概
通常的sliding windows需要大量的计算量: 首先我们需要框出一个区域, 再将该区域进行判断, 当区域(windows)的数量很多的时候, 这么做是非常耗时的.
但是本文作者发现, 通过卷积, 可以将所有的区域一次性计算, 使得大量重复计算能够节省下来. 个人觉得还是非常有意思的.
主要内容
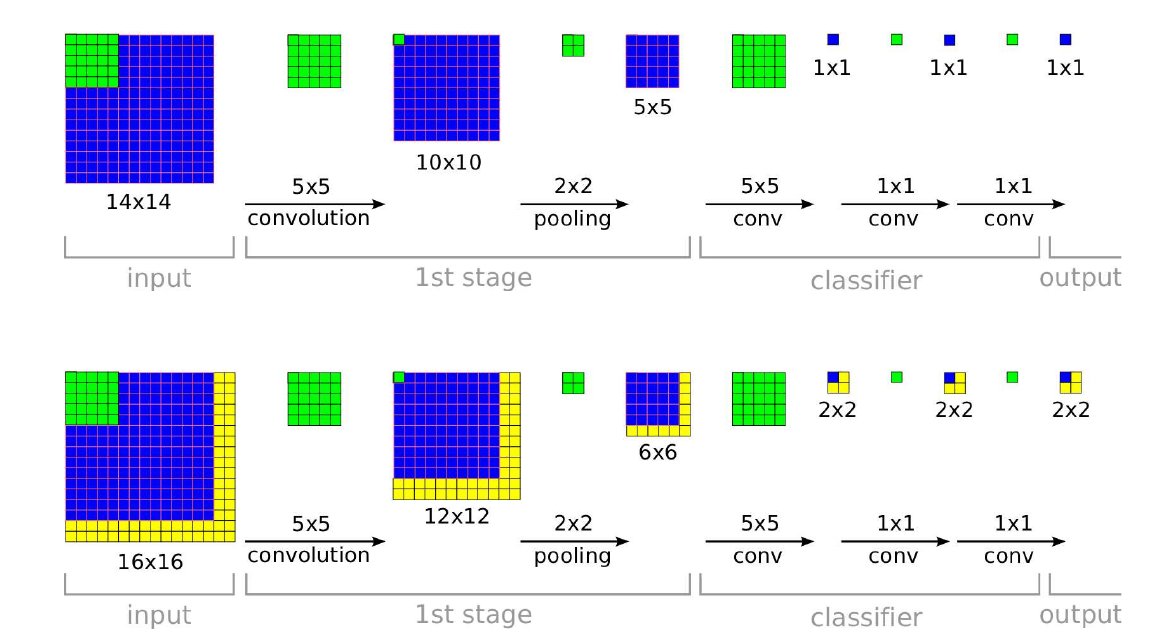
如上图所示, 第一行展示了对一个普通图片进行判断的过程:
- input: (14 imes 14 imes *), 经过(5 imes 5)的卷积核(stride=1, padding=0), 得到:
- (10 imes 10 imes *)的mappings, 再经过(2 imes 2)的pooling (stride=2, padding=0), 得到:
- (5 imes 5 imes *)的mappings, 到此为特征提取阶段;
- 接下来, 是分类器部分, 实际上, 原本是全连接层部分, 我们首先以全连接层的角度过一遍, 令(d_1=5 imes 5 imes *):
- 通过(W in mathbb{R}^{d_2 imes d_1}) 将特征映射为(d_2)的向量;
- 再通过(W' in mathbb{R}^{C imes d_2}) 将特征映射为(C)的向量(C表示类别数目);
- 既然全连接层是特殊的卷积, 4相当于
- (d_1)个(5 imes 5)的卷积作用于特征, 5相当于
- (d_2)个(1 imes 1)的卷积, 6相当于
- (C)个(1 imes 1)的卷积.
再来看第二行, 其输入为(16 imes 16)大小的图片, 输出是(2 imes 2 imes C), 而且蓝色部分之间是相互对应的. 设想, 我们将(16 imes 16)的图片通过sliding windows (stride=2)可以划分出四幅图片, 而这四个图片经过网络所得到的logits正好是最后输出的(2 imes 2)中所对应的位置, 这意味着我们一次性计算了所有的windows, 但是计算量却并没有太多增加.
那么, 相应的windows是怎么划分的呢?
倘若网络每一层的核的stride为(s_1, s_2, cdots, s_k), 那么windows之间的stride应该为
[s_1 imes s_2 imes cdots imes s_k.
]
注: stride是固定的, 但是图片的大小不一定固定, 像ResNet, 由于全连接层前有一个average pooling的操作, 故我们可以传入大小不定的图片进去.
问: 但是有些卷积核还有padding的操作, 这个该如何理解呢?(小误差?)