基本开发环境
·Python 3.6
·Pycharm
模块使用

网页分析

1.查看壁纸详情页内容 打开开发者工具就可以看到壁纸的地址以及壁纸的名字了
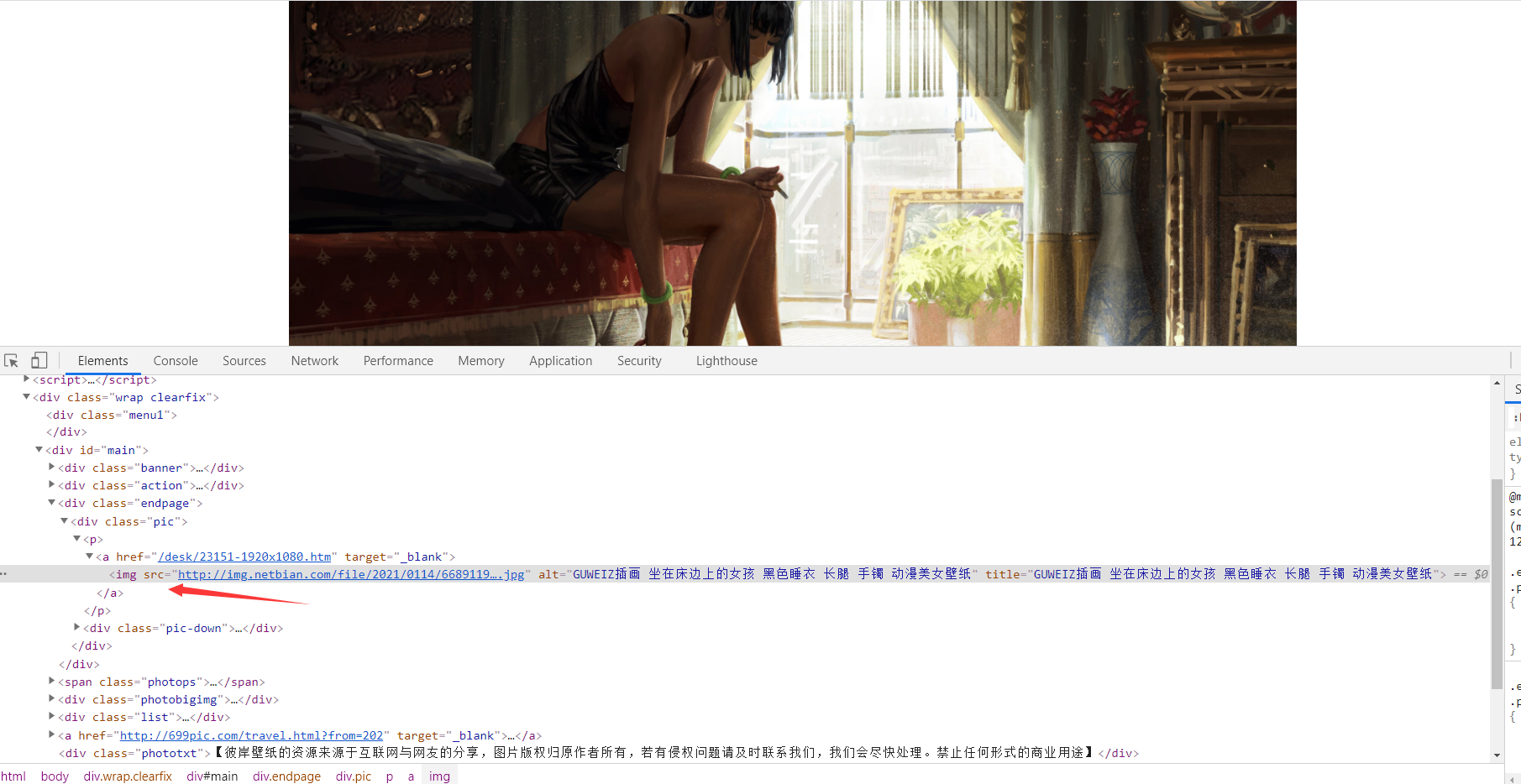
复制壁纸地址
详情页中的图片地址就是高清图片地址了
2.获取每张壁纸页的url

如上图所示,所有的壁纸详情页地址都包含在li标签中。
综上所述:
1、请求列表页,解析网页数据获取每张壁纸的详情页url,拼接url地址;
2、请求详情页,解析网页数据获取每张壁纸的图片url地址以及标题
3、请求图片url地址,保存壁纸
保存数据的时候会有一个坑:
在请求图片url地址的时候们要加上图片cokkie,如果你不加cookie,保存下来的图片是破损的,所以需要两个headers,一个是获取url地址的吗,一个是保存图片数据的。
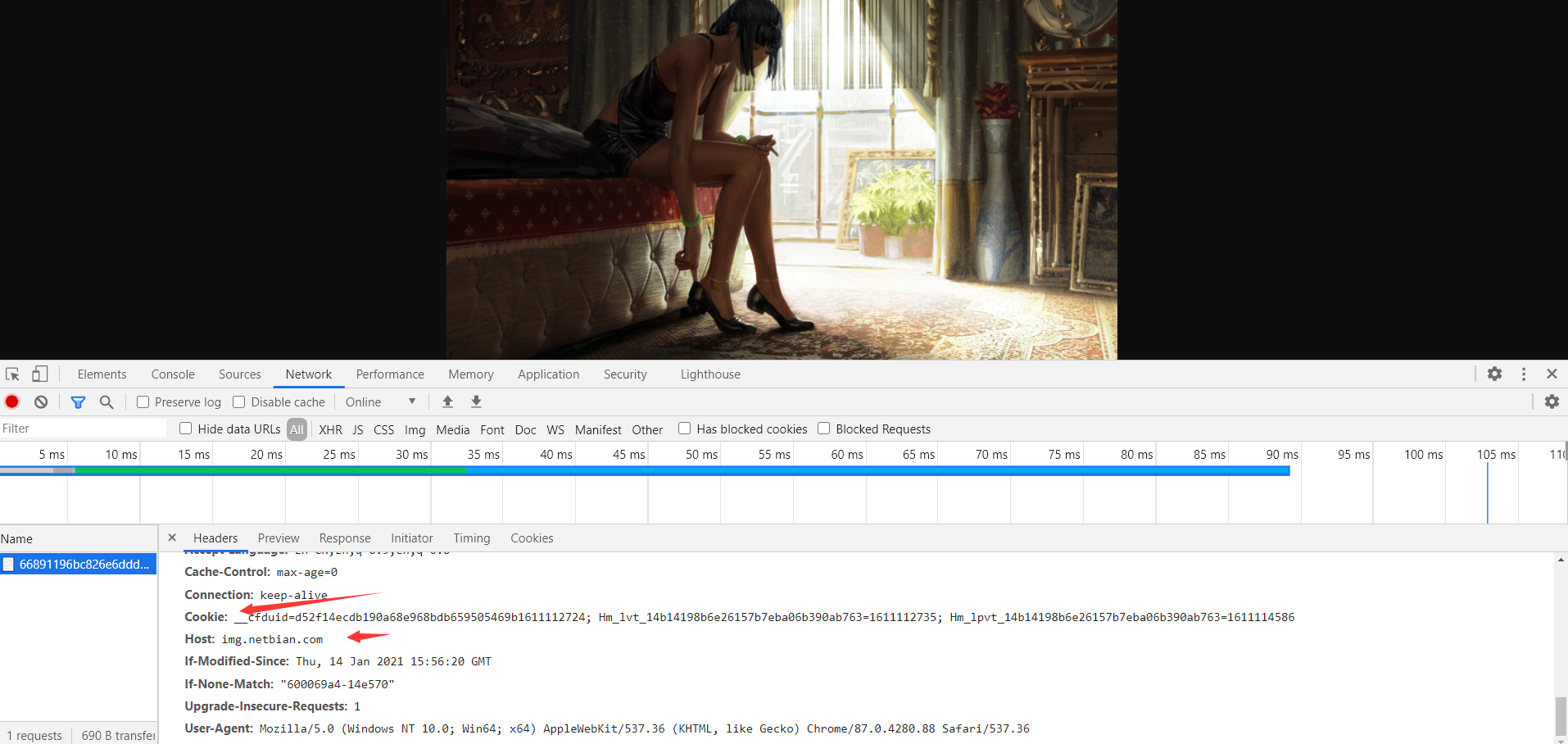

代码如下:
import requests import threding import concurrent.futures headers = { 'Cookie': '__cfduid=d06f453df5c4252eb0aac3e9280e5b0b01606983134; Hm_lvt_14b14198b6e26157b7eba06b390ab763=1606983135; xygkqecookieinforecord=%2C12-23053%2C; Hm_lpvt_14b14198b6e26157b7eba06b390ab763=1606984094', 'Host': 'www.netbian.com', 'Referer': 'http://www.netbian.com/1920x1080/index.htm', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36', } headers1 = { 'Cookie': 'Hm_lvt_14b14198b6e26157b7eba06b390ab763=1590498708; __cfduid=d7b17b08368a78ab8d8d6a42d580c62f01606985472', 'Host': 'img.netbian.com', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3823.400 QQBrowser/10.7.4307.400', } def get_response(html_url): """ 获取网页源代码 :param html_url: :return: """ response = requests.get(url=html_url, headers=headers) return response def get_response1(html_url): """ 获取网页源代码 (保存壁纸) :param html_url: :return: """ response = requests.get(url=html_url, headers=headers1) return response def get_parsing(html_data): """ 解析函数 :param html_data: :return: """ selector = parsel.Selector(html_data) return selector def save(img_url, name): """ 保存数据 :param img_url: :param name: :return: """ filename = 'img\' + name + '.jpg' img_content = get_response1(img_url).content with open(filename, mode='wb') as f: f.write(img_content) print('正在保存:', name) print(img_url) def get_img_url(page_url): """ 获取图片地址 以及 标题 :param page_url: :return: """ response = get_response(page_url) response.encoding = response.apparent_encoding selector = get_parsing(response.text) img_url = selector.css('.pic a img::attr(src)').get() name = selector.css('.pic a img::attr(title)').get() save(img_url, name) def main(url): """ 主函数 :param url: :return: """ response = get_response(url) response.encoding = response.apparent_encoding selector = get_parsing(response.text) lis = selector.css('.list ul li a::attr(href)').getall() lis.pop(2) lis.pop(2) for li in lis: page_url = 'http://www.netbian.com' + li get_img_url(page_url) if __name__ == '__main__': executor = concurrent.futures.ThreadPoolExecutor(max_workers=5) for page in range(2, 50): url = 'http://www.netbian.com/1920x1080/index_{}.htm'.format(page) executor.submit(main, url) executor.shutdown()
