个人感觉1.8新特性中Lambda和Stream算是一个很大的革新,当然默认方法和新的日期时间 API等特性也是很有意义的。只不过在我工作使用较少就不在这里叙述。
1.Lambda表达式
个人的理解Lambda表达式是一种使用特定语法书写的代码,因此我一直将他称为Lambda语法(个人理解),这种语法并不是开辟了什么新的东西,只是将原有的我们编写代码的方法变得更为简洁高效。由编译器转换为常规的代码,一定程度上减少代码的臃肿,但是第一篇文章的大佬还是不建议乱用哈哈。
首先我们来看一下Lambda表达式的写法(语法):
(parameters) -> expression
或
(parameters) ->{ statements; }
(参数)-> 表达式
或者
(参数)->{ 执行的代码;}。
- 可选类型声明:不需要声明参数类型,编译器可以统一识别参数值。
- 可选的参数圆括号:一个参数无需定义圆括号,但多个参数需要定义圆括号。
- 可选的大括号:如果主体包含了一个语句,就不需要使用大括号。
- 可选的返回关键字:如果主体只有一个表达式返回值则编译器会自动返回值,大括号需要指定明表达式返回了一个数值。
这里的参数不是必须的,同样也不限制个数。
可以通过简单的示例进行一个了解:
public class Test {
public static void main(String[]args){
SystemMassage systemMassage=(message)->System.err.println("接口实现输出:"+message);
systemMassage.sayMessage("你好");
}
interface SystemMassage {
void sayMessage(String message);
}
}
执行方法输出:接口实现输出:你好
(是不是有点草率,手动黑脸)。
我们可以通过用lombda的forEach循环对比原来的for循环,加深我们的了解。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//原有forEach循环
for(Integer integer:numbers){
System.err.println(integer);
}
//java 8新的forEach 配合lambda
numbers.forEach((integer)->System.err.println(integer));
更多的lambda表达式参考第一篇文章。
2.Stream
java 8 API添加了一个新的抽象称为流Stream,可以让你以一种声明的方式处理数据。
Stream 使用一种类似用 SQL 语句从数据库查询数据的直观方式来提供一种对 Java 集合运算和表达的高阶抽象。
Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
这种风格将要处理的元素集合看作一种流, 流在管道中传输, 并且可以在管道的节点上进行处理, 比如筛选, 排序,聚合等。
图 1. 流管道 (Stream Pipeline) 的构成(来自IBM Developer)
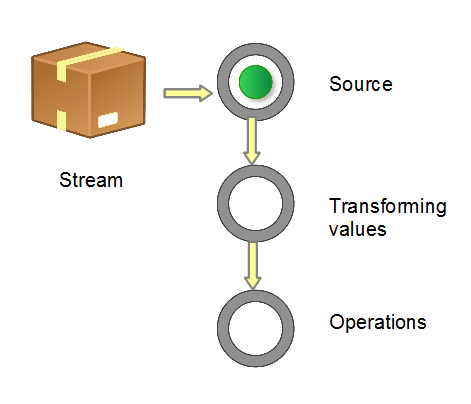
图片来自 IBM开发社区
有多种方式生成 Stream Source:
- 从 Collection 和数组
-
- Collection.stream()
- Collection.parallelStream()
- Arrays.stream(T array) or Stream.of()
- java.io.BufferedReader.lines()
- 静态工厂
- java.util.stream.IntStream.range()
- java.nio.file.Files.walk()
- 自己构建
-
- java.util.Spliterator
- Random.ints()
- BitSet.stream()
- Pattern.splitAsStream(java.lang.CharSequence)
- JarFile.stream()
流的操作类型分为两种:
- Intermediate:一个流可以后面跟随零个或多个 intermediate 操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
- Terminal:一个流只能有一个 terminal 操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal 操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个 side effect。
在对于一个 Stream 进行多次转换操作 (Intermediate 操作),每次都对 Stream 的每个元素进行转换,而且是执行多次,这样时间复杂度就是 N(转换次数)个 for 循环里把所有操作都做掉的总和吗?其实不是这样的,转换操作都是 lazy 的,多个转换操作只会在 Terminal 操作的时候融合起来,一次循环完成。我们可以这样简单的理解,Stream 里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在 Terminal 操作的时候循环 Stream 对应的集合,然后对每个元素执行所有的函数。
还有一种操作被称为 short-circuiting。用以指:
- 对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream。
- 对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果。
当操作一个无限大的 Stream,而又希望在有限时间内完成操作,则在管道内拥有一个 short-circuiting 操作是必要非充分条件。
先来一个示例操作简单了解一下:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
//实现当前集合大于10的值求和。
//原来的写法
int sum=0;
for(Integer integer:numbers){
if(integer>8){
sum+=integer;
}
}
//打印结果
System.err.println(sum);
//使用java8 的 Stream后的操作
//获取Stream
Stream<Integer> integerStream=numbers.stream();
//当前数组大于8的值求和
int sum= integerStream.filter((x)->x>8).mapToInt(Integer::intValue).sum();
//打印结果
System.err.println(sum);
filter 和 mapToInt 为 intermediate 操作,进行数据筛选和转换,最后一个 sum() 为 terminal 操作,对符合条件的全部结果求和。
需要注意的是,对于基本数值型,目前有三种对应的包装类型 Stream:
IntStream、LongStream、DoubleStream。当然我们也可以用 Stream<Integer>、Stream<Long> >、Stream<Double>,但是 boxing 和 unboxing 会很耗时,所以特别为这三种基本数值型提供了对应的 Stream。
Java 8 中还没有提供其它数值型 Stream,因为这将导致扩增的内容较多。而常规的数值型聚合运算可以通过上面三种 Stream 进行。
所以上面的代码我们可以这样写
IntStream integerStream= (IntStream) numbers.stream();
//当前数组大于8的值求和
int sum= integerStream.filter((x)->x>8).sum();
//打印结果
System.err.println(sum);
流的操作
接下来,当把一个数据结构包装成 Stream 后,就要开始对里面的元素进行各类操作了。常见的操作可以归类如下。
- Intermediate:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
流转换为其它数据结构
// 1. ArrayString[] strArray1 = stream.toArray(String[]::new);// 2. CollectionList<String> list1 = stream.collect(Collectors.toList());List<String> list2 = stream.collect(Collectors.toCollection(ArrayList::new));Set set1 = stream.collect(Collectors.toSet());Stack stack1 = stream.collect(Collectors.toCollection(Stack::new));// 3. StringString str = stream.collect(Collectors.joining()).toString();我们下面看一下 Stream 的比较典型用法。
map/flatMap
我们先来看 map。如果你熟悉 scala 这类函数式语言,对这个方法应该很了解,它的作用就是把 input Stream 的每一个元素,映射成 output Stream 的另外一个元素。(这段话是复制IBM的帖子,个人理解就是对值进行操作,可以通过代码详细了解,通过和原有的写法进行对比更容易理解,在写博客之前我也对它没理解。)
//将数组所有值转换为大写
List<String> strings = Arrays.asList("a", "b", "c", "d", "E", "f", "h", "i");
//定义结果集合
List<String> UpperCaseStr = new ArrayList<>();
//原来的写法 通过for循环遍历当前数组
for (String str : strings) {
//操作每一个元素并放入集合
UpperCaseStr.add(str.toUpperCase());
}
// 打印结果
System.err.println(UpperCaseStr);
//使用Stream的Map
List<String> UpperCaseStr =strings.stream().map(String::toUpperCase).collect(toList());
//下面的代码引自IBM的那篇文章
清单 8. 平方数
|
1
2
3
4
|
List<Integer> nums = Arrays.asList(1, 2, 3, 4);List<Integer> squareNums = nums.stream().map(n -> n * n).collect(Collectors.toList()); |
这段代码生成一个整数 list 的平方数 {1, 4, 9, 16}。
从上面例子可以看出,map 生成的是个 1:1 映射,每个输入元素,都按照规则转换成为另外一个元素。还有一些场景,是一对多映射关系的,这时需要 flatMap。
flatMap没看明白先把概念放在这里,底下我再研究研究再来补充。评论区有大神的分享一下
Stream<List<Integer>> inputStream = Stream.of( Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6) );Stream<Integer> outputStream = inputStream.flatMap((childList) -> childList.stream()); |
flatMap 把 input Stream 中的层级结构扁平化,就是将最底层元素抽出来放到一起,最终 output 的新 Stream 里面已经没有 List 了,都是直接的数字。
我先去研究暂时告一段落
//经过一番研习之后大致将他搞懂了继续为大家进行介绍
依旧是举例说明,在学习的过程中网上很多帖子都是用一个HelloWord数组进行的介绍,也有流程图比较详细我就不在这里进行复述,我只写自己的用法及理解。
为了方便能够清晰理解,我先将原数组结构按照图片格式展示在这里:可以看到我们每一个元素中包含一个新的集合,这个时候我们如果想要将每一个元素下的集合取出,并汇总成一个新的集合就需要用到 flatMap方法代码如下。

//直接将JSON字符串转成我们的list集合
JSONArray jsonArray=JSONArray.parseArray( "[{"name":"张店区","areaCode":"370303","number":null,"areaGoodVos":[{"goodName":"丙烯腈,稳定的","goodNumber":12,"unno":"1093"},{"goodName":"丙烯","goodNumber":2,"unno":"1077"}]},{"name":"桓台县","areaCode":null,"number":null,"areaGoodVos":[]},{"name":"高新区","areaCode":null,"number":null,"areaGoodVos":[{"goodName":"丙烯腈,稳定的","goodNumber":12,"unno":"1093"},{"goodName":"丙烯","goodNumber":2,"unno":"1077"}]},{"name":"周村区","areaCode":null,"number":null,"areaGoodVos":[]},{"name":"淄川区","areaCode":null,"number":null,"areaGoodVos":[]},{"name":"经开区","areaCode":null,"number":null,"areaGoodVos":[]},{"name":"临淄区","areaCode":null,"number":null,"areaGoodVos":[]},{"name":"沂源县","areaCode":null,"number":null,"areaGoodVos