美妆的第一步是人脸检测,找特征点。关于人脸检测,有很多成熟的库,我列举目前发现到的开源项目(注意软件所用的协议)。如果大家发现有漏掉的,可以发消息给我。
STASM www.milbo.users.sonic.net/stasm/
dlib http://dlib.net/
OpenFace https://cmusatyalab.github.io/openface/
SeetaFaceEngine https://github.com/seetaface/SeetaFaceEngine
Linkface https://www.linkface.cn/doc/api/v1/face_detection
Face Detection Data Set and Benchmark
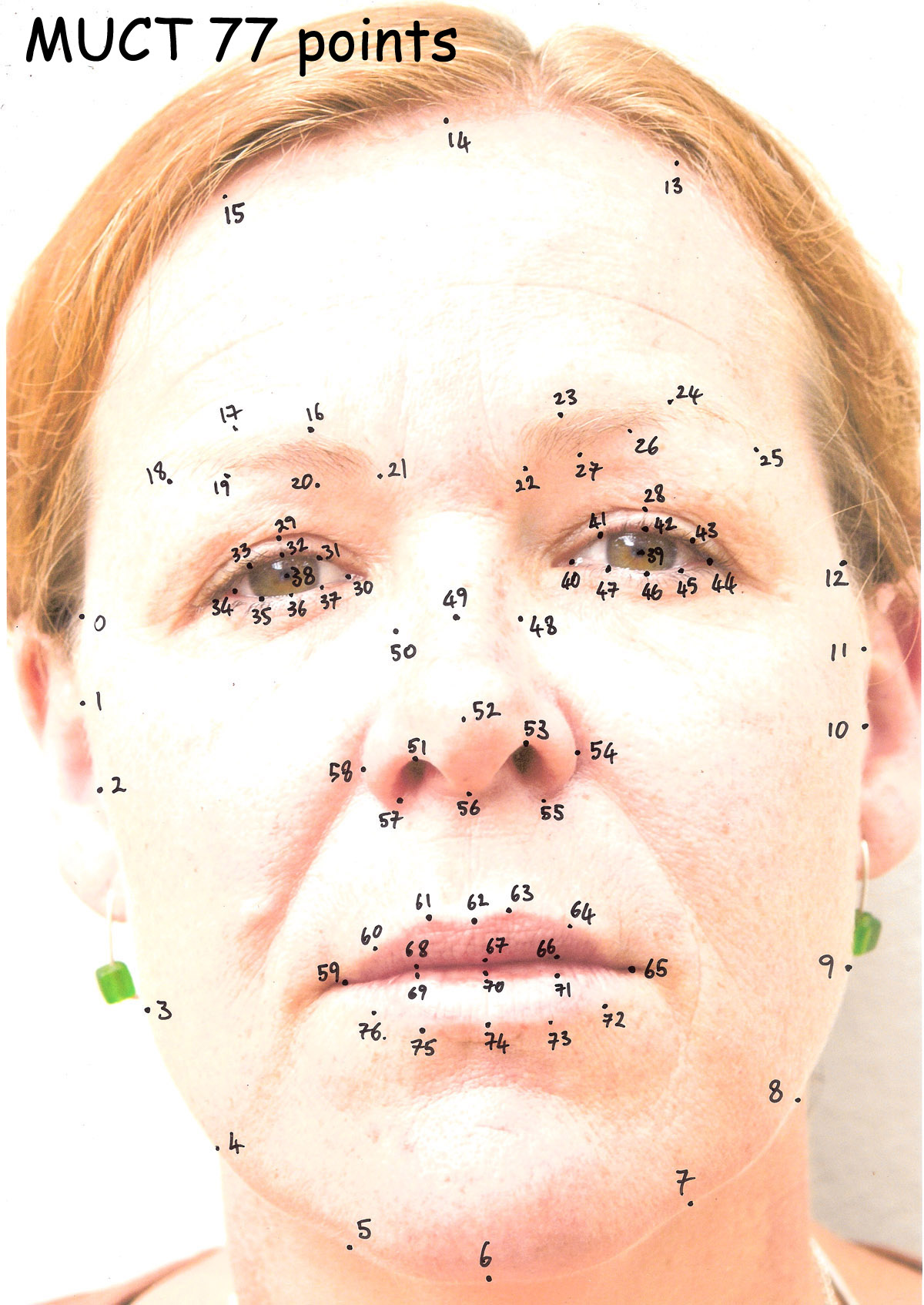
STASM 目前最新4.1.0版本,发布于2013/12/27,教之前的3.1版本而言,更快更好地拟合。STASM 采用 ASM(Active Shape Model) 训练人脸模型,采用的是BSD协议。对于正脸(可以带表情)识别的不错,检测出77个特征点。

打开 jni/stasm/stasm.h 文件,打开宏 TRACE_IMAGES,也就是 #define TRACE_IMAGES 1 ,WIN32下调试时,在 jni/build/ 目录下可以查看每一步形状的走势变化,别忘了在Release下关闭。我用 Obama 的图片制作了一张GIF。

PerfectShow 工程中,使用 Feature::detectFace() 检测单张人脸,Feature::detectFaces() 来检测多张人脸,他们分别调用了 STASM 库里面的 stasm_search_single (apps/minimal.cpp) 和 stasm_search_auto (apps/minimal2.cpp)。考虑到朋友圈最忌讳的事就是发照片只给自己化妆,却不给旁边的朋友美化的情形,所以在照片中有多个人的场景时,需要提供选取人脸分别对每个人化妆的流程。这个功能后期需要添加,暂时未完成。
STASM在额头两边缺少特征点(见下图),显得围成的脸部轮廓线不够圆滑。所以,我用旋转的方法在两边多各补了两个特征点。上图中的划线对应函数 Feature::mark(),在调试的时候有帮助,对用户而言是不可见的。用到的技术有,Catmull-Rom样条曲线(Catmull-Rom spline),德洛内三角剖分(Delaunay Triangulization),最小二乘法(Least Mean Square method)。
特征点连接起来的线段不够好,对后期眉毛、嘴巴的化妆有影响。数值分析里有讲到生成光滑曲线的几种插值方法,这里我选择了 Catmull-Rom 样条曲线,样条曲线是为了产生光滑的边缘,对应 jni/venus/opencv_utility.h 里的 catmullRomSpline() 函数。
与 Delaunay “对偶”的一个人叫 Voronoi,Delaunay 三角化与 Voronoi 图都是计算几何里面的。这种三角划分最大化最小角,让划分区域集中,避免长条三角形的出现。因为人脸特征点的相对位置一样,Delaunay 出来的三角形拓扑也几乎一样,说“几乎”是因为由于偏头动作、大笑等表情,会影响到最终的三角拓扑结构。所以不同的人脸不能共用这个结果。为了计算的统一,我将这个特征点的索引序列 const std::vector<Vec3b> Feature::triangle_indices 保存下来了。上一篇文章的图,参考论文 Digital Face Makeup by Example 的思路,从妆廊里选择一副妆容应用到用户脸上时,需要对三角化后的妆容图片每个三角形面片进行拉伸,与用户脸上的三角块一致后,就可以应用妆容了。
最小二乘法的发现归功于数学小王子高斯。我在工程中用到了最小二乘法。一般人脸是左右对称的,腮红应用妆容的时候,会作镜像处理贴上去。在贴之前,需要找到人脸的对称轴才能镜像。一个简单的做法是,取人脸检测(Haar特征 haarcascade_mcs_lefteye.xml,haarcascade_mcs_righteye.xml)到的眼角内点或外点的垂直平分线。利用眼珠子计算肯定是不行的,因为眼珠子会左右转动,计算出的结果不准确。而眼角,也可能会由于偏头、眨眼、眯眼等原因,人脸检测出的位置也可能有几度的偏差。考录到左右特征点连线的中点会落到对称轴上,最终我尝试把脸上左右对称的特征点(剔除了像眼珠子一样在脸上位置可能变动的特征点)求中点,拟合求出对称轴。大家可以看到第一张 Obama 图中的落到对称轴附近的叉叉就是中点,绿线是拟合出来的对称轴。OpenCV 里可以直接调用函数 cv::fitLine,工程代码里对应 Feature::getSymmetryAxis()。
公司也考虑过做美甲项目,这同样也涉及到检测特征点。
手册的第四章里有介绍,如何构建关于手掌分类器的模型,有兴趣的请移步。

dlib代码地址 https://github.com/davisking/dlib,一直都在更新,里面除了人脸识别,还有其他机器学习的算法。因为用到了 C++11 的一些特性,而 Visual Studio 对 C++11 的支持较落后,所以要求 VS2015 以上。dlib 检测的特征点比 STASM 更准确,工程文件对应 face_landmark_detection_ex.cpp 我用的是已经训练好的数据 shape_predictor_68_face_landmarks.dat,给出了68个特征点,相比 STASM 而言,没有额头特征点,眉毛没有构成封闭的多边形。网上也有标定好196个特征点的 Helen 数据库,我也测试过,因为它可以标定的区域更密集,从理论上说化妆效果也应该会更好。

给分类器文件瘦身
考虑到移动端的性能因素,shape_predictor_68_face_landmarks.dat 这个文件太大,BZIP压缩后61M,解压后有95M,直接打包在APK里,可能不太好。应该更适合联网下载,这是 dlib 输给 STASM 的一个地方,STASM 只需要几兆左右的空间,相关文件 haarcascade_frontalface_alt2.xml,haarcascade_mcs_lefteye.xml,haarcascade_mcs_righteye.xml,而且可以通过处理,缩减到一半大小。
对于网上提供的这些文件,XML文件以文本形式打开,会发现里面有很多注释和空白字符,这些都是为了方便理解数据,但是对于运行时则无用,占内存不说,还增加了解析时间,所以可以去掉。浮点数据类型,用文本形式存储的话很占空间,这个可以选择截断长度,对检测结果影响不大。所以在后期,我给分类器做了瘦身处理。haarcascade_mcs_mouth.xml 大小702 KB,删除注释和多余的空格字符后344KB;haarcascade_mcs_righteye.xml大小1.35 MB,同样的操作后662 KB,还是很可观的,差不多缩减到一半。浮点数的存储,二进制比文本更节省空间,可以尝试降低浮点数精度储存,比如-1.2275323271751404E-02 替换成-1.2275E-2。