import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt #这个一直想学,还没学,代码从莫烦python那copy的
import torchvision
import torchvision.transforms as transforms
import numpy as np
很遗憾,看了半天还是没怎么学会,只能先记录俩个例子放在这里了。然后Pytorch就先告一段落吧。
一个简单的回归网络的例子
这个例子是对莫烦python那例子的一个修改(主要是自己玩了下,懒得弄回去了)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = 4 * x ** 3 + x ** 2 + 3 * x + 0.2*torch.rand(x.size())
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self):
super(Net, self).__init__() # 继承 __init__ 功能
# 定义每层用什么样的形式
self.hidden = nn.Linear(1, 7) # 隐藏层线性输出
#self.hidden2 = torch.nn.Linear(3, 7)
self.predict = nn.Linear(7, 1) # 输出层线性输出
self.active = nn.Tanh() # 这里的激活函数玩得挺多的,带ReLU的一般效果都不错,还有Softshrink 有正有负效果也很好啊
def forward(self, x): # 这同时也是 Module 中的 forward 功能
# 正向传播输入值, 神经网络分析出输出值
x = self.active(self.hidden(x)) # 激励函数(隐藏层的线性值)
#x = self.active(self.hidden2(x))
x = self.predict(x) # 输出值
return x
net = Net()
plt.ion() # 画图
plt.show()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9) # 传入 net 的所有参数, 学习率
loss_func = nn.MSELoss()
for t in range(100):
prediction = net(x) # 喂给 net 训练数据 x, 输出预测值
loss = loss_func(prediction, y) # 计算两者的误差
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 接着上面来
if t % 20 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
有很多很有趣的现象,主要就是跟参数有关的东西:
self.hidden = nn.Linear(1, 100)
self.predict = nn.Linear(100, 1)
可能会出现下面的情况:

增加一个隐藏层也往往会这样。这个就是所谓的梯度爆炸?这类名字我也只是听过,到时候再深入吧,在此记一笔。
Tanh() 改为 Softshrink 就没问题了(因为Softshrink有正有负所以会有所抵消?)
再者:
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) * 3
一样会炸,所以要很小心才行啊(对了,调小学习率可以应付这种情况)。
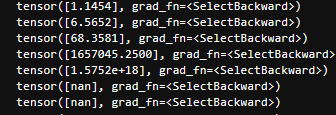
没一会功夫,最大参数的值就突破天际了。
再来一个例子
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 7)
#self.fc2 = nn.Linear(7, 5)
self.fc3 = nn.Linear(7, 1)
self.active = nn.ReLU()
def forward(self, x):
x = self.active(self.fc1(x))
#x = self.active(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
# y = x1 ** 3 + x2 ** 2 + x3 + e
x = torch.rand(100, 3)
y = x[:,0] ** 3 + x[:,1] ** 2 + x[:, 2] + torch.randn(100) * 0.05
optimizer = torch.optim.SGD(net.parameters(), lr=0.005, momentum = 0.9)
loss_func = nn.MSELoss()
for t in range(200):
pre = net(x)
loss = loss_func(pre, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#print('step: {0} | loss: {1}'.format(t, loss))
#结果很遗憾,最后都会趋于一个值,咋搞,弄不明白啊。
官方教程上图片识别的例子
图片是 3×32×323 imes 32 imes 323×32×32的
transform = transforms.Compose( #转换格式
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, #训练样本
download=False, transform=transform) #我下好了所以是False
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0) #num_workers 好像是线程进程的处理,但是我用了这个会崩,就改成0 shuffle 打扰顺序, batch_size,一个数据分成几堆,批训练。
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
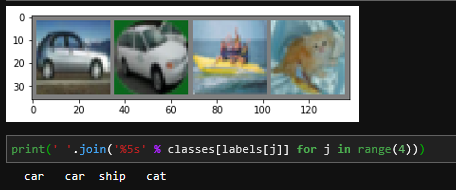
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # (3,6,5) in_channel:3,out_channel:6,kernel_size:5 * 5
#说人话就是,输入的图片是3个通道的(RGB),卷积后的图片是6个通道的,就是6层的矩阵
self.pool = nn.MaxPool2d(2, 2) #池化
self.conv2 = nn.Conv2d(6, 16, 5) #卷积
self.fc1 = nn.Linear(16 * 5 * 5, 120) #全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) #图片大小转换:(3,32,32)->(6,28,28)->(6,14,14)
x = self.pool(F.relu(self.conv2(x))) #图片大小转换: (6,14,14)->(16,10,10)->(16,5,5)
x = x.view(-1, 16 * 5 * 5) #这玩意儿是用来排列图像的 (16,5,5)是从上面得到的
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss() #交叉熵
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times 整体数据走2遍
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#测试数据
dataiter = iter(testloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))