高可用集群原理
LVS集群DR模式简单的架构图如下所示:
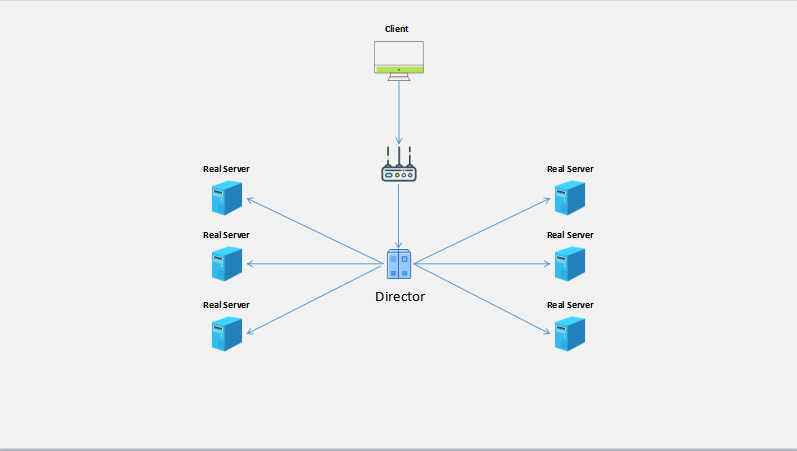
在上图的架构中,当Director服务器因软件、硬件、人为原因造成故障时,整个集群服务不可用,因此,需要再添加一台服务器实现Director服务高可用。
整个系统的架构图如下所示:
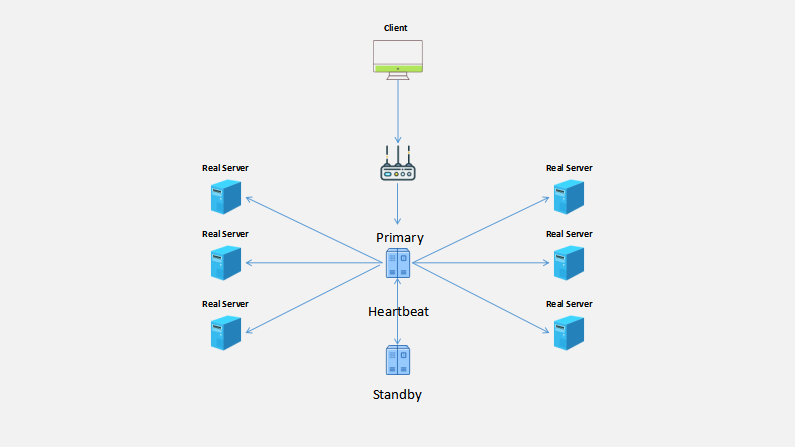
此时,客户端发送请求经过路由器到达Primary (Active)Director服务器,Primary Director服发务器根据调度规则,将请求发送至不同的RealServer服务器,并且Primary Director与Standby(Passive)Director 服务器处于同一网段上,相互进行心跳监测(Heartbeat),当发现提供服务的Primary Director服务器发生故障时,在LVS集群DR模式中,只需将Primary Director服务器上的VIP以及IPVS规则、RealServer高可用脚本转移到Standby Director 服务器上即可,在这个过程中VIP、IPVS规则、RealServer高可用脚本我们称之为高可用集群资源(High Availability Resource),这个转移资源的过程称之为资源转移,也称之为故障转移(FailOver)。
然而,此时在路由器中缓存的VIP和MAC地址仍然是配置在Primary 服务器网卡别名上的VIP和网卡的MAC地址。为了让路由器刷新缓存中的VIP和MAC地址,Standby拿到VIP时,强行进行一次ARP解析请求,因请求是广播的,路由器发现自己缓存中的VIP对应的MAC和广播中的不一样,便会更新自己的缓存,然后当客户端发起请求时,路由器就将请求发送至Standby服务器。
由上面简单高可用集群可以概括出高可用集群(High Availability Cluster)是指当某一个节点或服务器发生故障时,另一个节点能够自动且立即向外提供服务,即将有故障节点上的资源转移到另一个节点上去,这样另一个节点有了资源既可以向外提供服务。高可用集群是用于单个节点发生故障时,能够自动将资源、服务进行切换,这样可以保证服务一直在线。
高可用集群一般是通过系统的可靠性(Reliability)和系统 的可维护性(Maintainability)来衡量的。通常用平均无故障时间(MTTF)来衡量系统的可靠性,用平均维护 时间(MTTR)来衡量系统的可维护性。因此,一个高可用集群服务可以这样来定义:HA=MTTF/(MTTF+MTTR)*100%。
| 描述 | 通俗叫法 | 可用性级别 | 年度停机时间 |
| 基本可用 | 2个9 | 99% | 87.6小时 |
| 较高可用 | 3个9 | 99.9% | 8.8小时 |
| 具有故障自动恢复能力的可用 | 4个9 | 99.99% | 53分钟 |
| 极高可用 | 5个9 | 99.999% | 5分钟 |
在上面的描述中,对Director服务器的主、从描述将会产生误解,其实,当故障转移之后,主变成了从,从变成了主,将提供正常服务的Director主机称之为Primary更合理。
以上图为例,考虑一个问题,当Primary服务器故障修复时,是否需要将Standby服务器上的资源转移回Primary服务器?
假如我们在服务器上运行的是一个WEB服务,当Standby服务器的资源转移回Primary服务器时,所有用户连接必然会断开,用户体验不佳,但是,Standby服务器作为备用服务器,一般情况下,性能比Primary服务器差很多,我们不转移回Primary服务器,整个WEB性能跟不上,用户体验也不好,因此,就要判断资源更倾向于运行在那个服务器节点,资源对服务器节点的倾向值,称之为高可用集群的资源粘性。资源粘性的值一般用整数来表示,正数表示倾向与运行在当前节点,负数表示不适合运行在当前节点。再假如,Primary服务器的资源粘性是10,Standby的资源粘性是-10,当Primary服务器故障修复时,资源从StandbyPrimary服务器,这个过程称之为自动恢复,也称之为故障回转(FailBack)。