十二、Hbase
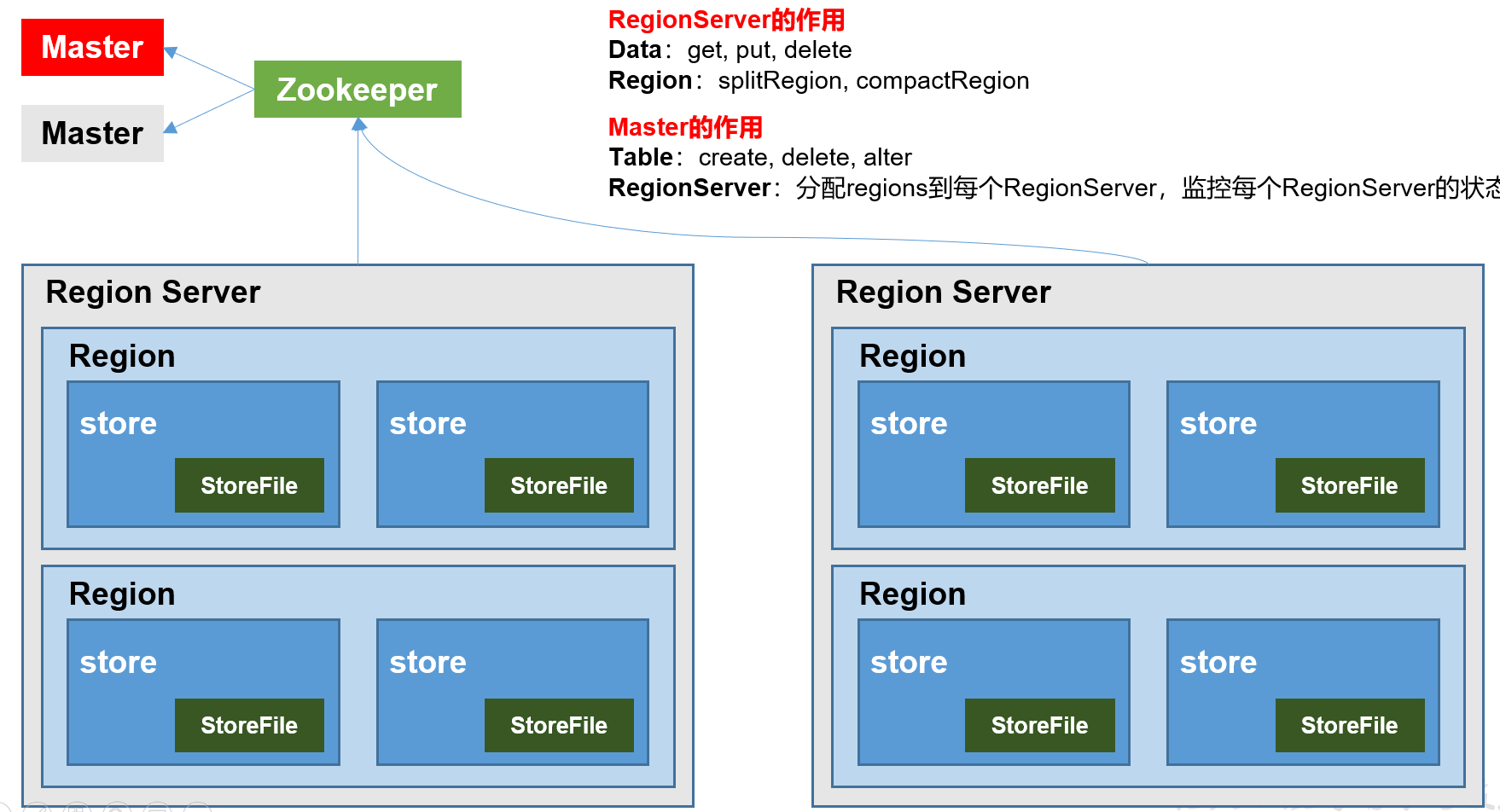
12.1 基本架构
12.2 读写流程
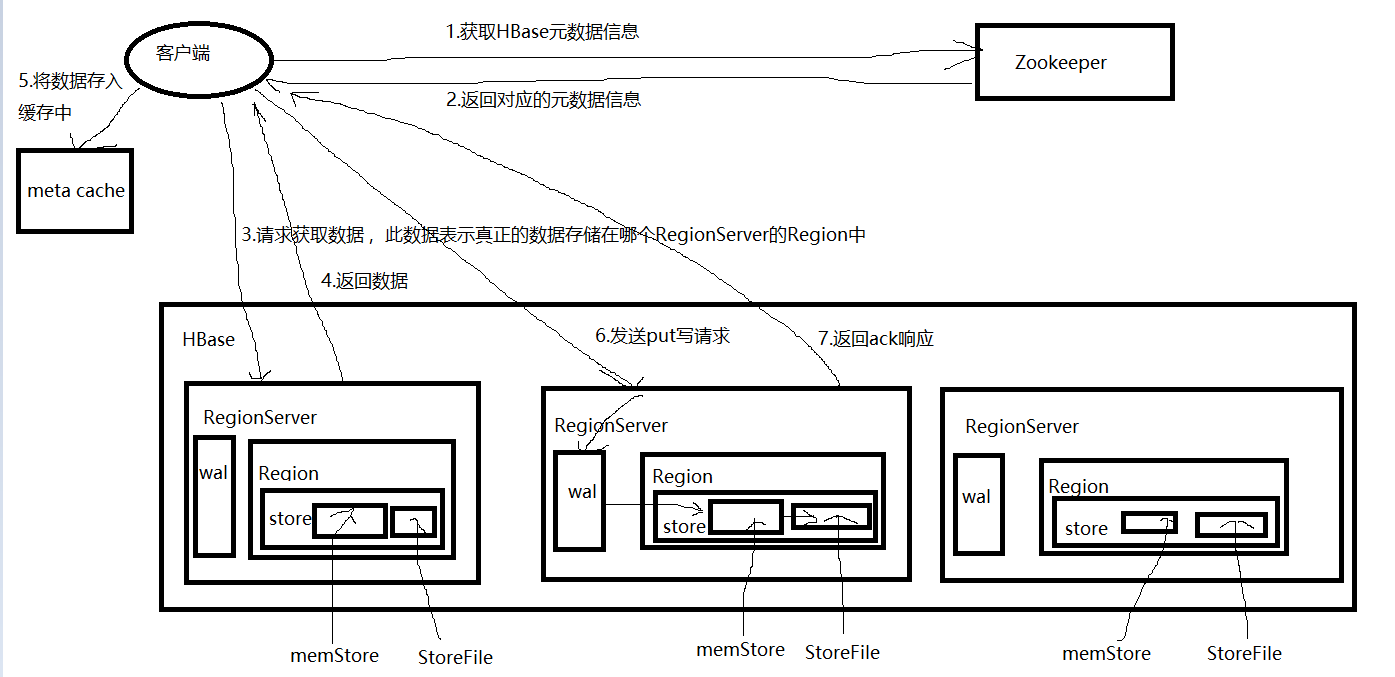
写流程:
1)Client先访问Zookeeper,获取hbase:meta表位于哪个RegionServer。
2)访问对应的RegionServer,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标RegionServer进行通讯;
4)将数据顺序写入(追加)到WAL(HLog日志文件);
5)将数据写入对应的MemStore,数据会在MemStore进行排序;
6)向客户端发送ack;
7)等达到MemStore的刷写时机后,将数据刷写到HFile。
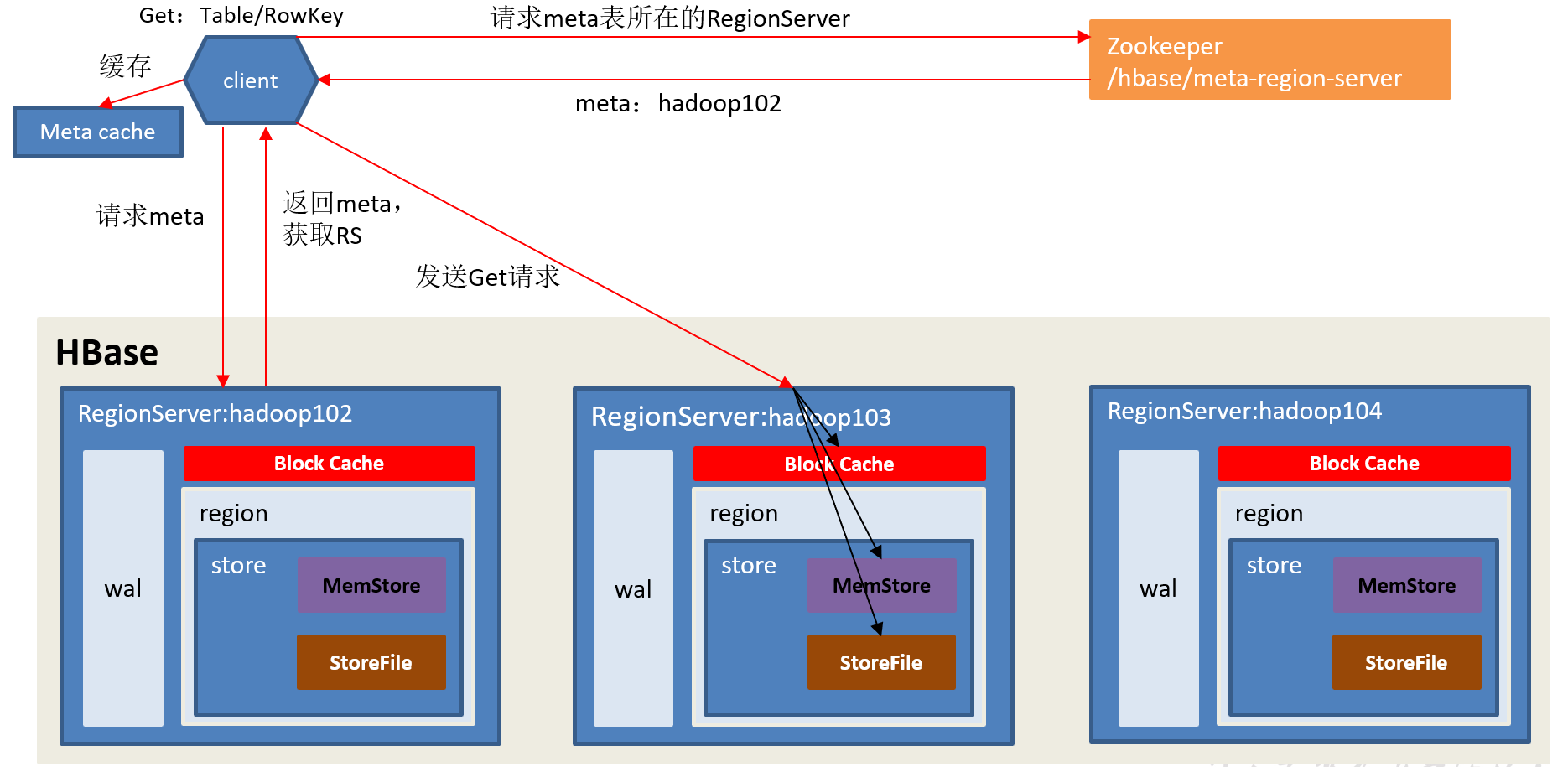
读流程:
1)Client先访问Zookeeper,获取hbase:meta表位于哪个RegionServer。
2)访问对应的RegionServer,获取hbase:meta表,根据读请求的namespace:table/rowkey,查询出目标数据位于哪个RegionServer中的哪个Region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问。
3)与目标RegionServer进行通讯;
4)分别在BlockCache(读缓存),MemStore中查询目标数据,如果BlockCache中未查到相应数据则扫描对应的HFile文件,HFile中扫描到的数据块(默认64K)写入BlockCache,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(timestamp)或者不同的类型(Put/Delete)。
5)将合并后的最终结果返回给客户端。
刷写条件:
memstore级别: flushsize ,默认 128m
region级别: 4 * flushSize ,触发刷写,默认512m
region server 级别: 0.4 * 堆内存 * 0.95
hlog : 32个文件数
手动刷写: 执行命令
12.3 合并
major:大合并,所有的Hfile合并成一个大的Hfile,会将过期、标记为删除的数据清理掉
minor:小合并,把相邻的几个Hfile合并成一个较大的Hfile,不会将过期、标记为删除的数据清理掉
企业怎么用?
大合并影响提供服务,默认7天一次
调整时间
关闭自动大合并,自己选择时间进行大合并
保持默认(我们公司)
12.4 自动切分
0.94:按照10G切分
0.94-2.0:min(2 * R^3 * flushSize,10G) 注:R表示某个RegionServer下的Region数
第一次按256M切,阈值越来越大,直到超过10G,后面一直10G切
2.0之后:第一次按256M切,后面全部按10G切
12.5 rowkey设置原则
1)唯一原则:不重复
2)长度原则:最长64kb,一般设为10~100b,最好是16B
3)散列原则:数据分布均匀
取Hash、加盐、反转、随机数
原始数据:1234567_ts
取Hash:hash(1234567_ts)
最终的rowkey:hash(1234567_ts)_1234567_ts
rowkey的比较:按照字典顺序,按位比较
12.6 分区键
建表时,进行预分区,SPLITS =》 {'000|','001|','002|'}
-∞~ 000|
000| ~ 001| ==》 001234312521
001| ~ 002| ==》 002345422
002| ~ +∞
12.7 热点问题
请求集中在个别的RegionServer上
解决思路:
将数据打散
良好的rowkey设计 + 合理的分区键
比如:1234567_ts
取随机数:1234567_ts --> a
再取模,按分区数取模:a % 4 = b (0、1、2、3)
最后拼接到原始的rowkey前:00b_1234567_ts
12.8 优化
1)内存:16~48G,我们公司设置为40G
2)9个参数:调大writebuffer、追加写、调大超时时长...
3)rowkey + 分区 !!!!
12.9 二级索引
rowkey zs 18 中性
实现:借助Phoenix
全局索引:索引表、数据表,在不同的region
create index 索引表名 on 数据表名(索引列);
索引表的rowkey = 索引列_原来的rowkey
本地索引:索引数据、数据表在同一个region
create local index 索引表名 on 数据表名(索引列);
索引数据的rowkey = 分区键_索引列_原始rowkey
数据直接写入HBase,不通过phoenix,新的数据会建立二级索引吗?
只能通过Phoenix写的数据,才会添加二级索引
如何解决?
往phoenix再写一次
十三、Spark
13.1 入门
1)常用端口号
4040:运行中的job的ui页面
18080:spark的历史服务器
7077:老大的rpc端口
2)部署模式
standalone:自己管资源
yarn:yarn管资源
client:driver启动在本地
cluster:driver位置由yarn决定
k8s:
mesos:国外
3)配置文件
spark-default.conf
spark-env.conf
13.2 core
1)RDD是什么?五大属性
分布式弹性数据集
计算分区
计算逻辑
血缘依赖
分区器
移动数据不如移动计算
2)RDD可变吗?RDD存储数据吗?
不可变,只存元数据,不存储真正的数据
3)共享变量
累加器
广播变量:存在Executor的BlockManger上
4)cache、checkpoint
cache:基于内存,不会切断血缘关系
checkpoint:基于HDFS,会切断血缘关系
开发中怎么用?cache + checkpoint
5)spark的checkpoint与flink的checkpoint有什么区别?
spark的checkpoint,只存储了driver的元数据,只是一个简单的状态
flink的checkpoint,使用了Chandy-Lamport算法,异步分界线快照算法
6)算子
单value:
map、flatmap、filter、groupby、mapPartition
双value:rdd1.xxx(rdd2)
union、zip、join、intersection、subtract
k-v:
groupbykey
sortbykey:对key进行排序
如果想对value排序,使用map算子调换一下顺序,然后再sortkeyby,最后再使用map换回来
| 初始值 | 分区内和分区间逻辑是否一致 | |
| reducebykey | 无 | 一致 |
| foldbykey | 有值 | 一致 |
| aggregatebykey | 有值 | 可以不一致 |
| combinebykey | 有函数 | 可以不一致 |
xxxbykey:会产生shuffle
手动重分区:
repartition:一般用来增加分区,底层实现是使用coalesce,一定会产生shuffle
coalesce:一般用来减少分区,不一定会产生shuffle
行动算子:foreach、collect、count、take、last、first、reduce、save
13.3 spark几种划分
job:遇到一个行动算子,就会生成一个job
stage:遇到shuffle(宽依赖),就会划分stage
taskset:一个stage中,task的集合
task:一个stage中,最后一个rdd的分区数
13.4 宽窄依赖
宽依赖产生shuffle,窄依赖不产生shuffle
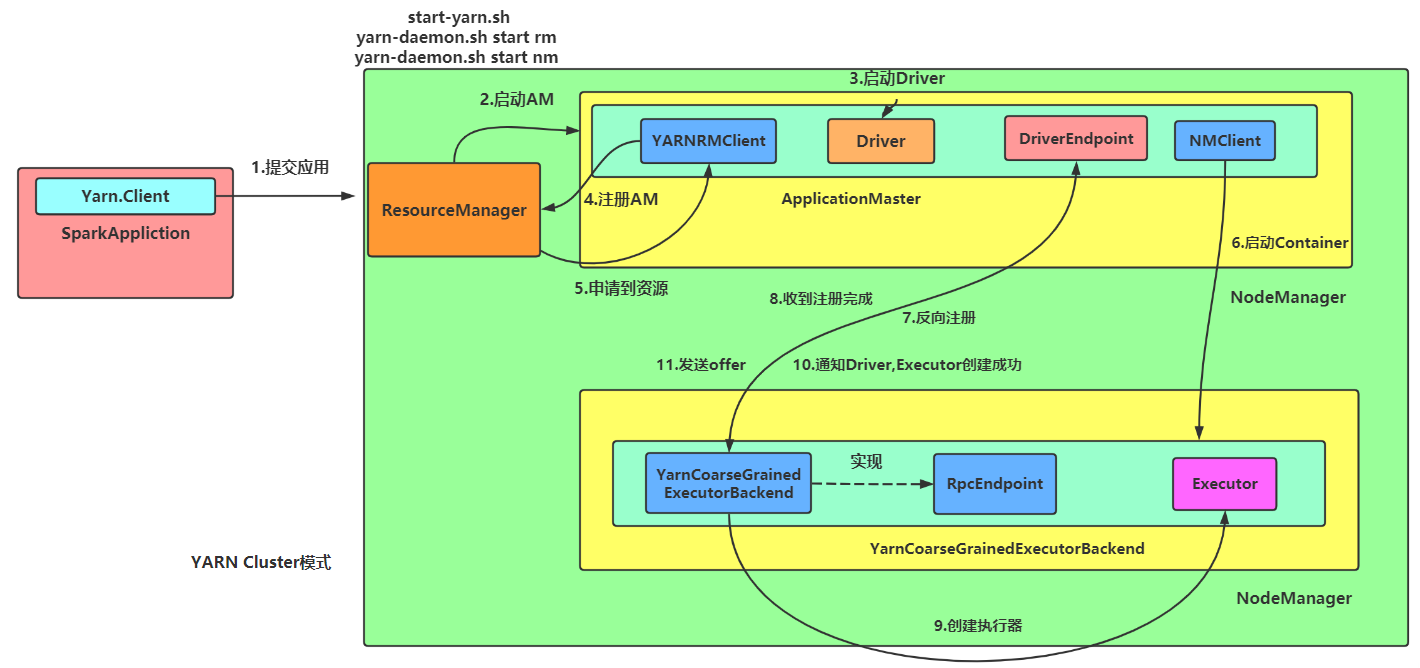
13.5 spark提交流程,通讯流程、任务调度、内存模型(统一内存模型)

13.6 spark优化
13.7 提交参数
spark-submit #指定模式 --master yarn --deploy-mode cluster #指定driver的资源 --driver-cores --driver-memory #指定Executor的资源 --num-executors --executor-cores --executor-memory --class xxx.xxx.xxx. jar包 main方法的传参
13.8 spark sql
1)Hive On SPark vs Spark On Hive
Hive On Spark : 只有执行引擎换成了spark,其他的 解析、编译、优化都是Hive自己来
Spark On Hive : 只是用了Hive的元数据,其他的 解析、编译、优化都是Spark自己来
2)有几种抽象?
rdd、df、ds
3)、spark sql中, 大小join怎么做最好?
广播小表
4)sparksql 有几种join?
broadcast hash join
shuffled hash join
sort merge join
Hive有几种join?
mapjoin
common join (shuffle join、reduce join)
SMB join
5)Spark SQL 怎么指定操作hive表?
创建 sparksession时, 调用 enableHiveSupport(),SparkSession.builder().xxx.xxxx.enableHiveSupport().getOrCreate()
6)小文件:
调用 coalesce,调整输出前的分区数
再启一个job,定期去合并小文件
13.9 spark streaming
1)计算模型?
微批次,每一个批次就是一个RDD
2)窗口 :窗口长度、滑动步长
滚动: 窗口长度 = 滑动步长
滑动: 窗口长度 > 滑动步长
窗口长度 = 批次间隔的 整数倍
3)常用参数
优雅关闭
背压
限流: 消费kafka, 单分区的速率上限
十四、Flink
14.1 入门
1)编程模型:分层API、编程四部曲(ENV、Source、Transform、Sink)
2)部署模式
standalone:自己管资源
yarn:yarn管资源
pre-job
yarn-session
application
k8s
mesos
企业怎么选?建议pre-job、application为主
3)常用端口号
6123 JobManager RPC端口
8081 Standalone模型下的webUI,若是yarn模式,通过8088跳转
4)配置文件
5)世界观:一切皆是流
14.2 基础
1)ENV:底层自动帮我们判断环境
2)Source:env.addSource
kafka
source之后就生成水印
设置空闲等待
3)transform:
map、flatmap、filter、connect、union、shuffled、rebalance、rescale
keyby:同一个分组的数据,会进入同一个分区
同一个分区内,可以有多个分组
两次Hash:第一次key本身的hashcode方法-->hash1
第二次hash-->hash2,对最大的并行度取模,得到键组ID(0~127)
计算分区:键组ID * 下游算子并行度 / 最大并行度
connect:一次只能连接两条流,类型可以不一致
union:一次可以合并多条流,类型必须一致
interval join:
(1)判断是否迟到,迟到就不处理
(2)每条流,各自存了Map类型的状态,来一条数据就存进去
key=时间戳,value=数据的集合
(3)不管哪条流的数据来了,它都会去对方的Map状态里遍历,查看是否能匹配上
(4)超过区间时,会清理Map对应的数据
4)sink:流.addSink()
14.3 高级
1)时间语义
处理时间
事件时间
注入时间
2)谈谈你对WaterMark的理解?
衡量事件时间的进展
处理乱序、迟到数据
单调不减
是一个特殊的时间戳,往下游传递
触发窗口、定时器的计算
Flink认为,时间戳小于watermark的数据,应该都处理过了,如果后面还有,则该数据为迟到数据
3)Watermark的传递
一对多:广播
多对一:以最小的为准
多对多:拆开来看
4)watermark是周期生成的吗?周期多久?
默认是周期生成,默认200ms
watermark = maxTs - 乱序程度 - 1ms
乱序程度:抽样估算、经验值(秒级或分钟级)
5)窗口分类
时间:滚动、滑动、会话
条数:滚动、滑动
6)窗口怎么划分?
窗口开始时间 = 事件时间戳 对 窗口长度取整
窗口结束时间 = 开始时间 + WindowSize
watermark >= 窗口最大时间戳,触发窗口的输出
7)窗口为什么左闭右开?
属于窗口的最大时间戳 = end - 1ms
8)什么时候创建、关窗(销毁)?
属于本窗口的第一条数据来的时间,现new的
watermark >= 窗口最大时间戳 + 允许迟到的时间
9)Flink怎么保证一致性?(丢数、重复)
状态:算子状态、键控状态(值、map、list、聚合类)、广播状态
状态后端:主要负责两件事,一是本地状态的管理,二是checkpoint的数据管理
| 本地状态 | checkpoint数据 | |
| 内存 | TM的堆内存 | JM的堆内存 |
| FS | TM的堆内存 | HDFS |
| RocksDB | RocksDB | HDFS |
企业怎么选? 一般用FS, 大厂用 RocksDB
端到端一致性的概念:
数据源:可重置,kafka满足要求
计算引擎:flink内部的checkpoint机制,barrier对齐
输出系统:幂等性、事务,输出是kafka,符合条件
展开checkpoint算法、barrier对齐
写到文件系统:
开启事务-->do--->do--->提交事务,如果失败就回滚
写入临时文件,成功,更改为正式文件名
失败,将临时文件删除
10)Flink怎么处理乱序、迟到?
(1)watermark
(2)允许迟到(窗口中设置)
(3)侧输出流
14.4 CEP&SQL
CEP三部曲:定义规则、应用规则、获取结果
SQL:动态表、连续查询 -->SQL解析器,Calcite
14.5 优化
1)提交参数:资源
2)如果是rocksdb:一些参数的调整
3)怎么处理反压?
(1)先断链
(2)webui看:第一个为ok的算子
(3)看对应算子的代码逻辑,修改
4)怎么处理数据倾斜?
(1)keyby前:利用重分区的算子,rebalance、rescale、shuffle
(2)keyby后:
(3)开窗
5)SQL参数
十五、实时数仓
15.1 ods层
用户行为日志、MySQL业务数据(maxwell)
2个Topic
15.2 dwd层 + dim层
kafka消费有序性(使用event time)
日志数据:页面日志放主流,其他4个放侧输出流(5个topic,页面,启动,曝光,事件,错误)
业务数据:
事实表:存kafka
维度表:存HBase、支持随时查询、长远考虑,没有做维度退化
动态分流:
首先在MySQL中创建一张配置表,指定了哪些表要去往哪里
然后使用FlinkCDC读取配置表,广播出去,做成广播流的形式
然后将广播流与主流中的数据进行connect,每一条数据都会匹配到一个配置信息,为接下来分流做准备
根据每条数据的配置分流出事实表和维度表,事实表根据配置信息中的Table名称作为Topic,然后sink到该Topic中
维度表先查询该表是否已经创建,如果没有创建,则先创建表(使用Phoenix),然后再往对应的表中写入数据
15.3 dwm层:预先处理的宽表
过渡层:避免拉宽表的时候,重复计算
事实表与事实表关联:双流Join(interval join)
事实表与维度表关联:通过Phoenix查询HBase
使用了异步IO的方式
做了旁路缓存(二级缓存):加速查询
如何保证缓存一致性?
如果是更新HBase,主动将Redis的数据进行一个更新处理
redis设置了过期时间,24小时(避免冷数据,长期占用缓存)
15.4 dws层:拉宽表(join和查维度)
宽表存ClickHouse
为什么存ClickHouse,为什么不存HBase?
HBase适合存明细数据,对于聚合分析统计,不太擅长,效率不高
ClickHouse聚合分析统计,快,不擅长join,适合放宽表这种已经关联过的数据表,字段多、数据量大的
开了一个小窗口:攒批,攒批一次性写入ClickHouse(因为ClickHouse对并发支持不好,最高每秒100次请求)
15.5 怎么保证一致性?
写Kafka:flink的checkpoint、两阶段提交的sink
写HBase:幂等性
写ClickHouse:ReplacingMergeTree(合并树),但只能保证最终一致性,合并分片时才会去重
解决方案:
1)手动优化
2)查ClickHouse时,加个group by
3)使用final(去重并取最新的数据),早期版本只支持单线程,20.5开始才开始支持多线程
使用方式:在表名后面加final即可
怎么用?推荐使用final + group by的方式
15.6 ads层
直接实时查询 dws层的数据,展示给前端(sugar)
15.7 一共几个Topic?
ods:2个
dwd:日志5个、业务15个
dwm:4个
dws:4个
2 + 5 + 15 + 4 + 4 = 30,所以我们公司有30多个Topic
15.8 一共几张表?
业务表30多张
15.9 数据量、速率、条数?
日活60万,平均每人产生100条数据,每条数据大小在0.5k~2k之间,平均取1k,所以每天产生60多G左右的数据
平均每秒产生700多条数据,平均每秒产生0.7M左右的数据
高峰期每秒产生1万多条数据,每秒产生10多M的数据
低谷期每秒产生40多条数据,每秒产生40k左右的数据
15.10 用什么监控?
Kafka:eagle
Flink:Prometheus + Grafana
ClickHouse:Prometheus + Grafana
15.11 ClickHouse支不支持更新?
是一个OLAP数据库,不支持事务
能更新、删除,但不是真正的更新和删除,使用:alter table xxx 实现
更新、删除的数据,只有在分片时才会真正的清理