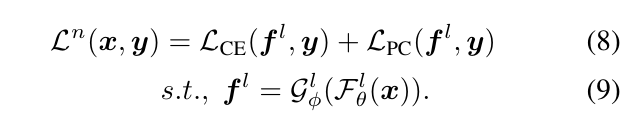概
类似的, 是large margin的思想, 亮点是多层?
主要内容
以下, (f^l)表示第(l)层的输入, (f)为最后一层的输入.

一般的网络只有(mathcal{L}_{CE}):
[ ag{1}
mathcal{L}_{CE}(x,y)=sum_{i=1}^m -log frac{exp(w_{y_i}^Tf_i+b_i)}{sum_{j=1}^kexp(w_j^Tf_i+b_j)},
]
从几何上将是不鲁棒的, 所以本文加了一个正则化项:
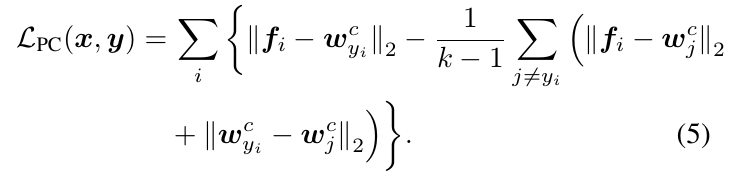
显然, 这个是希望(f_i)和类别中心(w_{y_i})靠的近, 同时最大化类间距离.
进一步可以拓展到多层情况: