支持向量机
本节将依SMO算法训练线性SVM, 核方法的使用可以很方便的进行扩展.
import numpy as np
import matplotlib.pyplot as plt
下面的Point的类中的:
[g(x) = sum_{i=1}^N alpha_i y_i k(x_i, x) + b,
]
[e = g - y, yg = y * g
]
class Point:
"""
因为在SM0算法中,我们需要不断更新以及判断数据点的
各种属性,所以创建了一个新的数据类型Point.
"""
def __init__(self, x, y, k, order,
g, alpha, c):
assert y == 1 or y == -1, "Invalid y"
self.x = x #数据向量
self.y = y # 类
self.order = order #序
self.k = k #距离矩阵
self.c = c
self.g = g
self.yg = g * y #衡量违背条件的指标
self.alpha = alpha
self.e = g - y
def kkt(self, epsilon=0.001):
"""
检查是否符合KKT条件
:epsilon: 条件判断时允许的误差
:return: 0 表示符合, 1 表示 不符合 其原因是便于统计不满足kkt的数据点的总量
"""
alpha = self.alpha
cond = self.y * self.g
if alpha == 0. and cond < 1 - epsilon:
self.satisfy_kkt = False
elif 0 < alpha < self.c and (cond <1 - epsilon or cond > 1 + epsilon):
self.satisfy_kkt = False
elif alpha == self.c and cond > 1 + epsilon:
self.satisfy_kkt = False
else:
self.satisfy_kkt = True
if self.satisfy_kkt:
return 0
else:
return 1
def update_g_e(self, dog1, dog2, oldb, newb, newalpha1, newalpha2):
"""
更新g, e参数
"""
k1 = self.k[self.order, dog1.order]
k2 = self.k[self.order, dog2.order]
self.g = self.g + (newalpha1- dog1.alpha) * dog1.y * k1
+ (newalpha2- dog2.alpha) * dog2.y * k2
+ newb - oldb
self.e = self.g - self.y
self.yg = self.g * self.y
下面是Points类的定义, 用训练和预测,值得一提的是在initial函数中对于alpha的初始化,从([0, self.c / self.size])中依照均匀分布选取,并且对最后一个样本的进行特别处理,以保证(sum alpha_i y_i=0), 这意味着(alpha)将是一个可行解, 一些文章中似乎是将alpha初始化为0的,不知道按照这种方式怎么进行更新迭代,因为:
[alpha_2^{new, unc} = alpha_2^{old} + frac{y_2(E_1-E_2)}{eta},
]
可(alpha^{old} = 0, b = 0, Rightarrow E=0 Rightarrow alpha^{new}=0). 意味着样本的参数(alpha)是不会变化的.
另外calc_func_value,计算的是:
[frac{1}{2} sum_{i=1}^Nsum_{j=1}^N alpha_i alpha_j y_i y_j k(x_i, x_j) - sum_{i=1}^N alpha_i
]
这个值越小收敛的越好
class Points:
"""
数据点的集合
"""
def __init__(self, points, labels, c=1.):
self.points = [] #用于保存Point对象
self.size = len(points)
self.initial(points, labels, c=c)
def distance(self, point1, point2):
"""
计算内积矩阵, 可以在这个函数中加入核方法而达到
核SVM的目的.
"""
return point1 @ point2
def initial(self, points, labels, b=0., c=1.):
"""
初始化 w, b
w: 权重
b: 截距
c: 正则化项的系数
:return:
"""
self.b = b
self.c = c
# alpha 进行初始化
alpha = np.random.uniform(0, self.c / self.size, size=self.size)
y = labels
the_sum = np.sum(y * alpha)
alpha[-1] = alpha[-1] - the_sum * y[-1]
while not (0 < alpha[-1] < self.c):
alpha = np.random.uniform(0, self.c / self.size, size=self.size)
the_sum = np.sum(y * alpha)
alpha[-1] = alpha[-1] - the_sum * y[-1]
alphay = alpha * y
k = np.zeros((self.size, self.size))
for i in range(self.size):
for j in range(i, self.size):
k[i, j] = self.distance(points[i], points[j])
k[j, i] = self.distance(points[j], points[i])
self.k = k #内积矩阵
g = k @ alphay + self.b
for i in range(self.size):
point = Point(points[i], labels[i], k, i,
g[i], alpha[i], c)
self.points.append(point)
def find_dog1(self, points):
"""
寻找第一个点
"""
lucky_dog1 = None
lucky_value1 = 99999999999.
dogs = points.copy()
#首先我们在不满足的kkt条件的支持向量中寻找
for dog in dogs:
if not dog.satisfy_kkt and dog.alpha > 0:
cond =np.abs(dog.yg - 1)
if cond < lucky_value1:
lucky_dog1 = dog
lucky_value1 = cond
#如果没找到,再在整个训练集中找违背kkt最严重的点.
if lucky_dog1 is None:
for dog in dogs:
if not dog.satisfy_kkt:
if dog.yg < lucky_value1:
lucky_dog1 = dog
lucky_value1 = dog.yg
return lucky_dog1
def find_dog2(self, points, dog1):
"""
寻找第二个点
"""
dogs = points.copy()
e1 = dog1.e
lucky_dog2 = None
lucky_value2 = -1.
#寻找使得|e2-e1|最大的点
for dog in dogs:
e2 = dog.e
value = np.abs(e2 - e1)
if value > lucky_value2:
lucky_dog2 = dog
lucky_value2 = value
return lucky_dog2
def calc_l_h(self, dogs):
"""
alpha需要裁剪,所以要计算L, H
:param dogs:
:return:
"""
dog1 = dogs[0]
dog2 = dogs[1]
if dog1.y != dog2.y:
l = max(0, dog2.alpha-dog1.alpha)
h = min(self.c, self.c + dog2.alpha-dog1.alpha)
else:
l = max(0, dog2.alpha+dog1.alpha-self.c)
h = min(self.c, dog2.alpha+dog1.alpha)
return (l, h)
def update(self, dogs, l, h):
"""
更新alpha, b, g, e
"""
dog1 = dogs[0]
dog2 = dogs[1]
e1 = dog1.e
e2 = dog2.e
k11 = self.k[dog1.order, dog1.order]
k12 = self.k[dog1.order, dog2.order]
k21 = self.k[dog2.order, dog1.order]
k22 = self.k[dog2.order, dog2.order]
eta = k11 + k22 - 2 * k12
alpha2_unc = dog2.alpha + dog2.y * (e1 - e2) / eta #未裁剪的alpha2
if alpha2_unc < l:
alpha2 = l
elif l < alpha2_unc < h:
alpha2 = alpha2_unc
else:
alpha2 = h
alpha1 = dog1.alpha + dog1.y * dog2.y * (dog2.alpha - alpha2)
b1 = -e1 - dog1.y * k11 * (alpha1 - dog1.alpha) -
dog2.y * k21 * (alpha2 - dog2.alpha) + self.b
b2 = -e2 - dog1.y * k12 * (alpha1 - dog1.alpha) -
dog2.y * k22 * (alpha2 - dog2.alpha) + self.b
b = (b1 + b2) / 2
#更新g, e
for point in self.points:
point.update_g_e(dog1, dog2, self.b, b, alpha1, alpha2)
#更新alpha, b
dog1.alpha = alpha1
dog2.alpha = alpha2
self.b = b
return (alpha1, alpha2, b)
def update_kkt(self, epsilon):
"""
检查每个Point是否符合kkt条件,并返回
不合格的Point的数量
"""
count = 0
for point in self.points:
count += point.kkt(epsilon)
return count
def calc_func_value(self):
"""
计算函数的值
"""
alpha = np.array([point.alpha for point in self.points])
y = np.array([point.y for point in self.points])
alphay = alpha * y
value = alphay @ self.k @ alphay - np.sum(alpha)
return value
def calc_w(self):
"""
计算w
"""
w = 0.0
for point in self.points:
w += point.alpha * point.y * point.x
self.w = w
return w
def smo(self, max_iter, x, y1, y2, epsilon=1e-3, enough_num=10):
"""
事实上,并不需要传入x, y1, y2, 这里只是做可视化用,
w 也仅在线性分类器时是有用的.
enough_num: 当不满足kkt条件的数目小于enough_num是退出
"""
iteration = 0
value_pre = None
points1 = self.points.copy()
points2 = self.points.copy()
while True:
iteration += 1
count = self.update_kkt(epsilon)
value = self.calc_func_value()
#print(iteration, value, count)
if count < enough_num or iteration > max_iter:
break
#下面部分的含义是如果我们所选的Point不能函数值下降,那么遍历其它的点
#直到目标函数有足够的下降,如果还不行,那么抛弃第一个Point,选择其它的Point
if value_pre == value:
points2.remove(dog2)
if len(points2) > 1:
dog2 = self.find_dog2(points2, dog1)
else:
points1.remove(dog1)
points2 = points1.copy()
dog1 = self.find_dog1(points1)
points2.remove(dog1)
dog2 = self.find_dog2(points2, dog1)
else:
points1 = self.points.copy()
points2 = self.points.copy()
dog1 = self.find_dog1(points1)
points2.remove(dog1)
dog2 = self.find_dog2(points2, dog1)
value_pre = value
l, h = self.calc_l_h((dog1, dog2))
self.update((dog1, dog2), l, h)
"""
可视化部分
if iteration % 10 == 9:
self.calc_w()
plt.cla()
plt.scatter(x, y1)
plt.scatter(x, y2)
y = -self.w[0] / self.w[1] * x - self.b
plt.title("SVM")
plt.plot(x, y, color="red")
plt.pause(0.01)
"""
self.calc_w()
return self.w, self.b
def pre(self, x):
"""
给定x 预测其分类, %%sh上,如果是线性分类器,
只需计算self.w,再计算self.w @ x + self.b即可,
为了方便扩展,这里做了一般化.
"""
value = self.b
for point in self.points:
value += point.alpha * point.y *
self.distance(x, point.x)
sign = 1 if value >= 0 else -1
return sign
准备数据
蓝色部分:
[y1 = 2x + 5 + epsilon_1, epsilon1 sim mathcal{N}(0, sigma^2).
]
红色部分
[y2 = 2x - 5 + epsilon_2, epsilon2 sim mathcal{N}(0, sigma^2)
]
np.random.seed(10086)
x = np.linspace(0, 10, 100)
e1 = np.random.randn(100) * 2
e2 = np.random.randn(100) * 2
y1 = 2 * x + 5 + e1
y2 = 2 * x - 5 + e2
data1 = np.hstack((x.reshape(-1, 1), y1.reshape(-1, 1)))
data2 = np.hstack((x.reshape(-1, 1), y2.reshape(-1, 1)))
data = np.vstack((data1, data2))
labels = np.hstack((np.ones(100), -np.ones(100)))
plt.scatter(x, y1)
plt.scatter(x, y2)
plt.show()
测试
test = Points(data, labels, c=10)
w, b = test.smo(30000, x, y1, y2, epsilon=1e-7)
print(w, b)
plt.scatter(x, y1)
plt.scatter(x, y2)
y = -w[0] / w[1] * x - b
plt.plot(x, y, color="red")
plt.show()
[-1.25243632 0.5887332 ] -1.1498779874793863

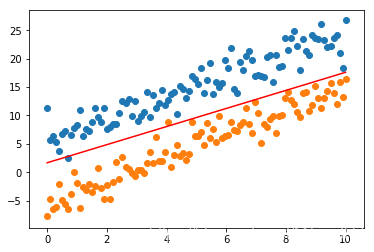
有些时候结果是不会那么好的, 在收敛过程中还是会有波动的, 而且数据越是混越是波动大
test.pre(np.array([10., 0.]))
-1
test.pre(np.array([0., 10.]))
1
test = Points(data, labels, c=1)
w, b = test.smo(30000, x, y1, y2, epsilon=1e-7)
print(w, b)
plt.scatter(x, y1)
plt.scatter(x, y2)
y = -w[0] / w[1] * x - b
plt.plot(x, y, color="red")
plt.show()
[-1.33721113 0.83955356] -1.6680372246340474
test = Points(data, labels, c=0.1)
w, b = test.smo(30000, x, y1, y2, epsilon=1e-7)
print(w, b)
plt.scatter(x, y1)
plt.scatter(x, y2)
y = -w[0] / w[1] * x - b
plt.plot(x, y, color="red")
plt.show()
[-0.78780019 0.44522279] -0.6061702858422205
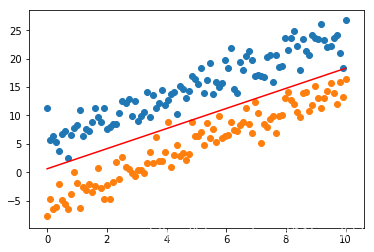
实验中发现, c越大波动越大,或许在训练过程可以动态调整c