第3章 数据读取与保存
Spark的数据读取及数据保存可以从两个维度来作区分:文件格式以及文件系统。
文件格式分为:Text文件、Json文件、Csv文件、Sequence文件以及Object文件;
文件系统分为:本地文件系统、HDFS以及数据库。
3.1 文件类数据读取与保存
3.1.1 Text文件
1)基本语法
(1)数据读取:textFile(String)
(2)数据保存:saveAsTextFile(String)
2)代码实现一
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestText { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //读取文件并创建RDD val rdd: RDD[String] = sc.textFile("datas/1.txt") //保存数据 rdd.saveAsTextFile("output/TestText") //关闭连接 sc.stop() } }
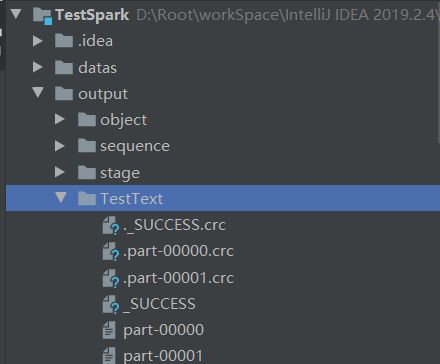
3)代码实现二
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestText { def main(args: Array[String]): Unit = { //设置访问HDFS集群的用户名 System.setProperty("HADOOP_USER_NAME","atguigu") //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //读取文件并创建RDD val rdd: RDD[String] = sc.textFile("hdfs://hadoop102:8020/spark/input/1.txt") //保存数据 rdd.saveAsTextFile("hdfs://hadoop102:8020/spark/output") //关闭连接 sc.stop() } }
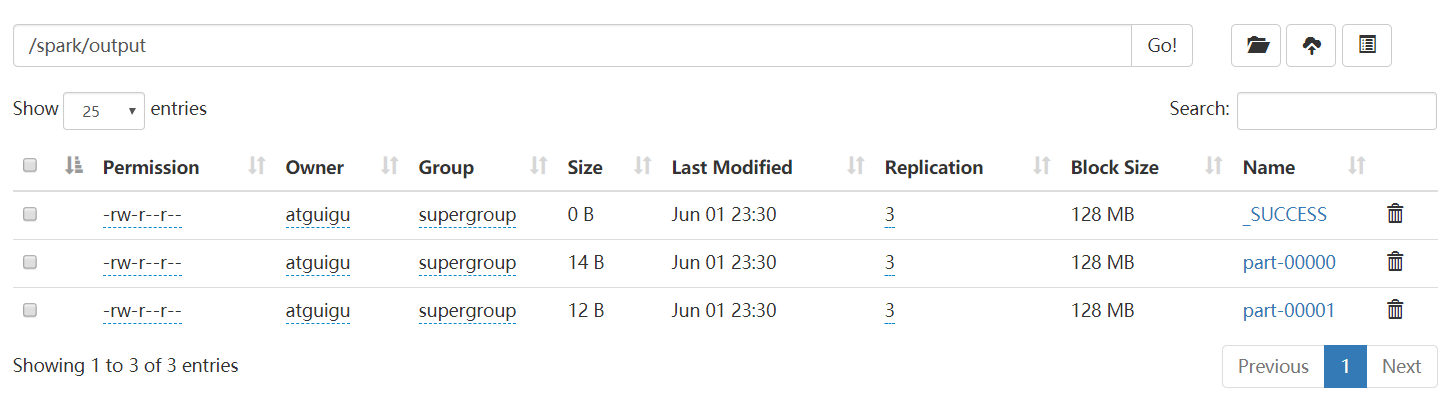
3.1.2 Sequence文件
SequenceFile文件是Hadoop用来存储二进制形式的key-value对而设计的一种平面文件(Flat File)。在SparkContext中,可以调用sequenceFile[keyClass, valueClass](path)。
代码实现(SequenceFile文件只针对PairRDD)
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestSequence { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[(Int,Int)] = sc.parallelize(Array((1,2),(3,4),(5,6))) //保存数据为SequenceFile rdd.saveAsSequenceFile("output/TestSequence") //读取SequenceFile sc.sequenceFile[Int,Int]("output/TestSequence").collect().foreach(println) //关闭连接 sc.stop() } }

3.1.3 Object对象文件
对象文件是将对象序列化后保存的文件,采用Java的序列化机制。可以通过objectFile[k,v](path)函数接收一个路径,读取对象文件,返回对应的RDD,也可以通过调用saveAsObjectFile()实现对对象文件的输出。因为是序列化所以要指定类型。
代码实现
package com.yuange.spark.day05 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestObjectTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[Int] = sc.parallelize(1 to 4) //保存数据 rdd.saveAsObjectFile("output/TestObjectTwo") //读取数据 sc.objectFile[Int]("output/TestObjectTwo").collect().foreach(println) //关闭连接 sc.stop() } }

3.2 文件系统类数据读取与保存
Spark的整个生态系统与Hadoop是完全兼容的,所以对于Hadoop所支持的文件类型或者数据库类型,Spark也同样支持。另外,由于Hadoop的API有新旧两个版本,所以Spark为了能够兼容Hadoop所有的版本,也提供了两套创建操作接口。如TextInputFormat,新旧两个版本所引用分别是org.apache.hadoop.mapred.InputFormat、org.apache.hadoop.mapreduce.InputFormat(NewInputFormat)
第4章 累加器
累加器:分布式共享只写变量。(Executor和Executor之间不能读数据)
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge
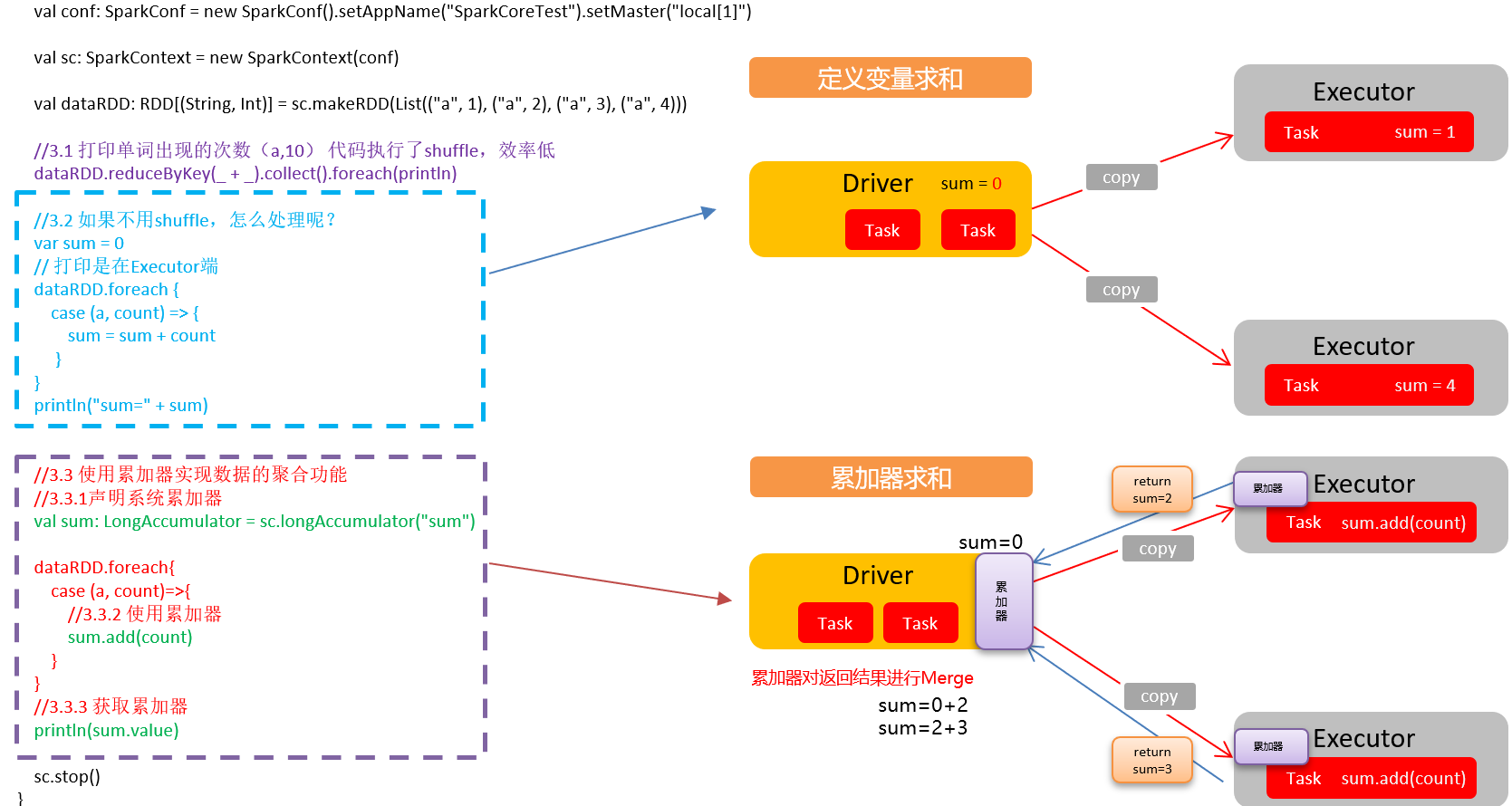
4.1 系统累加器
1)累加器使用
(1)累加器定义(SparkContext.accumulator(initialValue)方法)
val sum: LongAccumulator = sc.longAccumulator("sum")
(2)累加器添加数据(累加器.add方法)
sum.add(count)
(3)累加器获取数据(累加器.value)
sum.value
2)代码实现
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.util.LongAccumulator import org.apache.spark.{SparkConf, SparkContext} object TestAccumulatorSystem { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[(String,Int)] = sc.parallelize(List(("a", 1), ("a", 2), ("a", 3), ("a", 4))) //打印单词出现次数,有shuffle操作,效率低 rdd.reduceByKey(_ + _).collect().foreach(println) //打印在Executor端 var sum = 0 rdd.foreach{ case (a,number) => { sum = sum + number println("a=" + a + ",sum=" + sum) } } //打印在Driver端 println(("a=",sum)) //使用累加器实现聚合功能(Spark自带的累加器) val sum2: LongAccumulator = sc.longAccumulator("sum2") rdd.foreach{ case (a,number) => { sum2.add(number) } } //从累加器中取值(在Driver端取值并打印) println(sum2.value) //关闭连接 sc.stop() } }
注意:Executor端的任务不能读取累加器的值(例如:在Executor端调用sum.value,获取的值不是累加器最终的值)。从这些任务的角度来看,累加器是一个只写变量
3)累加器放在行动算子中
对于要在行动操作中使用的累加器,Spark只会把每个任务对各累加器的修改应用一次。因此,如果想要一个无论在失败还是重复计算时都绝对可靠的累加器,我们必须把它放在foreach()这样的行动操作中。转化操作中累加器可能会发生不止一次更新
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.util.LongAccumulator import org.apache.spark.{SparkConf, SparkContext} object TestAccumulatorUpdateCount { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[(String,Int)] = sc.parallelize(List(("a", 1), ("a", 2), ("a", 3), ("a", 4))) //定义累加器 val sum: LongAccumulator = sc.longAccumulator("sum") var rdd2: RDD[(String,Int)] = rdd.map(x=>{ sum.add(1) x }) //调用两次行为算子,map执行两次,导致累加器值翻倍 rdd.foreach(println) rdd.collect() //获取累加器的值 println("a=" + sum.value) //关闭连接 sc.stop() } }
4.2 自定义累加器
自定义累加器类型的功能在1.X版本中就已经提供了,但是使用起来比较麻烦,在2.0版本后,累加器的易用性有了较大的改进,而且官方还提供了一个新的抽象类:AccumulatorV2来提供更加友好的自定义类型累加器的实现方式。
1)自定义累加器步骤
(1)继承AccumulatorV2,设定输入、输出泛型
(2)重写方法
2)需求:自定义累加器,统计RDD中首字母为“H”的单词以及出现的次数
List("Hello", "Hello", "Hello", "Hello", "Hello", "Spark", "Spark")
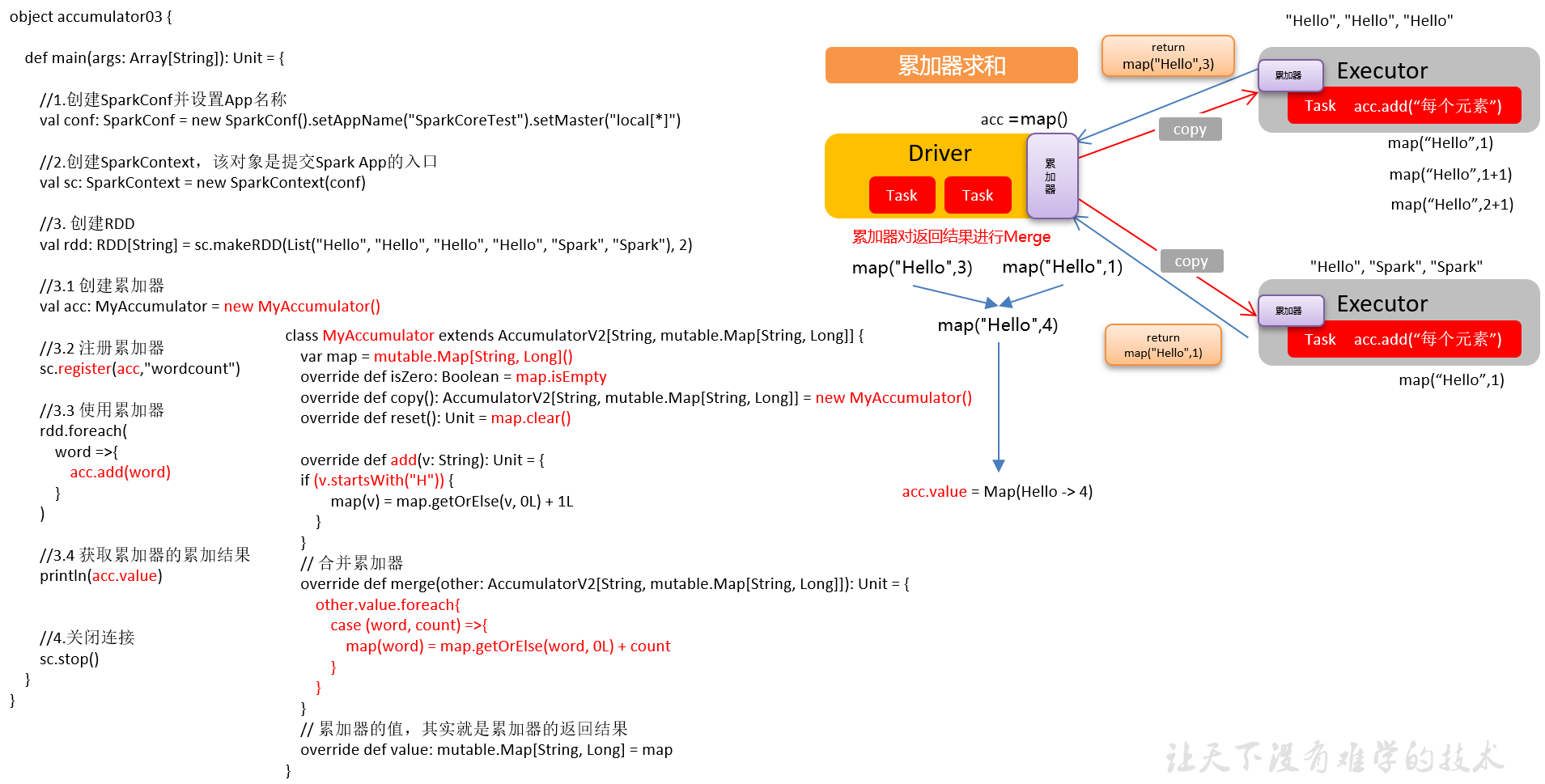
3)代码实现
package com.yuange.spark.day06 import org.apache.spark.util.AccumulatorV2 import scala.collection.mutable class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]{ //定义输出数据类型 var map = mutable.Map[String,Long]() //定义初始化状态 override def isZero: Boolean = map.isEmpty //复制累加器 override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = new MyAccumulator() //重置累加器 override def reset(): Unit = map.clear() //添加数据 override def add(v: String): Unit = { if (v.startsWith("H")){ map(v) = map.getOrElse(v,0L) + 1L } } //合并累加器 override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = { other.value.foreach{ case (word,count) => { map(word) = map.getOrElse(word,0L) + count } } } //返回累加器的值 override def value: mutable.Map[String, Long] = map }
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestAccumulatorDefine { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建一个RDD val rdd: RDD[String] = sc.parallelize(List("Hello", "Hello", "Hello", "Hello", "Spark", "Spark"), 2) //创建累加器 val accumulator: MyAccumulator = new MyAccumulator() //注册累加器 sc.register(accumulator,"TestAccumulator") //使用累加器 rdd.foreach(x=>{ accumulator.add(x) }) //获取累加器的结果 println(accumulator.value) //关闭连接 sc.stop() } }
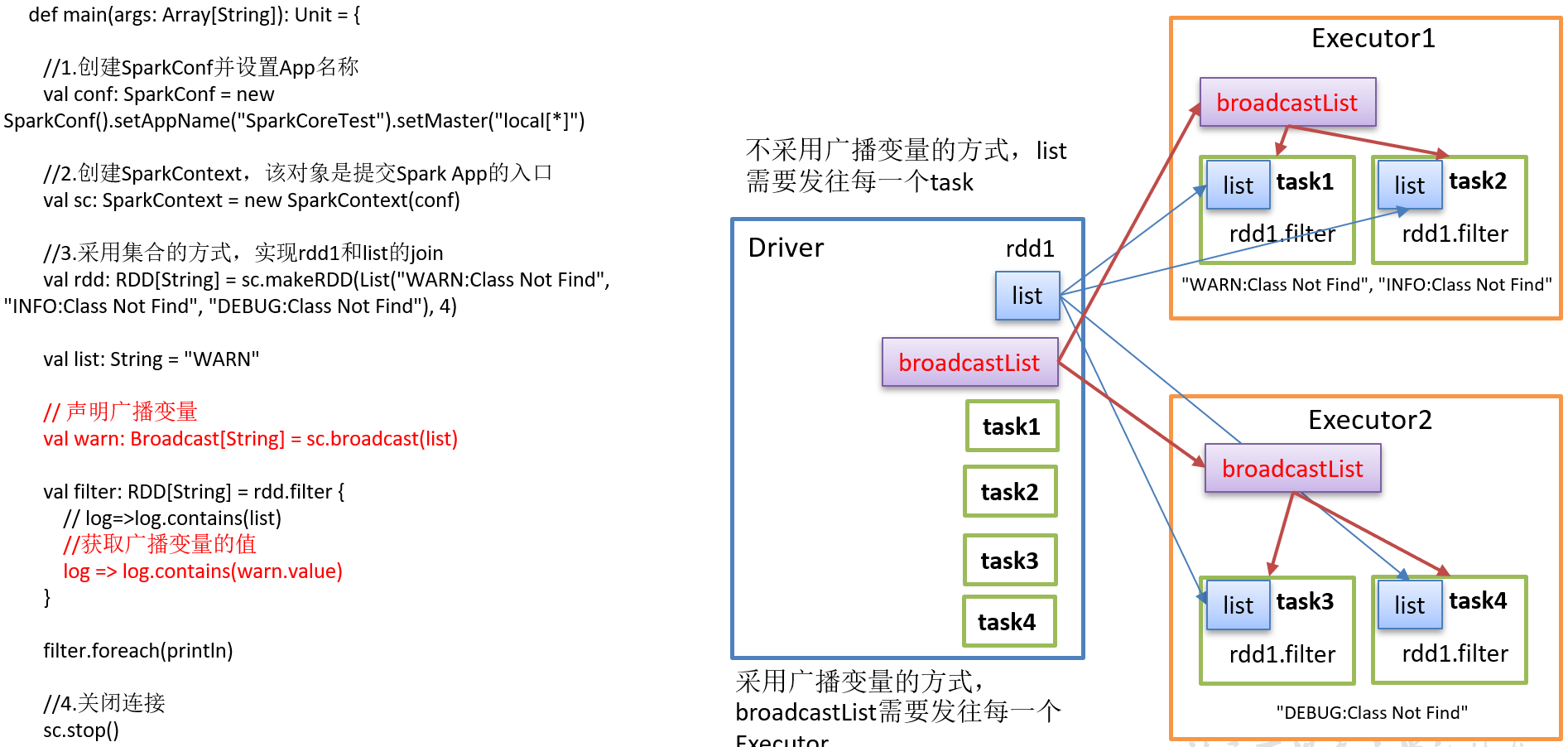
第5章 广播变量
广播变量:分布式共享只读变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个Spark操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark会为每个任务分别发送。
1)使用广播变量步骤:
(1)调用SparkContext.broadcast(广播变量)创建出一个广播对象,任何可序列化的类型都可以这么实现。
(2)通过广播变量.value,访问该对象的值。
(3)变量只会被发到各个节点一次,作为只读值处理(修改这个值不会影响到别的节点)。
2)原理说明
3)代码实现
package com.yuange.spark.day06 import org.apache.spark.broadcast.Broadcast import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestBroadcast { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) val rdd: RDD[String] = sc.makeRDD(List("WARN:Class Not Find", "INFO:Class Not Find", "DEBUG:Class Not Find"), 4) val list: String = "WARN" //声明广播变量 val warn: Broadcast[String] = sc.broadcast(list) rdd.filter(x=>{ // x.contains(list) //取出广播的值 x.contains(warn.value) }).foreach(println) //关闭连接 sc.stop() } }
第6章 SparkCore实战
6.1 数据准备
1)数据格式

2)数据详细字段说明
|
编号 |
字段名称 |
字段类型 |
字段含义 |
|
1 |
date |
String |
用户点击行为的日期 |
|
2 |
user_id |
Long |
用户的ID |
|
3 |
session_id |
String |
Session的ID |
|
4 |
page_id |
Long |
某个页面的ID |
|
5 |
action_time |
String |
动作的时间点 |
|
6 |
search_keyword |
String |
用户搜索的关键词 |
|
7 |
click_category_id |
Long |
点击某一个商品品类的ID |
|
8 |
click_product_id |
Long |
某一个商品的ID |
|
9 |
order_category_ids |
String |
一次订单中所有品类的ID集合 |
|
10 |
order_product_ids |
String |
一次订单中所有商品的ID集合 |
|
11 |
pay_category_ids |
String |
一次支付中所有品类的ID集合 |
|
12 |
pay_product_ids |
String |
一次支付中所有商品的ID集合 |
|
13 |
city_id |
Long |
城市 id |
6.2 需求1:Top10热门品类
需求说明:品类是指产品的分类,大型电商网站品类分多级,咱们的项目中品类只有一级,不同的公司可能对热门的定义不一样。我们按照每个品类的点击、下单、支付的量来统计热门品类。
鞋 点击数 下单数 支付数
衣服 点击数 下单数 支付数
电脑 点击数 下单数 支付数
例如,综合排名 = 点击数*20% + 下单数*30% + 支付数*50%
本项目需求优化为:先按照点击数排名,靠前的就排名高;如果点击数相同,再比较下单数;下单数再相同,就比较支付数。
6.2.1 需求分析(方案一)分步计算
思路:分别统计每个品类点击的次数、下单的次数和支付的次数:(品类,点击总数)(品类,下单总数)(品类,支付总数)
缺点:统计3次,需要启动3个job,每个job都有对原始数据遍历一次,效率低
package com.yuange.spark.day06 import org.apache.spark.{SparkConf, SparkContext} object TestWordCountOne { //Top10热门品类 def main(args: Array[String]): Unit = { val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test")) //1、读取数据 val rdd1 = sc.textFile("datas/user_visit_action.txt") //3、统计每个品类点击次数 //3.1、过滤点击数据 val clickRdd = rdd1.filter(line=>{ val arr = line.split("_") arr(6) != "-1" }) //3.2、切割 val clickSplitRdd = clickRdd.map(line=>{ val arr = line.split("_") (arr(6),1) }) //3.3、分组聚合 val clickNumRdd = clickSplitRdd.reduceByKey(_+_) //List( (1,10),(5,30)) //4、统计每个品类下单次数 //4.1、过滤下单数据 val orderRDD = rdd1.filter(line=>{ val arr = line.split("_") arr(8)!="null" }) //4.2、切割 val orderSplitRdd = orderRDD.flatMap(line=>{ val arr = line.split("_") val ids = arr(8) ids.split(",").map(id=> (id,1)) }) //4.3、统计下单次数 val orderNumRdd = orderSplitRdd.reduceByKey(_+_) //RDD[ (1,15),(5,5)] //5、统计每个品类支付次数 //5.1、过滤支付数据 val payRdd = rdd1.filter(line=>{ val arr = line.split("_") arr(10)!="null" }) //5.2、切割 val paySplitRdd = payRdd.flatMap(line=>{ val arr = line.split("_") val ids = arr(10) ids.split(",").map(id=>(id,1)) }) //5.3、统计支付次数 val payNumRdd = paySplitRdd.reduceByKey(_+_) //RDD[ (1,2),(5,3)] //6、join得到每个品类的点击、支付、下单次数 val totalRdd = clickNumRdd.leftOuterJoin(orderNumRdd).leftOuterJoin(payNumRdd) val totalNumRdd = totalRdd.map{ case (id,((clickNum,orderNum),payNum)) => (id,clickNum,orderNum.getOrElse(0),payNum.getOrElse(0)) } //7、排序取前十 totalNumRdd.sortBy({ case (id,clickNum,orderNum,payNum) => (clickNum,orderNum,payNum) },false) //8、结果展示 .collect().take(10).foreach(println(_)) } }
6.2.2 需求分析(方案二)常规算子
采用常规算子的方式实现
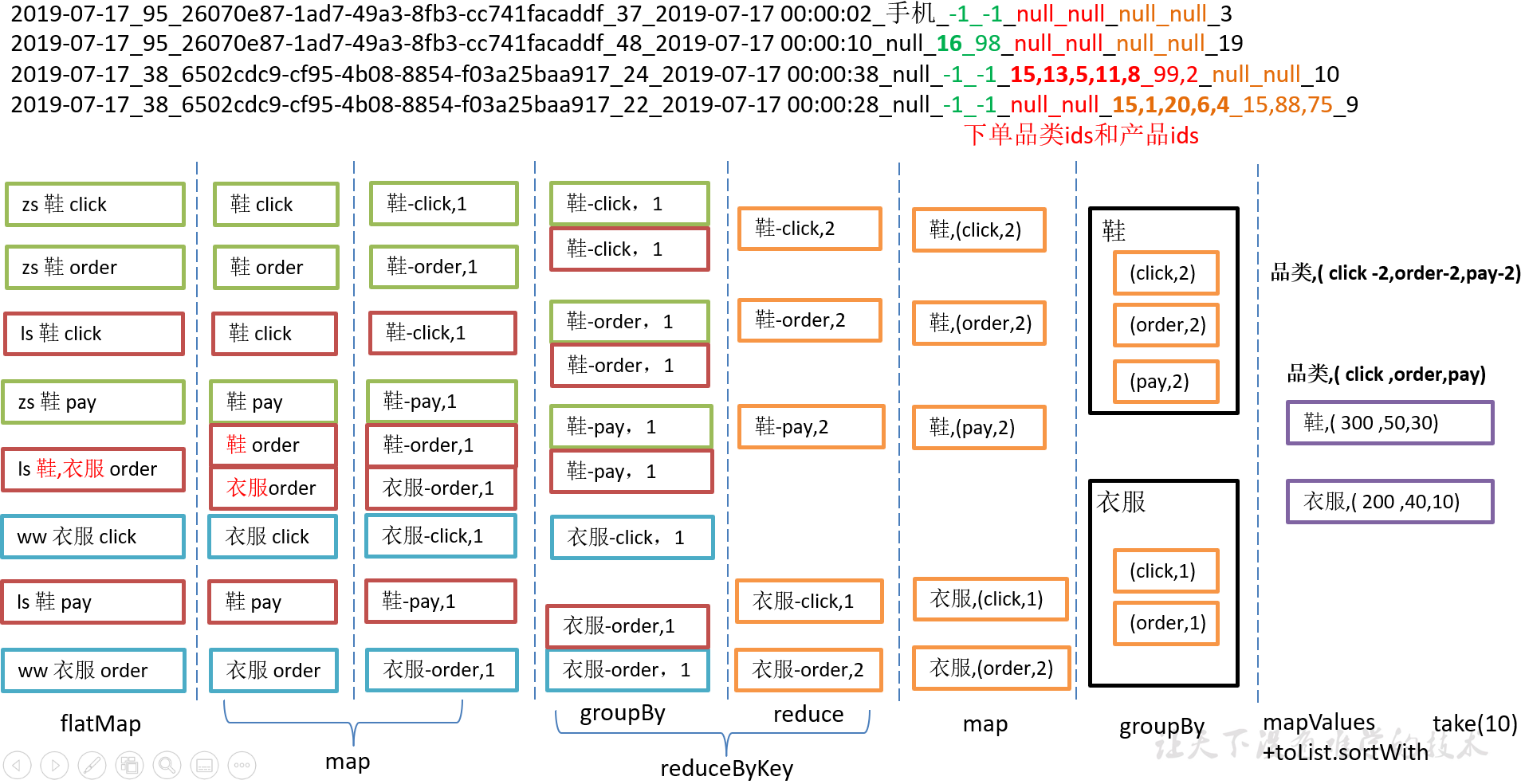
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestWordCountTwo { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //读取数据 val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt") //切割压平 val rdd2: RDD[(String,(Int,Int,Int))] = rdd.flatMap(x=>{ val arr: Array[String] = x.split("_") val clikeid = arr(6) val orderids = arr(8) val payids = arr(10) if (clikeid != "-1"){ (clikeid,(1,0,0)) :: Nil }else if (orderids != "null"){ val ids = orderids.split(",") ids.map(id => (id,(0,1,0))) }else { payids.split(",").map(id => (id,(0,0,1))) } }) //分组统计次数 val rdd3: RDD[(String,(Int,Int,Int))] = rdd2.reduceByKey((agg,curr)=>(agg._1+curr._1,agg._2+curr._2,agg._3+curr._3)) //排序取前十 val rdd4: Array[(String,(Int,Int,Int))] = rdd3.sortBy(_._2,false).take(10) //打印 rdd4.foreach(println) //关闭连接 sc.stop() } }
6.2.3 需求分析(方案三)样例类
采用样例类的方式实现

6.2.4 需求实现(方案三)
1)用来封装用户行为的样例类
package com.yuange.spark.day06 //用户访问动作表 case class UserVisitAction(date: String,//用户点击行为的日期 user_id: Long,//用户的ID session_id: String,//Session的ID page_id: Long,//某个页面的ID action_time: String,//动作的时间点 search_keyword: String,//用户搜索的关键词 click_category_id: Long,//某一个商品品类的ID click_product_id: Long,//某一个商品的ID order_category_ids: String,//一次订单中所有品类的ID集合 order_product_ids: String,//一次订单中所有商品的ID集合 pay_category_ids: String,//一次支付中所有品类的ID集合 pay_product_ids: String,//一次支付中所有商品的ID集合 city_id: Long)//城市 id // 输出结果表 case class CategoryCountInfo(categoryId: String,//品类id clickCount: Long,//点击次数 orderCount: Long,//订单次数 payCount: Long)//支付次数
注意:样例类的属性默认是val修饰,不能修改;需要修改属性,需要采用var修饰。
// 输出结果表 case class CategoryCountInfo(var categoryId: String,//品类id var clickCount: Long,//点击次数 var orderCount: Long,//订单次数 var payCount: Long)//支付次数
2)核心业务代码实现
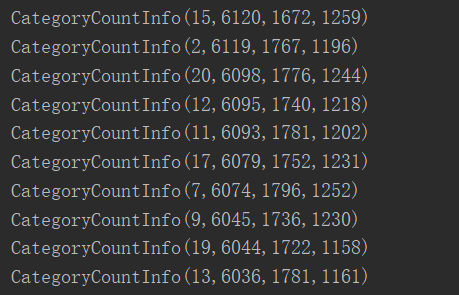
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ListBuffer object TestWordCountThree { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //获取原始数据 val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt") //将原始数据进行转换 var rdd2: RDD[UserVisitAction] = rdd.map(x=>{ //切割 val arrline: Array[String] = x.split("_") // 将解析的数据封装到 UserVisitAction UserVisitAction( arrline(0), arrline(1).toLong, arrline(2), arrline(3).toLong, arrline(4), arrline(5), arrline(6).toLong, arrline(7).toLong, arrline(8), arrline(9), arrline(10), arrline(11), arrline(12).toLong ) }) //将转换后的数据进行分解 var rdd3: RDD[CategoryCountInfo] = rdd2.flatMap{ case info => { if (info.click_category_id != -1){ //点击行为 List(CategoryCountInfo(info.click_category_id.toString,1,0,0)) }else if (info.order_category_ids != "null"){ //点击订单 val list: ListBuffer[CategoryCountInfo] = new ListBuffer[CategoryCountInfo] val ids: Array[String] = info.order_category_ids.split(",") for (i <- ids){ list.append(CategoryCountInfo(i,0,1,0)) } list }else if (info.pay_category_ids != "null"){ //点击支付 val list: ListBuffer[CategoryCountInfo] = new ListBuffer[CategoryCountInfo] val ids: Array[String] = info.pay_category_ids.split(",") for(i <- ids){ list.append(CategoryCountInfo(i,0,0,1)) } list }else{ Nil } } } //将相同的品类分成一组 val rdd4: RDD[(String,Iterable[CategoryCountInfo])] = rdd3.groupBy(x=>{ x.categoryId }) //聚合 val rdd5: RDD[CategoryCountInfo] = rdd4.mapValues(x=>{ x.reduce( (info1, info2) => { info1.orderCount = info1.orderCount + info2.orderCount info1.clickCount = info1.clickCount + info2.clickCount info1.payCount = info1.payCount + info2.payCount info1 } ) }).map(_._2) //排序取前十 rdd5.sortBy(x=>{ (x.clickCount,x.orderCount,x.payCount) },false).take(10).foreach(println) //关闭连接 sc.stop() } }
6.2.5 需求分析(方案四)样例类+算子优化
针对方案三中的groupBy,没有提前聚合的功能,替换成reduceByKey
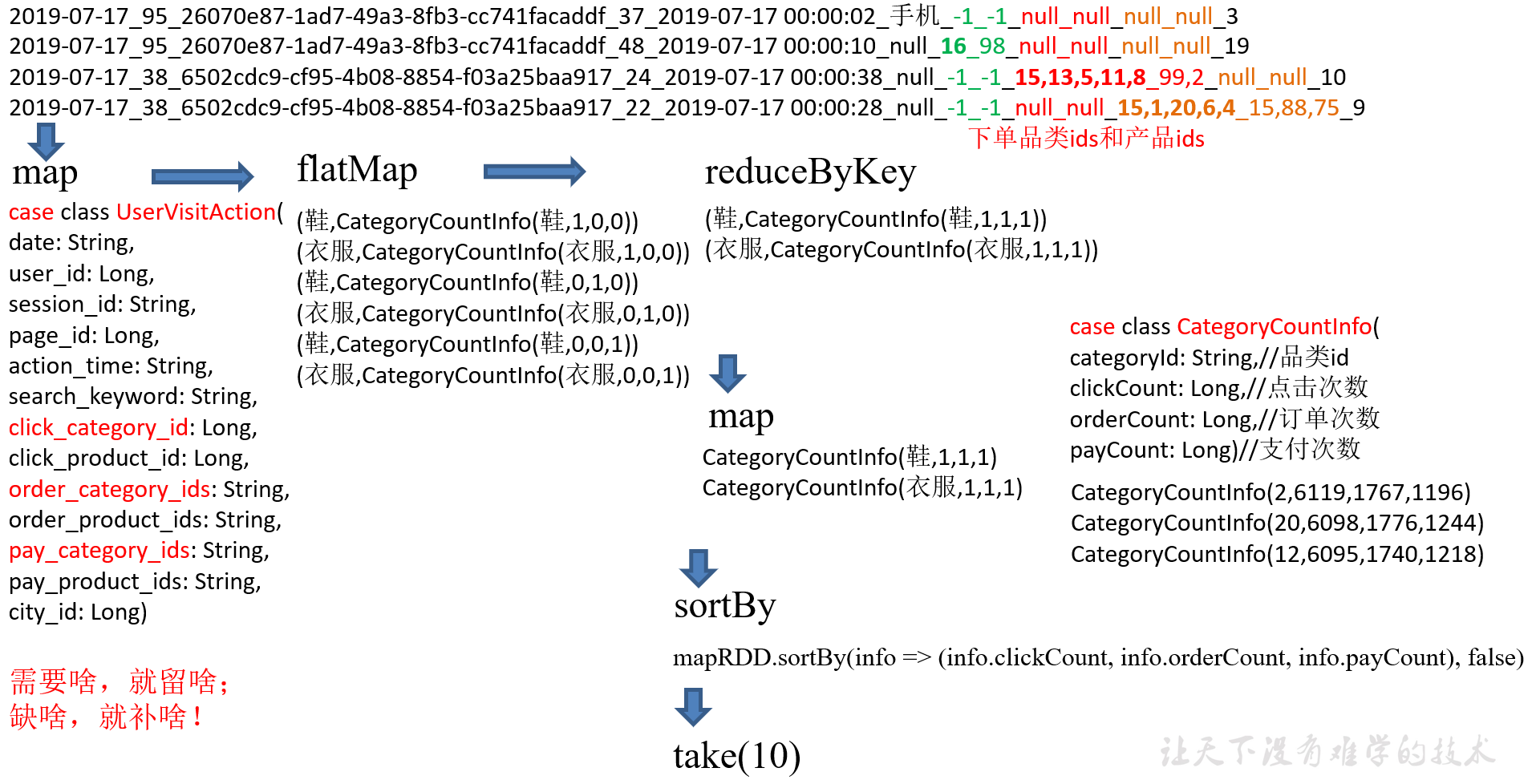
6.2.6 需求实现(方案四)
1)样例类代码
package com.yuange.spark.day06 //用户访问动作表 case class UserVisitAction(date: String,//用户点击行为的日期 user_id: Long,//用户的ID session_id: String,//Session的ID page_id: Long,//某个页面的ID action_time: String,//动作的时间点 search_keyword: String,//用户搜索的关键词 click_category_id: Long,//某一个商品品类的ID click_product_id: Long,//某一个商品的ID order_category_ids: String,//一次订单中所有品类的ID集合 order_product_ids: String,//一次订单中所有商品的ID集合 pay_category_ids: String,//一次支付中所有品类的ID集合 pay_product_ids: String,//一次支付中所有商品的ID集合 city_id: Long)//城市 id // 输出结果表 case class CategoryCountInfo(var categoryId: String,//品类id var clickCount: Long,//点击次数 var orderCount: Long,//订单次数 var payCount: Long)//支付次数
2)核心代码实现
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ListBuffer object TestWordCountFour { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //获取原始数据 val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt") //将原始数据进行转换 var rdd2: RDD[UserVisitAction] = rdd.map(x=>{ //切割 val arrline: Array[String] = x.split("_") // 将解析的数据封装到 UserVisitAction UserVisitAction( arrline(0), arrline(1).toLong, arrline(2), arrline(3).toLong, arrline(4), arrline(5), arrline(6).toLong, arrline(7).toLong, arrline(8), arrline(9), arrline(10), arrline(11), arrline(12).toLong ) }) //将转换后的数据进行分解 var rdd3: RDD[(String,CategoryCountInfo)] = rdd2.flatMap{ case info => { info match { case user: UserVisitAction =>{ if (user.click_category_id != -1){ //点击行为 List((user.click_category_id.toString,CategoryCountInfo(info.click_category_id.toString,1,0,0))) }else if (user.order_category_ids != "null"){ //点击订单 val list: ListBuffer[(String,CategoryCountInfo)] = new ListBuffer[(String,CategoryCountInfo)] val ids: Array[String] = user.order_category_ids.split(",") for (i <- ids){ list.append((i,CategoryCountInfo(i,0,1,0))) } list }else if (user.pay_category_ids != "null"){ //点击支付 val list: ListBuffer[(String,CategoryCountInfo)] = new ListBuffer[(String,CategoryCountInfo)] val ids: Array[String] = info.pay_category_ids.split(",") for(i <- ids){ list.append((i,CategoryCountInfo(i,0,0,1))) } list }else{ Nil } } case _ => Nil } } } //将相同的品类分成一组 val rdd4: RDD[CategoryCountInfo] = rdd3.reduceByKey((One,Two)=>{ One.orderCount =One.orderCount + Two.orderCount One.clickCount = One.clickCount + Two.clickCount One.payCount = One.payCount + Two.payCount One }).map(_._2) //排序取前十 rdd4.sortBy(x=>{ (x.clickCount,x.orderCount,x.payCount) },false).take(10).foreach(println) //关闭连接 sc.stop() } }
6.2.7 需求分析(方案五)累加器

6.2.8 需求实现(方案五)
1)累加器实现
package com.yuange.spark.day06 import org.apache.spark.util.AccumulatorV2 import scala.collection.mutable class CategoryCountAccumulator extends AccumulatorV2[UserVisitAction,mutable.Map[(String,String),Long]]{ var map: mutable.Map[(String,String),Long] = mutable.Map[(String,String),Long]() override def isZero: Boolean = map.isEmpty override def copy(): AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]] = new CategoryCountAccumulator() override def reset(): Unit = map.clear() override def add(v: UserVisitAction): Unit = { if (v.click_category_id != -1){ val key = (v.click_category_id.toString,"click") map(key) = map.getOrElse(key,0) + 1L }else if (v.order_category_ids != "null"){ val ids: Array[String] = v.order_category_ids.split(",") for (id <- ids){ val key = (id,"order") map(key) = map.getOrElse(key,0L) + 1L } }else if (v.pay_category_ids != "null"){ val ids: Array[String] = v.pay_category_ids.split(",") for (id <- ids){ val key = (id,"pay") map(key) = map.getOrElse(key,0L) + 1L } } } override def merge(other: AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]]): Unit = { other.value.foreach{ case (category,number) => { map(category) = map.getOrElse(category,0L) + number } } } override def value: mutable.Map[(String, String), Long] = map }
2)核心逻辑实现
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} import scala.collection.{immutable, mutable} object TestWordCountFive { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //3.1 获取原始数据 val lineRDD: RDD[String] = sc.textFile("datas/user_visit_action.txt") //3.2 将原始数据进行转换 val actionRDD: RDD[UserVisitAction] = lineRDD.map { line => { val datas: Array[String] = line.split("_") UserVisitAction( datas(0), datas(1).toLong, datas(2), datas(3).toLong, datas(4), datas(5), datas(6).toLong, datas(7).toLong, datas(8), datas(9), datas(10), datas(11), datas(12).toLong ) } } //3.5 创建累加器 val acc: CategoryCountAccumulator = new CategoryCountAccumulator() //3.6 注册累加器 sc.register(acc, "CategoryCountAccumulator") //3.7 累加器添加数据 actionRDD.foreach(action => acc.add(action)) //3.8 获取累加器的值 // ((鞋,click),10) // ((鞋,order),5) // =>(鞋,(click,order,pay))=>CategoryCountInfo val accMap: mutable.Map[(String, String), Long] = acc.value // 3.9 将累加器的值进行结构的转换 val group: Map[String, mutable.Map[(String, String), Long]] = accMap.groupBy(_._1._1) val infoes: immutable.Iterable[CategoryCountInfo] = group.map { case (id, map) => { val click = map.getOrElse((id, "click"), 0L) val order = map.getOrElse((id, "order"), 0L) val pay = map.getOrElse((id, "pay"), 0L) CategoryCountInfo(id, click, order, pay) } } //3.10 将转换后的数据进行排序(降序),取前10 infoes.toList.sortWith( (left,right)=>{ if (left.clickCount > right.clickCount){ true }else if(left.clickCount == right.clickCount){ if (left.orderCount > right.orderCount){ true }else if(left.orderCount == right.orderCount){ left.payCount > right.payCount }else { false } }else{ false } } ).take(10).foreach(println) //4.关闭连接 sc.stop() } }
6.3 需求2:Top10热门品类中每个品类的Top10活跃Session统计
6.3.1 需求分析

6.3.2 需求实现
1)累加器实现
package com.yuange.spark.day06 import org.apache.spark.util.AccumulatorV2 import scala.collection.mutable class CategoryCountAccumulator extends AccumulatorV2[UserVisitAction,mutable.Map[(String,String),Long]]{ var map: mutable.Map[(String,String),Long] = mutable.Map[(String,String),Long]() override def isZero: Boolean = map.isEmpty override def copy(): AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]] = new CategoryCountAccumulator() override def reset(): Unit = map.clear() override def add(v: UserVisitAction): Unit = { if (v.click_category_id != -1){ val key = (v.click_category_id.toString,"click") map(key) = map.getOrElse(key,0L) + 1L }else if (v.order_category_ids != "null"){ val ids: Array[String] = v.order_category_ids.split(",") for (id <- ids){ val key = (id,"order") map(key) = map.getOrElse(key,0L) + 1L } }else if (v.pay_category_ids != "null"){ val ids: Array[String] = v.pay_category_ids.split(",") for (id <- ids){ val key = (id,"pay") map(key) = map.getOrElse(key,0L) + 1L } } } override def merge(other: AccumulatorV2[UserVisitAction, mutable.Map[(String, String), Long]]): Unit = { other.value.foreach{ case (category,number) => { map(category) = map.getOrElse(category,0L) + number } } } override def value: mutable.Map[(String, String), Long] = map }
2)核心逻辑实现
package com.yuange.spark.day06 import org.apache.spark.broadcast.Broadcast import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD import scala.collection.{immutable, mutable} object TestWordCountSix { def main(args: Array[String]): Unit = { //1.创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]") //2.创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //3.1 获取原始数据 val dataRDD: RDD[String] = sc.textFile("datas/user_visit_action.txt") //3.2 将原始数据进行转换 val actionRDD: RDD[UserVisitAction] = dataRDD.map { data => { val datas: Array[String] = data.split("_") UserVisitAction( datas(0), datas(1).toLong, datas(2), datas(3).toLong, datas(4), datas(5), datas(6).toLong, datas(7).toLong, datas(8), datas(9), datas(10), datas(11), datas(12).toLong ) } } //3.5 创建累加器 val acc: CategoryCountAccumulator = new CategoryCountAccumulator() //3.6 注册累加器 sc.register(acc, "CategoryCountAccumulator") //3.7 累加器添加数据 actionRDD.foreach(action => acc.add(action)) //3.8 获取累加器的值 // ((鞋,click),10) // ((鞋,order),5) // =>(鞋,(click,order,pay))=>CategoryCountInfo val accMap: mutable.Map[(String, String), Long] = acc.value // 3.9 将累加器的值进行结构的转换 val group: Map[String, mutable.Map[(String, String), Long]] = accMap.groupBy(_._1._1) val infoes: immutable.Iterable[CategoryCountInfo] = group.map { case (id, map) => { val click = map.getOrElse((id, "click"), 0L) val order = map.getOrElse((id, "order"), 0L) val pay = map.getOrElse((id, "pay"), 0L) CategoryCountInfo(id, click, order, pay) } } //3.10 将转换后的数据进行排序(降序),取前10 val sort: List[CategoryCountInfo] = infoes.toList.sortWith( (left, right) => { if (left.clickCount > right.clickCount) { true } else if (left.clickCount == right.clickCount) { if (left.orderCount > right.orderCount) { true } else if (left.orderCount == right.orderCount) { left.payCount > right.payCount } else { false } } else { false } } ) val top10Info: List[CategoryCountInfo] = sort.take(10) //********************需求二******************************** //4.1 获取Top10热门品类 val ids: List[String] = top10Info.map(_.categoryId) //4.2 ids变成广播变量 val broadcastIds: Broadcast[List[String]] = sc.broadcast(ids) //4.3 将原始数据进行过滤(保留前10热门品类的数据,保留点击数据) val filterActionRDD: RDD[UserVisitAction] = actionRDD.filter( action => { if (action.click_category_id != -1) { broadcastIds.value.contains(action.click_category_id.toString) } else { false } } ) //4.4 对session点击次数进行转换:(categoryid-session, 1) val idAndSessionToOneRDD: RDD[(String, Int)] = filterActionRDD.map( action => (action.click_category_id + "--" + action.session_id, 1) ) //4.5 对session点击次数进行统计:(categoryid-session, sum) val idAndSessionToSumRDD: RDD[(String, Int)] = idAndSessionToOneRDD.reduceByKey(_+_) //4.6 将统计结果进行结构的转换:(categoryid, (session,sum)) val idToSessionAndSumRDD: RDD[(String, (String, Int))] = idAndSessionToSumRDD.map { case (key, sum) => { val keys: Array[String] = key.split("--") (keys(0), (keys(1), sum)) } } //4.7 将转换结构后的数据根据品类进行分组:(categoryid, Iterator[(session,sum)]) val idToSessionAndSumGroupRDD: RDD[(String, Iterable[(String, Int)])] = idToSessionAndSumRDD.groupByKey() //4.8 将分组后的数据进行排序(降序),取前10名 val resultRDD: RDD[(String, List[(String, Int)])] = idToSessionAndSumGroupRDD.mapValues { datas => { datas.toList.sortWith( (left, right) => { left._2 > right._2 } ).take(10) } } resultRDD.collect().foreach(println) //5.关闭连接 sc.stop() } }
6.4 需求3:页面单跳转化率统计
6.4.1 需求分析
1)页面单跳转化率
计算页面单跳转化率,什么是页面单跳转换率,比如一个用户在一次 Session 过程中访问的页面路径 3,5,7,9,10,21,那么页面 3 跳到页面 5 叫一次单跳,7-9 也叫一次单跳,那么单跳转化率就是要统计页面点击的概率。
比如:计算 3-5 的单跳转化率,先获取符合条件的 Session 对于页面 3 的访问次数(PV)为 A,然后获取符合条件的 Session 中访问了页面 3 又紧接着访问了页面 5 的次数为 B,那么 B/A 就是 3-5 的页面单跳转化率。

2)统计页面单跳转化率意义
产品经理和运营总监,可以根据这个指标,去尝试分析,整个网站,产品,各个页面的表现怎么样,是不是需要去优化产品的布局;吸引用户最终可以进入最后的支付页面,数据分析师,可以此数据做更深一步的计算和分析,企业管理层,可以看到整个公司的网站,各个页面的之间的跳转的表现如何,可以适当调整公司的经营战略或策略。
3)需求详细描述
在该模块中,需要根据查询对象中设置的Session过滤条件,先将对应得Session过滤出来,然后根据查询对象中设置的页面路径,计算页面单跳转化率,比如查询的页面路径为:3、5、7、8,那么就要计算3-5、5-7、7-8的页面单跳转化率,需要注意的一点是,页面的访问是有先后的,要做好排序。
1、2、3、4、5、6、7 1-2/ 1 2-3/2 3-4/3 4-5/4 5-6/5 6-7/6
4)需求分析
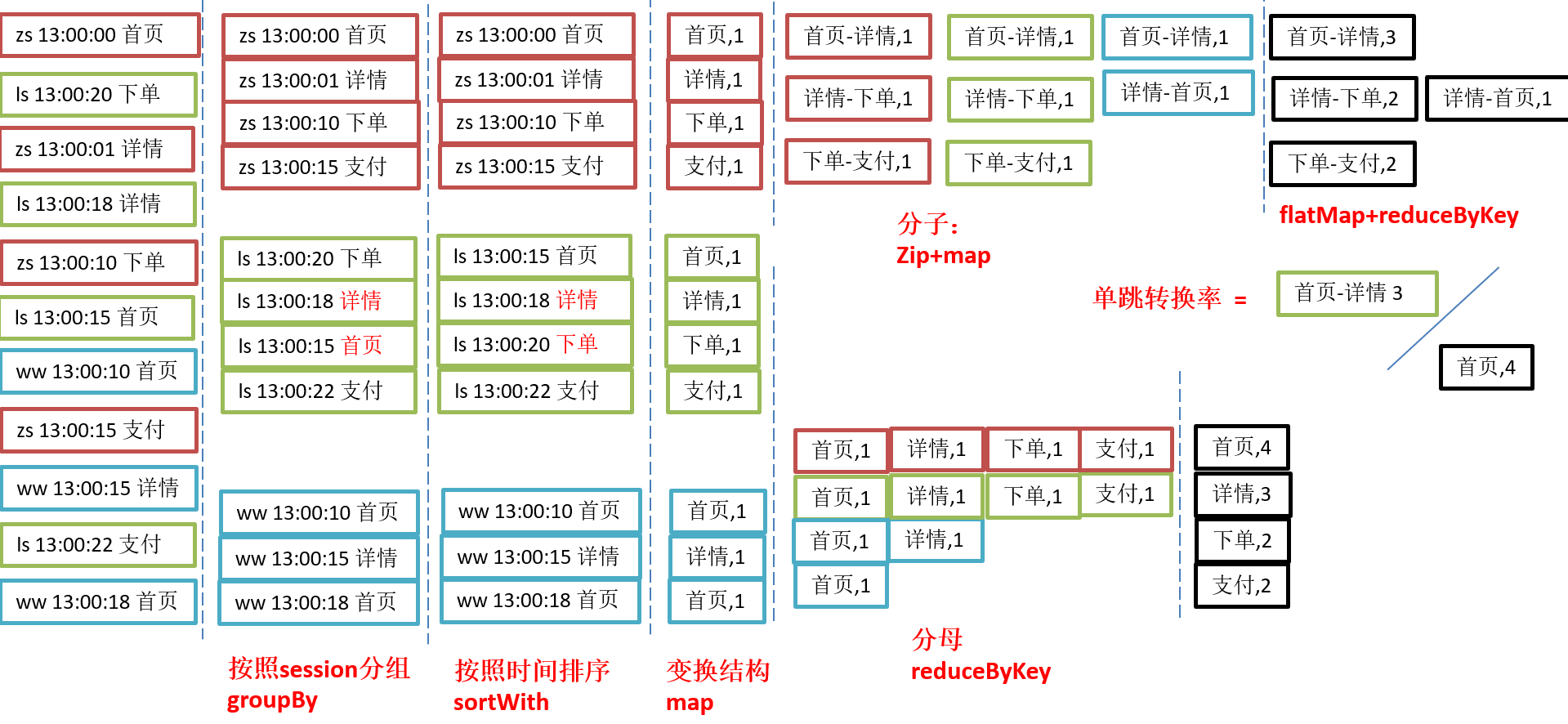


6.4.2 需求实现
方式一:
package com.yuange.spark.day06 import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} object TestWordCountSeven { def main(args: Array[String]): Unit = { //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //获取数据 val rdd: RDD[String] = sc.textFile("datas/user_visit_action.txt") //将数据结构进行转换 val rdd2: RDD[UserVisitAction] = rdd.map { line => { val datas: Array[String] = line.split("_") UserVisitAction( datas(0), datas(1).toLong, datas(2), datas(3).toLong, datas(4), datas(5), datas(6).toLong, datas(7).toLong, datas(8), datas(9), datas(10), datas(11), datas(12).toLong ) } } //定义要统计的页面(只统计集合中规定的页面跳转率) val ids = List(1, 2, 3, 4, 5, 6, 7) //过滤数据 val rdd3: List[String] = ids.zip(ids.tail).map{ case (pageOne,pageTwo) => pageOne + "-" + pageTwo } //计算分母 val fenmuMap: Map[Long,Long] = rdd2 .filter(x=> ids.init.contains(x.page_id)) //过滤出要统计的page_id .map(x=>(x.page_id,1L)) //变换结构 .reduceByKey(_ + _).collect().toMap //统计每个页面的总次数 //计算分子 val rdd4: RDD[(String,Iterable[UserVisitAction])] = rdd2.groupBy(_.session_id) //将分组后的数据根据时间进行排序(升序) val rdd5: RDD[List[String]] = rdd4.mapValues(x=>{ val action: List[UserVisitAction] = x.toList.sortWith((left,right)=>{ left.action_time < right.action_time }) //获取pageid val pageids: List[Long] = action.map(_.page_id) //形成单跳元组 val dantiaoList: List[(Long,Long)] = pageids.zip(pageids.tail) //变换结构 val dantiaoList2 = dantiaoList.map{ case (pageOne,pageTwo) => { pageOne + "-" + pageTwo } } //再次过滤 dantiaoList2.filter(x=>rdd3.contains(x)) }).map(_._2) //聚合 val rdd6: RDD[(String,Long)] = rdd5.flatMap(x=>x).map((_,1L)).reduceByKey(_ + _) //计算页面单跳率 rdd6.foreach{ case (pageflow,sum) => { val pageIds: Array[String] = pageflow.split("-") val pageidSum: Long = fenmuMap.getOrElse(pageIds(0).toLong,1L) println(pageflow + "=" + sum.toDouble / pageidSum) } } //关闭连接 sc.stop() } }
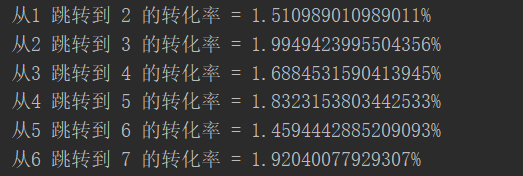
方式二:
package com.yuange.spark.day06 import org.apache.spark.{SparkConf, SparkContext} object TestWordCountEight { def main(args: Array[String]): Unit = { //待统计的页面转化率 val list = List(1,2,3,4,5,6,7) val pages = list.init.zip(list.tail) val sc = new SparkContext(new SparkConf().setMaster("local[4]").setAppName("test")) //1、读取数据 val datas = sc.textFile("datas/user_visit_action.txt") //2、是否过滤【不用】 是否去重【不用】 是否列裁剪【sessionid、页面id、时间】 val rdd1 = datas.map(line=>{ val arr = line.split("_") (arr(2),arr(3).toInt,arr(4)) }) //3、统计每个页面的访问的总人数【分母】 //3.1、过滤出 1,2,3,4,5,6,7 的数据 val rdd2 = rdd1.filter(x=>list.contains(x._2)) //3.2、数据类型转换 (页面id,1) val rdd3 = rdd2.map(x=>(x._2,1)) //3.3、统计并转换成map结构 val fmRdd = rdd3.reduceByKey(_+_) val fmMap = fmRdd.collect().toMap //4、统计每个会话中页面跳转的总人数【分子】 //4.1、按照session分组 val rdd4 = rdd1.groupBy{ case (session,page,time) => session } //[ // sessionid1 -> List( (sessionid1,page1,time1),(sessionid1,page5,time5) ,(sessionid1,page2,time2),..) // ] //4.2、对每个sesession中的数据按照时间进行排序 val rdd5 = rdd4.flatMap(x=>{ //x = sessionid1 -> List( (sessionid1,page1,time1),(sessionid1,page5,time5) ,(sessionid1,page2,time2)) val sortedList = x._2.toList.sortBy(_._3) val windowList = sortedList.sliding(2) //[ // List( (sessionid1,page1,time1) ,(sessionid1,page2,time2) ) // ... // ] //4.3、对数据两两组合,得到跳转 val toList = windowList.map(y=>{ // y = List( (sessionid1,page1,time1) ,(sessionid1,page2,time2) ) val fromPage = y.head._2 val toPage = y.last._2 ((fromPage,toPage),1) }) //4.4、过滤需要统计的跳转页面 val fzList = toList.filter{ case ((fromPage,toPage),num) => pages.contains((fromPage,toPage)) } fzList }) //4.5、统计页面跳转的总次数并转换为map val fzRdd = rdd5.reduceByKey(_+_) val fzMap = fzRdd.collect().toMap //5、统计转化率 pages.foreach{ case (frompage,topage)=> val fz = fzMap.getOrElse((frompage,topage),0) val fm = fmMap.getOrElse(frompage,1) val lv = fz.toDouble/fm println(s"从${frompage} 跳转到 ${topage} 的转化率 = ${lv * 100}%") } //关闭连接 sc.stop() } }
6.5 需求:求出用户行为轨迹
6.5.1 数据准备
val list = List[(String,String,String)]( ("1001","2020-09-10 10:21:21","home.html"), ("1001","2020-09-10 10:28:10","good_list.html"), ("1001","2020-09-10 10:35:05","good_detail.html"), ("1001","2020-09-10 10:42:55","cart.html"), ("1001","2020-09-10 11:35:21","home.html"), ("1001","2020-09-10 11:36:10","cart.html"), ("1001","2020-09-10 11:38:12","trade.html"), ("1001","2020-09-10 11:40:00","payment.html"), ("1002","2020-09-10 09:40:00","home.html"), ("1002","2020-09-10 09:41:00","mine.html"), ("1002","2020-09-10 09:42:00","favor.html"), ("1003","2020-09-10 13:10:00","home.html"), ("1003","2020-09-10 13:15:00","search.html") ) 需求: 分析每个用户每次会话的行为轨迹 val list = List[(String,String,String)]( (1,"1001","2020-09-10 10:21:21","home.html",1), (1,"1001","2020-09-10 10:28:10","good_list.html",2), (1,"1001","2020-09-10 10:35:05","good_detail.html",3), (1,"1001","2020-09-10 10:42:55","cart.html",4), (B,"1001","2020-09-10 11:35:21","home.html",1), (B,"1001","2020-09-10 11:36:10","cart.html",2), (B,"1001","2020-09-10 11:38:12","trade.html",3), (B,"1001","2020-09-10 11:40:00","payment.html",4), (C,"1002","2020-09-10 09:40:00","home.html",1), (C,"1002","2020-09-10 09:41:00","mine.html",2), (C,"1002","2020-09-10 09:42:00","favor.html",3), (D,"1003","2020-09-10 13:10:00","home.html",1), (D,"1003","2020-09-10 13:15:00","search.html",2) )
6.5.2 代码实现(一)
package com.yuange.spark.day06 import java.text.SimpleDateFormat import java.util.UUID import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} case class UserAnalysis(userid: String,time: Long,page: String,var session: String=UUID.randomUUID().toString,var step: Int=1) object TestUserAction { def main(args: Array[String]): Unit = { //数据 val list = List[(String,String,String)]( ("1001","2020-09-10 10:21:21","home.html"), ("1001","2020-09-10 10:28:10","good_list.html"), ("1001","2020-09-10 10:35:05","good_detail.html"), ("1001","2020-09-10 10:42:55","cart.html"), ("1001","2020-09-10 11:35:21","home.html"), ("1001","2020-09-10 11:36:10","cart.html"), ("1001","2020-09-10 11:38:12","trade.html"), ("1001","2020-09-10 11:40:00","payment.html"), ("1002","2020-09-10 09:40:00","home.html"), ("1002","2020-09-10 09:41:00","mine.html"), ("1002","2020-09-10 09:42:00","favor.html"), ("1003","2020-09-10 13:10:00","home.html"), ("1003","2020-09-10 13:15:00","search.html") ) //创建SparkConf并设置App名称 val conf: SparkConf = new SparkConf().setAppName("TestSparkRDD").setMaster("local[*]") //创建SparkContext,该对象是提交Spark App的入口 val sc: SparkContext = new SparkContext(conf) //创建RDD val rdd: RDD[(String,String,String)] = sc.parallelize(list) //转换数据类型 val rdd2: RDD[UserAnalysis] = rdd.map{ case (userid,timestr,page) => { val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") val time = format.parse(timestr).getTime UserAnalysis(userid,time,page) } } //按照用户分组 val rdd3: RDD[(String,Iterable[UserAnalysis])] = rdd2.groupBy(x=>x.userid) //对每个用户的所有数据排序 val rdd4: RDD[UserAnalysis] = rdd3.flatMap(x=>{ //按时间排序 val sortList: List[UserAnalysis] = x._2.toList.sortBy(_.time) //滑窗 val slidingList = sortList.sliding(2) //两两比较,是否属于同一次回话(若属于同一次回话,修改sessionid和step) slidingList.foreach(y=>{ val first = y.head val next = y.last if (next.time - first.time <= 30 * 60 * 1000){ next.session = first.session next.step = first.step + 1 } }) x._2 }) //打印 rdd4.foreach(println) //关闭连接 sc.stop() } }
6.5.2 代码实现(二)
package com.yuange.spark.day06 import java.text.SimpleDateFormat import scala.collection.mutable.ListBuffer object TestUserActionTwo { def main(args: Array[String]): Unit = { //数据准备 val list = List[(String,String,String)]( ("1001","2020-09-10 10:21:21","home.html"), ("1001","2020-09-10 10:28:10","good_list.html"), ("1001","2020-09-10 10:35:05","good_detail.html"), ("1001","2020-09-10 10:42:55","cart.html"), ("1001","2020-09-10 11:35:21","home.html"), ("1001","2020-09-10 11:36:10","cart.html"), ("1001","2020-09-10 11:38:12","trade.html"), ("1001","2020-09-10 11:40:00","payment.html"), ("1002","2020-09-10 09:40:00","home.html"), ("1002","2020-09-10 09:41:00","mine.html"), ("1002","2020-09-10 09:42:00","favor.html"), ("1003","2020-09-10 13:10:00","home.html"), ("1003","2020-09-10 13:15:00","search.html") ) //按照用户分组 val groupList: Map[String,List[(String,String,String)]] = list.groupBy(x=>x._1) //转换数据结构 groupList.flatMap(x=>{ val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") //对每个用户的数据按时间排序 val userList: List[(String,String,String)] = x._2.toList val sortList: List[(String,String,String)] = userList.sortBy(y=>y._2) //取出第一条数据 val firstUser: (String,String,String) = sortList(0) //初始化session var sessionid = 1 //初始化step var step = 0 //创建结果集 val result = ListBuffer[(Int,String,Long,String,Int)]() //将第一条数据添加到结果集 result.+=((sessionid,firstUser._1,format.parse(firstUser._2).getTime,firstUser._3,step)) //对排序好的sortList数据集进行遍历 (1 until sortList.size).foreach(index=>{ step = step + 1 //本次时间 val nextTime = format.parse(sortList(index)._2).getTime //上次时间 var firstTiem = format.parse(sortList(index-1)._2).getTime //如果本次时间-上次时间<=30分钟,属于同一次会话 if (nextTime - firstTiem <= 30 * 60 * 1000){ result.+=((sessionid,sortList(index)._1,nextTime,sortList(index)._3,step)) }else{ //修改sessionid sessionid = sessionid + 1 //新会话,重置step step = 1 result.+=((sessionid,sortList(index)._1,nextTime,sortList(index)._3,step)) } }) //返回结果集 result }).foreach(println(_)) } }
6.6 需求:统计每个用户一小时内的最大登录次数
6.6.1 数据准备
user_id,login_time a,2020-07-11 10:51:12 a,2020-07-11 11:05:00 a,2020-07-11 11:15:20 a,2020-07-11 11:25:05 a,2020-07-11 11:45:00 a,2020-07-11 11:55:36 a,2020-07-11 11:59:56 a,2020-07-11 12:35:12 a,2020-07-11 12:58:59 b,2020-07-11 14:51:12 b,2020-07-11 14:05:00 b,2020-07-11 15:15:20 b,2020-07-11 15:25:05 b,2020-07-11 16:45:00 b,2020-07-11 16:55:36 b,2020-07-11 16:59:56 b,2020-07-11 17:35:12 b,2020-07-11 17:58:59
6.6.2 代码实现
select t.user_id,max(t.num) from( select a.user_id,a.login_time,count(1) num from user_info a inner join user_info b on a.user_id = b.user_id and unix_timestamp(b.login_time) - unix_timestamp(a.login_time) <= 3600 and unix_timestamp(b.login_time)>= unix_timestamp(a.login_time) group by a.user_id,a.login_time ) t group by t.user_id