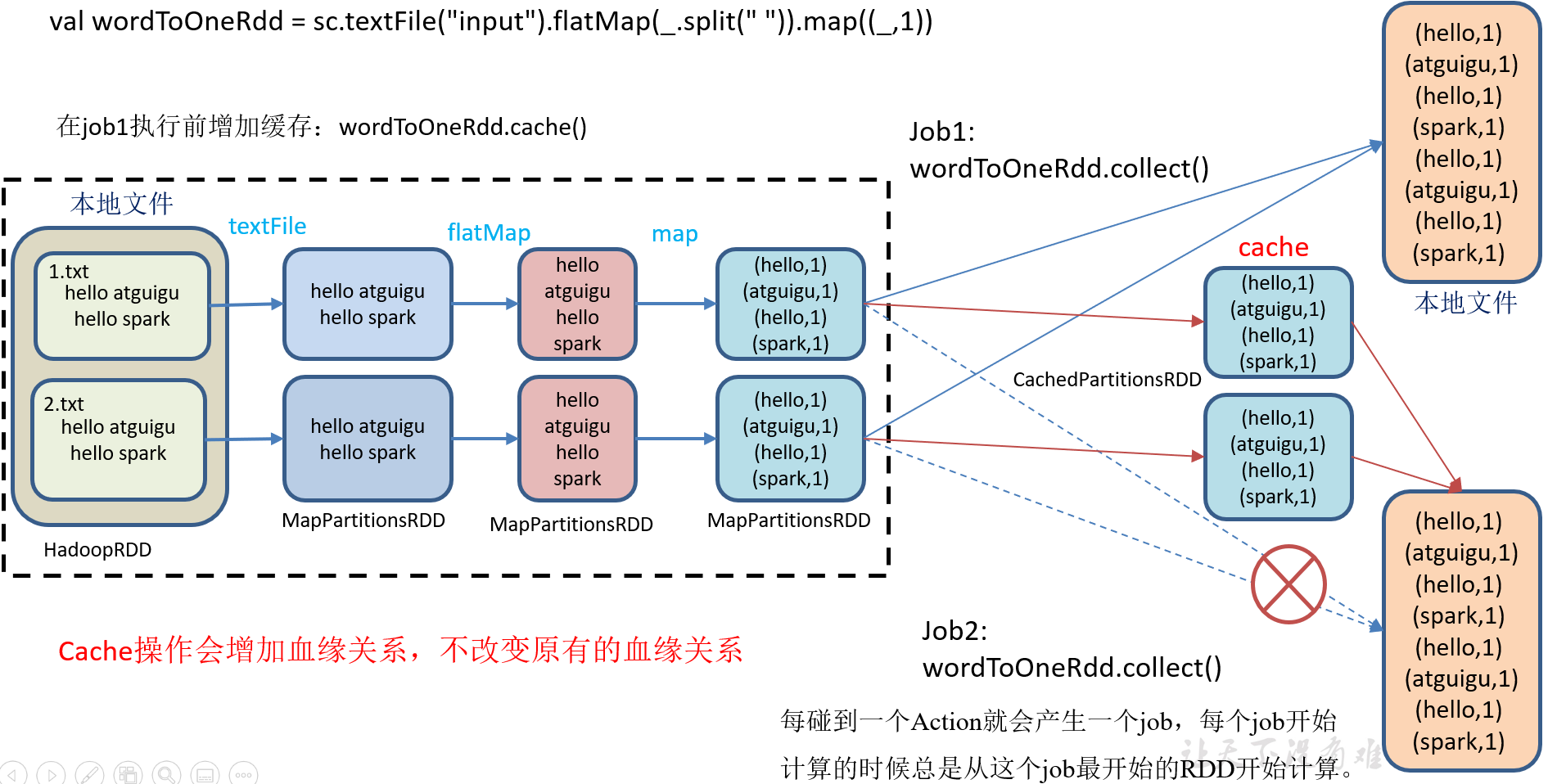
1)代码实现
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.storage.StorageLevel import org.apache.spark.{SparkConf, SparkContext} object TestCache { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[String] = sc.textFile("datas/4.txt") //切割压平 val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) //改变数据结构 var rdd3: RDD[(String,Int)] = rdd2.map(x=>{ println("-"*100) (x,1) }) //cache之前的血缘关系 println(rdd.toDebugString) //缓存:cache操作只会增加血缘关系,不会改变原有的血缘关系 rdd3.cache() //cache()方法默认使用的存储级别是MEMORY_ONLY(数据只保存在内存中) /** * cache方法的底层使用了persist()方法,persist()方法可以传入参数修改数据的存储级别 * val NONE = new StorageLevel(false, false, false, false) * val DISK_ONLY = new StorageLevel(true, false, false, false) * val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2) * val MEMORY_ONLY = new StorageLevel(false, true, false, true) * val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2) * val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false) * val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2) * val MEMORY_AND_DISK = new StorageLevel(true, true, false, true) * val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2) * val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false) * val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2) * val OFF_HEAP = new StorageLevel(true, true, true, false, 1) */ // rdd3.persist(StorageLevel.MEMORY_ONLY) //工作中常用的存储级别就两个:MEMORY_ONLY(数据只保存在内存中)、MEMORY_AND_DISK(数据保存在内存中,内存不足时溢写到磁盘) //触发执行逻辑 rdd3.collect() //再次查看血缘关系 println(rdd3.toDebugString) //再次触发执行逻辑 rdd3.collect() //http://localhost:4040 Thread.sleep(10000000) //关闭连接 sc.stop() } }

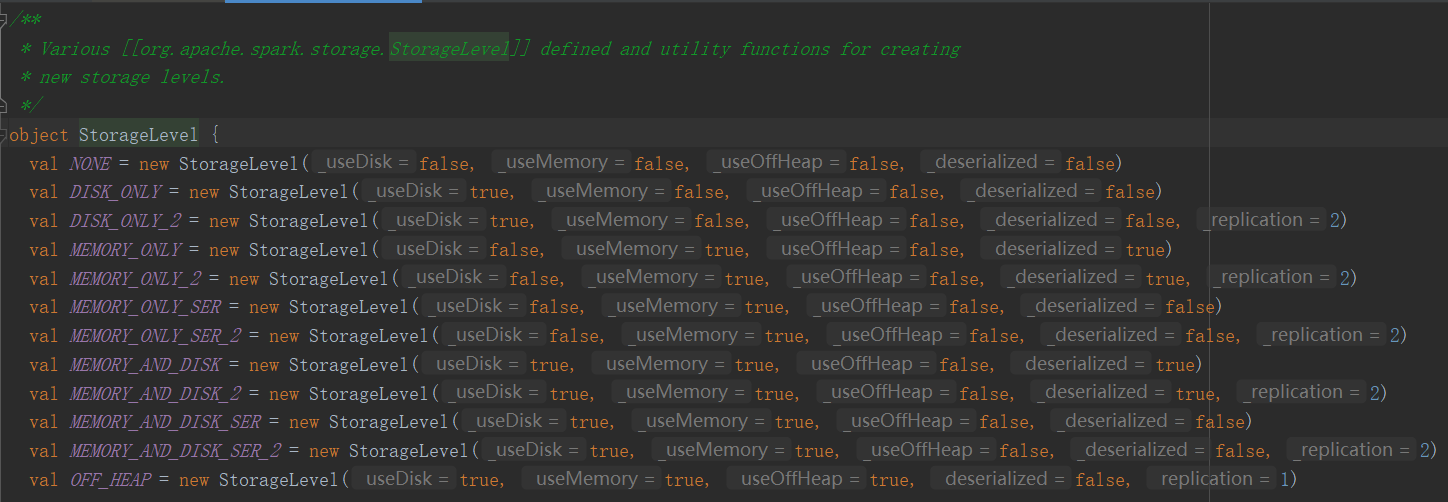
2)源码解析(默认的存储级别都是仅在内存存储一份,在存储级别的末尾加上“_2”表示持久化的数据存为两份,SER:表示序列化)



缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除,RDD的缓存容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列转换,丢失的数据会被重算,由于RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
3)自带缓存算子
Spark会自动对一些Shuffle操作的中间数据做持久化操作(比如:reduceByKey)。这样做的目的是为了当一个节点Shuffle失败了避免重新计算整个输入。但是,在实际使用的时候,如果想重用数据,仍然建议调用persist或cache。
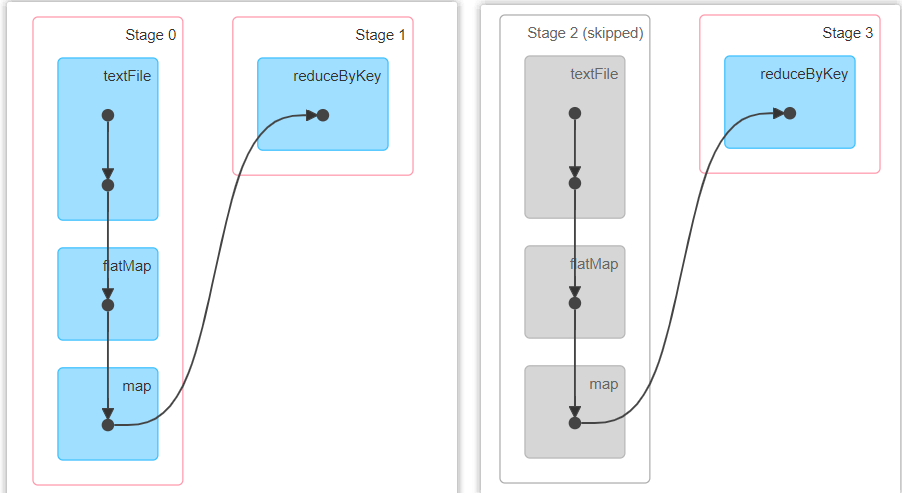
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCacheTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[String] = sc.textFile("datas/4.txt") //切割压平 val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) //改变数据结构 var rdd3: RDD[(String,Int)] = rdd2.map(x => { println("-"*100) (x,1) }) //采用reduceByKey,自带缓存 val rdd4: RDD[(String,Int)] = rdd3.reduceByKey(_ + _) //查看血缘关系 println(rdd4.toDebugString) //触发执行逻辑 rdd4.collect() //再次查看血缘关系 println(rdd4.toDebugString) //再次触发执行逻辑 rdd4.collect() //http://localhost:4040 Thread.sleep(1000000) //关闭连接 sc.stop() } }
访问 http://localhost:4040 页面,查看第一个和第二个job的DAG图。说明:增加缓存后血缘依赖关系仍然有,但是,第二个job取的数据是从缓存中取的。
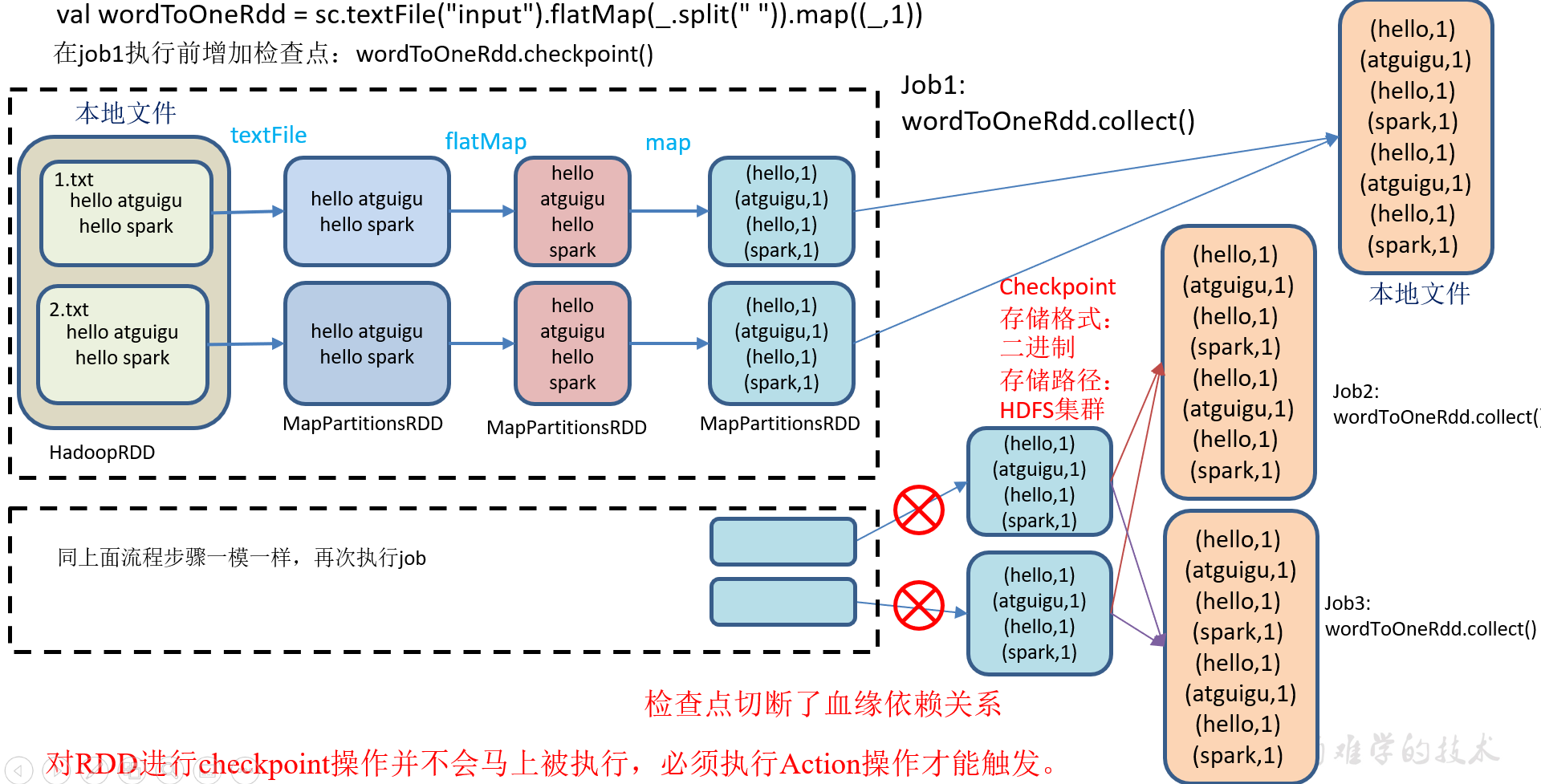
2.7.2 RDD CheckPoint检查点
1)检查点:是通过将RDD中间结果写入磁盘。
2)为什么要做检查点?
由于血缘依赖过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果检查点之后有节点出现问题,可以从检查点开始重做血缘,减少了开销。
3)检查点存储路径:Checkpoint的数据通常是存储在HDFS等容错、高可用的文件系统
4)检查点数据存储格式为:二进制的文件
5)检查点切断血缘:在Checkpoint的过程中,该RDD的所有依赖于父RDD中的信息将全部被移除。
6)检查点触发时间:对RDD进行Checkpoint操作并不会马上被执行,必须执行Action操作才能触发。但是检查点为了数据安全,会从血缘关系的最开始执行一遍
7)设置检查点步骤
(1)设置检查点数据存储路径:sc.setCheckpointDir("./checkpoint1")
(2)调用检查点方法:wordToOneRdd.checkpoint()
8)代码实现
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCheckpoint { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //设置存储路径 sc.setCheckpointDir("./TestCheckpointTwo") //创建RDD val rdd: RDD[String] = sc.textFile("datas/4.txt") //切割压平 val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) //改变数据结构 var rdd3: RDD[(String,Long)] = rdd2.map(x => { (x,System.currentTimeMillis()) }) //添加缓存,避免重新再跑一个job来进行checkpoint // rdd3.cache() //数据检查点 rdd3.checkpoint() //触发执行逻辑(会启用一个新的Job来做checkpoint计算) rdd3.collect().foreach(println) //再次触发执行逻辑 rdd3.collect().foreach(println) rdd3.collect().foreach(println) Thread.sleep(1000000) //关闭连接 sc.stop() } }
9)执行结果,访问 http://localhost:4040页面,查看4个job的DAG图。其中第2个图是checkpoint的job运行DAG图。第3、4张图说明,检查点切断了血缘依赖关系。
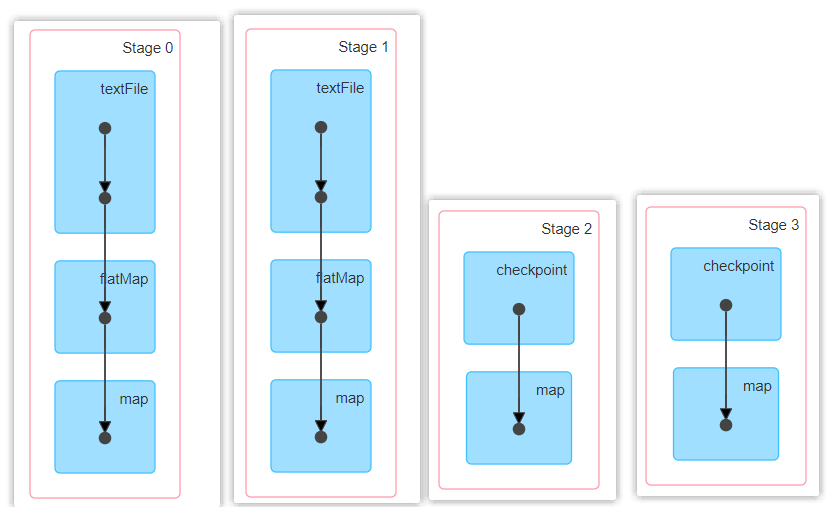
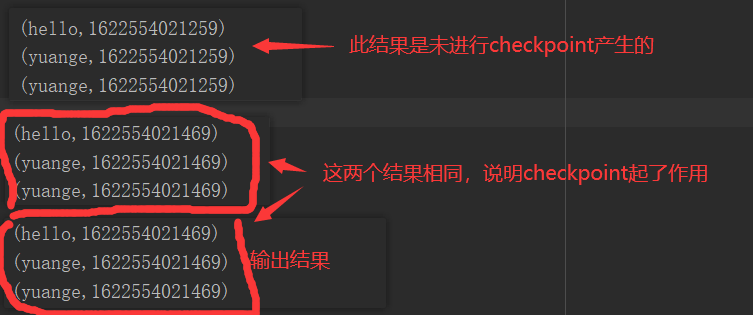
(1)只增加checkpoint,没有增加Cache缓存打印
第1个job执行完,触发了checkpoint,第2个job运行checkpoint,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。
(2)增加checkpoint,也增加Cache缓存打印
第1个job执行完,数据就保存到Cache里面了,第2个job运行checkpoint,直接读取Cache里面的数据,并把数据存储在检查点上。第3、4个job,数据从检查点上直接读取。
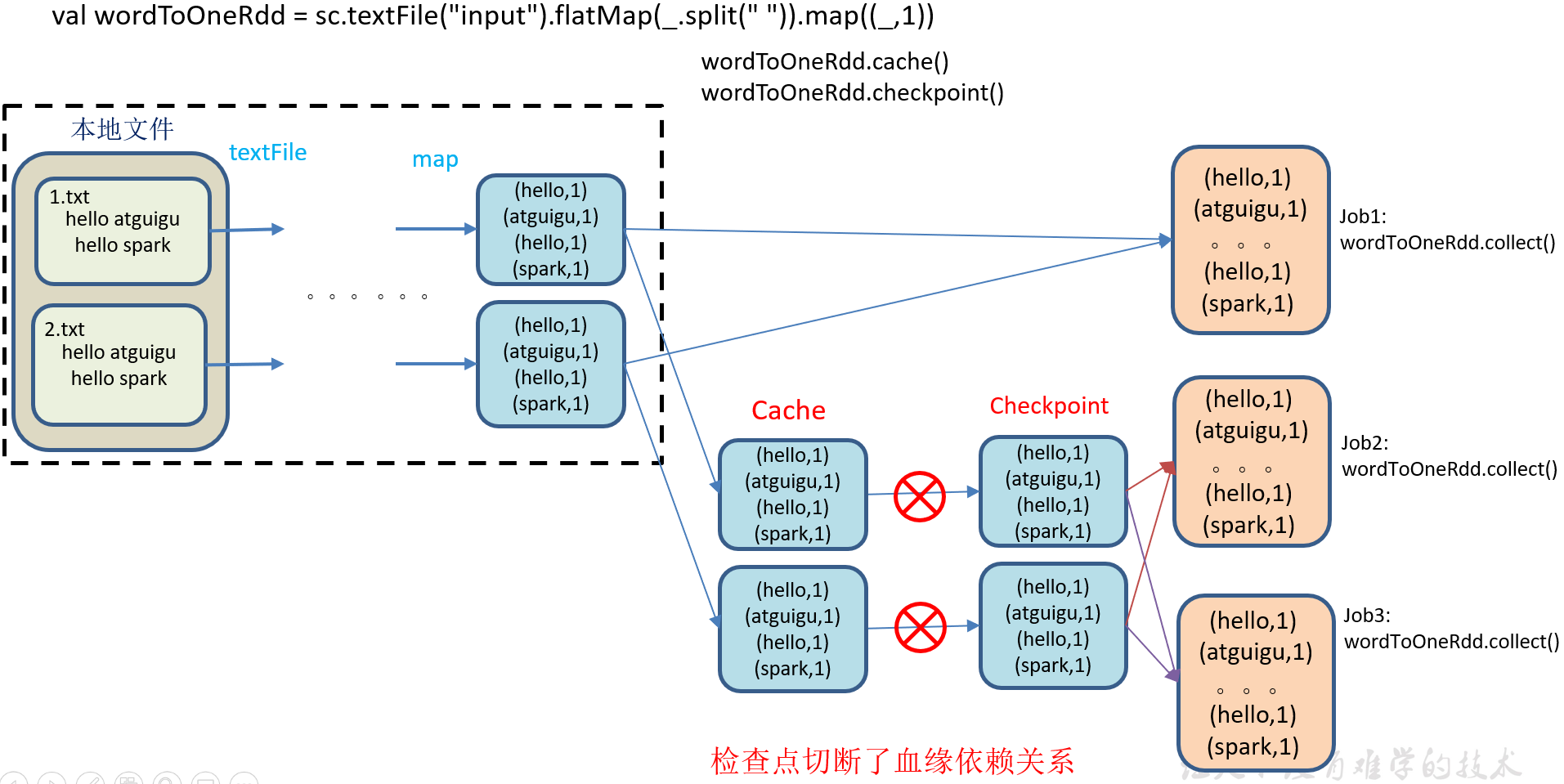
2.7.3 缓存和检查点区别
1)Cache缓存只是将数据保存起来,不切断血缘依赖。Checkpoint检查点切断血缘依赖。
2)Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低。Checkpoint的数据通常存储在HDFS等容错、高可用的文件系统,可靠性高。
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
4)如果使用完了缓存,可以通过unpersist()方法释放缓存
2.7.4 检查点存储到HDFS集群
如果检查点数据存储到HDFS集群,要注意配置访问集群的用户名。否则会报访问权限异常
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestCheckpointTwo { def main(args: Array[String]): Unit = { //设置访问HDFS集群的用户名 System.setProperty("HADOOP_USER_NAME","atguigu") //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //设置checkpoint数据存储路径:HDFS上必须存在该设置的路径,不然会报错 sc.setCheckpointDir("hdfs://hadoop102:8020/spark/checkpoint") //创建RDD val rdd: RDD[String] = sc.textFile("datas/4.txt") //切割压平 val rdd2: RDD[String] = rdd.flatMap(_.split(" ")) //改变数据结构 var rdd3: RDD[(String,Long)] = rdd2.map(x => { (x,System.currentTimeMillis()) }) //添加缓存,避免重新再跑一个job来进行checkpoint rdd3.cache() //数据检查点 rdd3.checkpoint() //触发执行逻辑(会启用一个新的Job来做checkpoint计算) rdd3.collect().foreach(println) //关闭连接 sc.stop() } }
2.8 键值对RDD数据分区
Spark目前支持Hash分区、Range分区和用户自定义分区。Hash分区为当前的默认分区。分区器直接决定了RDD中分区的个数、RDD中每条数据经过Shuffle后进入哪个分区和Reduce的个数。
1)注意:
(1)只有Key-Value类型的RDD才有分区器,非Key-Value类型的RDD分区的值是None
(2)每个RDD的分区ID范围:0~numPartitions-1,决定这个值是属于那个分区的。
2)获取RDD分区
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{HashPartitioner, SparkConf, SparkContext} object TestPartition { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[(Int,Int)] = sc.parallelize(List((1,1),(2,2),(3,3))) //打印分区器 println(rdd.partitioner) //使用HashPartitioner对RDD进行重分区 val rdd3: RDD[(Int,Int)] = rdd.partitionBy(new HashPartitioner(2)) //打印 println(rdd3.partitioner) //关闭连接 sc.stop() } }

2.8.1 Hash分区

2.8.2 Ranger分区

2.8.3 自定义分区
package com.yuange.spark.day04 import org.apache.spark.rdd.RDD import org.apache.spark.{Partitioner, SparkConf, SparkContext} //自定义分区类,继承Partitioner class MyPartitioner(number: Int) extends Partitioner{ //设置分区数 var number2 = if (number < 2){ 2 }else{ this.number } override def numPartitions: Int = number2 //分区逻辑 override def getPartition(key: Any): Int = { if (key.isInstanceOf[Int]){ val keyInt: Int = key.asInstanceOf[Int] if (keyInt % 2 == 0){ //将数据放在0号分区 0 }else{ //将数据放在1号分区 1 } }else{ //将数据放在0号分区 0 } } } object TestPartitionByTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(Int,String)] = sc.makeRDD(Array((1,"java"),(2,"mysql"),(3,"jdbc")),3) rdd.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect().foreach(println) //自定义分区 var rdd2: RDD[(Int,String)] = rdd.partitionBy(new MyPartitioner(2)) //打印 rdd2.mapPartitionsWithIndex((index,it)=>{ println(s"index:${index},datas:${it.toList}") it }).collect().foreach(println) //关闭连接 sc.stop() } }