高性能Linux服务器 第10章 基于Linux服务器的性能分析与优化
作为一名Linux系统管理员,最主要的工作是优化系统配置,使应用在系统上以最优的
状态运行。但硬件问题、软件问题、网络环境等的复杂性和多变性,使得对系统的优化变得
异常复杂,如何定位性能问题出在哪个方面,是性能优化的一大难题。本章从系统人手,重
点讲述由于系统软、硬件配置不当造成的性能问题,并且给出了检测系统故障和优化性能的
一般方法和流程。
10.1 系统性能分析的目的
10.1.1 找到系统性能的瓶颈
系统的性能是指操作系统完成任务的有效性、稳定性和响应速度。Linux系统管理员可
能经常会遇到系统不稳定、响应速度慢等问题,例如在Linux上搭建了一个Web服务,经常
出现网页无法打开、打开速度慢等现象。遇到这些问题,就会有人抱怨Linux系统不好,其
实这些都是表面现象。操作系统完成一个任务是与系统自身设置、网络拓扑结构、路由设
备、路由策略、接入设备、物理线路等多个方面密切相关的,任何一个环节出现问题,都会
影响整个系统的性能。因此,当Linux应用出现问题时,应当从应用程序、操作系统、服务
器硬件、网络环境等方面综合排查,定位问题出现在哪个部分,然后集中解决。
10.1.2提供性能优化方案
查找系统性能瓶颈是个复杂而耗时的过程,需要在应用程序、操作系统、服务器硬件、
网络环境等方面进行查找和定位,影响性能最大的是应用程序和操作系统两个方面,因为这
两个方面出现的问题不易察觉,隐蔽性很强。而硬件、网络方面出现的问题,一般都能马上
定位。一旦找到了系统性能问题,解决起来就非常迅速和容易。例如发现系统硬件存在问
题,如果是物理故障,那么更换硬件就可以了,如果是硬件性能不能满足需求,升级硬件就
可以了;如果发现是网络问题,比如带宽不够、网络不稳定,只需优化和升级网络即可:如
果发现是应用程序问题,修改或优化软件系统即可;而如果是操作系统配置问题,修改系统
参数、修改系统配置即可。
可见,只要找到了性能瓶颈,就可以提供性能优化方案,有标准、有目的地进行系
统优化。
10.1.3使系统硬件和软件资源的使用达到平衡
Linux操作系统是一个开源产品,也是一个开源软件的实践和应用平台,在这个平台下
有无数的开源软件支撑,常见的有Apache、Tomcat、MySQL、PHP等。开源软件的最大理
念是自由、开放,那么Linux作为一个开源平台,最终要实现的是通过这些开源软件的支
持,以最低廉的成本,达到应用性能的最优化。但是,系统的性能问题并非是孤立的,解决
了一个性能瓶颈。可能会出现另一个性能瓶颈。所以说性能优化的最终目的是:在一定范围
内使系统的各项资源使用趋干合理并保持一定的平衡,即系统运行良好的时候恰恰就是系统
资源达到了一个平衡状态的时候。而在操作系统中,任何一项资源的过度使用都会破坏这种
平衡状态,从而导致系统响应缓慢或者负载过高。例如,CPU资源的过度使用会造成系统中
出现大量的等待进程,导致应用程序响应缓慢,而进程的大量增加又会导致系统内存资源的
增加,当物理内存耗尽时,系统就会使用虚拟内存,而虚拟内存的使用又会造成磁盘I/O的增加并加大CPU的开销。因此,系统性能的优化就是在硬件、操作系统、应用软件之闻找
到一个平衡点。
10.2 分析系统性能涉及的人员
10.2.1 Linux系统管理人员
在进行性能优化的过程中,系统管理人员承担着很重要的任务,首先,系统管理人员要
了解和掌握操作系统的当前运行状态,例如系统负载、内存状态、进程状态、CPU负荷等,
这些信息是检测和判断系统性能的基础和依据;其次,系统管理人员还要掌握系统的硬件信
息,例如磁盘I/O、CPU型号、内存大小、网卡带宽等参数信息,然后根据这些信息综合评
估系统资源的使用情况;第三,作为一名系统管理人员,还要掌握应用程序对系统资源的使
用情况,更深入的一点就是要了解应用程序的运行效率,例如是否有程序bug、内存溢出等
问题。通过对系统资源的监控,就能发现应用程序是否存在异常,如果确实是应用程序存在
问题,需要把问题立刻反映给程序开发人员,进而改进或升级程序。
性能优化本身就是一个复杂和繁琐的过程,系统管理人员只有了解了系统硬件信息、网
络信息、操作系统配置信息和应用程序信息才能有针对性地展开对服务器的性能优化,这就
要求系统管理员有充足的理论知识、丰富的实战经验以及缜密分析问题的头脑。
10.2.2系统架构设计人员
系统性能优化涉及的第二类人员就是应用程序酌架构设计人员。如果系统管理人员在经
过综合判断后,发现影响性能的是应用程序的执行效率,那么程序架构设计人员就要及时介
入,深入了解程序运行状态。首先,系统架构设计人员要跟踪了解程序的执行效率,如果执
行效率存在问题,要找出哪里出现了问题;其次,如果真的是架构设计出现了问题,那么就
要马上优化或改进系统架构,设计更好的应用系统架构。
10.2.3软件开发人员
系统性能优化最后一个环节涉及的是程序或软件开发人员。在系统管理员或架构设计人
员找到程序或结构瓶颈后,程序开发人员要马上介入进行相应的程序修改。修改程序要以程
序的执行效率为基准,改进程序的逻辑,有针对性地进行代码优化。例如,系统管理人员在
系统中发现有条SQL语句耗费大量的系统资源,抓取这条执行的SQL语句后,发现此SQL
语句的执行效率太差,是开发人员编写的代码执行效率低造成的,这就需要把这个信息反馈
给开发人员。开发人员在了解到这个问题后,可以有针对性地进行SQL优化,进而实现程序
代码的优化。
从上面这个过程可以看出,系统性能优化一般遵循的流程是:首先系统管理人员查看系
统的整体状况,主要从系统硬件、网络设备、操作系统配置、应用程序架构和程序代码5个方面进行综合判断。如果发现是系统硬件、网络设备或者操作系统配置问题,系统管理负可以根据情况自主解决;如果发现是程序结构问题,就需要提交给程序架构设计人员:如果发现是程序代码执行问题,就交给开发人员进行代码优化。这样就完成了一个系统性能优化的过程。
10.3 影响Linux性能的各种因素
10.3.1 系统硬件资源
1.CPU
CPU是操作系统稳定运行的根本,CPU的速度与性能在很大程度上决定了系统整体的
性能,因此,CPU数量越多,主频越高,服务器性能也就相对越好。但事实并非完全如此。
目前大部分CPU在同一时间内只能运行一个线程,超线程的处理器可以在同一时间运
行多个线程,因此,可以利用处理器的超线程特性提高系统性能。在Linux系统下,只有运
行SMP内核才能支持超线程,但是,安装的CPU数量越多,从超线程获得的性能方面的提
高就越少。另外,Linux内核会把多核的处理器当做多个单独的CPU来识别,例如两个4核
的CPU,在Linux系统下会被当做8个单核CPU。但是从性能角度来讲,两个4核的CPU
和8个单核的CPU并不完全等价。根据权威部门得出的测试结论,前者的整体性能要比后
者低25%—30%。
可能出现CPU瓶颈的应用有邮件服务器、动态Web服务器等。对于这类应用,要把
CPU的配置和性能放在主要位置。
2.内存
内存的大小也是影响Linux性能的一个重要的因素。内存太小,系统进程将被阻塞,应
用也将变得缓慢,甚至失去响应;内存太大,导致资源浪费。Linux系统采用了物理内存和
虚拟内存两种方式,虚拟内存虽然可以缓解物理内存的不足,但是占用过多的虚拟内存,应
用程序的性能将明显下降。要保证应用程序的高性能运行,物理内存一定要足够大:但是过
大的物理内存,会造成内存资源浪费,例如,在一个32位处理器的Linux操作系统上,超
过8GB的物理内存都将被浪费。因此,要使用更大的内存,建议安装64位的操作系统,同
时开启Linux的大内存内核支持。
由于处理器寻址范围的限制,在32位Linux操作系统上,应用程序单个进程最大只能
使用2GB的内存,这样一来,即使系统有再大的内存,应用程序也无法“享”用。解决的办
法就是使用64位处理器,安装64位操作系统。在64位操作系统下,可以满足所有应用程
序对内存的使用需求,几乎没有限制。
可能出现内存性能瓶颈的应用右打印服务器、数据库服务器、静态Web服务器等,对于
这类应用要把内存大小放在主要位置。
3.磁盘I/O性能
磁盘的I/O性能直接影响应用程序的性能,在一个有频繁读写操作的应用中,如果磁盘
I/O性能得不到满足,就会导致应用停滞。好在如今的磁盘采用了很多方法来提高I]O性能,
比如常见的磁盘RAID技术。
RAID的英文全称为:Redundant Array of Independent Disk,即独立磁盘冗余阵列,简称磁盘阵列。RAID通过将多块独立的磁盘(物理硬盘)按不同方式组合起来形成一个磁盘组(逻辑硬盘),从而提供比单个硬盘更高的I/O性能和数据冗余。
通过RAID技术组成的磁盘组,就相当于一个大硬盘,用户可以对它进行分区格式化、
建立文件系统等操作,跟单个物理硬盘一模一样,唯一不同的是RAID磁盘组的I/O性能比
单个硬盘要高很多,同时在数据的安全性方面也有很大提升。
根据磁盘组合方式的不同,RAID可以分为RAIDO、RAIDI、RAID2、RAID3、RAID4、
RAID5、RAID6、RAID7、RAIDO+l、RAIDIO等级别,常用的RAID级别有RAIDO、RAID1、RAID5、RAIDO+1。这里进行简单介绍。
RAID 0:通过把多块硬盘粘合成一个容量更大的硬盘组,提高了磁盘的性能和吞吐量。
这种方式成本低,要求至少两块磁盘,但是没有容错和数据修复功能,因而只能用在对数据
安全性要求不高的环境中。
RAID l:也就是磁盘镜像,通过把一个磁盘的数据镜像到另一个磁盘上,最大限度地
保证磁盘数据的可靠性和可修复性,具有很高的数据冗余能力,但磁盘利用串只有50%,因
而,成本最高,多用在保存重要数据的场合。
RAID5:采用了磁盘分段加奇偶校验技术,从而提高了系统的可靠性。RAID5读出效率
很高,写入效率一般,至少需要3块盘。允许一块磁盘故障,而不影响数据的可用性。
RAID0+1:把RAID0和RAID1技术结合起来就成了RAID0+1,至少需要4块硬盘。此
种方式的数据除分布在多个盘上外,每个盘都有其镜像盘,提供全冗余能力,同时允许一个
磁盘故障,而不影响数据可用性,并具有快速读/写能力。
通过了解各个RAID级别的性能,可以根据应用的不同特性,选择适合自身的RAID级
别,从而保证应用程序在磁盘方面达到最优性能。
4.网络宽带
Linux下的各种应用,一般都是基于网络的,因此网络带宽也是影响性能的一个重要因
素,低速的、不稳定的网络将导致网络应用程序的访问阻塞,而稳定、高速的网络带宽,可
以保证应用程序在网络上畅通无阻的运行。幸运的是,现在的网络一般都是千兆带宽或光纤
网络,带宽问题对应用程序性能造成的影响正在逐步降低。
10.3.2操作系统相关资源
基于操作系统的性能优化也是多方面的,可以从系统安装、系统内核参数、网络参数、
文件泵统等几个方面进行衡量,下面依次进行简单介绍。
1.系统安装优化
系统优化可以从安装操作系统开始,当安装Linux系统时,磁盘的划分、SWAP内存的
分配都直接影响以后系统的运行性能,例如,磁盘分配可以遵循应用的需求:对于读写操作
频繁而对数据安全性要求不高的应用,可以把磁盘做成RAIDO:而对于对数据安全性较高,
对读写没有特别要求的应用,可以把磁盘做成RAIDI;对于对读操作要求较高,而对写操作
无特殊要求,并要保证数据安全性的应用,可以选择RAID5;对于对读写要求都很高,并且
对数据安全性要求也很高的应用,可以选择RAIDO+l。这样通过不同的应用需求设置不同的
RAID级别,在磁盘底层对系统进行优化操作。
随着内存价格的降低和内存容量的日益增大,对虚拟内存SWAP的设定,现在已经没有
了所谓虚拟内存是物理内存两倍的要求,但是SWAP的设定还是不能忽略,根据经验,如果
内存较小(物理内存小于4GB),一般设置SWAP交换分区大小为内存的2倍;如果物理内
存大干4GB小于16GB,可以设置SWAP大小等于或略小于物理内存即可:如果内存大小在
16GB以上,原则上可以设置SWAP为0(用free命令查看swap),但并不建议这么做,因为谩置一定大小的SWAP
还是有一定作用的。
2.内核参数优化
系统安装完成后,优化工作并没有结束,接下来还可以对系统内核参数进行优化,不过内核参数的优化要和系统中部署的应用结合起来整体考虑。例如,如果系统部署的是
Oracle数据库应用,那么就需要对系统共享内存段(kernel.shmmax、kemel.shmmni、kemel.
shmall)、系统信号量(kerncl.sem)、文件句柄(fs.file-max)等参数进行优化设置:如果部
署的是Web应用,那么就需要根据Web应用特性进行网络参数的优化,例如修改net.ipv4.
ip_local_port_range、net.ipv4.tcp_tw_reuse、net.core.somaxconn等网络内核参数。
3.文件系统优化
文件系统的优化也是系统资源优化的一个重点,在Linux下可选的文件系统有ext2、
ext3、xfs、ReiserFS。可根据不同的应用,选择不同的文件系统。
Linux标准文件系统是从VFS开始的,然后是ext,接着就是cxt2.应该说,ext2是
Linux上标准的文件系统,ext3是在ext2基础上增加日志形成的。从VFS到ext3,其设计思想没有太大变化,ext系列文件系统都是早期UNIX家族基于超级块和inode昀设计理念设计而成的。
XFS文件系统是SGI开发的一个高级日志文件系统,后来移植到了Linux系统下。XFS
通过分布处理磁盘请求、定位数据、保持Cache的一致性来提供对文件系统数据的低延迟、
高带宽的访问。因此,XFS极具伸缩性,非常健壮,具有优秀的日志记录功能、可扩展性强、
快速写入性能等优点。
ReiserFS是在Hans Reiser领导下开发出来的一款高性能的日志文件系统,它通过完全平衡树结构来管理数据B*树 海量小文件性能很好,包括文件数据、文件名及日志支持等。与ext2/ext3相比,其最大的优点是访问性能和安全性大幅提升。ReiserFS具有高效、合理利用磁盘空间,先进的日志管理机制,特有的搜寻方式,海量磁盘存储等优点。
10.3.3应用程序软件资源
应用程序的优化其实是整个优化工程的核心,如果一个应用程序存在bug.那么即使其
他方面都达到了最优状态,整个应用系统还是性能低下的。所以,对应用程序的优化是性能
优化过程的重中之重,这就对程序架构设计人员和程序开发人员提出了更高的要求。
10.4 系统性能分析标准和优化原则
性能调优的主要目的是使系统能够有效地利用各种资源,最大可能地发挥应用程序和系
统之间的性能触合,使应用高效、稳定地运行。但是,衡量系统资源利用率好坏的标准没有
一个严格的定义,针对不同的系统和应用也没有一个统一的说法,因此,这里提供的标准其
实是一个经验值,如表10-1所示。
表10-1 系统性能分析标准

其中:
口user%表示CPU处在用户模式下的时间百分比。
口sys%表示CPU处在系统模式下的时间百分比。
口iowait%表示CPU等待输入输出完成时间的百分比。
口Swap In即si,表示虚拟内存的页导入,即从SWAP DISK交换到RAM。
口Swap Out即so,表示虚拟内存的页导出,即从RAM交换到SWAP DISK。
10.5 几种典型应用对系统资源使用的特点
10.5.1 以静态内容为主的Web应用
这类应用的一个主要特点是小文件居多,并且读操作频繁.Web服务器一般为Apache
或Nginx,因为这陌个HTTP服务器对静态资源的处理非常迅速和高效。在Web访问量不大
时,可以直接对外提供服务,但是在有很大并发请求时,单一的Web服务无法支撑大量的客
户端访问,此时就需要由多台Wcb服务器组成负载集群系统。为了实现更高效的访问,在最
前端还可以搭建Cache服务器,也就是将静态资源文件缓存到操作系统内存中直接进行读操
作,因为直接从内存读取数据要比从硬盘读数据效率高很多,所以在Web前端搭建Cachc服务器可以大大提高并发访问性能。常用的Cachc轶件有Squid、Varinsh等。
Cache服务器虽然可以提高访问性能,但要求服务器有很大的内存,当系统内存充足时,
可以缓解磁盘随机读的压力:当内存过小或者内存不足时,系统就会使用虚拟内存,而虚拟
内存的使用会引起磁盘I/O的增大,当磁盘I/0增大时,CPU的开销也随之增加。
在高并发访问时,还存在另外一个问题,就是网络带宽瓶颈,如果客户端访问量很大且
带宽不够,就会阻塞网络,影响访问。因此,在构建基于Web的网络应用时,网络带宽也是
必须考虑的一个因素。
10.5.2 以动态内容为主的Web应用
这类应用的一个特点是频繁地执行写操作,例如Java、PHP、Perl、CGI等,会导致CPU资源消耗严重。因为动态程序的执行要进行编译java、解析php、读取数据库等操作,而这些操作都会
消耗CPU资源。因此,一个基于动态程序的Web应用,应该选择多个性能较高的CPU,这
将对系统整体性能的提高有很大帮助。
基于动态内容的Web应用在高并发访问时,系统执行的进程数会很多,因此要注意负载
的分配。由于过多的进程会消耗大量系统内存,如果内存不足,就会使用虚拟内存,而虚拟
内存的增加会导致磁盘写操作频繁,进而消耗CPU资源。因此要寻求一个硬件资源和软件
资源的平衡点,例如配置较大的内存和高性能的CPU,而在软件方面可通过如Memcached
之类的软件加快程序与数据库之间的访问效率。
10.5.3数据库应用
数据库应用的一个主要特点是消耗内存和磁盘I/O,而对CPU的消耗并不是很大,因此
最基本的做法就是为数据库服务器配置较大的内存和读写较快的磁盘阵列。例如,可以为数
据库服务器的磁盘选择RAID5、RAIDO+I等RAD级别。将Web Server与DB Server分离
也是优化数据库应用的一个常用做法。如果客户端用户对数据库的请求过大,还可以考虑采
取数据库昀负载均衡方案,通过软件负载均衡或硬件负载均衡的方式提高数据库访问性能。
对于数据库中过大的表,可以考虑进行拆分,也就是将一个大表拆分成多个小表,再通
过索引进行关联处理,这样可以避免查询大表造成的性能问题,因为表太大时,查询遍历全
表会造成磁盘读操作激增,进而出现读操作等待的情况。同时,数据库中查询语句复杂,大
量的where子句,order by、group by排序语句等,容易使CPU出现瓶颈。最后,当数据更新时,数据更新量大或更新频繁,也会造成磁盘写操作激增,出现写操作的瓶颈。这些也应该在程序代码中避免。
在日常应用中,还有一种方法可以显著提高数据库服务器的性能,那就是读写分离。同
时对数据库进行读和写的操作,是效率极低的一种访问方式,较好的做法是根据读、写的压
力和需求,分别建立两台结构完全相同的数据库服务器,将负责写的服务器上的数据,定时
复制给负责读的服务器,通过读写的协作提高系统整体性能。
通过缓存方式也可以提高数据库的性能,缓存是数据库或对象在内存中的临时容器,使
用缓存可大幅减少数据库的读取操作,改由内存来提供数据。比如可以在Web Server和DB
Server之间增加一层数据缓存层,在系绕内存中建立被频繁请求对象的副本,这样一来,不访问数据库也可为程序提供数据。现在应用很广泛的Memcached就是基于这个原理。
10.5.4软件下载应用
静态资源下载服务器的主要特点是带宽消耗严重,同时对存储性能要求也很高。在下载
量极高时,可以采用多台、多点服务器分流的形式分担下载负荷。在HTTP服务器方面,从
高性能和减少服务器部署的角度考虑,推荐采用Lighttpd HTTP服务器,而不是采用传统的Apache服务器,原因是Apache使用阻塞模式的I/O操作(select模型),性能相对较差,并发能力有限,
而Lighttpd使用异步I/O方式,处理资源下载的并发能力远远超过Apache。
10.5.5流媒体服务应用
流媒体主要应用在视频会议、视频点播、远程教育、在线直播等方面,这类应用主要的
性能瓶颈是网络带宽和存储系统带宽(主要是读操作)。面对海量用户,如何保障用户接收
到高清晰的、流畅的画面,如何最大限度地节省网络带宽,这些都是流煤体应用要解决的首
要问题。
对于流媒体服务器的优化,可以从存储策略、传输策略、调度策略、代理服务器缓存策
略及流媒体服务器的体系结构设计等几个方面进行考虑。在存储方面,需要对视频的编码格
式进行优化,进而节省空间,优化存储性能;在传输方面,可以采用智能流技术控制发送的
速率,最大程度地保障用户观看视频的流畅性;在调度方面,可以采用静态调度和动态调度
结合的方法:在代理服务器方面,可以采用分段缓存、动态缓存等管理策略;在流媒体体系
结构方面,可以采用内存池和线程池技术改善内存消耗和线程过多对性能造成的影响。
10.6 Linux下常见的性能分析工具
10.6.1 vmstat命令
vmstat是Virtual Meomory Statistics(虚拟内存统计)的缩写,很多Linux发行版本都默认安装了此命令工具。
利用vmstat命令可以对操作系统的内存信息、进程状态、CPU活动等进行监视,不足之处是无法对某个进程进行深入分析。
vmstat命令的语法如下:
vmstat [-v] [-n] [delay [ count]]
各个选项及参教含义如下:
口-V,表示打印出版本信息,是可选参数。
口-n,表示在周期性循环输出时,输出的头部信息仅显示一次。
口delay,表示两次输出之间的间隔时间。
口count,表示按照“delay”指定的时间间隔统计的次数,默认为l。
例如:
vmstat 3
表示每3秒更新一次输出信息,循环输出,按Ctrl+c停止输出。
vmstat3 5
表示每3秒更新一次输出信息,统计5次后停止输出。
下面是vmstat命令在某个系统中的输出结果:
[root@nodel -]# vmstat2 3 procs --------memory-----------swap--------io---- --ayatem-- 一CpU------ r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 0 162240 8304 67032 0 0 13 21 1007 23 0 1 98 0 0 0 0 0 162240 8304 67032 0 0 1 0 1010 20 0 1 100 0 0 0 0 0 162240 8304 67032 0 0 1 1 1009 18 0 1 99 0 0
上面每项输出的解释如下:
口procs
o r列表示运行和等待CPU时间片的进程数,这个值如果长期大干系统CPU的个
数,说明CPU不足,需要增加CPU。
O b列表示在等待资源的进程教,比如正在等待I/O或者内存交换等。
口memory
o swpd列表示切换到内存交换区的内存大小(以KB为单位)。如果swpd的值不为
0,或者比较大,只要si、so的值长期为O,这种情况一般不用担心,不会影响系
统性能。
我先来解释一下这三个步骤的作用: 第一步,使用free命令查看内存,这其实没有什么实际作用,就是做个前后对比; 第二步,执行sync命令,是为了确保文件系统的完整性(sync命令将所有未写的系统缓存写到磁盘中); 第三步,执行echo 3 > /proc/sys/vm/drop_caches就开始释放内存了。 这里说明一下/proc/sys/vm/drop_caches的作用: 当写入1时,释放页面缓存; 写入2时,释放目录文件和inodes; 写入3时,释放页面缓存、目录文件和inodes。 # free -m total used free shared buffers cached Mem: 996 925 71 9 187 252 -/+ buffers/cache: 484 511 Swap: 2047 400 1647

o free列表示当前空闲的物理肉存数量(以KB为单位)。
o buff列表示buffers cache的内存数量,一般对块设备的读写才需要缓冲。
o cache列表示page cached的内存数量,一般作为文件系统进行缓存,频繁访问 的文件都会被缓存。如果cache值较大,说明缓存的文件数较多,如果此时in中的bi比较小,说明文件系统效率比较好。
口swap
o si列表示由磁盘调入内存
o so列表示由内存调入磁盘
在一般情况下.SI、so的值都为0.如果si、so的值长期不为0.则表示系统内存不足,需要增加系统内存。
口io项显示磁盘读写状况
o bi列表示从块设备读人数据的总量(即读磁盘)(kb/s)。
o bo列表示写到块设备的数据总量(即写磁盘)(kb/s)。
这里设置的bi+bo参考值为1000,如果超过1000,而且wa值较大,则表示系统磁盘I/O有问题,应该考虑提高磁盘的读写性能。
口system显示采集间隔内发生的中断数。
o in列表示在某一时间间隔内观测到的每秒设备中断数。
o cs列表示每秒产生的上下文切换次数。
上面这两个值越大,由内核消耗的CPU时间越多。
口cpu项显示了CPU的使用状态,此列是关注的重点。
o us列显示了用户进程消耗的CPU时间百分比。us的值比较高时,说明用户进程
消耗的CPU时间多,但是如果长期大于50%,就需要考虑优化程序或算法。
o sy列显示了内核进程消耗的CPU时间百分比。sy的值较高时,说明内核消耗的
CPU资源很多。
根据经验.us+sy的参考值为80%,如果us+sy大干80%,说明可能存在CPU资源不足。
O id列显示了CPU处在空闲状态的时间百分比。
o wa列显示了IO等待所占用的CPU时间百分比。wa值越高,说明I/O等待越严
重。根据经验,wa的参考值为20%,如果wa超过20%,说明l/O等待严重。引
起I/O等待的原因可能是磁盘大量随机读写造成的,也可能是磁盘或者磁盘控制
器的带宽瓶颈(主要是块操作)造成的。
综上所述,在对CPU的评估中,需要重点注意procs项中r列的值和CPU项中us、sy和id列的值。
10.6.2 sar命令 -》sysstat包
sar命令很强大,是分析系统性能的重要工具之一。通过sar指令,可以全面获取系统的CPU、运行队列、磁盘I/O、分页(交换区)、内存、CPU中断、网终等性能数据。
安装
yum install -y sysstat
sar命令的语法如下:
sar [options] [-o filename] [interval [count] ]
各个选项及参数的含义如下:
口options.命令行选项,sar命令的命令行选项很多,下面只列出常用选项。
o -A,显示系统所有资源设备(CPU、内存、磁盘)的运行状况。
o -u,显示系统所有CPU在采样时间内的负载状态。
o -P,显示当前系统中指定CPU的使用情况。
o -d,显示系统所有硬盘设备在采样时间内的使用状况。
o -r,显示系统内存在采样时间内的使用状况。
o -b,显示缓冲区在采样时间内的使用情况。
o -v,显示进程、文件、节点和锁表状态。
o -n,显示网络运行状态。参数后面可跟DEV、EDEV、SOCK和FULL。DEV
显示网络接口信息,EDEV显示网络错误的统计数据,SOCK显示套接字信息,
FULL显示前三参数的所有信息。它们可以单独使用或者一起使用。
o -q,显示了运行队列的大小,它与系统当时的平均负载相同。
o -R.显示进程在采样时间内的活动情况。
o -y,显示终端设备在采样时间内的活动情况。
o -w,显示系统交换活动在采样时间内的状态。
o -o filename,表示将命令结果以二进制格式存放在文件中,filentune是文件名。
o interval,表示采样间隔时间,是必须有的参数。
o count,表示采样次数,是可选参数,默认值是l。
例如,要查看系统CPU的整体负载状况,每3秒统计一次,统计5次,可以使用以下
组合:
sar—u 3 5
系统的CPU计数是从O开始的,如果要查看第二个CPU的运行负载,使用下面组合:
sar—p 1 3 5
要查看系统磁盘的读写性能,使用以下组合:
sar-d 3 5
同理,查看系统内存使用情况、网络运行状态,可以分别使用下面的命令:
sar-r 5 2 sar—n DEV 5 3
下面是sar命令对某个系统的CPU统计输出:
[root@webserver -] # sar -u 3 5 Linux 2.6.9-42.ELsmp( webserver) 11:41:24 AM CPU %user %nice %system %iowait %steal %idle 11:41:27 AM all 0.88 0.00 0.29 0.00 0.00 98.83 11:41:30 AM all 0.13 0.00 0.17 0.21 0.00 99.50 11:41:33 AM all 0.04 0.00 0.04 0.00 0.00 99.92 11:41:36 AM all 0.29 0.00 0.13 0.00 0.00 99.58 11:41:39 AM all 0.38 0.00 0.17 0.04 0.00 99.41 Average: all 0.34 0.00 0.16 0.05 0.00 99.45
上面每项输出的解释如下:
口%user列显示了用户进程消耗的CPU时间百分比。
口%nice列显示了运行正常进程所消耗的CPU时间百分比。
口%system列显示了系统进程消耗的CPU时间百分比。
口%iowait列显示了I/O等待所占用的CPU时间百分比。
口%steal列显示了在内存相对紧张的环境下pagein强制对不同的页面进行的stcal操作。
口%idle列显示了CPU处在空闲状态的时间百分比。
这个输出是对系统整体CPU使用状况的统计,每项的输出都非常直观,并且最后一行Average是个汇总行,是上面统计信息的平均值。
需要注意的一点是,第一行的统计信息中包含了sar本身的统计消耗,所以%user列的值会偏高一点,不过,这不会对统计结果产生太大影响。
在一个多CPU的系统中,如果程序使用了单线程,会出现这么一个现象.CPU的整体
使用率不高,但是系统应用却响应缓慢。单线程只使用一个CPU,导致这个CPU占用率为
100%,无法处理其他请求,而其他的CPU却闲置,这就导致了整体CPU使用率不高而应用缓慢现象的发生。
针对这个问题,可以分开查询系统的每个CPU,统计每个CPU的使用情况。
[rootOwebaerver -] # sar -P 0 3 5 Linux 2.6.9-42.ELsmp (webaerver) 11/29/2008 _i686_ (8 CPU) 06:29:33 PM CPU %user %nice %system %iowait %steal %idle 06:29:36 PM O 3.00 0.00 0.33 0.00 0.00 96.67 06:29:39 PM O 0.67 0.00 0.33 0.00 0.00 99.00 06:29:42 PM O 0.00 0.00 0.33 0.00 0.00 99.67 06:29:45 PM O 0.67 0.00 0.33 0.00 0.00 99.00 06:29:48 PM 0 1.00 0.00 0.33 0.33 0.00 98.34 Average : 0 1.07 0.00 0.33 0.07 0.00 98.53
这个输出是对系统的第一个CPU的信息统计,需要注意的是,sar中对CPU的计数是从
0开始的,因此,“sar-P 0 3 5”表示对系统的第一个CPU进行信息统计,“sar-P 4 3 5”则表示对系统的第5个CPU进行统计。依此类推,可以看出,上面的系统有8个CPU。
10.6.3 iostat命令 -》也是sysstat包 (pidstat、sar、iostat、tapestat、mpstat、cifsiostat)
${PREFIX}/lib/sa/sadc
${PREFIX}/lib/sa/sa1
${PREFIX}/lib/sa/sa2
${PREFIX}/bin/sar
${PREFIX}/bin/sadf
${PREFIX}/bin/iostat
${PREFIX}/bin/tapestat
${PREFIX}/bin/mpstat
${PREFIX}/bin/pidstat
${PREFIX}/bin/cifsiostat
${PREFIX}(/share)/man/man8/sadc.8
${PREFIX}(/share)/man/man8/sa1.8
${PREFIX}(/share)/man/man8/sa2.8
${PREFIX}(/share)/man/man1/sar.1
${PREFIX}(/share)/man/man1/sadf.1
${PREFIX}(/share)/man/man1/iostat.1
${PREFIX}(/share)/man/man1/tapestat.1
${PREFIX}(/share)/man/man1/mpstat.1
${PREFIX}(/share)/man/man1/pidstat.1
${PREFIX}(/share)/man/man1/cifsiostat.1
${PREFIX}/share/locale/*/LC_MESSAGES/sysstat.mo
${PREFIX}/share/doc/sysstat-x.y.z/*
/var/log/sa
${INIT_DIR}/sysstat
/lib/systemd/system/sysstat.service if OS uses systemd
/lib/systemd/system/sysstat-collect.service if OS uses systemd
/lib/systemd/system/sysstat-collect.timer if OS uses systemd
/lib/systemd/system/sysstat-summary.service if OS uses systemd
/lib/systemd/system/sysstat-summary.timer if OS uses systemd
/etc/sysconfig/sysstat
/etc/sysconfig/sysstat.ioconf
/etc/cron.d/sysstat
/etc/rc.d/rc.sysstat (depending on your distro)
${RC_DIR}/rc2.d/S03sysstat
${RC_DIR}/rc3.d/S03sysstat
${RC_DIR}/rc5.d/S03sysstat
iostat主页:http://sebastien.godard.pagesperso-orange.fr/man_iostat.html
iostat是I/O statistics(输入/输出统计)的缩写,主要的功能是对系统的磁盘I/O操作进行监视。它的输出主要显示磁盘读写操作的统计信息,同时给出CPU的使用情况。同vmstat -样.iostat也不能对某个进程进行深入分析,仅对系统的整体情况进行分析。
iostat -般不随系统安装,要使用iostat工具,需要在系统上安装一个Sysstat的工具包。Sysstat是一个开源软件,官方网址http://pagesperso-orange.fr/sebastien.godard,可以选择源代码包或rpm包的方式安装。
安装
yum install -y sysstat
安装完毕,系统会多出3个命令:iostat、sar和mpstat,然后就可以直接在系统下运行iostat命令了。
iostat命令的语法如下:
iostat [-c|-d] [一k] [—t] [一x[device] ] [interval [count] ]
各个选项及参数含义如下:
口不带参数的iostat命令将会输出CPU和每个分区的输出/输出的统计信息
口-c.显示CPU的使用情况。
口-d,显示磁盘磁盘的所有分区的使用情况。
口-k,每秒以KB为单位显示数据。
口-N,输出LVM的统计信息 iostat -N
口-p,仅输出列出的磁盘的输入/输出统计信息 iostat -p sda
口-V,输出iostat的版本信息
口-t,打印出统计信息开始执行的时间。
口-x device.指定要缆计的磁盘设备名称,默认为所有的磁盘设备。
口interval,指定两次统计间隔的时间。
口count.按照“interval”指定的时间间隔统计的次数。
看下面的一个输出:
[root@webserver-]# iostat -c Linux 2.6.9-42.ELsmp (webserver) 11/29/2008 _i686_ (8 CPU) avg - cpu: %user %nice %system %iowait %steal %idle 2.52 0.00 0.30 0.24 0.00 96.96
在这里,使用了“-c”参数,只显示系统CPU的统计信息,输出中每项代表的含义与
sar命令的输出项完全相同。
下面通过“iostat -d”命令组合来查看系统磁盘的使用状况:
[root@webserver -] # iostat -d 2 3 Linux2.6.9-42.ELsmp (webserver) 12/01/2008 _i686_ (8 CPU) Device: tps Blk_read/s Blk_*rrtn/s Blk_read Blk_wrtn sda l. 87 2.58 114 . 12 6479462 286537372 Device: tps Blk_read/s Blk_*rrtn/s Blk_read Blk_wrtn sda o.oo o.oo o.oo o o Device: tps Blk_read/s Blk_Wr-tri/s Blk read Blk_wrtn sda l.00 0.00 12.00 0 24
上面每项输出的解释如下:
口tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。"一次传输"意思是"一次I/O请求"。多个逻辑请求可能会被合并为"一次I/O请求"。"一次传输"请求的大小是未知的。
口Blk_read/s表示每秒读取的数据块数。
口Blk_wrtn/s表示每秒写入的数据块数。
口Blk_read表示读取的所有块数。
口Blk_wrtn表示写入的所有块敛。
这里需要注意的一点是,上面输出的第一项是系统从启动到统计时的所有传输信息,第
二次输出的数据才代表在检测的时间段内系统的传输值。
可以通过Blk一read/s和Blk wrtn/s的值对磁盘的读写性能有一个基本的了解:如果Blk_wrtn/s值很大,表示磁盘的写操作很频繁,可以考虑优化磁盘或优化程序;如果Blk_ read/s值很大,表示磁盘的读操作很多,可以将读取的数据放入内存中进行操作。这两个选项的值没有一个固定的大小,根据系统应用的不同,会有不同的值。但是有一个规则还是可以遵循的:长期的、超大的数据读写,肯定是不正常的,这种情况一定会影响系统性能。
“iostat -x”组合还提供了对每个磁盘的单独统计,如果不指定磁盘,默认是对所有磁盘进行统计。例如下画这个输出:
[root@webserver -] # iostat -x /dev/sda 2 3 Linux 2.6.9-42.ELsmp (webserver) 12/01/2008 _i686_ (8 CPU) avg - cpu: %user %nice %system %iowait %steal %idle 2.45 0.00 0.30 0.24 0.00 97.03 Device:rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.01 12.48 0.10 l.78 2.58 114.03 62.33 0.07 38.39 1.30 0.24 avg - cpu: %user %nice %system %iowait %steal %idle 3.97 0.00 1.83 819 0.00 86 14 Device:rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util sda 0.00 195.00 0.00 18.00 0.00 1704.00 94.67 0.04 2.50 0.11 0.20 avg - cpu: %user %nice %system %iowait %steal %idle 4.04 0.00 1.83 8.01 0.00 86*18 Device:rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %utilsda sda 0.00 4.50 0.00 7.00 0.o0 92.00 13.14 0.OI 0.79 0.14 0.10
这个输出基本与“sar -d”相同。需要说明以下几个选项的含义:
口rrqm/s表示每秒进行合并的读操作数目。
口wrqm/s表示每秒进行合并的写操作数目。
口r/s表示每秒完成读I/O设备的次数。
口w/s表示每秒完成写I/O设备的次数。
口rsec/s表示每秒读取的扇区数。
口wsec/s表示每秒写入的扇区数。
与时俱进:iostat核心变化解读
http://mp.weixin.qq.com/s?__biz=MzI4NTA1MDEwNg==&mid=402833297&idx=1&sn=67734a59612f2377d20e651a9317bfb4&scene=4#wechat_redirect
近些年,存储技术飞速发展,有些OS命令的输出结果如果用老的思路去分析,就很容易进入误区。本文不是一篇iostat的科普文,我将深入解析的是大家使用iostat时常遇的问题。iostat 是sysstat工具包中重要的一员,而sysstat工具包在各类Linux操作系统中都适用,所以本文具有一定的普适性。
本文核心内容是,iostat实时看到的util%和svctm值只适用于传统硬盘时代,现在已不可取,需重新解读。
目录
通过SSD盘压测,解读util%的差异
Iostat命令核心条目解读
核心问题阐述及解释
正确解读iostat命令的方法
通过SSD盘压测,解读util%的差异
压测采用同一块SSD盘,SSD盘分配的盘符为sdb1,请注意两次压测的不同之处。
第一次压测结果(A):
第一次压测命令:
第二次压测结果(B):
第二次压测命令:
从这里我们可以明显看出,%util值和svctm值是存在很大问题的,都是100%,为什么IOPS一个只达到1416,而另外一个却可以达到9342。
通过下面一步步的解释,希望可以帮助大家解除疑惑。
Iostat命令核心条目解读
在解释之前,首先简单科普一下相关条目的意思。
1、r/s + w/s:就是当前的IOPS(每秒IO数量)
2、await:请求队列中等待时间+svctm(服务时间) ,单位是毫秒,按照每次IO平均。
3、svctm:
IO平均服务时间指物理设备处理时间,不包含主机层面的排队等待时间,所以理论上应为不变值。
服务时间包括磁头寻道时间(目前平均为3毫秒)+旋转延迟时间(磁盘转速相关)+数据传输时间(简单计算时可忽略不计)
旋转延迟时间一般以旋转一周时间的1/2表示。
7200转的为 60/7200/2 =0.00416666..秒=4.17毫秒
15000转为 60/15000/2=0.002秒=2毫秒
4、%util:设备使用率,越接近100,表示压力越大。
核心问题阐述及解释
通过之前两次压测结果,我们初步得到以下两点:
1、%util达到100%并不能表示压力完全繁忙。
2、svctm理应为一个不变的物理执行时间,却发生了变化,这到底为什么?
1
为什么%util值不再代表正确繁忙度?
之前有一个错误观点,认为%util达到100%磁盘就已经完全繁忙了,其实并不是。
机械硬盘时代(比如15000转的盘),在物理层面是串行的,一个时间只能干一个活。虽然有各种级别的concurrency,但并不是真正的并行。
SSD,RAID 则不同。他们可以真正在物理层面上并行执行多个IO。可以同时物理执行多个IO。
%util的计算 有一个简单的算法:
concurrency = (r/s + w/s) * (svctm / 1000)
%util = concurrency * 100%
然而这个concurrency 是个伪命题,因为svctm也是通过计算而来的,无论怎样压,算出来的concurrency都是1左右,那么自然util% 乘以出来就是100%
举例说明:
一个快递员的繁忙程度(uti%)是看这个快递员在一定时间内,真正用于工作的时间是多少。
统计时间为10分钟,如果10分钟内快递员一口水都没喝,都在跑来跑去地忙活。那么我们可以认定繁忙率是100%
这就是util%的计算方法。这种方法对于单块机械磁盘(串行IO)没有任何问题。
技术在进步,出现了SSD以及RAID后,我们就可以并行的执行IO。
在刚刚的例子中,这个快递员变成了漩涡鸣人,会分身术,它可以分出15个分身,一起出去送快递。
但原本的算法,只盯着漩涡鸣人本身,10分钟内跑来跑去,就认为他100%繁忙。
其实他真正的百分百繁忙时,应该是本身和15个分身,总计16个漩涡鸣人全部跑来跑去送快递。
在快递员会分身术后,util%算法便有了局限性。
看了这个例子,大家应该知道通过查看%util来确认压力大小已经非常不可取了。
而且在sysstat网站的最新文档中也已经注明: But for devices serving requests in parallel, such as RAID arrays and modern SSDs, this number does not reflect their performance limits. (文档地址:http://sebastien.godard.pagesperso-orange.fr/man_iostat.html)
2
为什么svctm值会发生变化?
上面解释%util就已经说到了,因为svctm是被计算出来的。而这个算法对于非单块机械盘(RAID,SSD)并不适用。
这一点在sysstat最新文档中已经注明。可以另外参考:http://www.xaprb.com/blog/2010/09/06/beware-of-svctm-in-linuxs-iostat/
正确解读iostat命令的方法
1
我们怎样获得真正的serviice time(svctm)?
这里给大家提供一个得到真正svctm的办法。
我们可以通过fio等压测工具,通过设置为同步IO,仅设置一个线程,io_depth也设置为1,压测出来的就是真正的service time(svctm),如果结果1
2
我们怎样获得某磁盘或lun的io最大并行度,如何获得真正的util%使用率?
我们继续看算出util%的公式是什么:
concurrency = (r/s + w/s) * (svctm / 1000)
%util = concurrency * 100%
这个公式的前提是svctm是个不变的固定物理处理时间。但是我们可以从上面的两次压测结果看出其时间也是计算出来,随着iops增加,svctm相应减少。自然该公式无论如何算都是100%。
我们首先带入第二次压测结果
concurrency = (9342 + 0) * (0.11 / 1000)
concurrency = 1.02762
第二次util%还是显示100%,这是根据公式推出的答案,但是此结果是错误的。
我想到一个办法,我们将svctm带入成一个常量,即我们之前第一次压测出来的真正物理处理时间。结果如下:
concurrency = (9342+0) * (0.61 / 1000) =5.63762
concurrency = 5.63762
util% = 563.762%
我们可以通过写小工具,调用iostat -x的结果,并且将实时svctm替换为事先压测好的真实svctm(实际物理处理时间),这样就可以算出真实的util%时间
3
算出真实的最大并行度有什么用?
那么现在,如果我们不写工具,怎么根据现有的iostat值,加上之前的压测成果,判断是否繁忙呢?
现在已知util% ,svctm 都不准确。我们这里应该参考avgqu-sz。
avgqu-sz:超过处理能力的请求数目,待处理的 I/O 请求,当请求持续超出磁盘处理能力,该值将增加。
我们通过实际经验得到,当该值持续超过读写能力的1.5倍时,就表示磁盘十分繁忙。
网上的一些文章中会写到,如果该值超过2那么可以认定磁盘繁忙,其实这是一种过时的理论。
这里的2,也是基于单块机械硬盘的IO能力得出的经验结论。我们之前说过,单块机械硬盘为串行化IO,物理层面同时只能有一个IO在处理(即处理能力为1)。
那么这里的等待处理为2,是对应于磁盘处理能力为1。
那么当RAIDs 或者 SSD等并行方式,如我们压测的磁盘通过上面带入正确值的公式,我们可以实现并行度为5.63,根据之前理论,应该是超过5.63的两倍,如11.26,而不再是一个固定的值2。是否为2在当前情况已经无法判断是否繁忙。
我们这里通过压测得知,在ssd或raid情况下,等待基本不可能达到读写能力的两倍,1.5倍基本就代表非常繁忙, 而1倍的时候就需要注意了。
这里我们看第二个压测结果的qvgqu-sz值为9.21。
压测满时的等待处理io值为9.21,并行度为5.63。
9.21/5.63=1.63
从值看出,在压满的情况下,avgqu-sz为并行度的1.6倍左右。
我们可以得出结论:在事先有压测结果,知道并行度的情况下,我们可以通过查看avgqu-sz是否为并行度的1.5倍来判断该磁盘是否繁忙。
还有一个更简单主观的识别方法,即当svctm和await时间相差过大(await>>svctm)时,就可判断系统层面已经排队时间过高了,此时系统IO压力很大,要引起注意了。
但是该方法只适合经验派使用,因为它无法给出一个精准的值作为参考,也无法作为问题的发现依据写入文档。
如果你还有什么疑惑,可以将问题写在评论中,我们可以一起探讨分析。
作者介绍:代海鹏
新炬网络资深数据库工程师。
5年+Oracle维护经验,曾为中国人寿、中国移动、国家电网等大型企业提供数据库技术支持服务。
擅长数据库性能优化、故障诊断。
10.6.4 free命令
free是监控Linux内存使用状况最常用的指令。看下面这一个输出:
[root@webserver-]#free—m total used free shared buffers cached Mem: 8111 7185 925 0 243 6299 -/+buffers/cache:643 7468 SWap: 8189 0 8189
“free -m”表示查看以M为单位的内存使用情况,在这个输出中,重点关注的应该
是frce列与cached列的输出值。由输出可知,此系统共有8GB内存,系统空闲内存还有
925MB.其中,Buffer Cache占用了243MB,Page Cache占用了6299MB。由此可知,系
统缓存了很多的文件和目录,而对于应用程序来说,可以使用的内存还有7468MB.当然这
7468MB包含了Buffer Cache和Page Cache的值。从swap项可以看出,交换分区还未使用,
所以从应用的角度来说,此系统的内存资源还非常充足。
一般有这样一个经验公式:当应用程序可用内存/系统物理内存>70%时,表示系统内
存资源非常充足,不影响系统性能:当应用程序可用内存/系统物理内存<20%时,表示系
统内存资源紧缺,需要增加系统内存:当20%<应用程序可用内存/系统物理内存<70%时,表示系统内存资源基本能满足应用需求,暂时不影响系统性能。
free命令还可以适时监控内存的使用状况,使用“.s”参数可以在指定的时间段内不间断地监控内存的使用情况。例如下面这个输出:
[root@webeerver -] # free -b -s 5 total used free shared buffers cached Mem : 8505901056 7528706048 977195008 0 260112384 6601158656 -/+buffera/cache : 667435008 7838466048 Swap : 858714 9312 163840 8586985472 total used free shared buffers cached Mem: 8505901056 7526936576 978964480 0 260128768 6601142272 -/+ buffers/cache : 665665536 7840235520 Swap : 858714 9312 163840 8586985472 total used free shared buffers cached Mem : 8505901056 7523987456 981913600 -/+ buffers/cache : 662716416 7843184640 Swap : 8587149312 163840 8586985472
其中,“-b”表示以千字节(也就是1024字节)为单位来显示内存使用情况。
10.6.5 uptime命令
uptIme是监控系统性能最常用的一个命令,主要用来统计系统当前的运行状况。输出的信息依次为:系统现在的时间,系统从上次开机到现在运行了多长时间,系统目前有多少登录用户,系统在1分钟内、5分钟内、15分钟内的平均负载。看下面的一个输出:
[root@webaerver -] # uptime 18:52:11 up 27 days, 19:44, 2 uaers, load average: 0.12, 0.08, 0.08 ,,上两位数就要注意了
这里需要注意load average这个输出值,它的3个值的大小一般不能大干系统CPU的个数。例如,本输出中系统有8个CPU.如果Ioad average的3个值长期大干8时,说明CPU很繁忙,负载很高,可能会影响系统性能;如果偶尔大干8,倒不用担心,一般不会影响系统性能。相反,如果load average酌输出值小于CPU的个数,则表示CPU还有空闲的时间片,比如本例的输出显示.CPU是非常空闲的。
10.6.6 netstat命令
netstat命令用于显示本机网络连接、运行端口、路由表等信息。其语法如下:
Netstat[选项]
该命令的选项说明如表10-2所示。
表10-2 netstat命令的选项说明
选项 含 义 -a 显示本机的所有连接和监听端口 -n 以网络IP地址的形式显示当前蠢立的有效连接和端口 -r 显示路由表信息 -s 显示按协议的统计信息.默认将显示IP、IPv6、ICMP、ICMPv6、 TCP、TCPv6、UDP和UDPv6的统计信息 /etc/services 文件 -v 显示当前的有效连接,与“-n”选项类似 -t 显示所有的TCP协议连接情况 -u 显示所有的UDP协议连接情况 -c<秒数> 后面的秒致表示每隔几秒就刷新显示一次 -i 显示自动配置接口的状态 -l 仅显示连接状态为“LISTEN”的服务的网络状态 -p 显示连接对应的PID与程序名
“netstat—i”命令组合可以显示网络接口的详细信息。看下面的输出:
[root@webeerver -] # netstat -i Keniel Interface table Iface rau Met RX-OK RX-ERR RX-mP RX-OVR TX-OK TX-ERR TX-DRP TX-CrVR Flg eth0 1500 0 1313129253 0 0 0 1320686497 0 0 0 BMRU ethl 1500 0 494902025 0 0 0 292358810 0 0 0 EMRU l0 16436 0 41901601 0 0 0 41901601 0 0 0 LRU
上面每项输出的解释如下:
口Iface表示网络设备的接口名称。
口MTU表示最大传输单元,单位为字节。
口RX-OK/TX-OK表示已经准确无误地接收/发送了多少数据包。
口RX-ERR/TX-ERR表示接收/发送数据包时产生了多少错误。
口RX-DRP/TX-DRP表示接收/发送数据包时丢弃了多少数据包。
口RX-OVR/TX-OVR表示由于误差而遗失了多少数据包。
口Flg表示接口标记,其中:
口L表示该接口是个回环设备。
口B表示设置了广播地址。
口M表示接收所有数据包。
口R表示接口正在运行。
口U表示接口处于活动状态。
口O表示在该接口上禁用arp。
口P表示一个点到点的连接。
在正常情况下.RX-ERR/TX-ERR、RX-DRP/TX-DRP和RX-OVR/TX-OVR的值都应该为0,如果这几个选项的值不为0.并且很大,那么网络质量肯定有问题,网络传输性能也一定会下降。
当网络传输存在问题时,可以检测网卡设备是否存在故障,如果可能的话,应升级为
千兆网卡或光纤网络。还可以检查网络部署环境是否合理。
在网络不通或网络异常时,首先想到的就是检查系统的路由表信息。“netstat-r”的输出结果与route -n命令的输出完全相同。看下面的一个实例:
[root@webaerver -] # netatat -r Kernel IP routing table Deatination Gateway Genmask Flaga MSS Window irtt Iface 10.10.1-0 * 255.255.255.0 U 0 0 0 eth0 192.168.200.O * 255.255.255.0 U 0 0 0 eth1 169.254 .0.0 * 255.255.0.0 U 0 0 0 eth1 default 10.10.1.254 0 .O.O.O UG 0 0 0 eth0
关于输出中每项的具体含义显示得很明确,这里不再多讲。这里我们重点关注的是
default行对应的值,表示系统的默认路由,对应的网络接口为eth0。
10.6.7 top命令
top命令提供了实时耐系统处理器状态的监控,能够实时显示系统中各个进程的资源占
用状况。该命令可以按照CPU的使用、内存的使用和执行时间对系统任务进程进行排序显
示。同时top命令还可以通过交互式命令进行设定显示。通过top命令可以查看即时活跃的
进程,类似干Windows的任务管理器。
top命令的语法如下:
Top[选项]
top的选项很多,其常用的选项如表10-3所示。
表10-3 top的常用选项说明 选项 含 义 -d 指定每两次屏幕信息刷新之间的时间间隔 -I 不显示闲置或僵死的进程信息 -c 显示进程的整个命令路径,而不是只显示命令名称 -s 使top命令在安全模式下运行,此时top的交互指令被取消,避免潜在危险 -b 分屏显示输出信息,结合“一n”选项可以将屏幕信息输出到文档 -n top输出信息更新的次数,完成后将退出top命令
top命令中除了以上这些选项外,还有很多交互式命令,这些交互命令就是在top命令执行过程中使用的一些命令。这些命令都是单个字母,从应用角度来讲,熟悉这些交互式命令至关重要。
表10-4交互式命令及其代表的具体含义
表10-4交互式命令及其代表的具体含义 交互命令 表示含义 h或? 显示帮助信息,给出交互式命令的一些总结或说明总结 K 终止一个进程,系统将提示用户输入一个需要终止进程的PID I 忽略闲置进程和噩死进程.这是一个开关式命令 s 改变top输出信息两次剐新之间的时间,系统将提示输入新的时间,单 位是秒,如果是小数,就换算成毫秒,如果输入O,系统输出将不断被刷 新,默认刷新时间是5秒.需要注意的是,如果设置的时间太小,可能会 引起系统不断地刷新,无法看清输出的显示情况,而且系统负载也会加大 o或者O 改变cop输出信息中显示项目的顺序。按小写的a-z键可以将相应的 列向右移动,而按大写的A—Z键可以将相应的列向左移动,最后接回车键 确定 f或者F 从当前显示列表中添加或删除项目.按f键之后会显示列的列表,按a--z 之间的任意键即可显示或隐蠢对应的列,最后接回车键确定 m 切换显示内存信息 t 切换显示进程和CPU状态信息 r 重新设置一个进程的优先级,系统提示用户输入需要改变的进程PID 以及需要设置的进程优先级值.输入一个正值将使优先级降低,反之刚使 该进程拥有更高的优先权.默认值是10 l 切换显示平均负载和启动时间信息 q 退出top显示 c 切换显示完整命令行和命令名称信息 M 根据驻留内存大小进行排序输出 P 根据CPU使用百分比大小进行排序输出 T 根据时间/累计时间进行排序输出 S 切换到累计模式 W 将当前top设置写入~/.toprc文件中
下面通过一个具体的例子来解释top命令中每个选项的含义。
查看当前系统活动的进程,如图10-1所示。
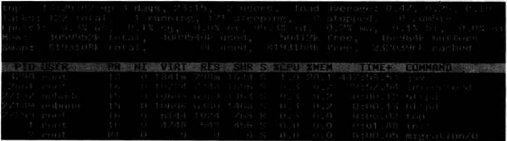
图10-1 查看当前系统活动的进程
从图10-1中可以看到,top的输出分为两个部分:统计信息区和进程信息区,即前5行显示为统计信息区,后面几行的为进程信息区。下面分别介绍。
(l)统计信息区
第一行为任务队列信息,含义如下:
口13:29:02,表示当前系统时间。
口up 3 days,23:15.表示系统已经启动了3天23小时15分钟。
口2 users,当前登录系统的用户数。
口load average: 0.47,0.20, 0.10,表示系统平均负载,3个数值分别表示1,上两位数就要注意了
分钟、5分钟、15分钟前到现在的系统平均负载值。
第二、三两行为进程和CPU信息,具体含义如下:
口Tasks: 122 total,进程的总数。
口l running,正在运行的进程数。
口121 sleeping.处于休眠的进程数。
口0 stopped.停止的进程数。
口O zombie,僵死的进程数。
口Cpu(s): 0.3% us,表示用户进程占用CPU的百分比。
口0.1% sy,系统进程占用CPU的百分比。
口0.0% ni,用户进程空间内改变过优先级的进程占用CPU的百分比。
口99.3% id,空闲CPU占用的百分比。
口0.2% wa:等待输入输出的进程占用CPU的百分比。
最后两行输出的是内存信息,具体含义如下:
口Mem: 4059952k total.系统的物理内存大小。
口4009540k used,已经使用的物理内存大小。
口50412k free,目前空余内存大小。
口468964k buffers,用作内核缓冲区的内存大小。
口Swap: 8193108k total,交换分区的内存大小。
口Ok used,已经使用的交换分区大小。
口8193108k free,空闲的交换分区大小。
口2320396k cached,高速缓存的大小。
(2)进程信息区
进程信息区显示了每个进程的运行状态。先来看一下每列输出的含义:
口PID,进程的id。
口USER.进程所有者的用户名。
口PR,进程优先级。
口NI: nice值,负值表示高优先级,正值表示低优先级。
口VIRT,进程使用的虚拟内存总量,单位为KB。VIRT=SWAP+RES。
口RES.进程使用的、未被换出的物理内存大小,单位为KB。RES=CODE+DATA。
口SHR,共享内存大小,单位为KB。
口S.进程状态,D表示不可中断的睡眠状态,R表示运行状态,S表示睡眠状态.T
表示跟踪/停止,Z表示僵死进程。
口%CPU,上次更新到现在的CPU时间占用百分比。
口%MEM,进程占用的物理内存百分比。
口TIME+.进程使用的CPU时间总计,单位为1/100秒。
口COMMAND,正在运行进程的命令名或命令路径。
10.7基于Web应用的性能分析及优化案例
10.7.1 基于动态内容为主的网站优化案例
1.网站运行环境说明
硬件环境:1台IBM x3850服务器,单个双核Xeon 3.OG CPU,2GB内存,3块72GB
SCSI磁盘。
操作系统:CentOS 5.4。
网站架构:Web应用是基于LAMP架构,所有服务都在一台服务器上部署。
2.性能问囊现象及处理措施
(1)现象描述
网站在上午10点左右和下午3点左右访问高峰时,网页无法打开,重启服务后,网站在一段时间内能正常服务,但过一会又变得响应缓慢,最后网页彻底无法打开。
(2)检查配置
首先检查系统资源状态,炭现服务出现故障时系统负载极高,内存基本耗尽。接着检查Apache配置文件httpd.conf,发现“MaxClients”选项值被设置为2000.并且打开了Apache的KeepAlive特性。
(3)处理措施
根据上面的检查,初步判断是Apache的“MaxClients”选项配置不当引起的,因为系统内存仅有2GB大小,而“MaxClients”选项被配置为2000,过多的用户访问进程耗尽了系统内存。
然后,修改httpd.conf配置文件的“MaxClients”选项,将此值由2000降到
1500。继续观察发现,网站还是频繁宕机,于是将“MaxClients”选项值降到1024。观察
一段时间发现,网站服务宕机时间间隔加长了,不像以前那么频繁了,但是系统负载还是很
高,网页访问速度极慢。
3.第一次分析优化
既然是由系统资源耗尽导致的网站服务失去响应,那么就深入分析系统资源的使用情
况。通过uptune、vmstat、.top、ps等命令的联合使用,得出如下结论:
(l)结论描述
系统平均负载很高,通过uptime输出的系统“load average”值都在10以上,上两位数就要注意了,而CPU
资源也消耗严重,这是造成网站响应缓慢或长时间没有响应的主要原因,而导致系统资源消
耗过高的主要因素是用户进程消耗资源严重。
(2)原因分析
通过top命令发现,每个Apacbe子进程消耗将近6~8MB左右内存,这是不正常的。
根据经验,在正常情况下每个Apache子进程消耗的内存在IMB左右。结合Apache输出日
志发现,网站首页访问频率最高,也就是说首页程序代码可能存在问题。于是检查首页的
PHP代码,发现首页的页面非常大,图片很多,并且由全动态的程序组成,这样每次用户访
问首页都要多次查询数据库,而查询数据库是个非常耗费CPU资源的过程,并且首页PHP
代码也没有相应的缓存机制,每个用户请求都要重新进行数据库查询操作,数据库查询负荷
有多高可想而知。
(3)处理措施
修政酋页PHP代码,缩减页面大小,并且对访问频繁的操作增加缓存机制,尽量减少
程序对数据库的访问。
4.第二次分析优化
通过前面简单优化,系统服务宕机现象出现次数减少很多,但是在访问高峰时网站偶尔
还会无法正常访问。这次仍然从分析系统资源使用状况人手,发现系统内存资源消耗过大,
并且磁盘I/O有等待问题,于是得出如下结论:
(1)原因分析
内存消耗过大,肯定是用户访问进程敛过多导致的,在没有优化PHP代码之前,每个
Apache子进程消耗6~8MB内存,如果设置Apache的最大用户数为1024.那么内存耗尽
是必然的.当物理内存耗尽时,虚拟内存就会启用,频繁地使用虚拟内存,肯定会出现磁盘
I/O等待问题,最终导致CPU资源耗尽。
(2)处理措施
通过上面对PHP代码的优化,每个Apache子进程消耗的内存资源基本维持在1~2MB左右,因此修改Apache配置文件htqxLconf中的“MaxClients”选项值为“600”,同时把Apache配置中的“KeepAlive”特性关闭,这样Apache进程数大量减少,基本维持在500~600之间,虽然偶尔也会使用虚拟内存,但是Web服务正常了,服务宕机问题也很少幽现了。
5.第三次分析优化
经过前两次的优化,网站基本运行正常,但是在访问高峰时偶尔还会出现站点无法访问的现象。继续进行问题分析,通过命令查看系统资源,发现仍是CPU资源耗尽导致的,但
是与前两次又有所不同。
(1)原因分析
通过观察后台日志,发现PHP程序有频繁访问数据库的操作,大量的SQL语句中有
where、order by等子句,同时,数据库查询过多,大部分都是复杂查询,一般都需要遍历全表,而大量的表没有建立索引,这样的程序代码导致MySQL数据库负荷过高,而MySQL
数据库和Apache部署在同一台服务器上,这也是导致服务器消耗CPU资源过高的原因。
(2)处理措施
优化程序中的SQL语句,增加where子句上的匹配条件,减少遍历全部的查询。同时
在where和order by子句的字段上建立索引,并且增加程序缓存机制。通过这次优化,网站运行基本处于正常状态,再也没有出现宕机的现象。
6.第四次优化分析
通过前面三次优化以后,网站在程序代码、操作系统、Apache等方面的优化空间越来越小。要避免出现服务器宕机现象,并且保证网站稳定、高效、快速的运行,可以从网站结构上进行优化,也就是将Web和数据库分离部署。可以增加一台专用的数据库服务器,单独部署MySQL数据庠。随着访问量的增加,如果前端无法满足访问请求,还可以增加多台Web
服务器,Web服务器之间进行负载均衡部署,解决前端性能瓶颈。如果在数据库端还存在读
写压力,还可以继续增加一台MySQL服务器,将MySQL进行读写分离部署。这样,一套
高性能、高可靠的网站系统就构建起来了。
10.7.2基于动态、静态内容结合的网站优化案例
1.网站运行环境说明
硬件环境:两台IBM x3850服务器,单个双核Xeon 3.OG CPU,4GB内存,3块72GB
SCSI磁盘。
操作系统:CentOS 5.4。
网站架构:Web应用是基于J2EE架构的电子商务应用,Web端应用服务器是Tomcat,
采用MySQL数据库,Web和数据库独立部署在两台服务器上。
2.性能问置现象以及处理措施
(l)现象描述
网站访问高峰时,网页无法打开,重启Java服务后,网站可以正常运行一段时间,但过一会又变得响应缓慢,最后网页彻底无法打开。
(2)检查配置
首先检查系统资源状态,发现服务出现故障时系统负载极高,CPU满负荷运行,Java进程占用了系统99%的CPU资源,但内存资源占用不大。接着检查应用服务器信息,发现只
有一个Tomcat在运行Java程序。再查看Tomcat配置文件server.xml.发现server.xml文件中的参数都是默认配置,没有进行任何优化。
(3)处理措施
server.xml文件的默认参数需要根据应用的特性进行适当的修改,例如可以修改
“connectionTimeout“、“maxKeepAliveRequests”、“maxProcessors”等几个Tomcat配置文件的参数,适当加大这几个参数值。修改参数值后,继续观察发现,网站服务宕机时间间隔加长了,不像以前那么频繁,但是Java进程消耗CPU资源还是很严重,网页访问速度极慢。
3.第一次分析优化
既然Java进程消耗CPU资源严重,那么需要查看到底是什么导致Java消耗资源严重。
通过lsof、netstat命令发现有大量的Java请求等待信息,然后查看Tomcat日志,发现有大量报错信息、日志提示和数据库连接超时,最终无法连接到数据库。同时,访问网站静态资源,也无法访问,于是得出如T结论:
(l)原因分析
Tomcat本身就是一个Java容器,是使用连接/线程模型处理业务请求的,主要用于处
理Jsp、servlet等动态应用,虽然它也能当作HTTP服务器,但是处理静态资源的效串很低,
远远比不上Apache或Nginx。从前面观察到的现象分析,可以初步判断是Tomcat无法及时
响应客户端的请求,进而导致请求队列越来越多,直到Tomcat彻底崩溃。对于一个正常的
访问请求来说,服务器接收到请求后,会把请求交给Tomcat去处理,Tomcat接着执行编译、
访问数据库等操作,然后把信息返回给客户端。客户端接收到信息后.Tomcat就关闭这个请求链接,这样一个完整的访问过程就结束了。而在高并发访问状态下,很多的请求瞬间都交给Tomcat处理,这样Tomcat还没有完成第一个请求,第二个请求就来了,接着是第三个,
等等。这样越积越多.Tomcat最终失去响应,Java进程就会处于僵死状态,资源无法释放,
这就是根本原因。
(2)处理措施 网站动静分离 静态化
要优化Tomcat性能,需要从结构上进行重构。首先,加入Apache支持,由Apache处
理静态资源,由Tomcat处理动态请求,Apache服务器和Tomcat胀务器之间使用Mod.,JK
模块进行通信。使用Mod- JK模块的好处是:它可以定义详细的资源处理规则,根据动态、
静态网站的特点,将静态资源文件全部交给Apache处理,而动态请求通过Mod—JK模块传
给Tomcat去处理。通过Apache+JK+Tomcat的整合,可以大幅度提高Tomcat应用的性能。
4.第二次分析优化
经过前面的优化措施,Java资源偶尔会增高,但是一段时间后又会自动降低,这属于正常状态。而在高并发访问情况下,Java进程有时还会出现资源上升无法下降的情况,通过查看Tomcat日志,综合分析得出如下结论:
要获得更高、更稳定的性能,单一的Tomcat应用服务器有时会无法满足需求,因此要结合Mod—JK模块运行基于Tomcat的负载均衡系统,这样前端由Apache负责用户请求的
调度,后端又多个Tomcat负责动态应用的解析操作。通过将负载均分配给多个Tomcat服务
器,网站的整体性能会有一个质的提升。
10.8本章小结
本章通过理论与实践相结合的方法,系统地讲述了Linux服务器的性能分析原则和优化
方法。首先介绍了系统性能分析的目的和意义,接着讲解了影响Linux性能的各种因素,然
后分析了常见的几种Web应用系统使用系统资源的特点。接下来详细介绍了Linux下几个常
见的性能优化分析工具的使用,最后通过两个具体的案例从整体上一步一步演示了Web应用
系统的优化过程。
系统优化是个非常大的话题,涉及的知识面广,分析过程也较复杂,这对系统优化人员
提出了非常高的要求。但是万变不离其宗,只要掌握了分析问题的步骤和思考问题的方法,
优化系统的过程也将变得十分轻松。
f