第1章 需求分析
1.1 灵活查询的场景
数仓中存储了大量的明细数据,但是Hadoop存储的数仓计算必须经过MR,所以即时交互性非常糟糕。为了方便数据分析人员查看信息,数据平台需要提供一个能够根据文字及选项等条件,进行灵活分析判断的数据功能。
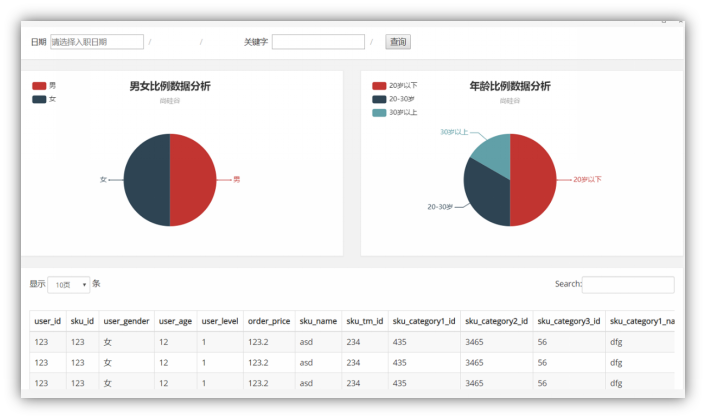
1.2 需求详细
输入参数
|
日期 |
查询数据的日期 |
|
关键字 |
根据商品名称涉及到的词进行搜索 |
返回结果
|
饼图 |
男女比例占比 |
男 ,女 |
|
年龄比例占比 |
20岁以下,20-30岁,30岁以上 |
|
|
购买行为数据明细 |
包括,用户id,性别年龄,级别,购买的时间,商品价格,订单状态,等信息。 可翻页。 |
|
第2章 架构分析
2.1 T+1 模式
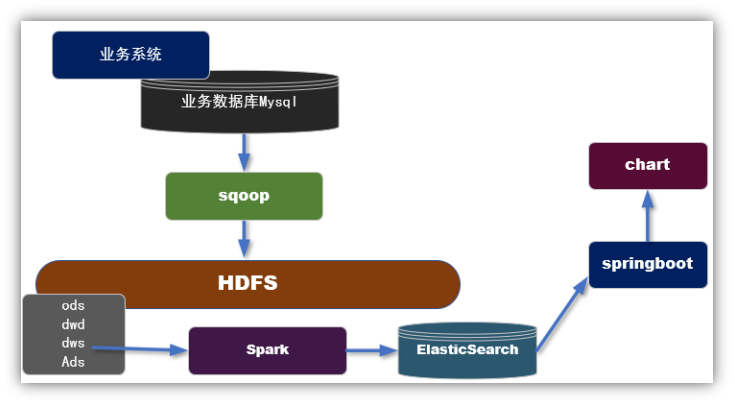
2.1.1 实现步骤
1)利用sqoop等工具,从业务数据库中批量抽取数据;
2)利用数仓作业,在dws层组织宽表(用户购买行为);
3)开发spark的批处理任务,把dws层的宽表导入到ES中;
4)从ES读取数据发布接口,对接可视化模块。
2.1.2 特点
优点:可以利用在离线作业处理好的dws层宽表,直接导出一份到ES进行快速交互的分析。
缺点:因为要用离线处理的后的结果在放入ES,所以时效性等同于离线数据。
2.2 T+0 模式
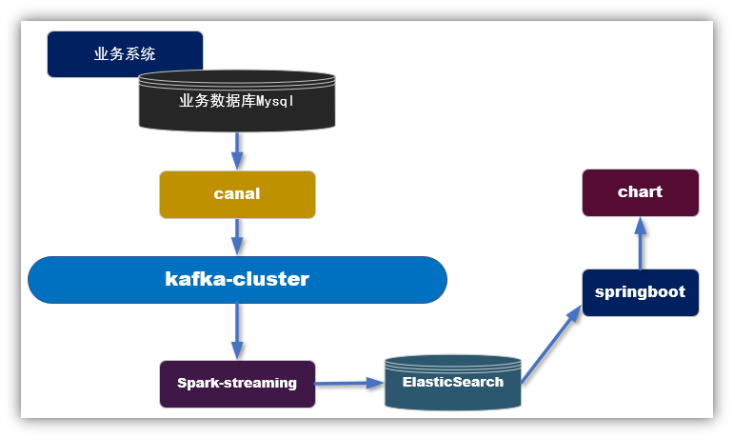
2.2.1 实现步骤
1)利用canal抓取对应的数据表的实时新增变化数据,推送到Kafka;
2)在spark-streaming中进行转换,过滤,关联组合成宽表的结构;
3)保存到ES中;
4)从ES读取数据发布接口,对接可视化模块。
2.2.2 特点
优点:实时产生数据,时效性非常高。
缺点:因为从kafka中得到的是原始数据,所以要利用spark-streaming要进行加工处理,相对来说要比批处理方式麻烦,比如join操作,其中存在网络延迟问题。
第3章 实时采集数据
3.1 在Canal 模块中增加要追踪的表
1)在gmall_common模块中添加两个常量
public static final String GMALL_ORDER_DETAIL = "GMALL_ORDER_DETAIL"; //gmall_order_detail public static final String GMALL_USER_INFO = "GMALL_USER_INFO"; //gmall_user_info
2)修改gmall_canalclient模块中的MyClient类
package com.yuange.canal; import com.alibaba.fastjson.JSONObject; import com.alibaba.otter.canal.client.CanalConnector; import com.alibaba.otter.canal.client.CanalConnectors; import com.alibaba.otter.canal.protocol.CanalEntry; import com.alibaba.otter.canal.protocol.Message; import com.google.protobuf.ByteString; import com.google.protobuf.InvalidProtocolBufferException; import com.yuange.constants.Constants; import java.net.InetSocketAddress; import java.util.List; import java.util.Random; /** * @作者:袁哥 * @时间:2021/7/7 18:10 * 步骤: * ①创建一个客户端:CanalConnector(SimpleCanalConnector: 单节点canal集群、ClusterCanalConnector: HA canal集群) * ②使用客户端连接 canal server * ③指定客户端订阅 canal server中的binlog信息 * ④解析binlog信息 * ⑤写入kafka * * 消费到的数据的结构: * Message: 代表拉取的一批数据,这一批数据可能是多个SQL执行,造成的写操作变化 * List<Entry> entries : 每个Entry代表一个SQL造成的写操作变化 * id : -1 说明没有拉取到数据 * Entry: * CanalEntry.Header header_ : 头信息,其中包含了对这条sql的一些说明 * private Object tableName_: sql操作的表名 * EntryType; Entry操作的类型 * 开启事务: 写操作 begin * 提交事务: 写操作 commit * 对原始数据进行影响的写操作: rowdata * update、delete、insert * ByteString storeValue_: 数据 * 序列化数据,需要使用工具类RowChange,进行转换,转换之后获取到一个RowChange对象 */ public class MyClient { public static void main(String[] args) throws InterruptedException, InvalidProtocolBufferException { /** * 创建一个canal客户端 * public static CanalConnector newSingleConnector( * SocketAddress address, //指定canal server的主机名和端口号 * tring destination, //参考/opt/module/canal/conf/canal.properties中的canal.destinations 属性值 * String username, //不是instance.properties中的canal.instance.dbUsername * String password //参考AdminGuide(从canal 1.1.4 之后才提供的),链接地址:https://github.com/alibaba/canal/wiki/AdminGuide * ) {...} * */ CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("hadoop104", 11111), "example", "", ""); //使用客户端连接 canal server canalConnector.connect(); //指定客户端订阅 canal server中的binlog信息 只统计在Order_info表 canalConnector.subscribe("gmall_realtime.*"); //不停地拉取数据 Message[id=-1,entries=[],raw=false,rawEntries=[]] 代表当前这批没有拉取到数据 while (true){ Message message = canalConnector.get(100); //判断是否拉取到了数据,如果没有拉取到,歇一会再去拉取 if (message.getId() == -1){ System.out.println("暂时没有数据,先等会"); Thread.sleep(5000); continue; } // 数据的处理逻辑 List<CanalEntry.Entry> entries = message.getEntries(); for (CanalEntry.Entry entry : entries) { //判断这个entry的类型是不是rowdata类型,只处理rowdata类型 if (entry.getEntryType().equals(CanalEntry.EntryType.ROWDATA)){ ByteString storeValue = entry.getStoreValue(); //数据 String tableName = entry.getHeader().getTableName(); //表名 handleStoreValue(storeValue,tableName); } } } } private static void handleStoreValue(ByteString storeValue, String tableName) throws InvalidProtocolBufferException { //将storeValue 转化为 RowChange CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue); /** * 一个RowChange代表多行数据 * order_info: 可能会执行的写操作类型,统计GMV total_amount * insert : 会-->更新后的值 * update : 不会-->只允许修改 order_status * delete : 不会,数据是不允许删除 * 判断当前这批写操作产生的数据是不是insert语句产生的 * */ // 采集 order_info 的insert if ( "order_info".equals(tableName) && rowChange.getEventType().equals(CanalEntry.EventType.INSERT)) { writeDataToKafka(Constants.GMALL_ORDER_INFO,rowChange); // 采集 order_detail 的insert }else if ("order_detail".equals(tableName) && rowChange.getEventType().equals(CanalEntry.EventType.INSERT)) { writeDataToKafka(Constants.GMALL_ORDER_DETAIL,rowChange); }else if((rowChange.getEventType().equals(CanalEntry.EventType.INSERT) ||rowChange.getEventType().equals(CanalEntry.EventType.INSERT))&&"user_info".equals(tableName)){ writeDataToKafka(Constants.GMALL_USER_INFO,rowChange); } } public static void writeDataToKafka(String topic,CanalEntry.RowChange rowChange){ //获取行的集合 List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList(); for (CanalEntry.RowData rowData : rowDatasList) { JSONObject jsonObject = new JSONObject(); //获取insert后每一行的每一列 List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList(); for (CanalEntry.Column column : afterColumnsList) { jsonObject.put(column.getName(),column.getValue()); } // 模拟网络波动和延迟 随机产生一个 1-5直接的随机数 int i = new Random().nextInt(15); /*try { Thread.sleep(15 * 1000); } catch (InterruptedException e) { e.printStackTrace(); }*/ //发送数据到Kafka MyProducer.sendDataToKafka(topic,jsonObject.toJSONString()); } } }
第4章 实时数据处理
4.1 数据处理流程
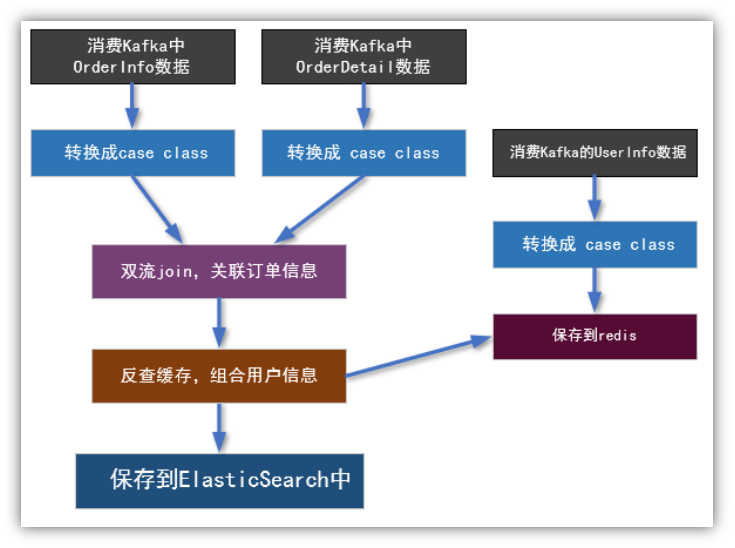
4.2 双流join(难点)
4.2.1 程序流程图
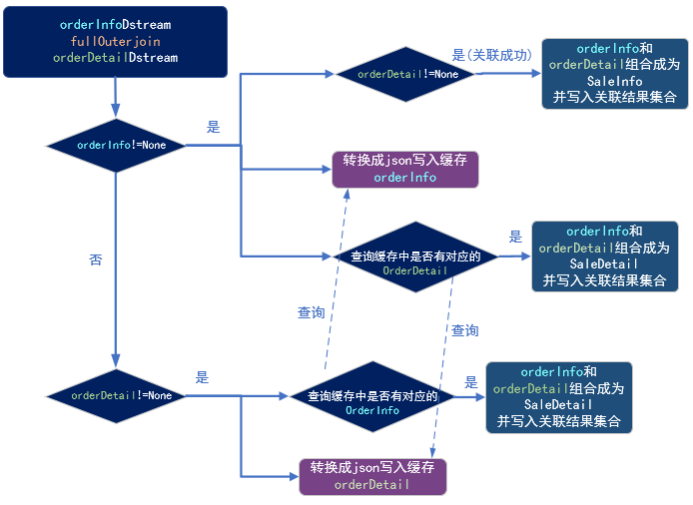
4.2.2样例类
1)在gmall_realtime模块新建样例类OrderDetail
package com.yuange.realtime.beans /** * @作者:袁哥 * @时间:2021/7/11 21:34 * 样例类的字段: * 如果需要取kafka的全部字段,设置对应的全部字段 * 此外额外添加自己需要的字段,如果不需要Kafka中的全部字段,可以只取需要的字段 */ case class OrderDetail(id:String, order_id: String, sku_name: String, sku_id: String, order_price: String, img_url: String, sku_num: String)
2)在gmall_realtime模块新建样例类SaleDetail
package com.yuange.realtime.beans
import java.text.SimpleDateFormat
/** * @作者:袁哥 * @时间:2021/7/11 21:36 */ case class SaleDetail( var order_detail_id:String =null, var order_id: String=null, var order_status:String=null, var create_time:String=null, var user_id: String=null, var sku_id: String=null, var user_gender: String=null, var user_age: Int=0, var user_level: String=null, var sku_price: Double=0D, var sku_name: String=null, var dt:String=null) { def this(orderInfo:OrderInfo,orderDetail: OrderDetail) { this mergeOrderInfo(orderInfo) mergeOrderDetail(orderDetail) } def mergeOrderInfo(orderInfo:OrderInfo): Unit ={ if(orderInfo!=null){ this.order_id=orderInfo.id this.order_status=orderInfo.order_status this.create_time=orderInfo.create_time this.dt=orderInfo.create_date this.user_id=orderInfo.user_id } } def mergeOrderDetail(orderDetail: OrderDetail): Unit ={ if(orderDetail!=null){ this.order_detail_id=orderDetail.id this.sku_id=orderDetail.sku_id this.sku_name=orderDetail.sku_name this.sku_price=orderDetail.order_price.toDouble } } def mergeUserInfo(userInfo: UserInfo): Unit ={ if(userInfo!=null){ this.user_id=userInfo.id val formattor = new SimpleDateFormat("yyyy-MM-dd") val date: java.util.Date = formattor.parse(userInfo.birthday) val curTs: Long = System.currentTimeMillis() val betweenMs= curTs-date.getTime val age=betweenMs/1000L/60L/60L/24L/365L this.user_age=age.toInt this.user_gender=userInfo.gender this.user_level=userInfo.user_level } } }
3)在gmall_realtime模块新建样例类UserInfo
case class UserInfo(id:String, login_name:String, user_level:String, birthday:String, gender:String)
4.2.3 App
1)在gmall_realtime模块新建OrderDetailApp
package com.yuange.realtime.app import java.time.{LocalDate, LocalDateTime} import java.time.format.DateTimeFormatter import java.util import com.alibaba.fastjson.JSON import com.google.gson.Gson import com.yuange.constants.Constants import com.yuange.realtime.beans.{OrderDetail, OrderInfo, SaleDetail, UserInfo} import com.yuange.realtime.utils.{MyEsUtil, MyKafkaUtil, RedisUtil} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.streaming.dstream.{DStream, InputDStream} import redis.clients.jedis.Jedis import scala.collection.mutable.ListBuffer /** * @作者:袁哥 * @时间:2021/7/11 21:59 */ object OrderDetailApp extends BaseApp { override var appName: String = "OrderDetailApp" override var duration: Int = 10 def main(args: Array[String]): Unit = { run{ val ds1: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_ORDER_INFO, streamingContext) val ds2: InputDStream[ConsumerRecord[String, String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_ORDER_DETAIL, streamingContext) //封装为K-V DS val ds3: DStream[(String, OrderInfo)] = ds1.map(record => { val orderInfo: OrderInfo = JSON.parseObject(record.value(), classOf[OrderInfo]) // 封装create_date 和 create_hour "create_time":"2021-07-07 01:39:33" val formatter1: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss") val formatter2: DateTimeFormatter = DateTimeFormatter.ofPattern("yyyy-MM-dd") val localDateTime: LocalDateTime = LocalDateTime.parse(orderInfo.create_time, formatter1) orderInfo.create_date = localDateTime.format(formatter2) orderInfo.create_hour = localDateTime.getHour.toString // 订单的明细数据,脱敏 演示手机号脱敏 orderInfo.consignee_tel = orderInfo.consignee_tel.replaceAll("(\\w{3})\\w*(\\w{4})", "$1****$2") (orderInfo.id, orderInfo) }) // ds3.print() val ds4: DStream[(String, OrderDetail)] = ds2.map(record => { val detail: OrderDetail = JSON.parseObject(record.value(), classOf[OrderDetail]) (detail.order_id, detail) }) // ds4.print() val ds5: DStream[(String, (Option[OrderInfo], Option[OrderDetail]))] = ds3.fullOuterJoin(ds4) ds5.print() val ds6: DStream[SaleDetail] = ds5.mapPartitions(partition => { //存放封装后的订单详请 val saleDetails: ListBuffer[SaleDetail] = ListBuffer[SaleDetail]() //获取redis连接 val jedis: Jedis = RedisUtil.getJedisClient() val gson = new Gson partition.foreach { case (order_id, (orderInfoOption, orderDetailOption)) => { if (orderInfoOption != None) { val orderInfo: OrderInfo = orderInfoOption.get // 在当前批次关联Join上的orderDetail if (orderDetailOption != None) { val orderDetail: OrderDetail = orderDetailOption.get val detail = new SaleDetail(orderInfo, orderDetail) saleDetails.append(detail) } //将order_info写入redis ,在redis中存多久: 取系统的最大延迟(假设5min) * 2 // set + expire = setex jedis.setex("order_info:" + order_id, 5 * 2 * 60, gson.toJson(orderInfo)) // 从redis中查询,是否有早到的order_detail val earlyOrderDetatils: util.Set[String] = jedis.smembers("order_detail:" + order_id) earlyOrderDetatils.forEach( str => { val orderDetail: OrderDetail = JSON.parseObject(str, classOf[OrderDetail]) val detail = new SaleDetail(orderInfo, orderDetail) saleDetails.append(detail) } ) } else { //都是当前批次无法配对的orderDetail val orderDetail: OrderDetail = orderDetailOption.get // 从redis中查询是否有早到的order_info val orderInfoStr: String = jedis.get("order_info:" + orderDetail.order_id) if (orderInfoStr != null) { val detail = new SaleDetail(JSON.parseObject(orderInfoStr, classOf[OrderInfo]), orderDetail) saleDetails.append(detail) } else { //说明当前Order_detail 早来了,缓存中找不到对于的Order_info,需要将当前的order-detail写入redis jedis.sadd("order_detail:" + orderDetail.order_id, gson.toJson(orderDetail)) jedis.expire("order_detail:" + orderDetail.order_id, 5 * 2 * 60) } } } } jedis.close() saleDetails.iterator }) // 根据user_id查询 用户的其他信息 val ds7: DStream[SaleDetail] = ds6.mapPartitions(partition => { val jedis: Jedis = RedisUtil.getJedisClient() val saleDetailsWithUserInfo: Iterator[SaleDetail] = partition.map(saleDetail => { val userInfoStr: String = jedis.get("user_id:" + saleDetail.user_id) val userInfo: UserInfo = JSON.parseObject(userInfoStr, classOf[UserInfo]) saleDetail.mergeUserInfo(userInfo) saleDetail }) jedis.close() saleDetailsWithUserInfo }) //写入ES 将DS转换为 docList: List[(String, Any)] val ds8: DStream[(String, SaleDetail)] = ds7.map(saleDetail => ((saleDetail.order_detail_id, saleDetail))) ds8.foreachRDD(rdd => { rdd.foreachPartition(partition => { MyEsUtil.insertBulk("gmall_sale_detail" + LocalDate.now() , partition.toList) }) }) } } }
2)在gmall_realtime模块新建UserInfoApp
package com.yuange.realtime.app import com.alibaba.fastjson.JSON import com.yuange.constants.Constants import com.yuange.realtime.utils.{MyKafkaUtil, RedisUtil} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.spark.streaming.dstream.InputDStream /** * @作者:袁哥 * @时间:2021/7/13 20:11 */ object UserInfoApp extends BaseApp { override var appName: String = "UserInfoApp" override var duration: Int = 10 def main(args: Array[String]): Unit = { run{ val ds: InputDStream[ConsumerRecord[String,String]] = MyKafkaUtil.getKafkaStream(Constants.GMALL_USER_INFO,streamingContext) ds.foreachRDD(rdd => { rdd.foreachPartition(partiton => { //获取连接 val jedis = RedisUtil.getJedisClient() partiton.foreach(record => { val key: String = JSON.parseObject(record.value()).getString("id") jedis.set("user_id:" + key, record.value()) }) jedis.close() }) }) } } }
3)在gmall_realtime模块中的MyEsUtil 中给items做一个判空处理
package com.yuange.realtime.utils import java.util.Objects import java.util import io.searchbox.client.config.HttpClientConfig import io.searchbox.client.{JestClient, JestClientFactory} import io.searchbox.core.{Bulk, BulkResult, Index} import collection.JavaConverters._ /** * @作者:袁哥 * @时间:2021/7/9 21:16 */ object MyEsUtil { private val ES_HOST = "http://hadoop102" private val ES_HTTP_PORT = 9200 private var factory: JestClientFactory = null /** * 获取客户端 * * @return jestclient */ def getClient: JestClient = { if (factory == null) build() factory.getObject } /** * 关闭客户端 */ def close(client: JestClient): Unit = { if (!Objects.isNull(client)) try client.shutdownClient() catch { case e: Exception => e.printStackTrace() } } /** * 建立连接 */ private def build(): Unit = { factory = new JestClientFactory factory.setHttpClientConfig(new HttpClientConfig.Builder(ES_HOST + ":" + ES_HTTP_PORT).multiThreaded(true) .maxTotalConnection(20) //连接总数 .connTimeout(10000).readTimeout(10000).build) } /* 批量插入数据到ES 需要先将写入的数据,封装为 docList: List[(String, Any)] (String, Any): K:id V: document */ def insertBulk(indexName: String, docList: List[(String, Any)]): Unit = { if (docList.size > 0) { val jest: JestClient = getClient val bulkBuilder = new Bulk.Builder().defaultIndex(indexName).defaultType("_doc") for ((id, doc) <- docList) { val indexBuilder = new Index.Builder(doc) if (id != null) { indexBuilder.id(id) } val index: Index = indexBuilder.build() bulkBuilder.addAction(index) } val bulk: Bulk = bulkBuilder.build() var items: util.List[BulkResult#BulkResultItem] = null try { items = jest.execute(bulk).getItems } catch { case ex: Exception => println(ex.toString) } finally { //自动关闭连接 close(jest) if (items != null){ println("保存" + items.size() + "条数据") /* items: 是一个java的集合 <- 只能用来遍历scala的集合 将items,由Java的集合转换为scala的集合 java集合.asScala 由scala集合转java集合 scala集合.asJava */ for (item <- items.asScala) { if (item.error != null && item.error.nonEmpty) { println(item.error) println(item.errorReason) } } } } } } }
4.3 ES索引建立
PUT _template/gmall_sale_detail_template { "index_patterns": ["gmall_sale_detail*"], "settings": { "number_of_shards": 3 }, "aliases" : { "{index}-query": {}, "gmall_sale_detail-query":{} }, "mappings" : { "_doc" : { "properties" : { "order_detail_id" : { "type" : "keyword" }, "order_id" : { "type" : "keyword" }, "create_time" : { "type" : "date" , "format" : "yyyy-MM-dd HH:mm:ss" }, "dt" : { "type" : "date" }, "order_status" : { "type" : "keyword" }, "sku_id" : { "type" : "keyword" }, "sku_name" : { "type" : "text", "analyzer": "ik_max_word" }, "sku_price" : { "type" : "float" }, "user_age" : { "type" : "long" }, "user_gender" : { "type" : "keyword" }, "user_id" : { "type" : "keyword" }, "user_level" : { "type" : "keyword", "index" : false } } } } }
4.4 测试
1)启动Zookeeper
zookeeper.sh start
2)启动Kafka
kafka.sh start
3)启动canal
/opt/module/canal/bin/startup.sh
4)启动gmall_canalclient模块中的MyClient类的main方法,将数据从mysql传输至kafka
5)启动ES集群
elasticsearch.sh start
6)启动Redis
redis-server /opt/module/redis/redis.conf
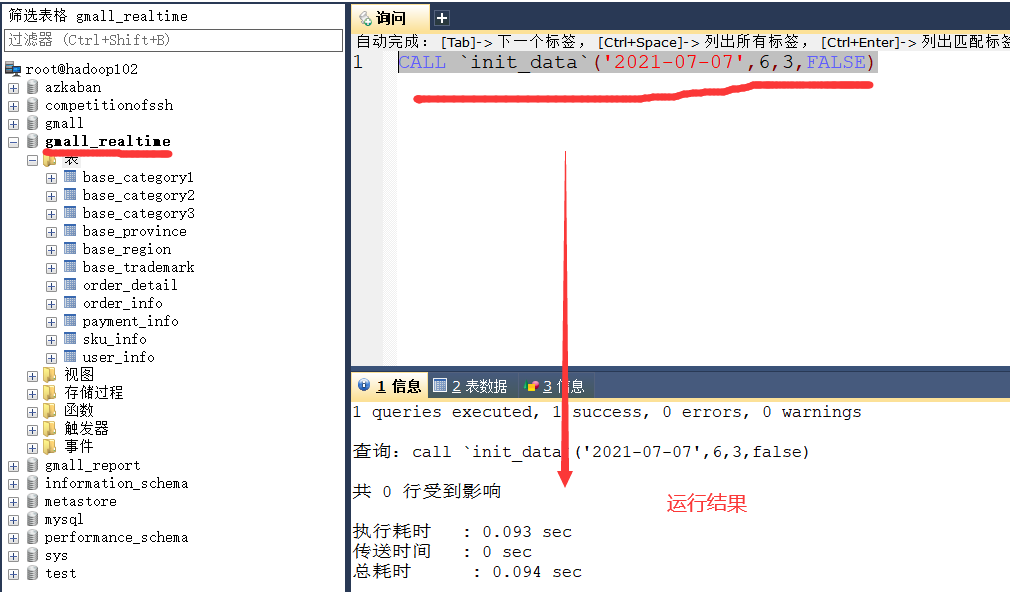
7)使用存储过程模拟生成数据
#CALL `init_data`(造数据的日期, 生成的订单数, 生成的用户数, 是否覆盖写) call `init_data`('2021-07-07',6,3,true)
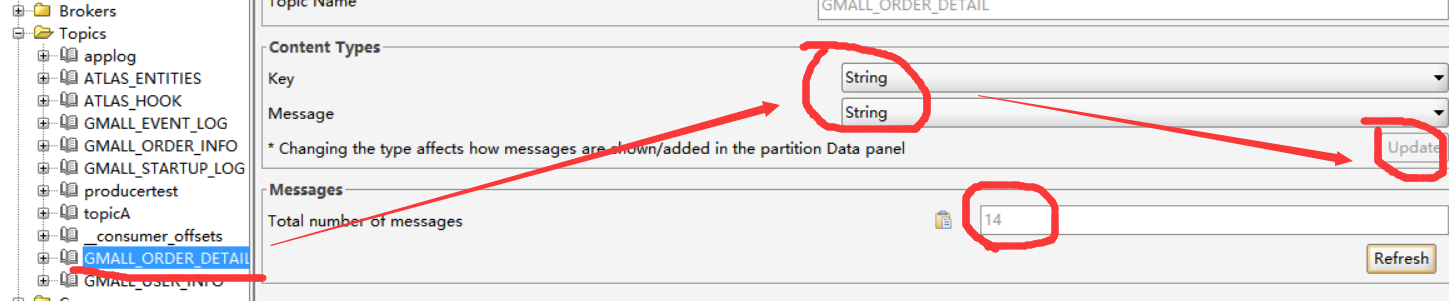
8)启动gmall_realtime模块的UserInfoApp中的main方法,将kafka中的用户数据传入Redis
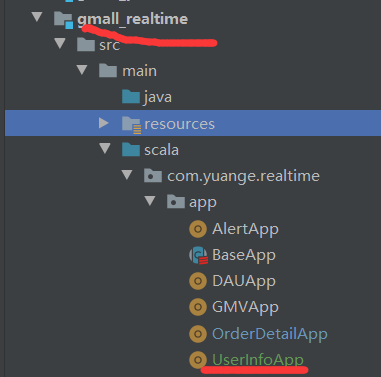
9)启动gmall_realtime模块的OrderDetailApp中的main方法,将数据Join之后存入ES
10)查看Redis中的数据

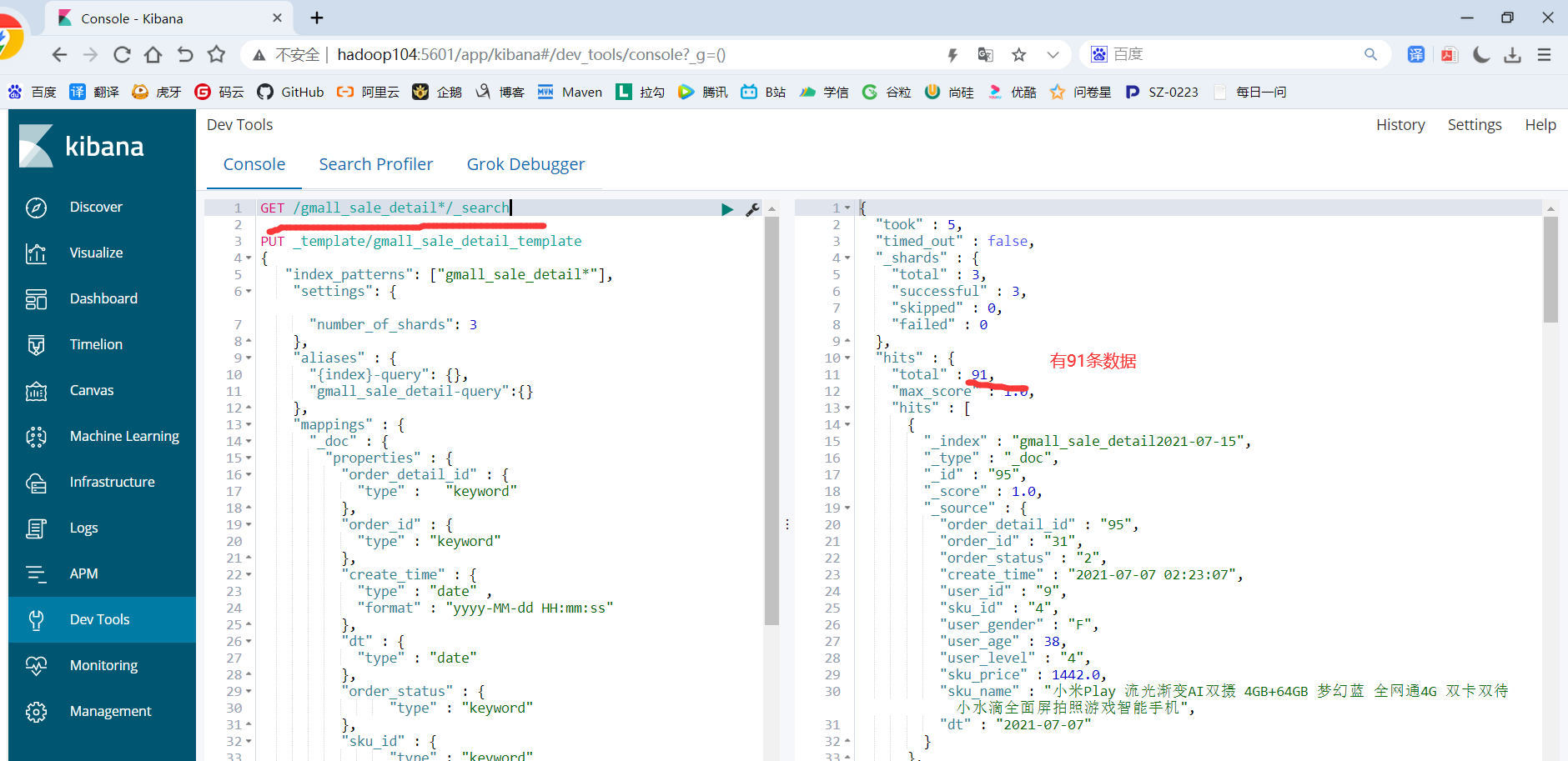
11)查看ES中的数据
第5章 灵活查询数据接口开发
5.1 传入路径及参数
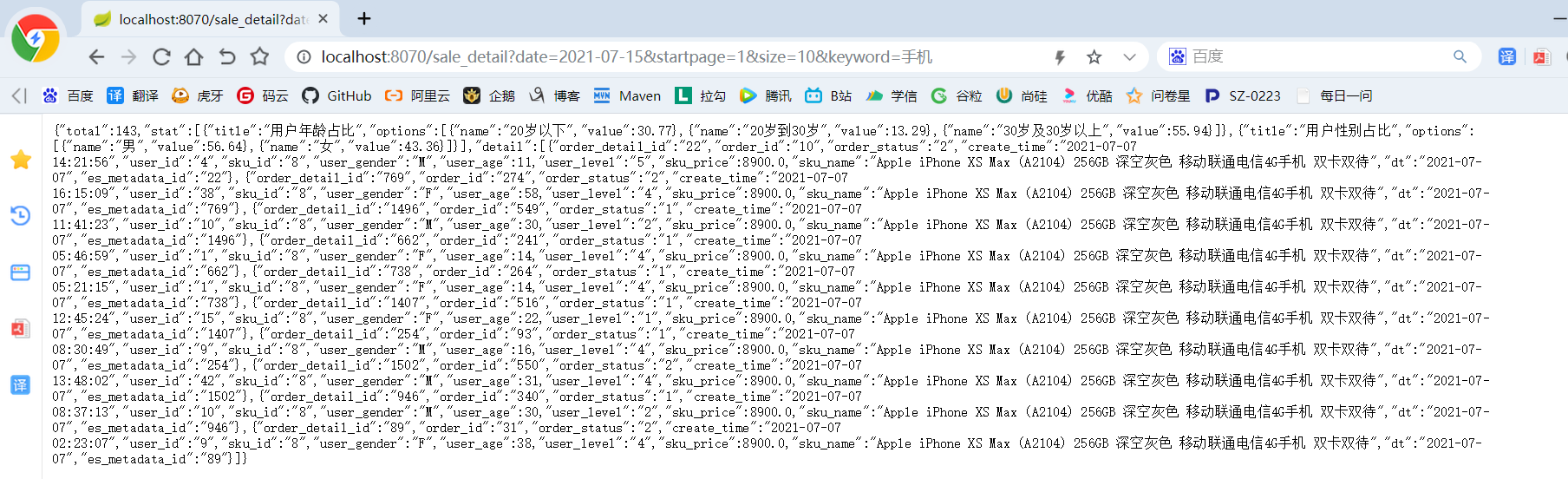
http://localhost:8070/sale_detail?date=2020-08-21&startpage=1&size=5&keyword=小米手机
5.2 返回值
{"total":62,"stat":[{"options":[{"name":"20岁以下","value":0.0},{"name":"20岁到30岁","value":25.8},{"name":"30岁及30岁以上","value":74.2}],"title":"用户年龄占比"},{"options":[{"name":"男","value":38.7},{"name":"女","value":61.3}],"title":"用户性别占比"}],"detail":[{"user_id":"9","sku_id":"8","user_gender":"M","user_age":49.0,"user_level":"1","sku_price":8900.0,"sku_name":"Apple iPhone XS Max (A2104) 256GB 深空灰色 移动联通电信4G手机 双卡双待","sku_tm_id":"86","sku_category1_id":"2","sku_category2_id":"13","sku_category3_id":"61","sku_category1_name":"手机","sku_category2_name":"手机通讯","sku_category3_name":"手机","spu_id":"1","sku_num":6.0,"order_count":2.0,"order_amount":53400.0,"dt":"2019-02-14","es_metadata_id":"wPdM7GgBQMmfy2BJr4YT"},{"user_id":"5","sku_id":"8","user_gender":"F","user_age":36.0,"user_level":"4","sku_price":8900.0,"sku_name":"Apple iPhone XS Max (A2104) 256GB 深空灰色 移动联通电信4G手机 双卡双待","sku_tm_id":"86","sku_category1_id":"2","sku_category2_id":"13","sku_category3_id":"61","sku_category1_name":"手机","sku_category2_name":"手机通讯","sku_category3_name":"手机","spu_id":"1","sku_num":5.0,"order_count":1.0,"order_amount":44500.0,"dt":"2019-02-14","es_metadata_id":"wvdM7GgBQMmfy2BJr4YT"},{"user_id":"19","sku_id":"8","user_gender":"F","user_age":43.0,"user_level":"5","sku_price":8900.0,"sku_name":"Apple iPhone XS Max (A2104) 256GB 深空灰色 移动联通电信4G手机 双卡双待","sku_tm_id":"86","sku_category1_id":"2","sku_category2_id":"13","sku_category3_id":"61","sku_category1_name":"手机","sku_category2_name":"手机通讯","sku_category3_name":"手机","spu_id":"1","sku_num":7.0,"order_count":2.0,"order_amount":62300.0,"dt":"2019-02-14","es_metadata_id":"xvdM7GgBQMmfy2BJr4YU"},{"user_id":"15","sku_id":"8","user_gender":"M","user_age":66.0,"user_level":"4","sku_price":8900.0,"sku_name":"Apple iPhone XS Max (A2104) 256GB 深空灰色 移动联通电信4G手机 双卡双待","sku_tm_id":"86","sku_category1_id":"2","sku_category2_id":"13","sku_category3_id":"61","sku_category1_name":"手机","sku_category2_name":"手机通讯","sku_category3_name":"手机","spu_id":"1","sku_num":3.0,"order_count":1.0,"order_amount":26700.0,"dt":"2019-02-14","es_metadata_id":"xvdM7GgBQMmfy2BJr4YU"}]}
5.3 编写DSL语句
GET gmall_sale_detail-query/_search { "query": { "bool": { "filter": { "term": { "dt": "2021-07-07" } }, "must": [ {"match":{ "sku_name": { "query": "小米手机", "operator": "and" } } } ] } } , "aggs": { "groupby_age": { "terms": { "field": "user_age" } }, "groupby_gender": { "terms": { "field": "user_gender" } } }, "from": 0, "size": 2 }
5.4 代码开发
5.4.1 代码清单
|
bean |
Stat |
饼图 |
|
Option |
饼图中的选项 |
|
|
控制层 |
PublisherController |
增加getSaleDetail方法,调用服务层方法得到数据并根据web接口和参数组织整理返回值 |
|
服务层 |
PublisherService |
增加getSaleDetail方法 |
|
PublisherServiceImpl |
实现getSaleDetail方法,依据DSL语句查询ElasticSearch |
5.4.2 在gmall_publisher模块中修改pom.xml
<!--- ES依赖包-->
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.codehaus.janino</groupId>
<artifactId>commons-compiler</artifactId>
<version>2.7.8</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
5.4.3在gmall_publisher模块中配置 application.properties
#es spring.elasticsearch.jest.uris=http://hadoop102:9200
5.4.4 Bean
1)新建Option
package com.yuange.gmall.gmall_publisher.beans; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/15 10:45 */ @NoArgsConstructor @AllArgsConstructor @Data public class Option { String name; Double value; }
2)新建Stat
package com.yuange.gmall.gmall_publisher.beans; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/15 10:46 */ @AllArgsConstructor @NoArgsConstructor @Data public class Stat { String title; List<Option> options; }
3)新建SaleDetail
package com.yuange.gmall.gmall_publisher.beans; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @作者:袁哥 * @时间:2021/7/15 10:51 */ @NoArgsConstructor @AllArgsConstructor @Data public class SaleDetail { private String order_detail_id; private String order_id; private String order_status; private String create_time; private String user_id; private String sku_id; private String user_gender; private Integer user_age; private String user_level; private Double sku_price; private String sku_name; private String dt; // 多添加 private String es_metadata_id; }
4)lombok注解说明:
@Data:注解会自动增加getter 和setter方法
@AllArgsConstructor:会自动增加包含全部属性的构造函数
@NoArgsConstructor:添加无参构造器
5)需要pom.xml增加依赖(我之前已经加入依赖了,若你没加,就加上)
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
5.4.5 ESDao
package com.yuange.gmall.gmall_publisher.dao; import com.alibaba.fastjson.JSONObject; import java.io.IOException; /** * @作者:袁哥 * @时间:2021/7/15 10:53 */ public interface ESDao { JSONObject getESData(String date, Integer startpage, Integer size, String keyword) throws IOException; }
5.4.6 ESDaoImpl
package com.yuange.gmall.gmall_publisher.dao; import com.alibaba.fastjson.JSONObject; import com.yuange.gmall.gmall_publisher.beans.Option; import com.yuange.gmall.gmall_publisher.beans.SaleDetail; import com.yuange.gmall.gmall_publisher.beans.Stat; import io.searchbox.client.JestClient; import io.searchbox.core.Search; import io.searchbox.core.SearchResult; import io.searchbox.core.search.aggregation.MetricAggregation; import io.searchbox.core.search.aggregation.TermsAggregation; import org.elasticsearch.index.query.MatchQueryBuilder; import org.elasticsearch.search.aggregations.AggregationBuilders; import org.elasticsearch.search.aggregations.bucket.terms.TermsBuilder; import org.elasticsearch.search.builder.SearchSourceBuilder; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Repository; import java.io.IOException; import java.text.DecimalFormat; import java.util.ArrayList; import java.util.List; /** * @作者:袁哥 * @时间:2021/7/15 10:56 */ @Repository public class ESDaoImpl implements ESDao { @Autowired //从容器中取一个JestClient类型的对象 private JestClient jestClient; /* 从ES中查询出数据 date : 指定查询的index 名称 gmall2020_sale_detail + date keyword: 全文检索的关键字 startpage: 计算from : (N - 1) size 1页 10 条数据。 startpage: 1 from: 0 size: 10 startpage: 2 from: 10 size 10 startpage: N from: (N - 1) size startpage: 3 from: 20 , size : 10 size: 查询返回的数据条数 查询条件: GET /gmall2020_sale_detail-query/_search { "query": { "match": { "sku_name": "手机" } }, "from": 0, "size": 20, "aggs": { "genderCount": { "terms": { "field": "user_gender", "size": 10 } }, "ageCount": { "terms": { "field": "user_age", "size": 150 } } } } */ public SearchResult getDataFromES(String date, Integer startpage, Integer size, String keyword) throws IOException { String indexName ="gmall_sale_detail" + date; int from = (startpage - 1 ) * size; // genderCount:{} TermsBuilder aggs1 = AggregationBuilders.terms("genderCount").field("user_gender").size(10); // "ageCount":{} TermsBuilder aggs2 = AggregationBuilders.terms("ageCount").field("user_age").size(150); // query":{} MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("sku_name", keyword); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder().query(matchQueryBuilder).aggregation(aggs1).aggregation(aggs2); //生成查询的字符串 Search search = new Search.Builder(searchSourceBuilder.toString()).addType("_doc").addIndex(indexName).build(); SearchResult searchResult = jestClient.execute(search); return searchResult; } // 将ES中查询的数据,按照指定的格式,封装 detail数据 public List<SaleDetail> getDetailData(SearchResult searchResult){ ArrayList<SaleDetail> saleDetails = new ArrayList<>(); List<SearchResult.Hit<SaleDetail, Void>> hits = searchResult.getHits(SaleDetail.class); for (SearchResult.Hit<SaleDetail, Void> hit : hits) { SaleDetail saleDetail = hit.source; saleDetail.setEs_metadata_id(hit.id); saleDetails.add(saleDetail); } return saleDetails; } // 将ES中查询的数据,按照指定的格式,封装 age相关的 stat数据 public Stat getAgeStat(SearchResult searchResult){ Stat stat = new Stat(); MetricAggregation aggregations = searchResult.getAggregations(); TermsAggregation ageCount = aggregations.getTermsAggregation("ageCount"); List<TermsAggregation.Entry> buckets = ageCount.getBuckets(); int agelt20=0; int agege30=0; int age20to30=0; double sumCount=0; for (TermsAggregation.Entry bucket : buckets) { if (Integer.parseInt(bucket.getKey()) < 20 ){ agelt20 += bucket.getCount(); }else if(Integer.parseInt(bucket.getKey()) >= 30){ agege30 += bucket.getCount(); }else{ age20to30+=bucket.getCount(); } } sumCount = age20to30 + agege30 + agelt20; DecimalFormat format = new DecimalFormat("###.00"); List<Option> ageoptions =new ArrayList<>(); double perlt20 = agelt20 / sumCount * 100; double per20to30 = age20to30 / sumCount * 100; ageoptions.add(new Option("20岁以下",Double.parseDouble(format.format(perlt20 )))); ageoptions.add(new Option("20岁到30岁",Double.parseDouble(format.format( per20to30)))); ageoptions.add(new Option("30岁及30岁以上",Double.parseDouble(format.format(100 - perlt20 - per20to30 )))); stat.setOptions(ageoptions); stat.setTitle("用户年龄占比"); return stat; } public Stat getGenderStat(SearchResult searchResult){ Stat stat = new Stat(); MetricAggregation aggregations = searchResult.getAggregations(); TermsAggregation ageCount = aggregations.getTermsAggregation("genderCount"); List<TermsAggregation.Entry> buckets = ageCount.getBuckets(); int maleCount=0; int femaleCount=0; double sumCount=0; for (TermsAggregation.Entry bucket : buckets) { if (bucket.getKey().equals("F") ){ femaleCount += bucket.getCount(); }else{ maleCount += bucket.getCount(); } } sumCount = maleCount + femaleCount; DecimalFormat format = new DecimalFormat("###.00"); List<Option> ageoptions =new ArrayList<>(); ageoptions.add(new Option("男",Double.parseDouble(format.format(maleCount / sumCount * 100 )))); ageoptions.add(new Option("女",Double.parseDouble(format.format( (1 - maleCount / sumCount ) * 100 )))); stat.setOptions(ageoptions); stat.setTitle("用户性别占比"); return stat; } // 将ES中查询的数据,按照指定的格式,封装 gender相关的 stat数据 @Override public JSONObject getESData(String date, Integer startpage, Integer size, String keyword) throws IOException { SearchResult searchResult = getDataFromES(date, startpage, size, keyword); List<SaleDetail> detailData = getDetailData(searchResult); Stat ageStat = getAgeStat(searchResult); Stat genderStat = getGenderStat(searchResult); JSONObject jsonObject = new JSONObject(); jsonObject.put("total",searchResult.getTotal()); ArrayList<Stat> stats = new ArrayList<>(); stats.add(ageStat); stats.add(genderStat); jsonObject.put("stat",stats); jsonObject.put("detail",detailData); return jsonObject; } }
5.4.7 PublisherService
JSONObject getESData(String date, Integer startpage, Integer size, String keyword) throws IOException;
5.4.8 PublisherServiceImpl
@Autowired private ESDao esDao; @Override public JSONObject getESData(String date, Integer startpage, Integer size, String keyword) throws IOException { return esDao.getESData(date,startpage,size,keyword); }
5.4.9 PublisherController
/* http://localhost:8070/sale_detail?date=2020-08-21&startpage=1&size=5&keyword=小米手机 */ @RequestMapping(value = "/sale_detail") public JSONObject handle3(String date,Integer startpage,Integer size,String keyword) throws IOException { return publisherService.getESData(date,startpage,size,keyword); }
5.4.10 index.html
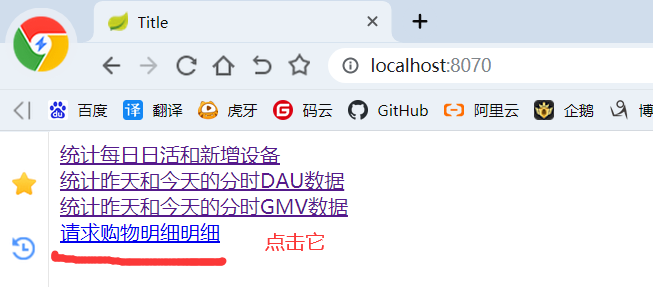
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <a href="/realtime-total?date=2021-07-06">统计每日日活和新增设备</a> <br/> <a href="/realtime-hours?id=dau&date=2021-07-06">统计昨天和今天的分时DAU数据</a> <br/> <a href="/realtime-hours?id=order_amount&date=2021-07-07">统计昨天和今天的分时GMV数据</a> <br/> <a href="/sale_detail?date=2021-07-15&startpage=1&size=10&keyword=手机">请求购物明细明细</a> </body> </html>
5.4.11 启动gmall_publisher模块
5.4.12 测试:
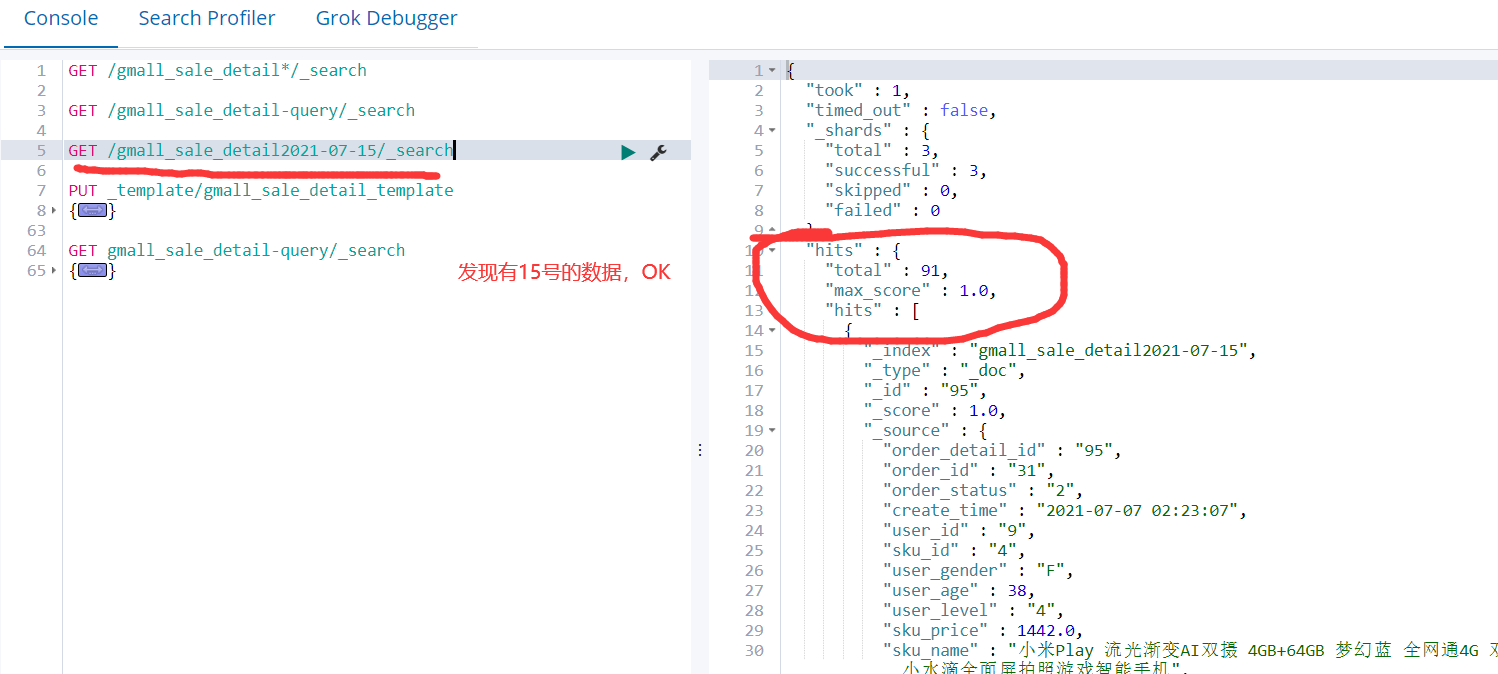
1)先在ES中查询是否有2021-07-15的数据,若没有,下面的操作会返回500错误码
2)访问:http://localhost:8070/
3)完整实时项目代码已上传至GitHub:https://github.com/LzMingYueShanPao/gmall_sparkstream.git