内容主要来自https://www.runoob.com/java/java-collections.html,增加了一些我自己的理解。
首先java的集合框架可以概括为一张图:
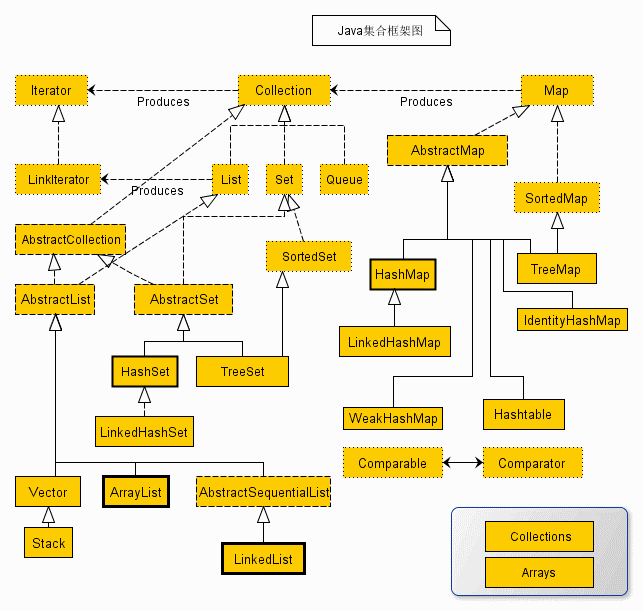
从上面的集合框架图可以看到,Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对(key-value)映射。
Collection接口又有3个子类型,List、Set和Queue,再是下面的抽象类(粗虚线),最后再是继承自抽象类的具体实现类(ArrayList、LinkedList,HashSet、LinkedHashSet、HashMap、LinkedHashMap等)下面是对接口和实现的具体解释:

注意:集合框架位于java.util包中,使用时需要导入java.util.xxx(避免使用“*”通配符!)
Collection接口:
Collection 是最基本的集合接口,一个 Collection 代表一组 Object,即 Collection 的元素, Java不提供直接继承自Collection的类,只提供继承于的子接口(如List和set)。Collection 接口存储一组不唯一,无序的对象。
List接口:
List接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。List 接口存储一组不唯一,有序(插入顺序)的对象。
Set接口:
Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。Set 接口存储一组唯一,无序的对象。
Map接口:
Map 接口存储一组键值对象,提供key(键)到value(值)的映射。
Enumeration接口:
这是一个传统的接口和定义的方法,通过它可以枚举(一次获得一个)对象集合中的元素。这个传统接口已被迭代器(iterator)取代。
Set和List的区别:
-
1. Set 接口实例存储的是无序的,不重复的数据。List 接口实例存储的是有序的,可以重复的元素。
-
2. Set检索效率低下(因为没有序号用于检索),删除和插入效率高(没有序号在删除和插入的时候不用改变元素的位置)<实现类有HashSet,TreeSet>。
-
3. List和数组类似,可以动态增长,根据实际存储的数据的长度自动增长List的长度。查找元素效率高(有序号用于检索),插入删除效率低(假如现有5个元素,我要在2号位置插入一个元素,则2,3,4号元素要依次下移一位,才能腾出位置给新元素插入,和可以直接插入的Set比效率自然会低很多) <实现类有ArrayList,LinkedList,Vector>。
同时关于Set的一些补充:
虽然说List是有序且重复的,Set是无序不重复的。但是这里有个误区,这里说的顺序有两个概念,一是按添加的顺序排列,二是按自然顺序a-z排列。Set并不是无序的,传统说的Set无序是指HashSet,它不能保证元素的添加顺序,更不能保证自然顺序,而Set的其他实现类是可以实现这两种顺序的:
保证元素添加的顺序:LinkedHashSet
保证元素自然的顺序:TreeSet
这个可以通过下面的这个例子说明:
1 public class Test { 2 public static void sAdd_print(Set<String> set){ 3 set.add("s1"); 4 set.add("s5"); 5 set.add("s3"); 6 set.add("s4"); 7 set.add("s2"); 8 set.forEach(e -> System.out.print(e + " ")); 9 System.out.println(); 10 } 11 12 public static void main(String[] args) { 13 Set<String> set = new HashSet<>(); 14 sAdd_print(set); 15 16 Set<String> set2 = new LinkedHashSet<>(); 17 sAdd_print(set2); 18 19 Set<String> set3 = new TreeSet<>(); 20 sAdd_print(set3); 21 } 22 }
三种Set,添加的顺序都是15342,而最后输出是:
s3 s4 s5 s1 s2 (第一行的元素看似无序,但似乎也是按一定的顺序排列,运行好多次,更换ide都是这个顺序,可能跟Hash有关)
s1 s5 s3 s4 s2 (按元素添加的顺序排列)
s1 s2 s3 s4 s5 (按元素自然顺序排列)