Radford A., Narasimhan K., Salimans T. and Sutskever I. Improving language understanding by generative pre-training. 2018.
Devlin J., Chang M., Lee K. and Toutanova K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Conference the North American Chapter of the Association for Computational Linguistics Human Language Technologies (NAACL-HLT), 2019.
概
两个经典的NLP的预训练模型.
主要内容
GPT

就是普通的transformer, 注意的是tokens之间的联系方式是auto-regressive的:
[P(x_i|x_{i-k}, cdots, x_{i-1} ; heta).
]
即每个token仅与之前的tokens有关.
BERT
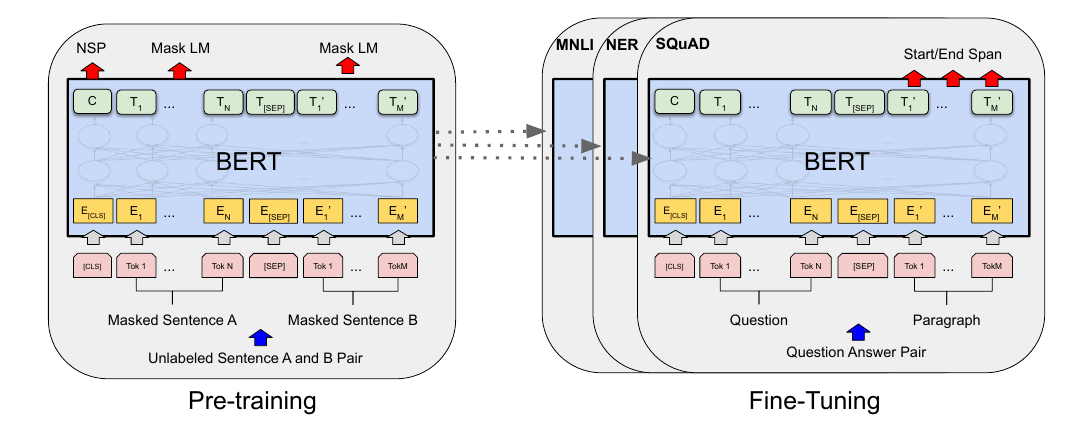
与GPT最为不同的是, BERT并非是auto-regressive的, 即其认为一个词可以通过上下文关联起来:
[P(x_i|X),
]
在实际中, BERT对部分的词mask掉, 相当于用别的词来推断:
[P(x_i|x_j,
ot in M).
]
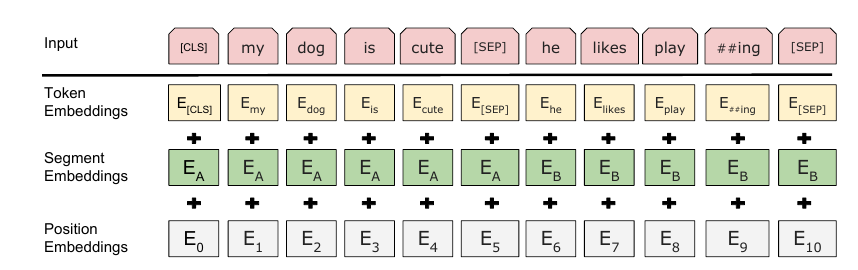
切除了普通的positional embeddings, 额外增加了segment embeddings, 用来标记不同的句子. 这么设计是认为很多下游任务都能通过两个部分的结构来表示.