此作业的要求参见https://edu.cnblogs.com/campus/nenu/2019fall/homework/6583
代码:https://e.coding.net/meixiaoyu/work.git
词频统计 SPEC 20180918
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
重难点分析:1.需要将wf.py文件生成wf.exe文件
2.实现文件的读取
代码片段:
def main(): infile=open(filename,'r') count=100 words=[] data=[] #读取文件
wordCounts={} for line in infile: processLine(line.lower(), wordCounts) pairs = list(wordCounts.items()) #记录词频数 print("total : %d "% len(pairs)) items = [[x,y]for (y,x)in pairs] items.sort() for i in range(len(items) - 1, -1 , -1): print(items[i][1] + " " + str(items[i][0])) data.append(items[i][0]) words.append(items[i][1]) infile.close() #按词频数进行排序
运行结果如图所示:
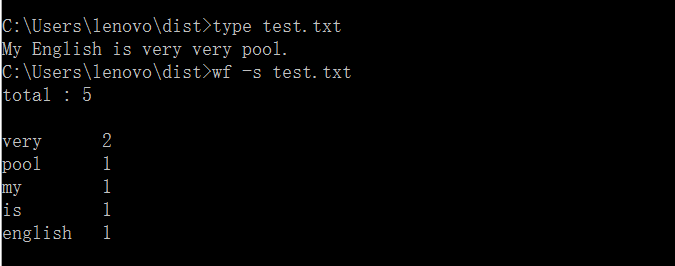
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
重难点分析:文件更大,需要对出现频数不同的字符排序
代码片段:
tf = {} for word in word_list2: word = word.lower() # print(word) word = ''.join(word.split()) if word in tf: tf[word] += 1 else: tf[word] = 1 return tf def get_counts(words): tf = {} for word in words: word = word.lower() # print(word) word = ''.join(word.split()) if word in tf: tf[word] += 1 else: tf[word] = 1 #统计词频
#根据频数排序,得到频数最高的前十个词
运行效果图:
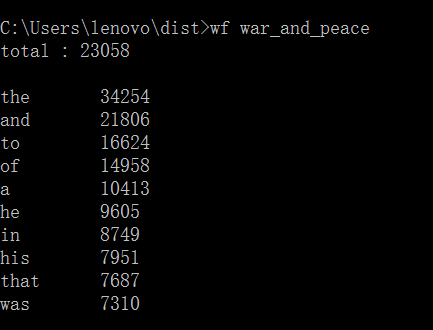
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
>dir folder
gone_with_the_wand
runbinson
janelove
>wf folder
gone_with_the_wand
total 1234567 words
the 5023
a 4783
love 4572
fire 4322
run 3822
cheat 3023
girls 2783
girl 2572
slave 1322
buy 822
----
runbinson
total 1234567 words
重难点:批量读取文件
代码:
textFolder = folderName fileNameList = [] for folder in folderList: if textFolder == folder: path1= os.listdir(folder) for i in path1: if os.path.splitext(i)[1] == '.txt': fileNameList.append(os.path.splitext(i)[0])
#读取文件夹中文件进行批量读取
运行效果图:
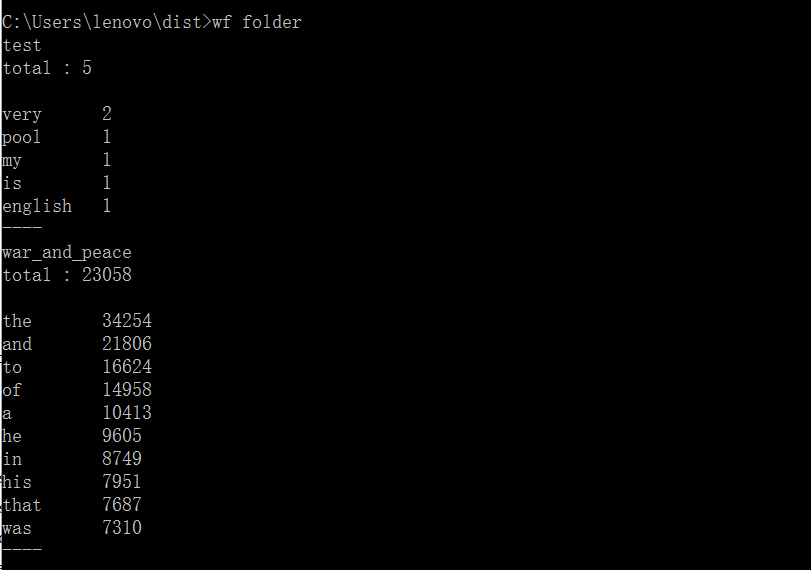
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)
关于重定向捕获的文件方面理解不清晰,查阅了相关资料,简单写了一些代码,但是还没有实现。
def main(argv): if sys.argv[1] == '-h': print ('test.py -i -s filename.txt') sys.exit() elif sys.argv[1]=="-s": if(len(sys.argv)==3): countFileWords(sys.argv[2]) else: redirect_words = sys.stdin.read()
psp表格
