motivation
用两个BN(一个用于干净样本, 一个用于对抗样本), 结果当使用(mathrm{BN}_{nat})的时候, 精度能够上升, 而使用(mathrm{BN}_{adv})的时候, 也有相当的鲁棒性. 原文采用的是
[alpha mathcal{L}(f(x), y) + (1-alpha) mathcal{L}(f(x+delta), y),
]
来训练(这里(f(x))输出的是概率向量而非logits), 试试看别的组合方式, 比如
[mathcal{L}(alpha f(x_{nat}) + (1-alpha)f(x_{adv}) ,y).
]
settings
| Attribute | Value |
|---|---|
| attack | pgd-linf |
| batch_size | 128 |
| beta1 | 0.9 |
| beta2 | 0.999 |
| dataset | cifar10 |
| description | AT=0.5=default-sgd-0.1=pgd-linf-0.0314-0.25-10=128=default |
| epochs | 100 |
| epsilon | 0.03137254901960784 |
| learning_policy | [50, 75] x 0.1 |
| leverage | 0.5 |
| loss | cross_entropy |
| lr | 0.1 |
| model | resnet32 |
| momentum | 0.9 |
| optimizer | sgd |
| progress | False |
| resume | False |
| seed | 1 |
| stats_log | False |
| steps | 10 |
| stepsize | 0.25 |
| transform | default |
| weight_decay | 0.0005 |
results
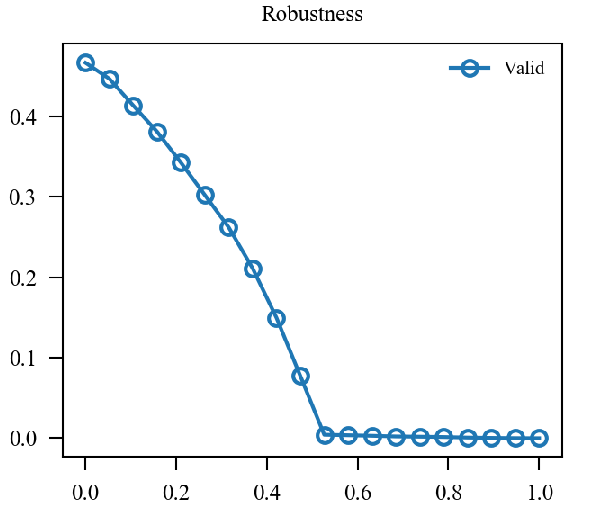
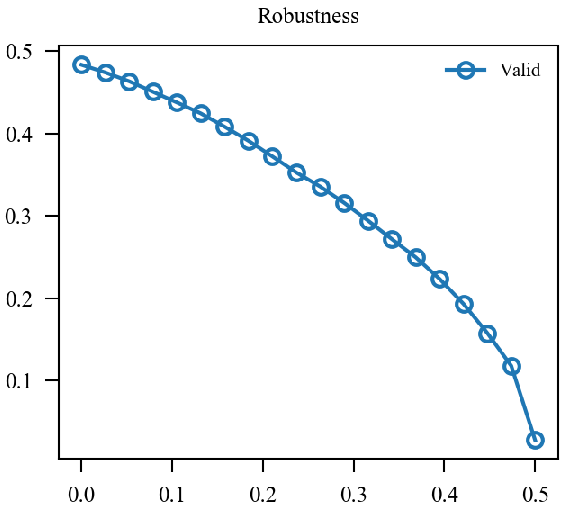
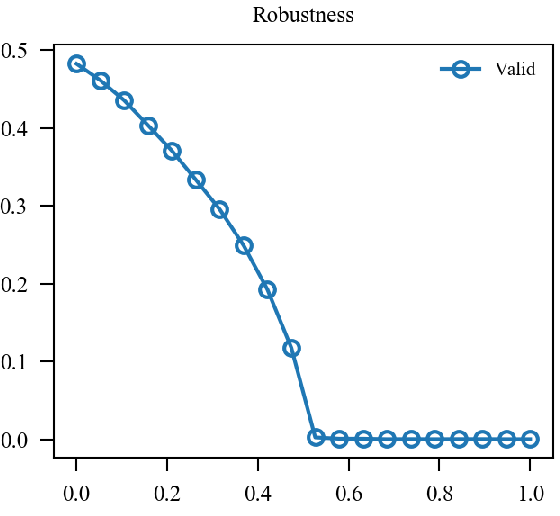
x轴为(alpha)从(0)变化到(1).
| Accuracy | Robustness | |
|---|---|---|
| (0.5 mathcal{L}_{nat} + 0.5mathcal{L}_{adv}) | 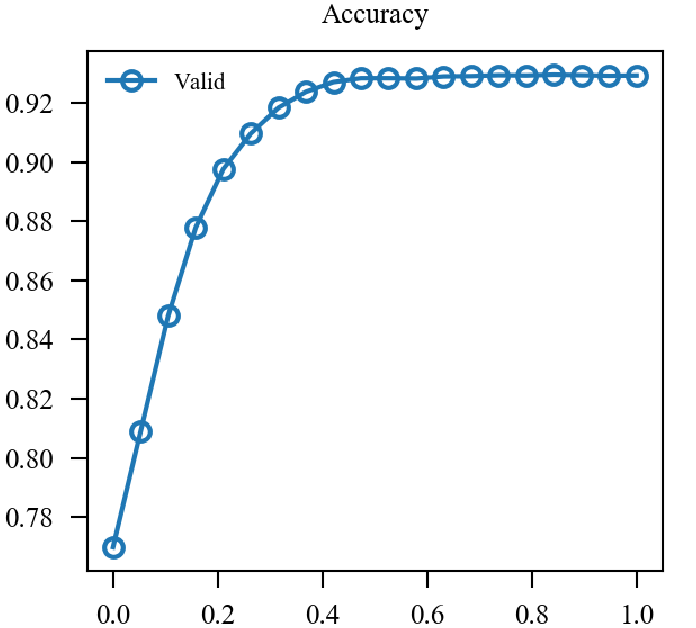 |
 |
| (mathcal{L}(0.5 p_{nat} + 0.5p_{adv}, y)) |  |
 |
| (0.1 mathcal{L}_{nat} + 0.9mathcal{L}_{adv}) 48.350 | 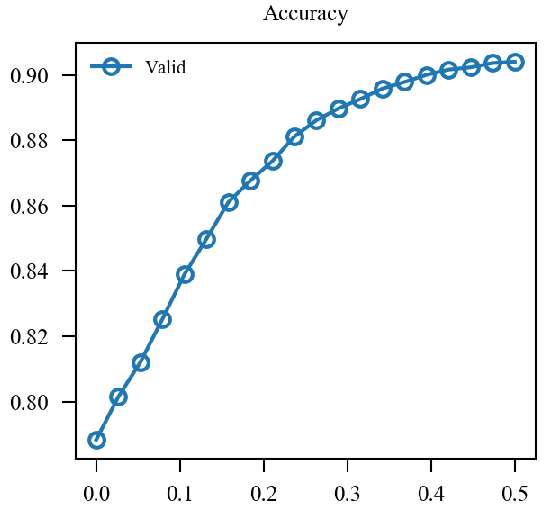 |
 |
| (mathcal{L}(0.1 p_{nat} + 0.9p_{adv}, y)) 48.270 | 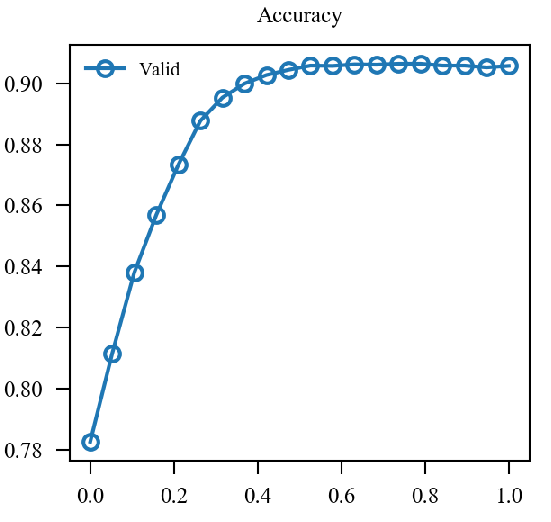 |
 |
| (0.2 mathcal{L}_{nat} + 0.8mathcal{L}_{adv}) 48.310 | 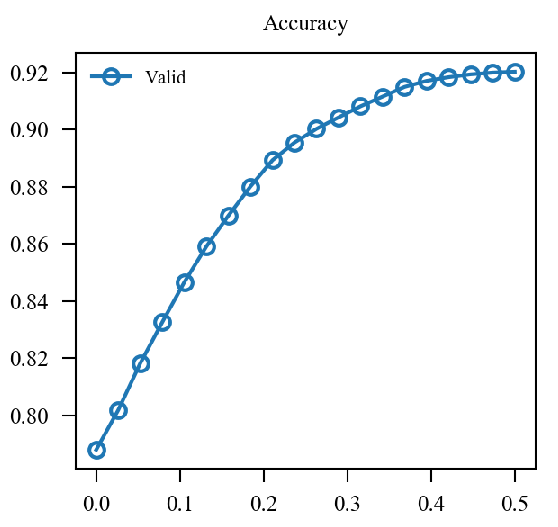 |
 |
| (mathcal{L}(0.2 p_{nat} + 0.8p_{adv}, y)) 47.960 | 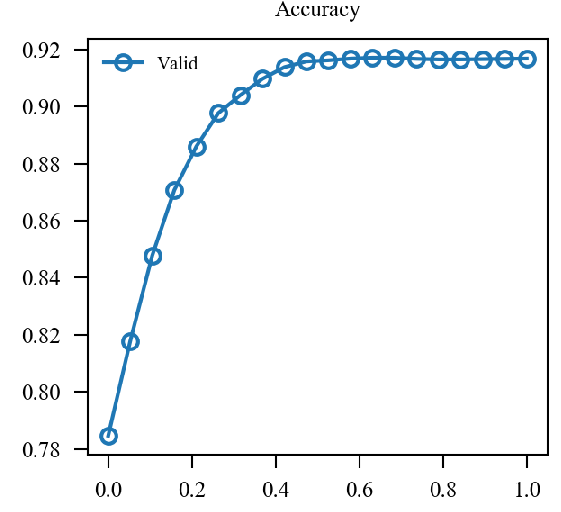 |
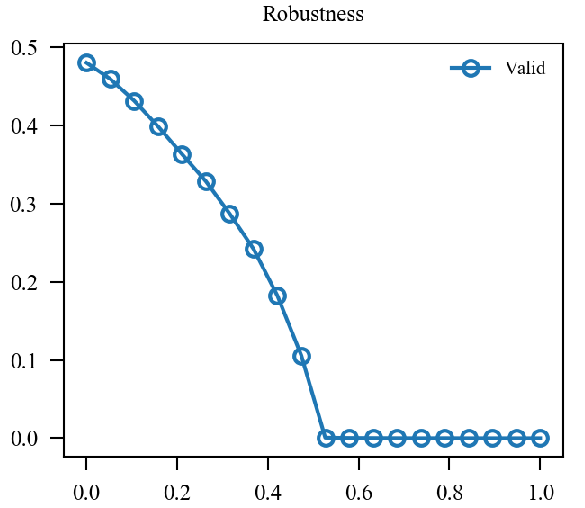 |
似乎原来的形式情况更好一点.